

序列化
一、什么是java序列化
首先谈一下什么是序列化, 序列化简单的来说,序列化会用在把一个对象、一个变量,以数据形式保留。比如把对象的二进制存在缓存、文件中。等需要的时候再次拿出来,反序列化为你想要的变量、对象。Java序列化即为,在现实应用中,就可能要求在JVM停止运行之后能够保存(持久化)指定的对象,并在将来重新读取被保存的对象。Java对象序列化就能够帮助我们实现该功能。
由上面可知,java序列化是为了保存一个对象当前属性的,便于还原重新构造这个对象。因此,java中的序列化做的即为保存java对象的成员变量的。因此,java序列化并不会关注类中的静态变量。同时java也对一些不需要序列化的变量提供了关键词transient,用transient修饰的变量就不会被序列化跟反序列化。
序列化好的数据,可以便于本地写入文件、或者写入redis缓存供多个机器通过读缓存的方式一起使用这个对象。用处很多。
二、java序列化需要具备
序列化应该具备的能力:
-
基础能力:提供序列化、反序列化的能力。
- 正确性:对对象引用关系(特殊的比如循环引用)、继承关系以及泛型的支持是否完备,这些都可能带来不可预知的bug。
- 开发成本:有的序列化方式可以无缝接入业务系统,有的则需要额外的配置,以具体场景能容忍的开发成本为准。
- 时间开销:序列化过程中,JVM的GC机制、类加载反射机制会影响时间开销,另外由于IO的成本一般大于内存、CPU的计算的成本,时间开销也往往强依赖于序列化的空间开销,序列化文件越大相应的时间开销也越大。
- 空间开销:包括序列化过程中动态的内存空间占用量,以及序列化后产出的文件大小。
- 安全性:因为序列化常涉及到存储和传输,数据暴露在外,涉及到安全性的问题。但同时由于序列化的过程常发生在内部网络,对外输出的数据则有应用层的协议保障安全,故一般情况下,序列化对安全性要求不高。
-
兼容性:
- 前向后向兼容:从业务演化的角度,可能出现序列化前后数据模式的改变。比如RPC过程中调用端和被调用端的Java类字段的改变。这就要求序列化有前向、后向兼容性,以此保证业务流程在业务演化过程中的稳定性。
- 跨语言兼容:大多数情况下同一架构体系内的应用采用同样的语言框架,不用考虑跨语言兼容。
三、java常用序列化方式
下面分布介绍,Java原生Serializable、Hessian、Kryo、proto-buffers、proto-stuff、fastjson。
1 Java原生Serializable
序列化代码例子,java序列化的话,很简单。如果是把一个对象序列化的话,implement java.io.Serializable 接口即可。一个类如果是implements java.io.Serializable的话,它的子类也是可以序列化的。序列化的时候,如果一个成员变量是基本类型如int、double类型的,这些可以被序列化,但是如果成员变量的类型是未实现Serializable接口的类的话,需要把成员变量的类型这个类,实现序列化接口 Serializable。
优点:
- 稳定无bug,java兼容性高。
- 开发接入成本低。
- 支持自定义序列化的方式,可实现自定义的加密等措施(重写
readObject,writeObject方法) - 提供了安全性的支持(比如使用
javax.crypto.SealedObject或java.security.SignedObject做装饰)
缺点:
- 序列化类的元素也太多有:开头、类描述、字段值,类的版本、元数据、字段描述,字段值等这些组成,这也是他byte数组大,速度慢的主要原因;
- 无法跨语言,java强绑定
2 Hessian
hessian原本是一个RPC框架,基于http传输,通过自定义的序列化协议将数据转换成二进制流,支持跨语言兼容性。由于其中序列化协议在稳定性和效率的折中上表现优异,切接入零成本,被广泛在互联网应用中使用。
优点:
- 时间、空间开销优于Java原生的方式,逊于Kryo、protobuff等其他方式。
- 对继承支持不足。由于其跨语言的特请,没在继承关系上充足考虑,在继承体系上有很多bug。
- 支持引用类型,支持循环引用。
缺点:
3 Kryo
序列化是Google提供的一种序列化方式,速度更快,使用内存更少,速度是Java序列化的10倍。但是并不支持Java序列化的所有形式(无所谓),并且使用之前需要对需要序列化的类进行注册。建议使用这种方式。
优点:
- 注册类:Kryo二进制流中没有类的字段描述信息,这减小了二进制流的大小。字段描述信息通过向kryo注册类来主动加载,或者在第一次被序列化、反序列化时被动加载。
- 支持引用开关:开启引用功能后,支持循环引用。
- 通过变长编码来记录int、long型,节省空间。
缺点:
- 前后向兼容差,不支持改动字段。因为二进制流中没有字段描述信息。
- 跨语言不支持
- 开发成本:必须有无参构造函数(hessian不需要),但不需要实现
Serializable接口(hessian一定要实现)
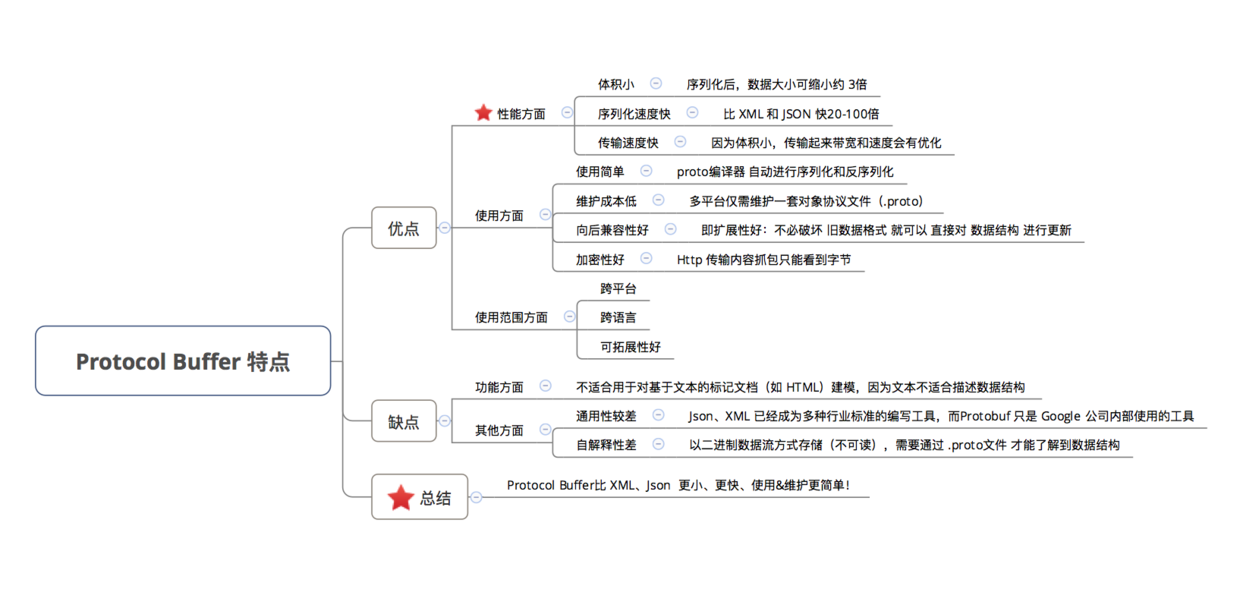
4 proto-buffers
一种 结构化数据 的数据存储格式(类似于 XML、Json )
优点:
- 序列化速度 & 反序列化速度快
- 数据压缩效果好,即序列化后的数据量体积小
缺点:
- 不支持继承。
- 没有引用类型,不支持循环引用。
- 需要自己写proto文件,定义schema,并生成对应的源码文件。开发繁琐,侵入了业务代码。
5 proto-stuff
Protostuff是一个开源的、基于Java语言的序列化库,它内建支持向前向后兼容(模式演进)和验证功能。
6 fastjson
JSON的格式本身有强语义,可读。把它作为中间结果,便于问题排查。其中较快的库有alibaba的fastJson。
优点:
- 中间结果可读,易于排查
- 跨平台、跨语言支持
- 速度快、但体积大
- 支持引用类型,支持循环引用。
- 由于多了层JSON的解析,引入了更多稳定应隐患,对继承、泛型的支持也不够好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号