

python常用操作
目录
一、运算符
二、公共操作
三、循环
四、函数
五、推导式
六、递归&匿名函数
七、内置高阶函数
八、常见数据结构
九、生成器generator
十、Collections库常用方法
一、运算符
#数据类型 age = 18 name = 'TOM' weight = 75.5 stu_id = 1 print('今年我的年龄是%d岁' % age) print('我的名字是%s' % name) print('我的体重是%.1f公斤' % weight) print('我的学号是%03d' % stu_id) print('我的名字是%s,今年%d岁了' % (name,age)) #打印更高效 print(f'我的名字是{name},今年{age}岁了') print('hello\nworld') print('a\tb\tc\td') print('hello world',end="...") # 注释 ctrl+ / """ print('where') """ ''' print('are') ''' #输入 #password = input("请输出密码:") #print(f'您输入的密码是{password}') #print(type(password)) #print(type(int(password))) #运算 print(10//3)#取整 print(10%3)#取模 print(10**2)#指数 #多变量赋值 num1,float1,str1 = 10, 0.5 ,'yep' print(num1) print(float1) print(str1) c= 10 c *= 1 + 2 print(c) #逻辑运算 #and运算符,只要有一个值为0,则结果为0,否则返回最后一个非0数字 #or运算符,只有所有值为0结果才为0,否则返回第一个非0数字 a = 0 b = 1 c = 2 print(b and c) print(a or c) #三目运算符 a = 10 b = 6 c = a - b if a > b else b - a print(c)
二、公共操作
# 公共操作(运算符、公共方法、容器类型转换) str1 = 'aa' str2 = 'bb' list1 = [1,2] list2 = [10,20] t1 = (1,2) t2 = (10,20) dict1 = {'name':'Python'} dict2 = {'age':'30'} # +:合并,支持字符串、列表、元组 print(str1 + str2) print(list1 + list2) print(t1 + t2) #print(dict1 + dict2) # *: 复制,支持字符串、列表、元组 print(str1 * 5) print(list1 * 5) print(t1 * 5) #print(dict1 * 5) # len计算元素个数 print(len(str1)) print(len(list1)) print(len(t1)) print(len(dict2)) # del 或 del() 删除 # max(),min() print(max(str1)) # range(start,end,step) for i in range(1,10,1): print(i) # enumerate(可遍历对象,start=0) 返回结果是元组,第一个是下标,第二个是数据 list1 = [1,2,3,4] for i in list1: print(i) for i in enumerate(list1): print(i) for key,value in enumerate(list1,start = 1): print( key,value) # 容器转换 # tuple() 转成元组 # list() 转成列表 # set() 转成集合
三、循环
#随机数 import random as rd print (rd.randint(0,2)) #while循环 i = 0 while i < 5: print('媳妇我错了') i += 1 #break 终止此循环 #continue 退出当前循环,开始下一个循环 #pass 跳过 #打印长方形 j = 0 while j < 5: k = 0 while k < 5: print('*' ,end=' ') k += 1 print() j +=1 #打印三角形 i = 0 while i < 5: j = 0 while(j <= i): print('*' ,end=' ') j += 1 print() i += 1 #打印乘法表 i = 1 while i <= 9: j = 1 while(j <= i): # print(f'{j} * {i} = {i*j}',end = '\t') print('%d * %d = %d' %(j,i,i*j),end = '\t') j += 1 print() i += 1
四、函数
# 函数 def sel_func(): print('显示余额') print('取款') print('存款') print('恭喜你登录成功') sel_func() print('您的余额是1000000') sel_func() print('取了1000') sel_func() # 全局变量 global num # 位置参数:顺序和数量要一致 # 关键字参数:如果有位置参数,必须在位置参数后,数量一致,关键字参数的顺序没有要求 # 默认参数 # 不定长位置参数,返回一个元组 def user_info(*args): print(args) user_info('Tom') user_info('Tom',18) # 不定长关键参数,返回一个字典 def user_info(**args): print(args) user_info(NAME='Tom',AGE=28,SEX='男') # 字典拆包 dict1 = {'name':'Tom','age':18} a,b = dict1 print(a) print(b) print(dict1[a]) print(dict1[b]) # 交换变量 a, b = 1, 2 a, b = b, a print(a,b) # 引用,在py中,值是靠引用来传递的 # id():那块内存的地址标识 a = 1 b = a print(id(a)) print(id(b)) a = 2 print(id(a)) print(id(b)) aa = [10,20] bb = aa print(id(aa)) print(id(bb)) aa = [30,40] print(id(aa)) print(id(bb)) # 引用可以当做实参传入 # 内置函数 绝对值 abs() 幂函数 pow(x,y) 即 x的y次幂 # math包函数 平方根 math.sqrt(4) = 2
五、推导式
# 推导式(化简代码)支持列表、字典、集合 # 一、列表推导式, # 创建一个0-10的列表 # 1.循环实现 list1 = [] i = 0 while i < 10: list1.append(i) i += 1 print(list1) list1 = [] for i in range(0,10): list1.append(i) i += 1 print(list1) # 2.列表推导式 list1 = [i for i in range(10)] print(list1) # 创建0-10的偶数列表 list2 = [i for i in range(0,10,2)] print(list2) list3 = [i for i in range(0,10,2) if i % 2 == 0] print(list3) # 多个for循环实现列表推导式 # [(1,0),(1,1),(1,2),(2,0),(2,1),(2,2)] # 数据1:1,2 range(1,3) # 数据2:0,1,2 range(0,3) list3 = [(i,j) for i in range(1,3) for j in range(3)] # 二、字典推导式 # 创建一个字典,key是1-5,value是key的二次方 dict1 = {i:i**2 for i in range(1,6)} print(dict1) # 将两个列表合并为一个字典 list1 = ['name','age','gender'] list2 = ['Tom',20,'man'] dict1 = {list1[i]:list2[i] for i in range(len(list1))} print(dict1) # 如果两个列表的数据个数不同,按len少的列表数据为准 # 三、集合推导式 list1 = [1,1,2] set1 = {i ** 2 for i in list1} print(set1)
六、递归&匿名函数
# 递归:函数内部自己调用自己、必须有出口 def sum_numbers(num): if num == 1: return 1 return num + sum_numbers(num -1) result = sum_numbers(10) print(result) # lambda:(匿名函数)如果一个函数有一个返回值,并且只有一句代码,可以用lambda简化 fn2 = lambda: 100 print(fn2) print(fn2()) fn1 = lambda a,b: a + b print(fn1(1,2)) # 可变参数*args,返回元组 fn3 = lambda *args: args print(fn3(10,20,30)) print(fn3(10)) # 可变参数*kwargs,返回字典 fn4 = lambda **kwargs: kwargs print(fn4(name='Python')) print(fn4(age=30)) # 带判断的lambda fn5 = lambda a,b:a if a > b else b print(fn5(120,119)) # 列表数据按字典key值排序 students = [ {'name':'Tom','age':18}, {'name':'Jack','age':20}, {'name':'wuchen','age':19} ] info = students.sort(key = lambda x:x['age'],reverse = True) print(students)
七、内置高阶函数
#1. 高阶函数 abs(),round() def sum(a,b,f): return f(a) + f(b) print(sum(-1,5,abs)) print(sum(1.1,2.1,round)) #2. 内置高阶函数 map(func,lst) 将传入的函数变量作用到lst变量的每个元素中,并将结果组成新的迭代器返回 做文本处理的时候,假如要对序列里的每个单词进行大写转化操作。 这个时候就可以使用map()函数。 chars = ['apple','watermelon','pear','banana'] a = map(lambda x:x.upper(),chars) print(list(a)) # 输出:['APPLE', 'WATERMELON', 'PEAR', 'BANANA'] map()会根据提供的函数,对指定的序列做映射,最终返回迭代器。 也就是说map()函数会把序列里的每一个元素用指定的方法加工一遍,最终返回给你加工好的序列。 举个例子,对列表里的每个数字作平方处理: nums = [1,2,3,4] a = map(lambda x:x*x,nums) print(list(a)) # 输出:[1, 4, 9, 16] #3. 内置高阶函数 reduce(func,lst),其中func必须哟两个参数,每次func计算的结果继续和序列的下一个元素做累积计算 前面说到对列表里的每个数字作平方处理,用map()函数。 那我想将列表里的每个元素相乘,该怎么做呢? 这时候用到reduce()函数。 from functools import reduce nums = [1,2,3,4] a = reduce(lambda x,y:x*y,nums) print(a) # 输出:24 reduce()会对参数序列中元素进行累积。 第一、第二个元素先进行函数操作,生成的结果再和第三个元素进行函数操作,以此类推,最终生成所有元素累积运算的结果。 再举个例子,将字母连接成字符串。 from functools import reduce chars = ['a','p','p','l','e'] a = reduce(lambda x,y:x+y,chars) print(a) # 输出:apple 你可能已经注意到,reduce()函数在python3里已经不再是内置函数,而是迁移到了functools模块中。 这里把reduce()函数拎出来讲,是因为它太重要了。 #4. 内置高阶函数 filter(func,lst),用于过滤序列,过滤掉不符合条件的元素,返回一个filter对象 list1 = [1,2,3,4,5,6,7,8,9,10] def func(x): return x % 2 == 0 result = filter(func,list1) print(result) print(list(result)) #5.set() 当需要对一个列表进行去重操作的时候,set()函数就派上用场了。集合对象创建后,还能使用并集、交集、差集功能。 A = set('hello') B = set('world') A.union(B) # 并集,输出:{'d', 'e', 'h', 'l', 'o', 'r', 'w'} A.intersection(B) # 交集,输出:{'l', 'o'} A.difference(B) # 差集,输出:{'d', 'r', 'w'} #6.eval() eval(str_expression)作用是将字符串转换成表达式,并且执行。 a = eval('[1,2,3]') print(type(a)) # 输出:<class 'list'> b = eval('max([2,4,5])') print(b) # 输出: 5 #7.sorted() 在处理数据过程中,我们经常会用到排序操作,比如将列表、字典、元组里面的元素正/倒排序。 这时候就需要用到sorted() ,它可以对任何可迭代对象进行排序,并返回列表。 对列表升序操作: a = sorted([2,4,3,7,1,9]) print(a) # 输出:[1, 2, 3, 4, 7, 9] 对元组倒序操作: sorted((4,1,9,6),reverse=True) print(a) # 输出:[9, 6, 4, 1] 使用参数:key,根据自定义规则,按字符串长度来排序: chars = ['apple','watermelon','pear','banana'] a = sorted(chars,key=lambda x:len(x)) print(a) # 输出:['pear', 'apple', 'banana', 'watermelon'] 根据自定义规则,对元组构成的列表进行排序: tuple_list = [('A', 1,5), ('B', 3,2), ('C', 2,6)] # key=lambda x: x[1]中可以任意选定x中可选的位置进行排序 a = sorted(tuple_list, key=lambda x: x[1]) print(a) # 输出:[('A', 1, 5), ('C', 2, 6), ('B', 3, 2)] #8.reversed() 如果需要对序列的元素进行反转操作,reversed()函数能帮到你。 reversed()接受一个序列,将序列里的元素反转,并最终返回迭代器。 a = reversed('abcde') print(list(a)) # 输出:['e', 'd', 'c', 'b', 'a'] b = reversed([2,3,4,5]) print(list(b)) # 输出:[5, 4, 3, 2] #9.filter() 一些数字组成的列表,要把其中偶数去掉,该怎么做呢? nums = [1,2,3,4,5,6] a = filter(lambda x:x%2!=0,nums) print(list(a)) # 输出:[1,3,5] filter()函数轻松完成了任务,它用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象。 filter()函数和map()、reduce()函数类似,都是将序列里的每个元素映射到函数,最终返回结果。 我们再试试,如何从许多单词里挑出包含字母w的单词。 chars = chars = ['apple','watermelon','pear','banana'] a = filter(lambda x:'w' in x,chars) print(list(a)) # 输出:['watermelon'] #10.enumerate() 这样一个场景,同时打印出序列里每一个元素和它对应的顺序号,我们用enumerate()函数做做看。 chars = ['apple','watermelon','pear','banana'] for i,j in enumerate(chars): print(i,j) ''' 输出: 0 apple 1 watermelon 2 pear 3 banana ''' enumerate翻译过来是枚举、列举的意思,所以说enumerate()函数用于对序列里的元素进行顺序标注,返回(元素、索引)组成的迭代器。 再举个例子说明,对字符串进行标注,返回每个字母和其索引。 a = enumerate('abcd') print(list(a)) # 输出:[(0, 'a'), (1, 'b'), (2, 'c'), (3, 'd')]
八、常见数据结构
1. 数组:Array
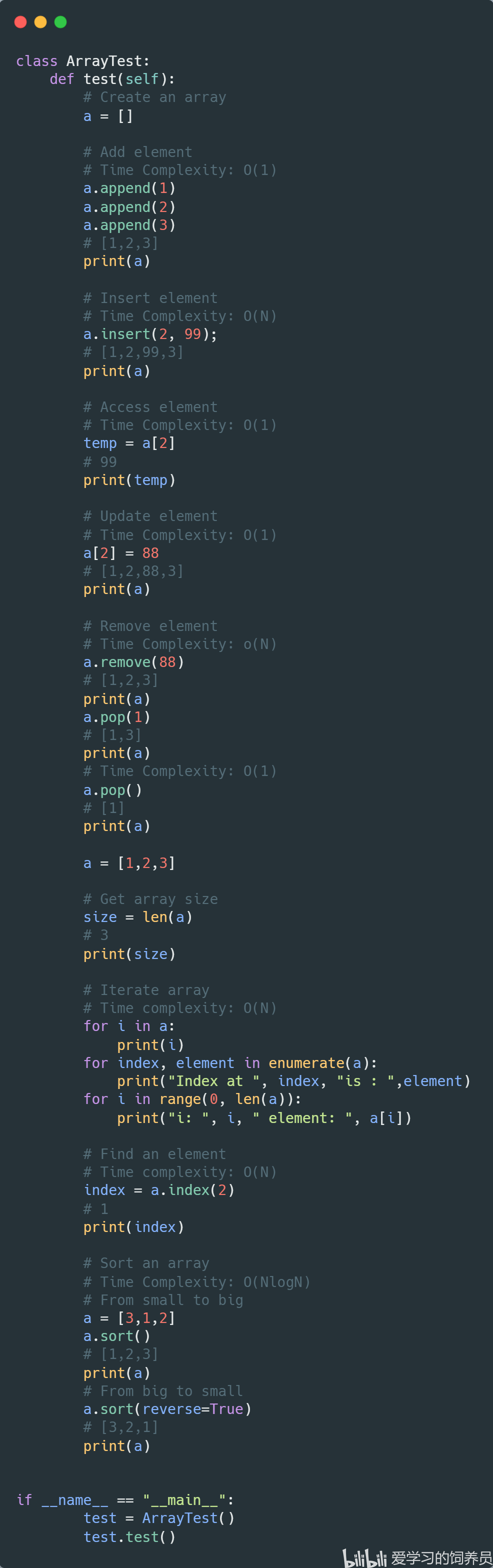
2. 链表:Linkedlist
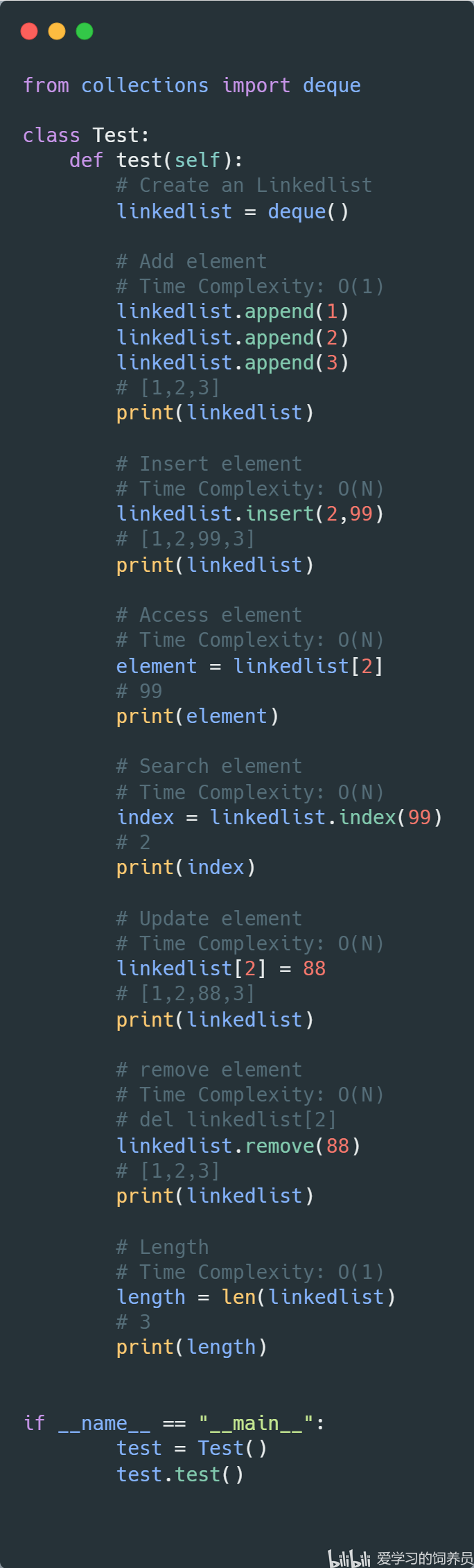
3. 哈希表:HashTable
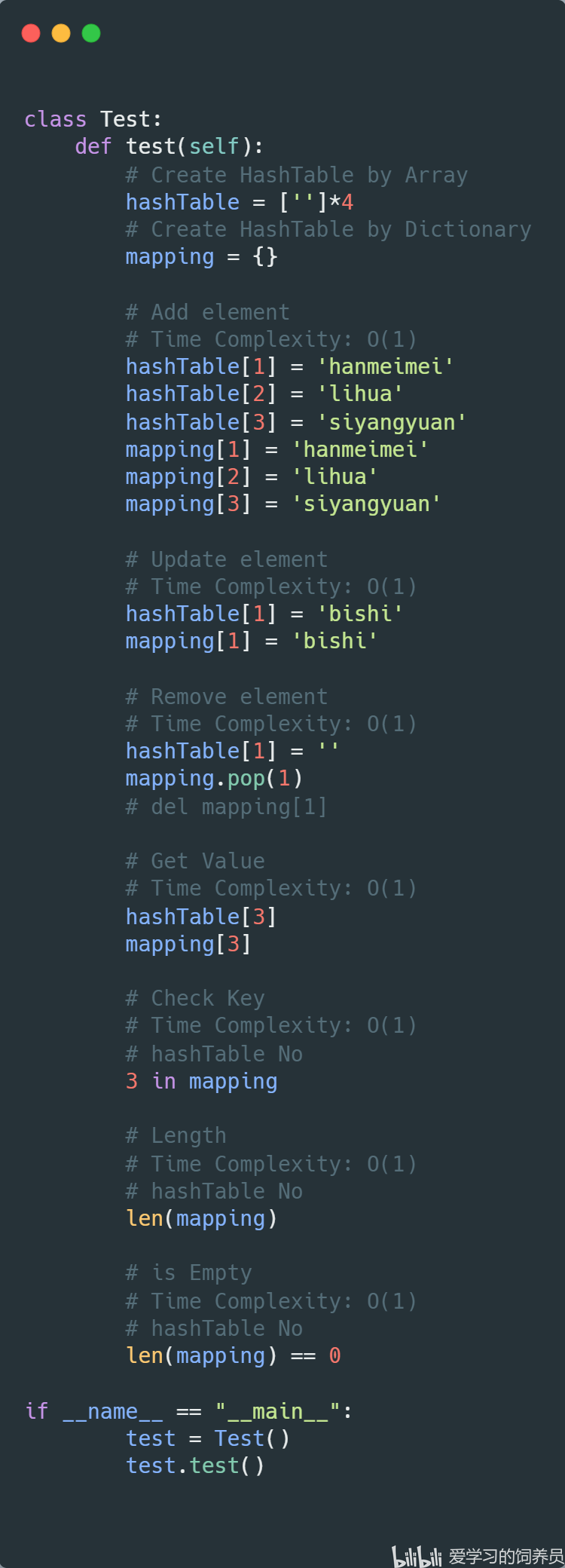
4. 队列:Queue
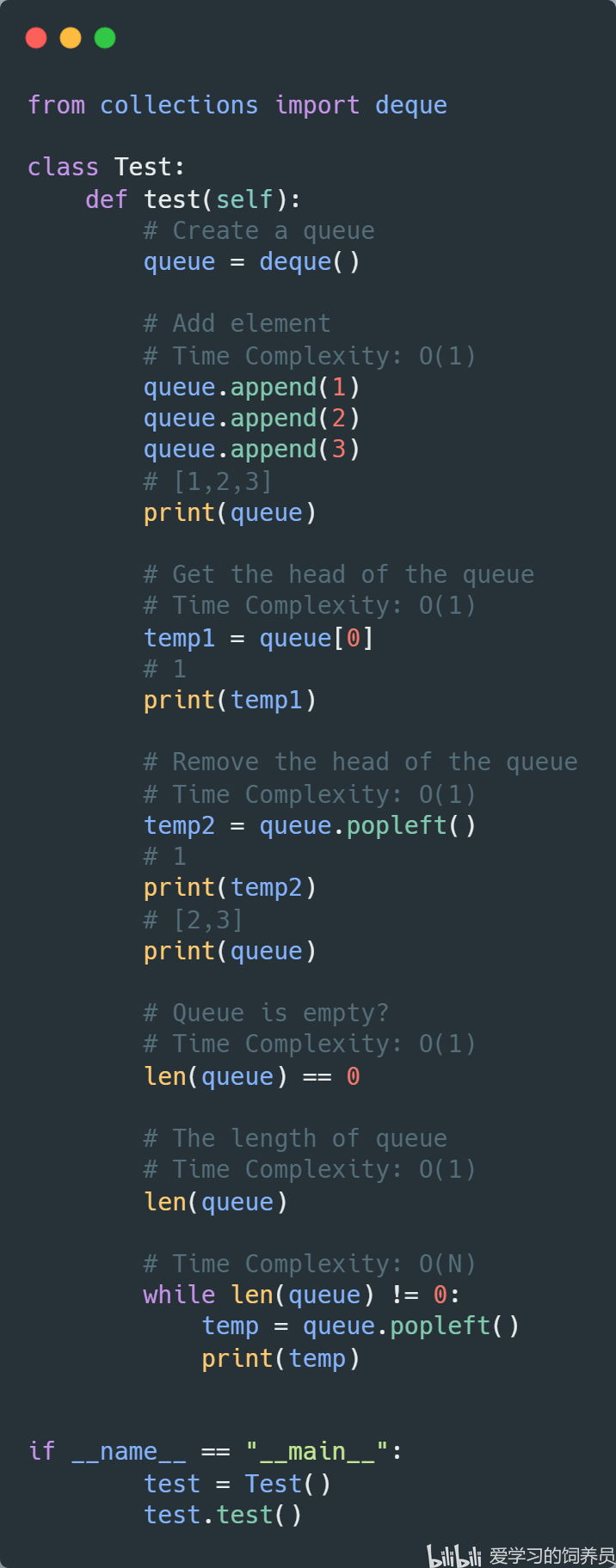
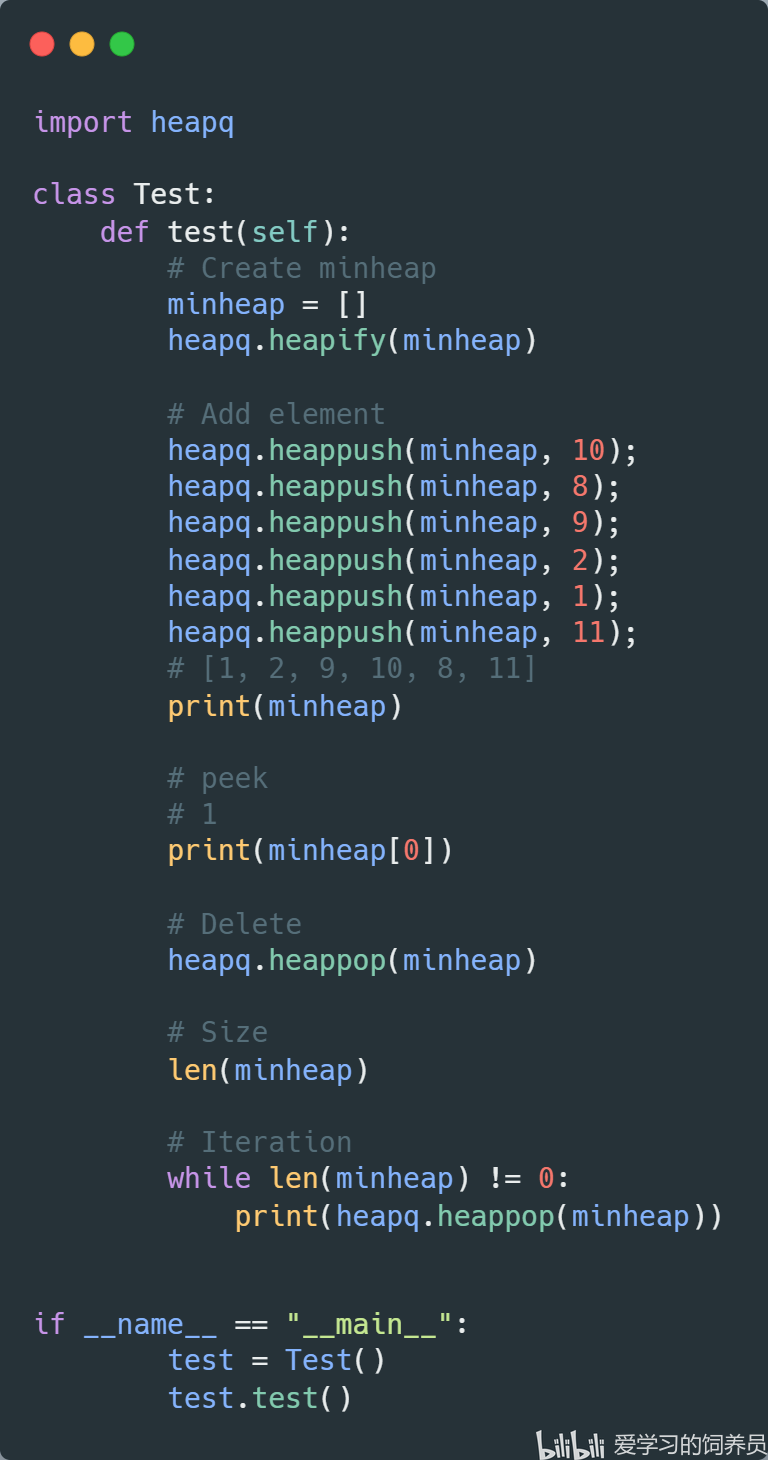
5. 堆:Heap
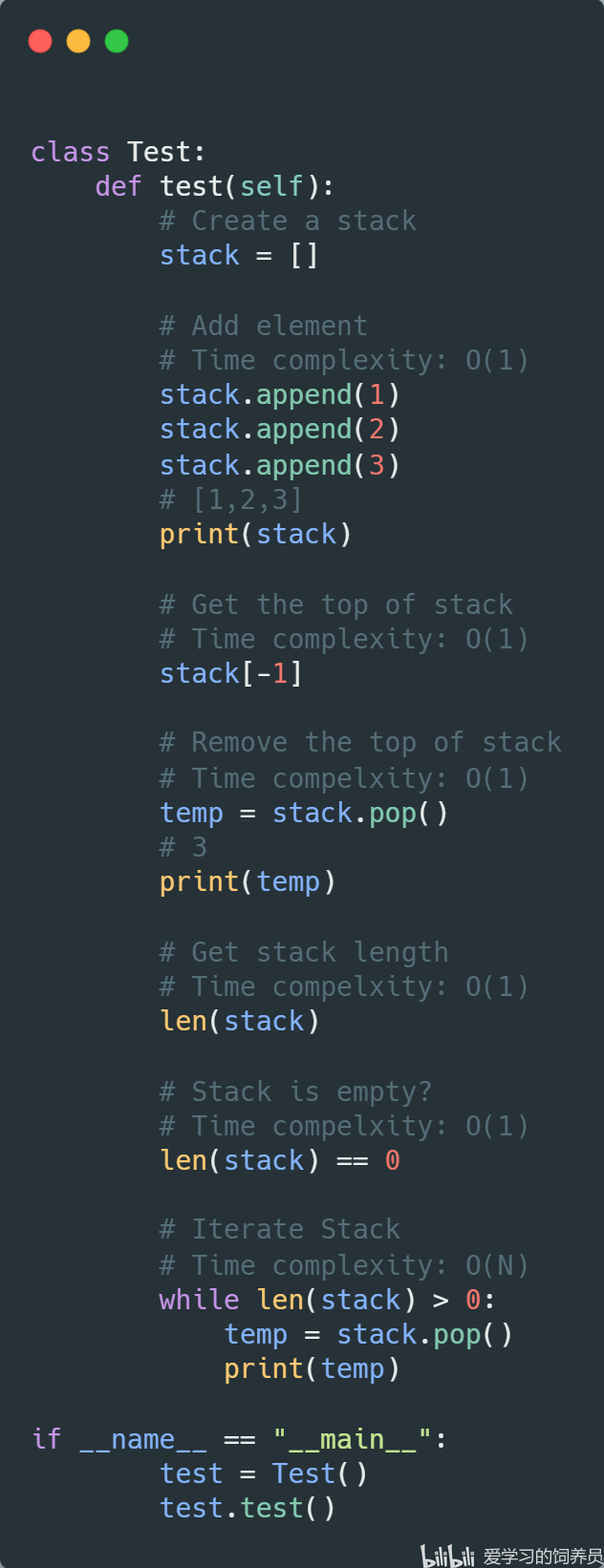
6. 栈:Stack
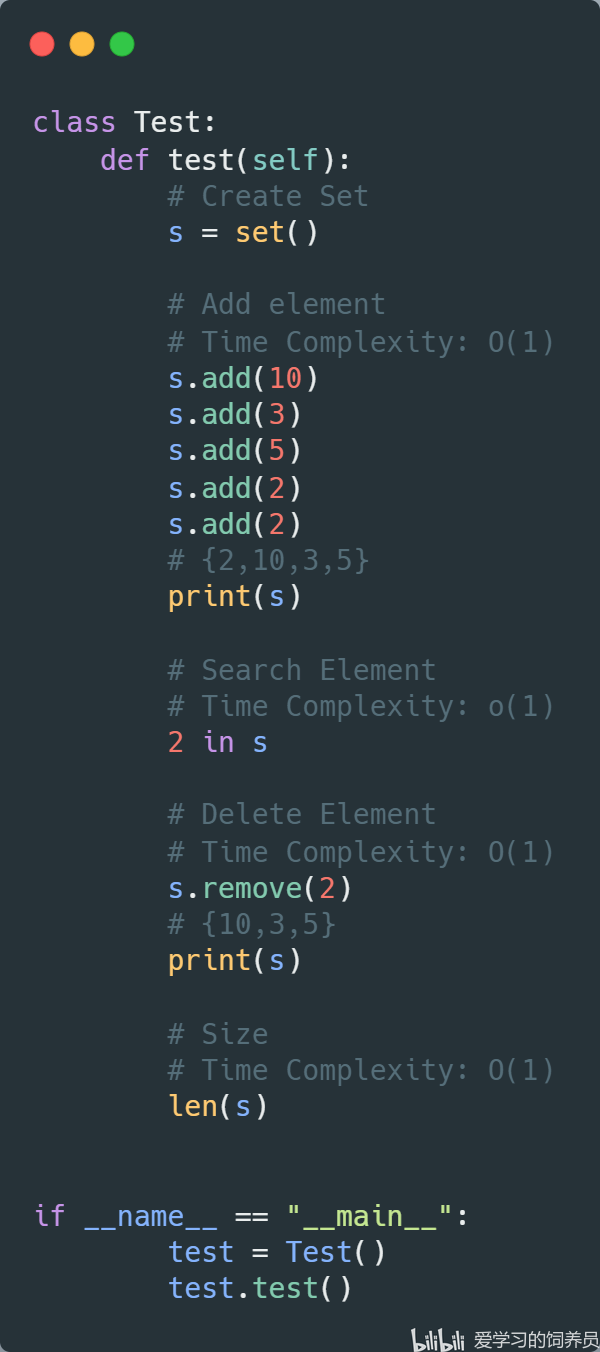
7. 集合:Set
九、生成器generator
1.yield关键字做了什么?
如果不太好理解yield,可以先把yield当作return的同胞兄弟来看,他们都在函数中使用,并履行着返回某种结果的职责。
这两者的区别是:
有return的函数直接返回所有结果,程序终止不再运行,并销毁局部变量;
有个经典的例子就是使用yield生成斐波那契数列:
1 def fab(max): 2 n, a, b = 0, 0, 1 3 while n < max: 4 yield b # 使用 yield 5 # print b 6 a, b = b, a + b 7 n = n + 1 8 9 for n in fab(5): 10 print n
2.生成器有哪些作用?
如果想具体化数据的形式,通常会将数据存储在一个列表中。但这样做,列表的内容将占用有形内存。列表越大,占用的内存资源就越多。
但是,如果数据集有某种逻辑,就不必存储在一个列表中,只需编写一个生成器,它将在需要时生成这些值,基本不占用内存。
十、Collections库常用方法
1.Counter统计词频 from collections import Counter with open('E:\唐诗.txt') as f: #读取成列表 c_list = f.readlines() #所有诗整合成字符串 c_str = ','.join(c_list) #使用Counter进行字频统计 c_cnt = Counter(c_str) #去除符号、'李'、'白'等特殊字符 useless_character = [',',',','。','【','】',':',':','《','》','\n','','作','者'] for i in useless_character: del c_cnt[i] #使用most_common方法提取频次最高的前10字符 c_top_10 = c_cnt.most_common(10) #打印 print(c_cnt) print(c_top_10) 2.Counter用法 Collections是一个容器模块,来提供Python标准内建容器 dict、list、set、tuple 的替代选择。也就是说collections模块是作为Python内建容器的补充,在很多方面它用起来更加有效率。 Counter是字典的子类,用于计数可哈希对象。计数元素像字典键(key)一样存储,它们的计数存储为值。
所以说Counter对象可以使用字典的所有方法。
1)创建Counter对象 from collections import Counter # 创建了一个空的Counter对象 c = Counter() # 用可迭代对象创建了一个Counter对象 c = Counter('gallahad') # 用映射来创建一个Counter c = Counter({'red': 4, 'blue': 2}) #用关键字参数创建Counter c = Counter(cats=4, dogs=8)
2)对可迭代对象进行计数 from collections import Counter c = Counter('bananas') c # 输出:Counter({'b': 1, 'a': 3, 'n': 2, 's': 1})
3)根据键引用值 from collections import Counter c = Counter('bananas') c['a'] # 输出:3
4)如果不存在该键,则返回0 from collections import Counter c = Counter('bananas') c['u'] # 输出:0
5)删除其中一个键值对 from collections import Counter c = Counter('bananas') del c['a'] c # 输出:Counter({'b': 1, 'n': 2, 's': 1})
6)用映射来创建一个Counter,并返回迭代器 from collections import Counter c = Counter({'red': 3, 'blue': 1,'black':2}) list(c.elements()) # 输出:['red', 'red', 'red', 'blue', 'black', 'black']
7)查看出现频次最高的前n元素及其次数 from collections import Counter c = Counter('absabasdvdsavssaffsdaws') c.most_common(3) # 输出:[('s', 7), ('a', 6), ('d', 3)]
8)两个Counter相减 from collections import Counter c = Counter(a=4, b=2, c=0) d = Counter(a=1, b=2, c=3) c.subtract(d) c # 输入:Counter({'a': 3, 'b': 0, 'c': -3})
9)转换成字典 from collections import Counter c = Counter('bananas') dict(c) # 输出:{'b': 1, 'a': 3, 'n': 2, 's': 1}
10)添加可迭代对象 from collections import Counter c = Counter('bananas') c.update('apples') c # 输出:Counter({'b': 1, 'a': 4, 'n': 2, 's': 2, 'p': 2, 'l': 1, 'e': 1})

 浙公网安备 33010602011771号
浙公网安备 33010602011771号