
正则表达式的基本用法
正则表达式的基本用法
概述
正则表达式,是一种文本模式匹配工具,通常用来检索、替换和控制文本。
在C#中,可以使用System.Text.RegularExpressions命名空间中的Regex类来处理正则表达式:
- 匹配单个字符:获取字符串中第一个匹配项
// input: 要搜索匹配项的字符串
// pattern: 要匹配的正则表达式模式
var match = Regex.Match(input, pattern);
- 获取所有匹配项
var matches = Regex.Matches(input, pattern);
我将使用 xUnit 测试框架来展示一些基本的正则表达式用法。
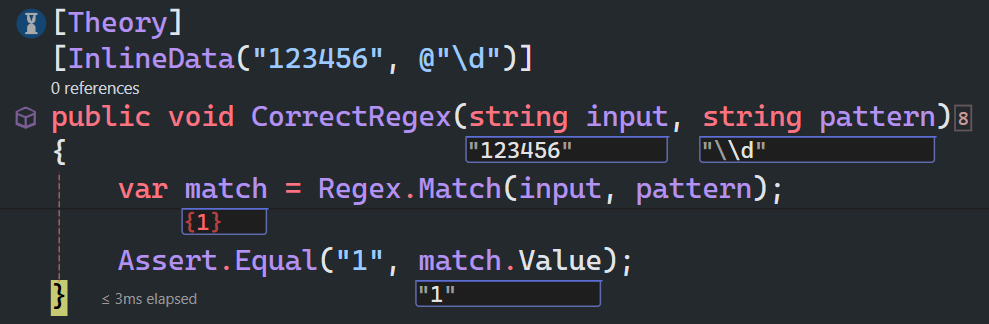
例如,使用正则字符\d获取字符串中的数字:
public class RegexTests
{
[Theory]
[InlineData("123456", @"\d")]
public void DigitalRegex(string input, string pattern)
{
var match = Regex.Match(input, pattern);
Assert.Equal("1", match.Value);
}
}
使用方法
数字与非数字
\d匹配一个数字字符,等价于[0-9]
输入要搜索匹配项的字符串:
input="123456"
在 C# 中,需要使用双反斜杠 "\d" 来表示一个反斜杠和一个 'd' 字符,这在正则表达式中表示匹配一个数字字符。
pattern="\\d"
使用 Regex.Match 方法匹配输入字符串中的第一个匹配项
var match = Regex.Match(input, pattern);
我们可看到第一个匹配项的值为"1"。
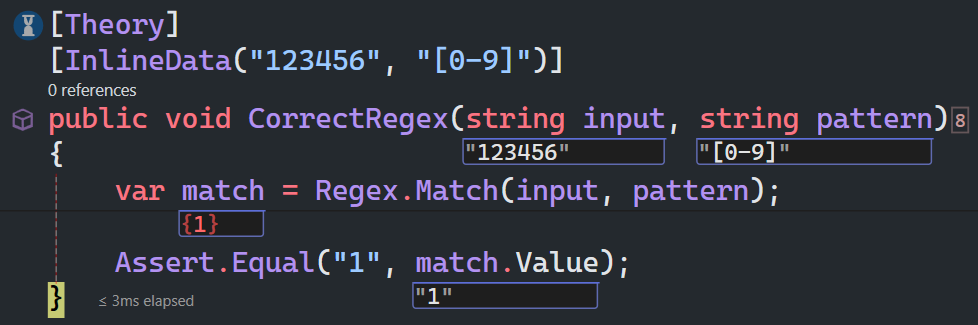
同样地,使用[0-9]作为正则表达式模式:
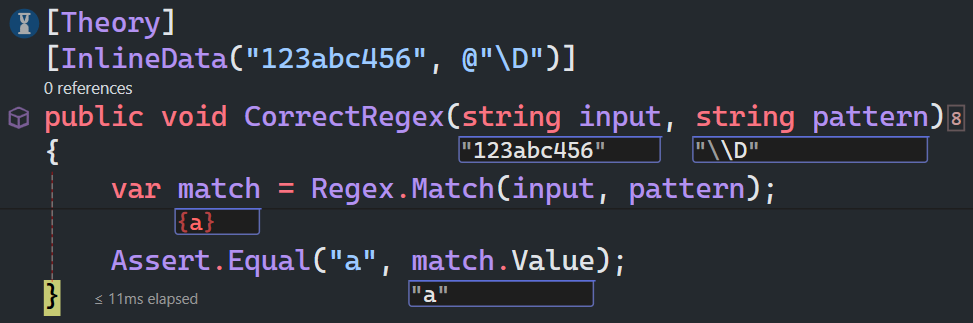
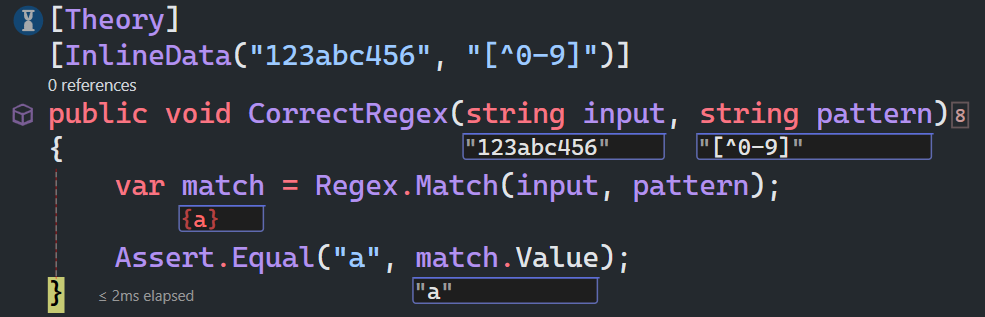
\D匹配一个非数字字符,等价于[^0-9]
同样地,使用[^0-9]作为正则表达式模式:
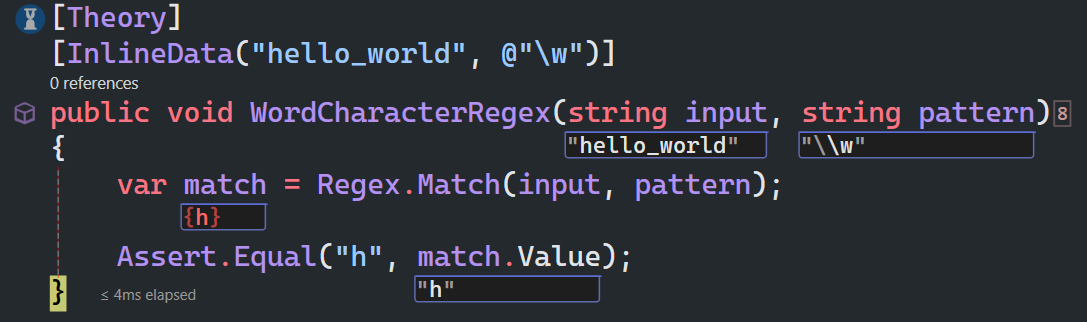
单词字符与非单词字符
\w匹配包括下划线的任何单词字符,等价于[A-Za-z0-9_]
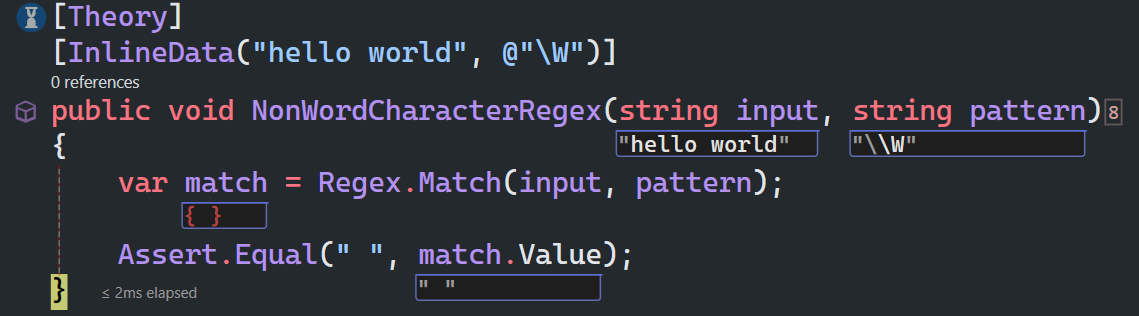
\W匹配包括下划线的任何单词字符,等价于[^A-Za-z0-9_]
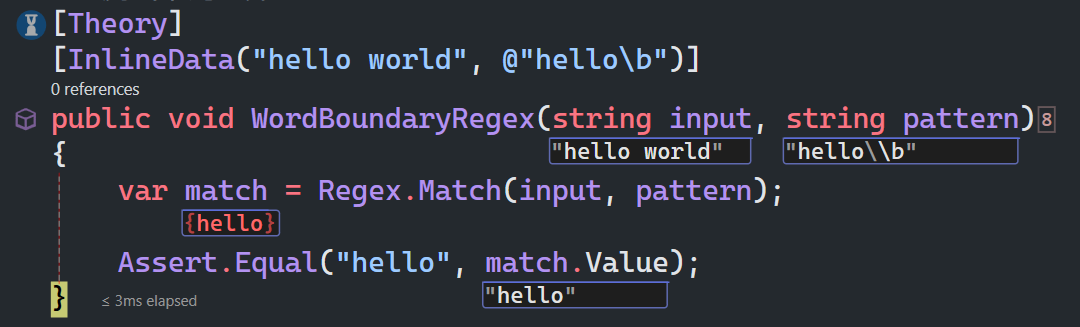
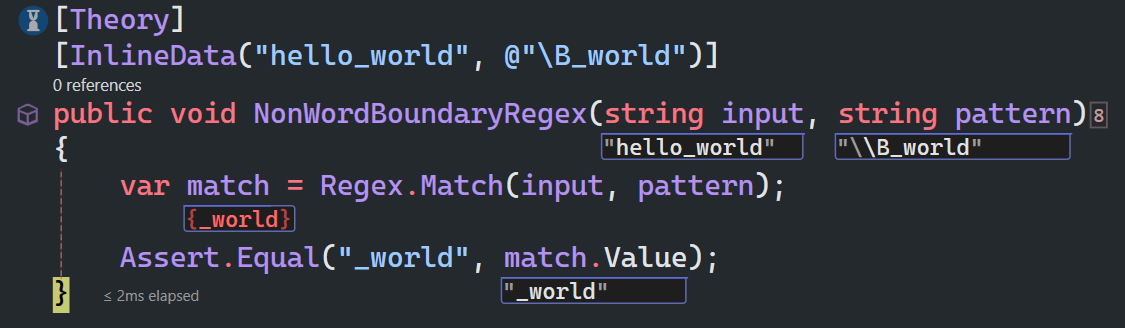
单词边界与非单词边界
\b匹配一个单词边界,也就是指单词和空格间的位置
\B匹配非单词边界
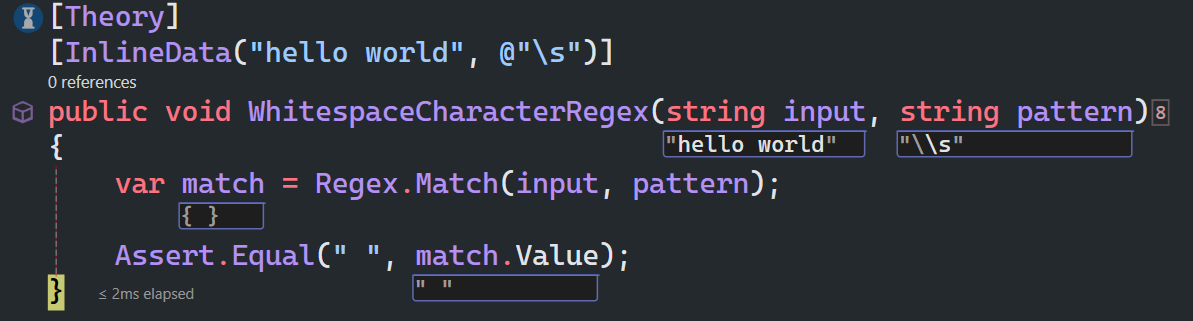
空白字符与非空白字符
\s匹配任何空白字符,包括空格、制表符、换页符等等,等价于[ \f\n\r\t\v]
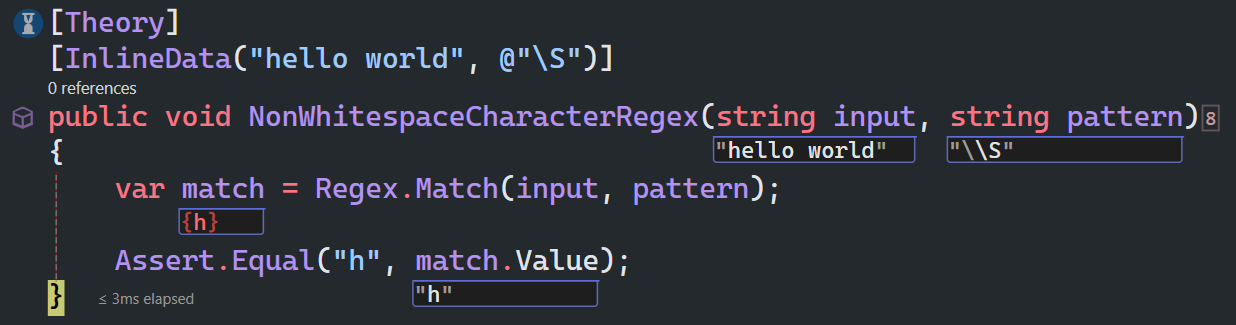
\S匹配任何非空白字符,等价于[^ \f\n\r\t\v]
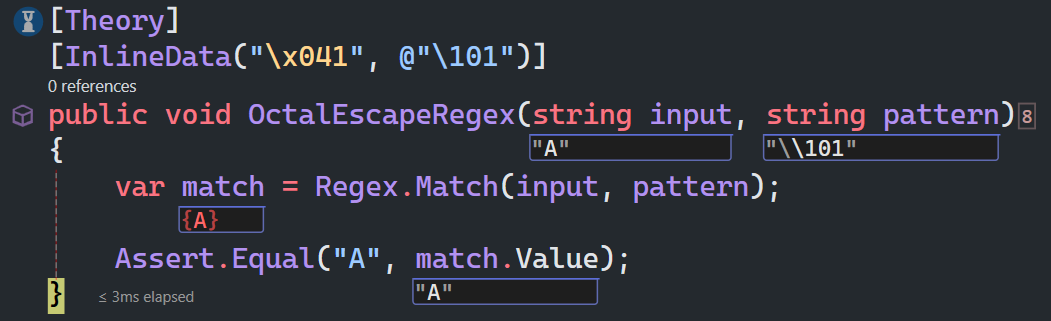
八进制转义字符
\nml 如果n为八进制数字(0-3),且m和l均为八进制数字(0-7),则匹配八进制转义值nml
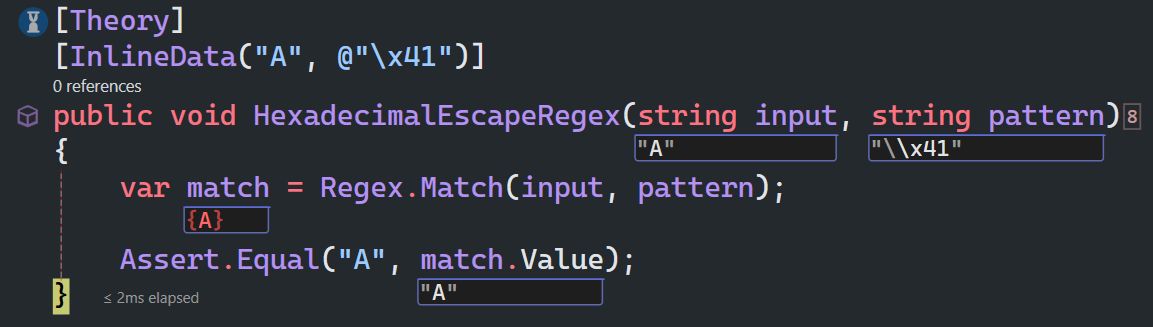
十六进制转义字符
\xn 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长
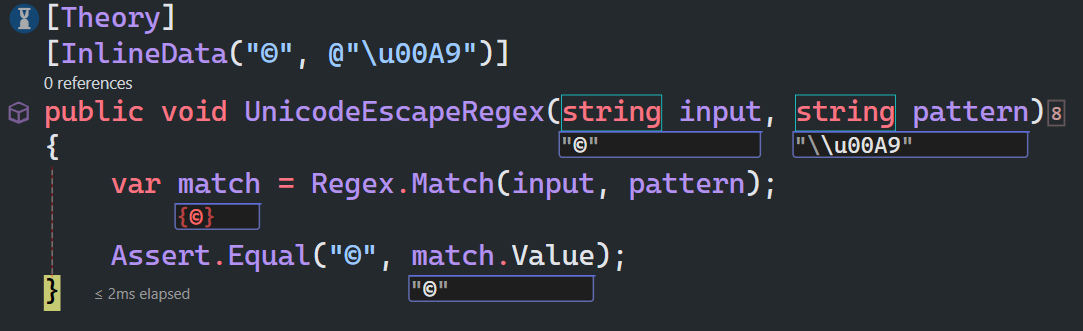
Unicode转义字符
\Un 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。
向后引用
\num 匹配num,其中num是一个正整数,对所获取的匹配的引用。
你可能对上述描述感到困惑,我们需要提前理解捕获组的功能:
(.):捕获组,捕获匹配的子字符串,供后续使用。其中括号内的.表示任意字符。
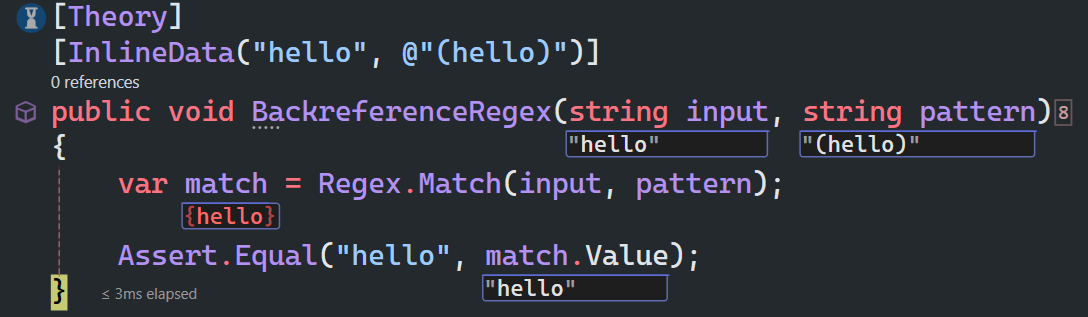
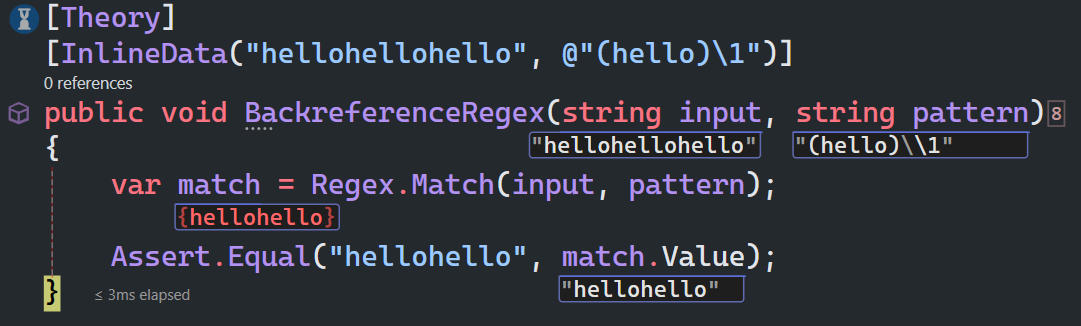
假设你有一个字符串 "hellohello",你希望匹配两个连续的相同子字符串。可以使用以下正则表达式:
(hello)\1
其中:
(hello):捕获组,匹配字符串 "hello"。
\1:向后引用,引用第 1 个捕获组的内容,即 "hello"。
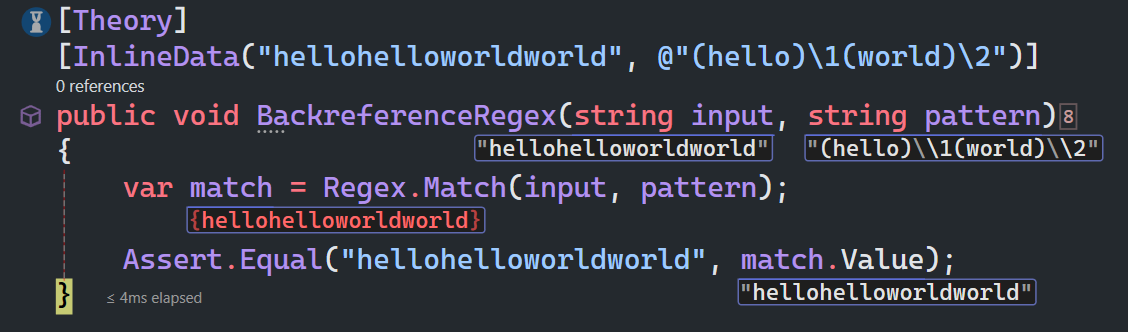
再看一个例子,假设你有一个字符串 "hellohelloworldworld",你希望匹配两个连续的相同子字符串。可以使用以下正则表达式:
(hello)\1(world)\2
其中:
(hello):捕获组,匹配字符串 "hello"。
\1:向后引用,引用第 1 个捕获组的内容,即 "hello"。
(world):捕获组,匹配字符串 "world"。
\2:向后引用,引用第 2 个捕获组的内容,即 "world"。
其他特殊字符
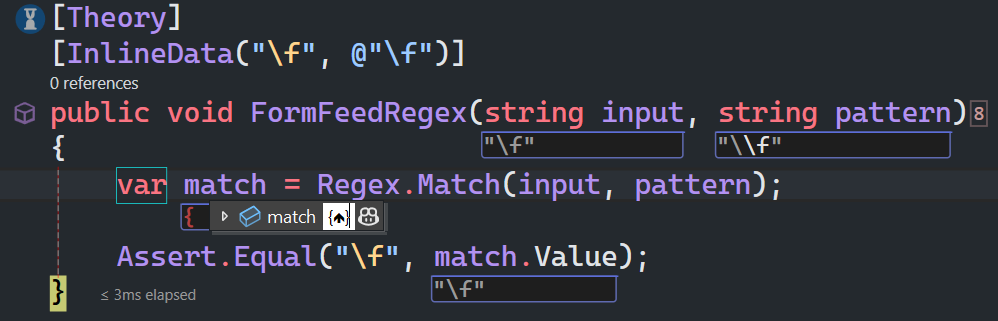
换页符
f 匹配一个换页符,等价于 \x0c 和 \cL
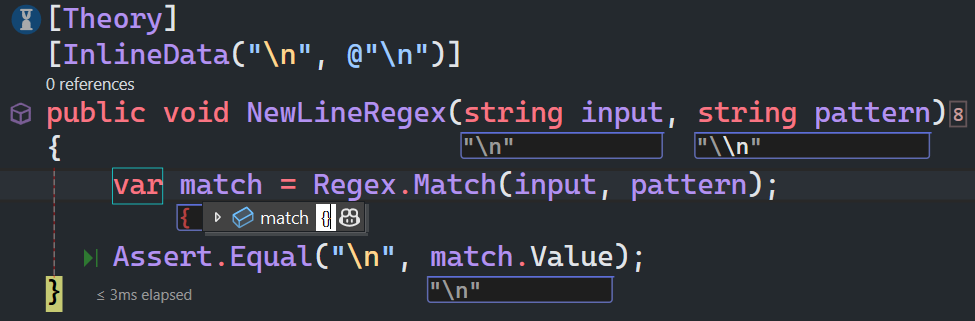
换行符
\n 匹配一个换行符。等价于 \x0a 和 \cJ。
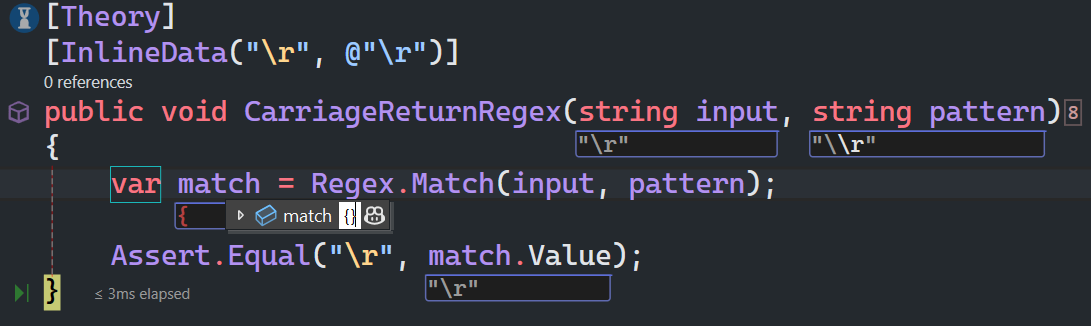
回车符
\r 匹配一个回车符。等价于 \x0d 和 \cM。
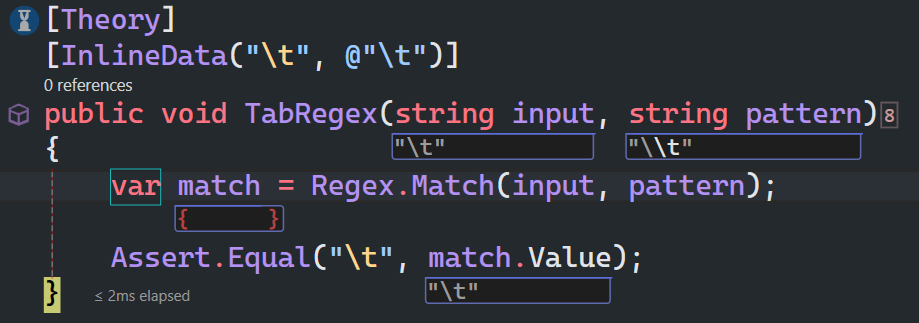
制表符
\t 匹配一个制表符。等价于 \x09 和 \cI。
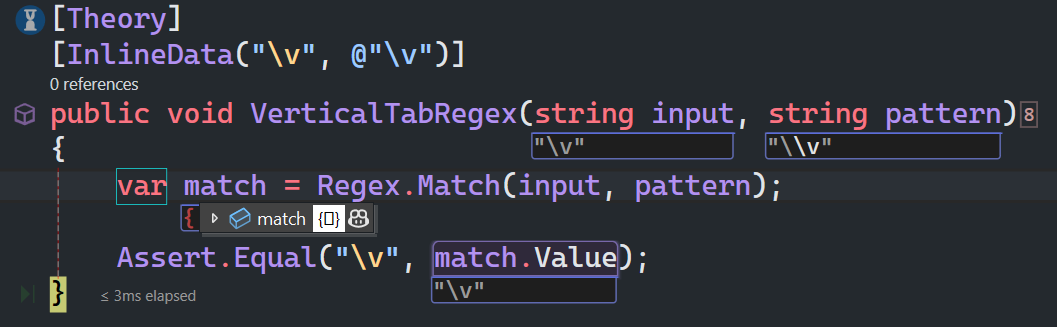
垂直制表符
\v 匹配一个垂直制表符。等价于 \x0b 和 \cK。
其他正则字符
以下表格引用自 https://stackoverflow.org.cn/regexsucha/。
| 正则字符 | 描述 |
|---|---|
\ |
将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符 |
^ |
匹配输入字符串的开始位置 |
| $ | 匹配输入字符串的结束位置 |
* |
匹配前面的子表达式零次或多次 |
+ |
匹配前面的子表达式一次或多次 |
? |
匹配前面的子表达式零次或一次 |
{n} |
n是一个非负整数。匹配确定的n次。 |
{n,} |
n是一个非负整数。至少匹配n次。 |
{n,m} |
m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。 |
? |
当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。 |
. |
匹配除\n之外的任何单个字符 |
x|y |
匹配x或y |
[xyz] |
字符集合。匹配所包含的任意一个字符。 |
[^xyz] |
负值字符集合。匹配未包含的任意字符。 |
[a-z] |
字符范围。匹配指定范围内的任意字符。 |
[^a-z] |
负值字符范围。匹配任何不在指定范围内的任意字符。 |
示例
// 锚点 ^ 和 $
[Theory]
[InlineData("hello", @"^h", "h")] // 匹配开头
[InlineData("world", @"d$", "d")] // 匹配结尾
[InlineData("hello world", @"^hello.*d$", "hello world")] // 完整匹配
public void StartAndEndAnchorRegex(string input, string pattern, string expected)
{
var match = Regex.Match(input, pattern);
Assert.Equal(expected, match.Value);
}
// 量词 * + ? {n}
[Theory]
[InlineData("aabbcc", @"a+b*", "aab")] // a至少1次,b任意次
[InlineData("ab", @"a?b", "ab")] // a可选
[InlineData("aaa", @"a{2}", "aa")] // 精确匹配2次
[InlineData("aaaa", @"a{2,4}", "aaaa")] // 匹配2-4次
public void QuantifiersRegex(string input, string pattern, string expected)
{
var match = Regex.Match(input, pattern);
Assert.Equal(expected, match.Value);
}
// 字符集合 [ ] 和范围
[Theory]
[InlineData("cat", @"[aeiou]", "a")] // 匹配元音字母
[InlineData("dog", @"[^aeiou]", "d")] // 非元音字符
[InlineData("data123", @"[a-z]{4}", "data")] // 小写字母范围
public void CharacterSetRegex(string input, string pattern, string expected)
{
var match = Regex.Match(input, pattern);
Assert.Equal(expected, match.Value);
}
// 或操作符 | 和分组
[Theory]
[InlineData("apple", @"apple|orange", "apple")] // 匹配其中一个
[InlineData("orange", @"apple|orange", "orange")]
public void OrOperatorRegex(string input, string pattern, string expected)
{
var match = Regex.Match(input, pattern);
Assert.Equal(expected, match.Value);
}
参考文章
- stackoverflow 正则表达式
https://stackoverflow.org.cn/regexsucha/
声明
内容准确性: 我会尽力确保所分享信息的准确性和可靠性,但由于个人知识有限,难免会有疏漏或错误。如果您在阅读过程中发现任何问题,请不吝赐教,我将及时更正。
posted on 2025-02-05 16:03 wubing7755 阅读(55) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号