六_docker网络之跨主机网络通信(2)
(2)、Overlay内部方案
一、overlay的原生网络
注意:以下实验使用vmare尽量用桥接模式或者自定义区段,自定义区段可以使用openwrt代替通信,部署方法如下:
- 准备以下软件和包
vmare:http://www.ddooo.com/softdown/177923.htm
openwrt x86:https://openwrt.mpdn.fun:8443/?dir=lede/x86_64/2022-04-13__05-24-23--plus-daily 一般在网上可以下载x86镜像,最好下载vmdk镜像的版本的,如果下载的是img的可以使用下面工具进行转换:
- 在你空余的磁盘创建一个文件夹并命名为openwrt,并将openwrt x86固件和img转vmdk工具复制到此目录。
- 打开img转vmdk工具将img转为vmdk
1.开始安装openwrt
和安装其他虚拟机没有什么区别,有几处需要注意的地方我已经在图中标记出来了。
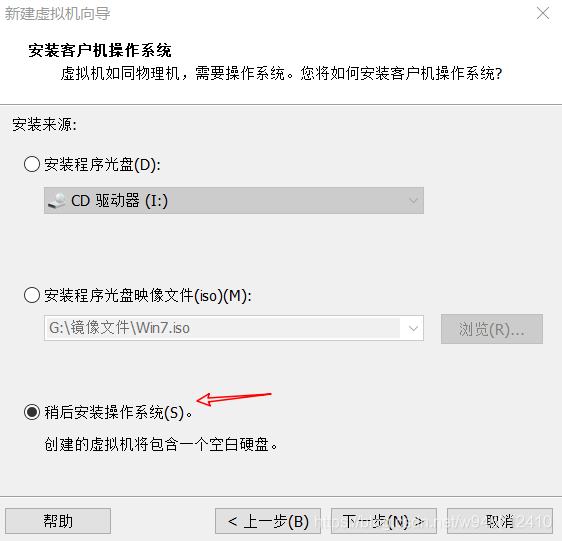
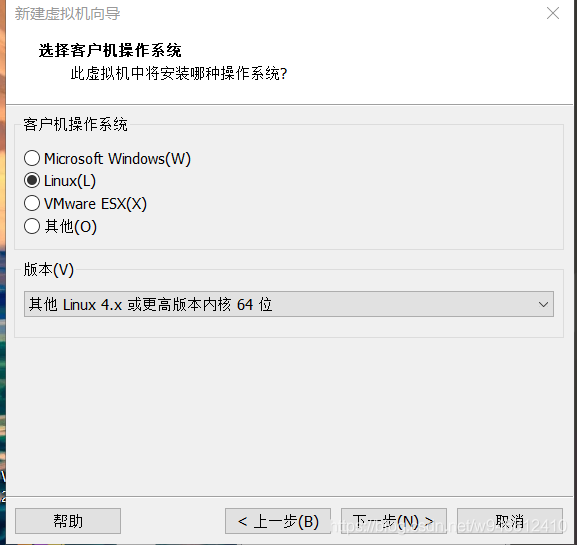
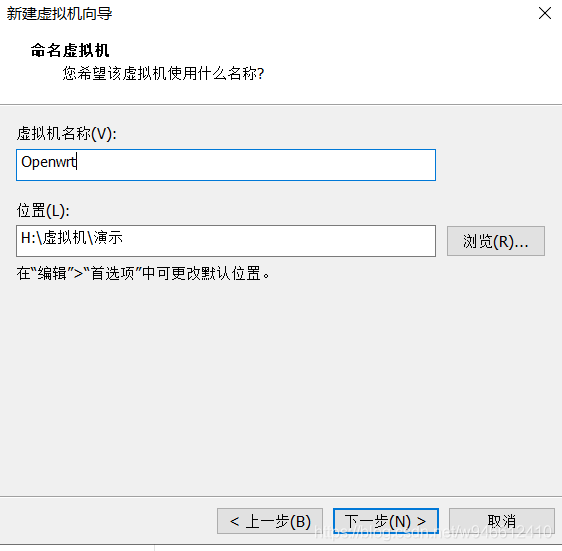
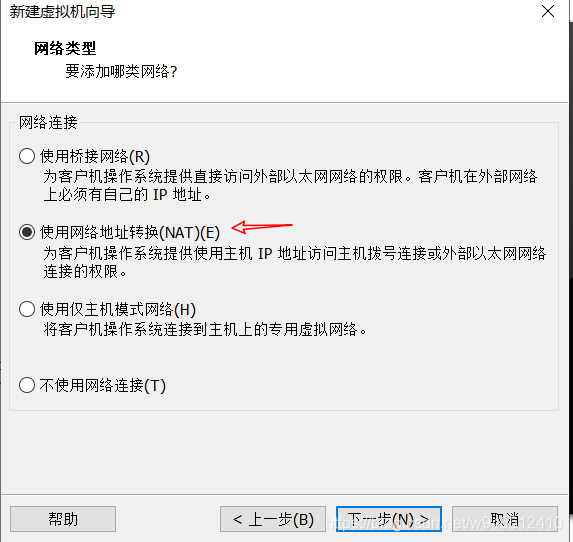
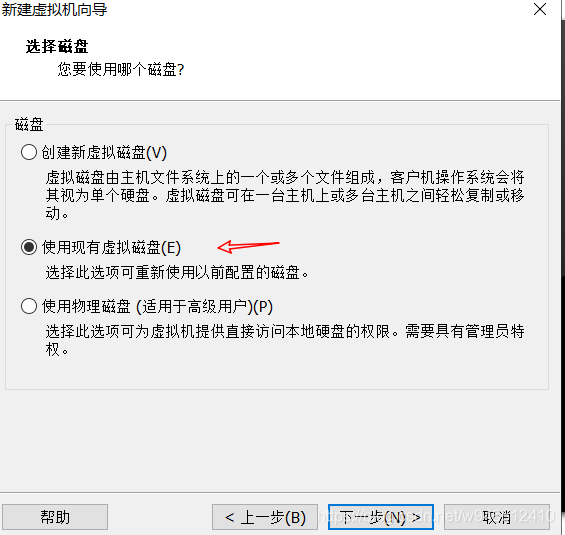
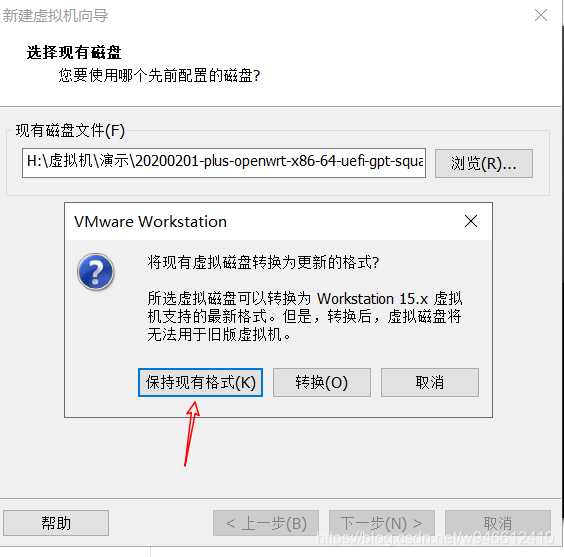
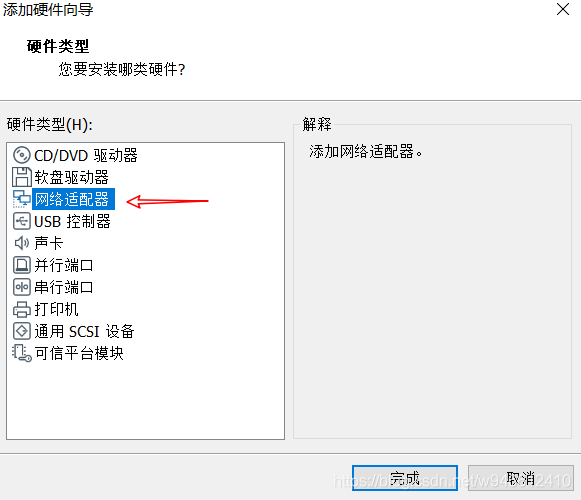
注意:****第一个网口选择LAN区段1
第二个网口选择NAT模式,(PS:Openwrt默认将第一个网口设置为lan口)。
2.配置openwrt
开启openwrt并编辑网卡:
vi /etc/config/network
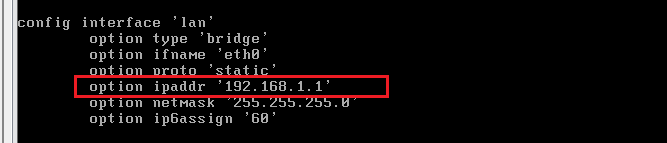
修改成你想的网关,注意不能设置成和虚拟机NAT一样的网段。不修改默认就行
修改密码:
passwd root
输入你的密码
再次输入
重启网络:
/etc/init.d/network restart
注意:以后虚拟机上网的话,需要将你其他的虚拟机加入到LAN区段。例如我们在ununtu上进行管理并添加节点:
unubtu获取到了openwrt分配的地址。
基于consul搭建:
使用ubuntu20.04测试
1、修改两个主机的主机名
主机1:
[root@localhost ~]# hostnamectl set-hostname server1
主机2:
[root@localhost ~]# hostnamectl set-hostname server2
2、拉取consul镜像并启动
主机1:
[root@server1 ~]# docker pull consul
[root@server1 ~]# docker run -d --restart always -p 8500:8500 -h consul --name consul consul
--restart=always参数能够使我们在重启docker时,自动启动相关容器。
查看是否启动成功
http://192.168.72.139:8500/ui/dc1/overview/server-status
2、将docker加入到consul并重新启动docker
主机1
[root@server1 ~]#vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --cluster-store=consul://192.168.72.139:8500 --cluster-advertise=ens33:2376
:wq
--sluster-store=consul:// #consul服务端的地址
--cluster-advertise= #自己的连接地址
systemctl daemon-reload
systemctl restart docker
主机2:
vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --cluster-store=consul://192.168.72.139:8500 --cluster-advertise=ens33:2376
:wq
systemctl daemon-reload
systemctl restart docker
3、查看两台主机是否加入到了consul
http://192.168.72.139:8500/ui/dc1/kv/docker/nodes/
如果没有请添加防火墙规则或关闭防火墙

4、开启俩台主机网卡的混杂模式
root@server1:~# apt-get install -y net-tools
ifconfig ens33 promisc
5、server1创建overlay网络并查看且是否进行了同步
[root@server1 ~]# docker network create --driver overlay --attachable overlay-net
通过“--attachable” 参数声明当前创建的overlay网络可以被container直接加入。
或者可以自定义子网:
docker network create --driver overlay --subnet=192.168.1.0/24 --gateway 192.168.1.1 --ip-range 192.168.1.10/24 --attachable overlay-net
--ip-range:定义开始分配ip地址的范围。注意L这个子网不能和宿主机处于同一网段
[root@server1 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
d88b01a3e6b5 bridge bridge local
f207caf75172 host host local
0f93b639ce19 none null local
7520c6722809 overlay-net overlay global
[root@server2 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
2ec6ce651639 bridge bridge local
d056cef19eee host host local
060dd76b27fc none null local
7520c6722809 overlay-net overlay global
6、运行容器进行测试:
等server1创建完成后容器在进行执行server2命令
server1:
[root@server1 ~]# docker run -dit --name box1 --net=overlay-net busybox
server2:
[root@server2 ~]# docker run -dit --name box2 --net=overlay-net busybox
我们在创建容器后查看执行以下命令:
[root@server1:~# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.024251705d99 no veth1a99b02
docker_gwbridge 8000.0242416db558 no veth8722f12
[root@server1 ~]# ip add
root@server1:~# ip add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:ff:9e:4f brd ff:ff:ff:ff:ff:ff
altname enp2s1
inet 192.168.72.139/24 brd 192.168.72.255 scope global dynamic noprefixroute ens33
valid_lft 913sec preferred_lft 913sec
inet6 fe80::de34:d893:8756:ae25/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:51:70:5d:99 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:51ff:fe70:5d99/64 scope link
valid_lft forever preferred_lft forever
7: veth1a99b02@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 0e:3c:27:a4:fa:b9 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::c3c:27ff:fea4:fab9/64 scope link
valid_lft forever preferred_lft forever
12: docker_gwbridge: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:41:6d:b5:58 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/16 brd 172.18.255.255 scope global docker_gwbridge
valid_lft forever preferred_lft forever
inet6 fe80::42:41ff:fe6d:b558/64 scope link
valid_lft forever preferred_lft forever
14: veth8722f12@if13: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker_gwbridge state UP group default
link/ether 06:7a:4d:24:ee:aa brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet6 fe80::47a:4dff:fe24:eeaa/64 scope link
valid_lft forever preferred_lft forever
可以看到多了一个docker_gwbridge 桥接网卡,其中veth1a99b02是consul的网卡,veth8722f12就是box1的网卡。我们进入到box容器查看ip:
root@server1:~# docker exec -it box1 sh
/ # ip add
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
10: eth0@if11: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue
link/ether 02:42:0a:00:00:02 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.2/24 brd 10.0.0.255 scope global eth0
valid_lft forever preferred_lft forever
13: eth1@if14: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.2/16 brd 172.18.255.255 scope global eth1
valid_lft forever preferred_lft forever
可以看到eth1和宿主机的docker_gwbridge网桥在一个网段,且13和14是一对,且brctl show显示的和ip add显示的都是veth8722f12。说明veth8722f12桥接到了docker_gwbridge网桥上。我们可以查看下路由表:
root@server1:~# ip route
default via 192.168.72.2 dev ens33 proto dhcp metric 100
169.254.0.0/16 dev ens33 scope link metric 1000
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
172.18.0.0/16 dev docker_gwbridge proto kernel scope link src 172.18.0.1
192.168.72.0/24 dev ens33 proto kernel scope link src 192.168.72.139 metric 100
可以看到172.18.0.0/16的数据都转发到172.18.0.1(docker_gwbridge)网关上,我们在查看box1的路由信息。
root@server1:~# docker exec -it box1 ip route
default via 172.18.0.1 dev eth1
10.0.0.0/24 dev eth0 scope link src 10.0.0.2
172.18.0.0/16 dev eth1 scope link src 172.18.0.2
所谓覆盖形网络就是由两个网卡,一个连接物理机的网卡(172.18),一个在它之上在建一个网络(10.0).还有两个box容器eth1的ip地址都是一样的,这是用因为:
root@server1:~# docker network ls
NETWORK ID NAME DRIVER SCOPE
e1c9d45f9f90 docker_gwbridge bridge local
43a737e0b246 overlay-net overlay global
这个 docker_gwbridge 只在本地生效,它只是作为连接宿主机网络,并不存在于宿主机的其他网络中。
测试两台主机是否可以通信
root@server1:~# docker exec -it box1 ping box2
PING box2 (10.0.0.3): 56 data bytes
64 bytes from 10.0.0.3: seq=0 ttl=64 time=0.708 ms
64 bytes from 10.0.0.3: seq=1 ttl=64 time=2.893 ms
64 bytes from 10.0.0.3: seq=2 ttl=64 time=0.874 ms
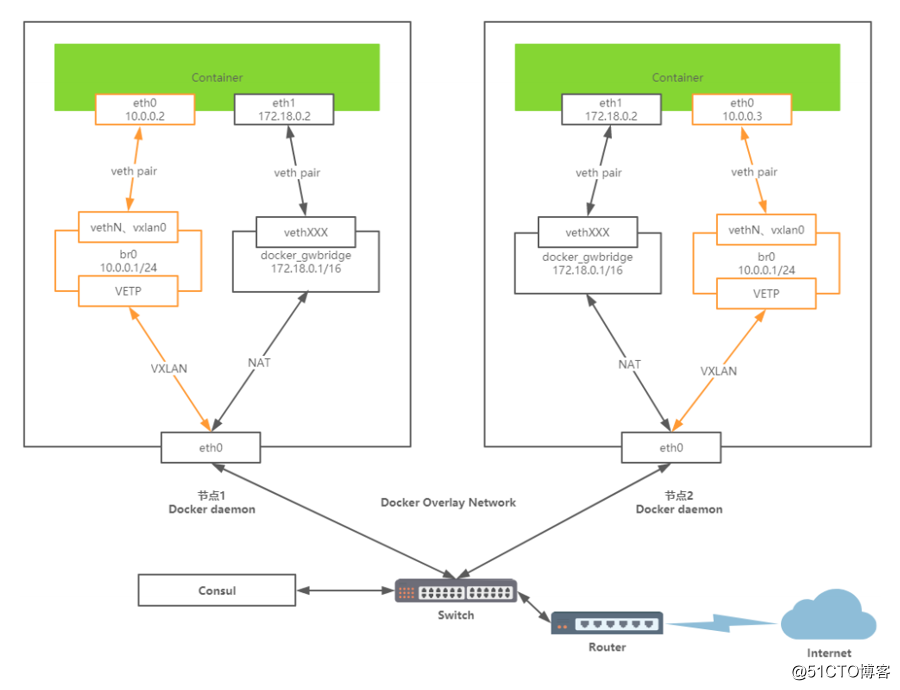
容器Container1会通过Container eth0 将这个数据包发送到 10.0.0.1 的网关。
网关将数据包发送出去后到达br0网桥。
br0网桥针对VXLAN设备,主要用于捕获对外的数据包通过VETP进行数据包封装。
封装好将VXLAN格式数据包交给eth0,通过UDP方式交给Container2的eth0。
Container2收到数据包后通过VETP将数据包解封装。
网桥通过网关将解封装的数据包转发给Container eth0,完毕通信。
因此,Docker容器的overlay网络的实现原理是:
1、docker会为每个overlay网络创建个单独的命名空间,在这个命名空间里创建了个br0的bridge。
2、在这个命名空间内创建两张网卡并挂载到br0上,创建一对veth pair端口 和vxlan设备。
3、veth pair一端接在namespace的br0上,另一端接在container上。
4、vxlan设备用于建立vxlan tunnel,vxlan端口的vni由docker-daemon在创建时分配,具有相同vni的设备才能通信。
5、docker主机集群通过key/value存储(我们这里用的是consul)共享数据,在7946端口上,相互之间通过gossip协议学习各个宿主机上运行了哪些容器。守护进程根据这些数据来在vxlan设备上生成静态MAC转发表。
6、vxlan设备根据静态mac转发表,通过host上的4789端口将数据发到目标节点。
7、根据流量包中的vxlan隧道ID,将流量转发到对端宿主机的overlay网络的网络命名空间中。
8、对端宿主机的overlay网络的网络命名空间中br0网桥,起到虚拟交换机的作用,将流量根据MAC地址转发到对应容器内部。
使用swarm测试(centos)
1、主机1初始化swarm环境
[root@server1 ~]# docker swarm init
Swarm initialized: current node (y9q4pcnsspaozkxtbjhnz4de9) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-251poh7tef8d6efnpleg3cmvrmlvbmwammjtxlzbplf88xqbvb-9apnvsc0tyqc6bixznrm8gsn0 192.168.72.130:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
启动docker swarm之后可以在host上看到启动了2个端口:2377和7946,2377作为cluster管理端口,7946用于节点发现。swarm的overlay network会用到3个端口,由于此时没有创建overlay network,故没有4789端口(注:4789端口号为IANA分配的vxlan的UDP端口号)。
[root@server1 ~]# netstat -ntpl
tcp6 0 0 :::2377 :::* LISTEN 1363/dockerd
tcp6 0 0 :::7946 :::* LISTEN 1363/dockerd
[root@server1 ~]#
2、配置防火墙规则:
两个都配:
firewall-cmd --zone=public --add-port=2377/tcp --permanent
firewall-cmd --zone=public --add-port=7946/tcp --permanent
firewall-cmd --zone=public --add-port=7946/udp --permanent
firewall-cmd --zone=public --add-port=4789/tcp --permanent
firewall-cmd --zone=public --add-port=4789/udp --permanent
firewall-cmd --reload
或者可以关闭防火墙
3、主机2加入到swarm,同时该节点上也会打开一个7946端口,与swarm服务端通信。
使用server1创建出来的:
docker swarm join --token SWMTKN-1-251poh7tef8d6efnpleg3cmvrmlvbmwammjtxlzbplf88xqbvb-9apnvsc0tyqc6bixznrm8gsn0 192.168.72.130:2377
查看server1查看节点信息,
[root@server1 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
y9q4pcnsspaozkxtbjhnz4de9 * server1 Ready Active Leader 20.10.14
x4xx9vfji9b1vttlqg94iq7vd server2 Ready Active 20.10.14
查看网络信息,可以发现新增了如下网络,docker_gwbridge和ingress,前者提供通过bridge方式提供容器与host的通信,后者在默认情况下提供通过overlay方式与其他容器跨host通信
[root@server1 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
fd9160b2c501 docker_gwbridge bridge local
rxg5ud7wl5vo ingress overlay swarm
4、server1创建自定义网络
[root@localhost ~]# docker network create --driver overlay --attachable overlay-net
oa5oxdrfe8jibpy2h99r3pmm0
5、创建容器测试:
主机1:
docker run -dit --name box1 --net=overlay-net busybox
主机2:
docker run -dit --name box2 --net=overlay-net busybox
查看两个容器的IP地址
主机1:
[root@localhost ~]# docker exec -it box1 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
16: eth0@if17: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue
link/ether 02:42:0a:00:01:02 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.2/24 brd 10.0.1.255 scope global eth0
valid_lft forever preferred_lft forever
18: eth1@if19: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:12:00:03 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.3/16 brd 172.18.255.255 scope global eth1
valid_lft forever preferred_lft forever
主机2:
[root@localhost ~]# docker exec -it box2 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
22: eth0@if23: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue
link/ether 02:42:0a:00:01:04 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.4/24 brd 10.0.1.255 scope global eth0
valid_lft forever preferred_lft forever
24: eth1@if25: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:12:00:03 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.3/16 brd 172.18.255.255 scope global eth1
valid_lft forever preferred_lft forever
主机1ping主机2:
[root@localhost ~]# docker exec -it box1 ping box2
PING box2 (10.0.1.4): 56 data bytes
64 bytes from 10.0.1.4: seq=0 ttl=64 time=1.492 ms
64 bytes from 10.0.1.4: seq=1 ttl=64 time=1.161 ms
64 bytes from 10.0.1.4: seq=2 ttl=64 time=3.304 ms
64 bytes from 10.0.1.4: seq=3 ttl=64 time=2.754 ms
查看server2上box2容器的网络信息,可以看到overlay网络的接口为eth0,它对应的对端网卡编号为22;eth1对应的对端网卡编号为24,对应的网卡即为host上的vetha98af8d。该网卡连接的网桥就是docker_gwbridge。
[root@localhost ~]# docker exec -it box2 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
22: eth0@if23: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1450 qdisc noqueue
link/ether 02:42:0a:00:01:04 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.4/24 brd 10.0.1.255 scope global eth0
valid_lft forever preferred_lft forever
24: eth1@if25: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:12:00:03 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.3/16 brd 172.18.255.255 scope global eth1
valid_lft forever preferred_lft forever
[root@localhost ~]# ip a
18: veth9d6f0a7@if17: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker_gwbridge state UP
link/ether 9a:b3:1c:4e:74:e4 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::98b3:1cff:fe4e:74e4/64 scope link
valid_lft forever preferred_lft forever
box2的eth1对应的网卡即为host上的 veth9d6f0a7,
25: vetha98af8d@if24: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker_gwbridge state UP
link/ether be:f3:28:9f:ee:6c brd ff:ff:ff:ff:ff:ff link-netnsid 3
inet6 fe80::bcf3:28ff:fe9f:ee6c/64 scope link
valid_lft forever preferred_lft forever
overlay的网络通CT22容器的eth0流出,那eth0对应的对端网卡在哪里?由于box2连接到名为my-overlay的网络,在/var/run/docker/netns下查看该网络对应的namespace,可以看到eth0对应该my-overlay的veth1,且它们连接到bridge br0
[root@localhost ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
83764e8a8208 bridge bridge local
042064b49d09 docker_gwbridge bridge local
d056cef19eee host host local
qski6sk84myc ingress overlay swarm
060dd76b27fc none null local
oa5oxdrfe8ji overlay-net overlay swarm
[root@localhost ~]# ll /var/run/docker/netns/
总用量 0
-r--r--r--. 1 root root 0 5月 5 11:23 1-oa5oxdrfe8
-r--r--r--. 1 root root 0 5月 5 11:21 1-qski6sk84m
-r--r--r--. 1 root root 0 5月 5 11:23 7ec59b2eebed
-r--r--r--. 1 root root 0 5月 5 11:21 ingress_sbox
-r--r--r--. 1 root root 0 5月 5 11:23 lb_oa5oxdrfe
[root@localhost ~]# cd /var/run/docker/netns/
[root@localhost netns]# nsenter --net=1-oa5oxdrfe8 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP
link/ether 02:cf:5d:ef:c2:6b brd ff:ff:ff:ff:ff:ff
inet 10.0.1.1/24 brd 10.0.1.255 scope global br0
valid_lft forever preferred_lft forever
19: vxlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UNKNOWN
link/ether 02:cf:5d:ef:c2:6b brd ff:ff:ff:ff:ff:ff link-netnsid 0
21: veth0@if20: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UP
link/ether 9a:58:66:16:91:02 brd ff:ff:ff:ff:ff:ff link-netnsid 1
23: veth1@if22: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UP
link/ether d2:38:33:ae:ba:3d brd ff:ff:ff:ff:ff:ff link-netnsid 2
[root@localhost netns]# nsenter --net=1-oa5oxdrfe8 ip link show master br0
19: vxlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UNKNOWN mode DEFAULT
link/ether 02:cf:5d:ef:c2:6b brd ff:ff:ff:ff:ff:ff link-netnsid 0
21: veth0@if20: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UP mode DEFAULT
link/ether 9a:58:66:16:91:02 brd ff:ff:ff:ff:ff:ff link-netnsid 1
23: veth1@if22: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UP mode DEFAULT
link/ether d2:38:33:ae:ba:3d brd ff:ff:ff:ff:ff:ff link-netnsid 2
这样overlay在box2上的报文走向如下,所有的容器使用bridge方式直接连接在默认的docker_gwbridge上,而overlay方式通过在my-overlay上的br0进行转发。这样做的好处是,当在一个host上同时运行多个容器的时候,仅需要一个vxlan的udp端口即可,所有的vxlan流量由br0转发。
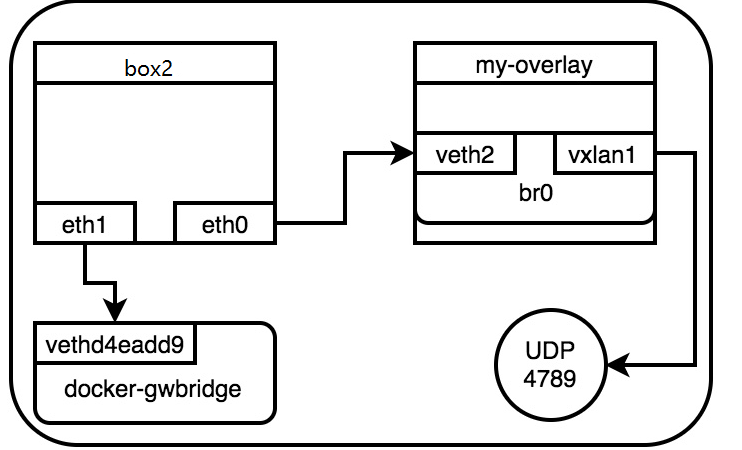
br0的vxlan(该vxlan是由swarm创建的)会在host上开启一个4789的端口,报文过该端口进行跨主机传输.
[root@localhost ~]# netstat -anup
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
udp 0 0 0.0.0.0:4789 0.0.0.0:*
二、DockerMacvlan 方案
macvlan 驱动程序是经过检验的真正网络虚拟化技术的新实现。Linux 上的实现非常轻量级,因为它们不是使用 Linux 网桥进行隔离,而是简单地与 Linux 以太网接口或子接口相关联,以强制实现网络之间的分离以及与物理网络的连接。
macvlan 驱动程序使用父接口的概念。此接口可以是物理接口,例如 eth0,用于 802.1q VLAN 标记的子接口,如 eth0.10(.10 表示 VLAN 10),或者甚至是绑定的主机适配器,它将两个以太网接口捆绑到一个逻辑接口中。
在 MACVLAN 网络配置期间需要网关地址。网关必须位于网络基础架构提供的主机外部。MACVLAN 网络允许在同一网络上的容器之间进行访问。如果没有在主机外部路由,则无法在同一主机上的不同 MACVLAN 网络之间进行访问。 可以将MACVLAN认为是单臂路由实验
相同macvlan网络之间通信
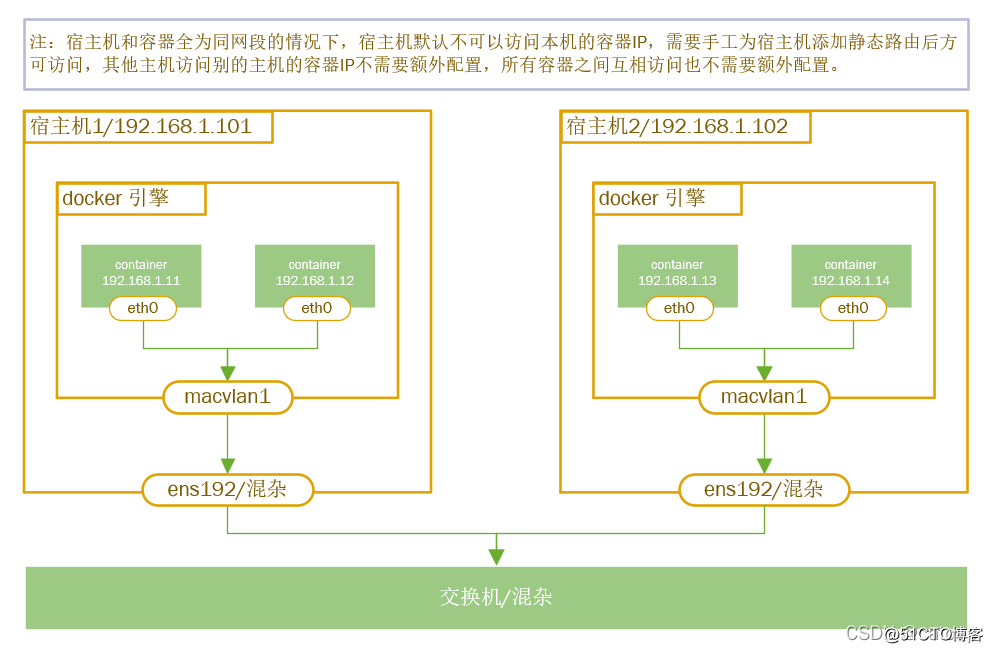
1、两台node创建连个macvlan网络
ns1:
[root@ns1 ~]# docker network create -d macvlan --subnet=172.16.10.0/24 --gateway=172.16.10.1 -o parent=ens33 mac1
ns2:
[root@ns2 ~]# docker network create -d macvlan --subnet=172.16.10.0/24 --gateway=172.16.10.1 -o parent=ens33 mac1
其中:
-d 指定 Docker 网络 driver
--subnet 指定 macvlan 网络所在的网络
--gateway 指定网关
-o parent 指定用来分配 macvlan 网络的物理网卡
查看创建的网络:
[root@ns2 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
53949d70eeb5 bridge bridge local
d056cef19eee host host local
f7d56581fcb7 mac1 macvlan local
060dd76b27fc none null local
2、在 node1 运行容器 c1,并指定使用 macvlan 网络:
docker run -itd --name c1 --ip=172.16.10.2 --network mac1 busybox
--ip 指定容器 c1 使用的 IP,这样做的目的是防止自动分配,造成 IP 冲突
--network 指定 macvlan 网络
3、 在node2 中运行容器 c2:
docker run -itd --name c2 --ip=172.16.10.3 --network mac1 busybox
4、在node1 c1中ping node2 c2,可通
[root@ns1 ~]# docker exec -it c1 ping 172.16.10.3
PING 172.16.10.3 (172.16.10.3): 56 data bytes
64 bytes from 172.16.10.3: seq=0 ttl=64 time=2.225 ms
64 bytes from 172.16.10.3: seq=1 ttl=64 time=3.462 ms
64 bytes from 172.16.10.3: seq=2 ttl=64 time=0.843 ms
64 bytes from 172.16.10.3: seq=3 ttl=64 time=2.339 ms
1、两边节点分别创建macvlan网络,并创建子网段。
2、docker0网卡会通过NET去访问网络
3、容器内的eth0是由macvlan所在物理接口ens33创建的一个逻辑网口。
4、当节点1向节点2发送数据包时,容器内的子网网卡会向它的网关发送一个mac地址请求。
5、虚拟网关接受请求后会先查询本地的路由表查找发送目标,如果找不到它会转交给eth1来发ARP送广播,来获取目标IP地址是多少。
6、节点2收到ARP广播后它会查找本地是否存在目标IP地址,通过IP来获取自定IP的mac地址。
7、获取mac地址后它会转发给eth0真机网卡,然后通过宿主级网卡发送给节点1的外网网卡,然后再转给容器内网卡。
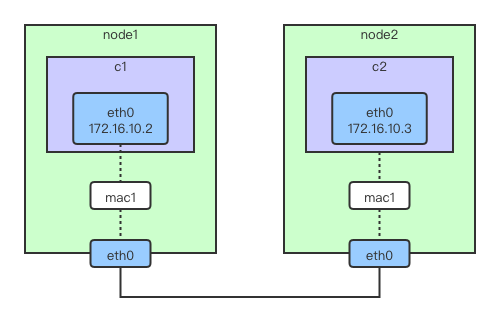
不同mancvlan网络之间的通信
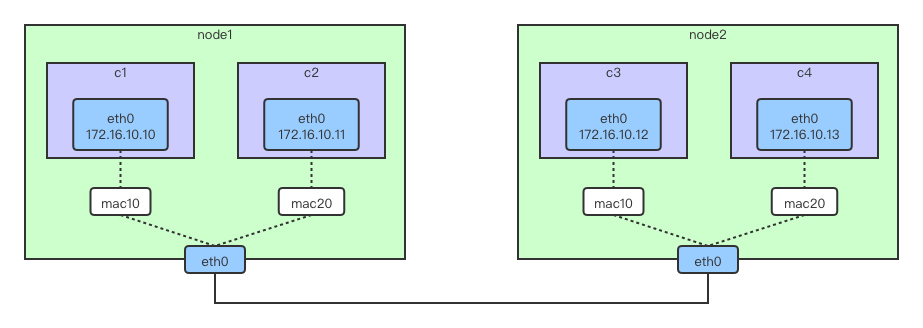
1、安装依赖
配置vlan需要vconfig命令,由于centos7上没有自带vconfig命令,所以需要安装vconfig
1、配置epel源:
[root@localhost ~]# yum install epel-release -y
2、安装vconfig:
[root@localhost ~]# yum install vconfig -y
3、加载modprobe 8021q模块
[root@localhost ~]# modprobe 8021q
4、开启转发
vim /etc/sysctl.d/99-sysctl.conf
net.ipv4.ip_forward=1
:wq
[root@localhost ~]# sysctl -p
net.ipv4.ip_forward = 1
5、开启网卡混杂模式
ifconfig ens33 promisc
2、分别在两台主机上将物理接口ens33创建两个VLAN子接口
[root@localhost ~]# vconfig add ens33 10
Added VLAN with VID == 10 to IF -:ens33:-
[root@localhost ~]# vconfig add ens33 20
Added VLAN with VID == 20 to IF -:ens33:-
设置 VLAN 的 REORDER_HDR 参数,默认就行了
[root@localhost ~]# vconfig set_flag ens33.10 1 1
Set flag on device -:ens33.10:- Should be visible in /proc/net/vlan/ens33.10
[root@localhost ~]# vconfig set_flag ens33.20 1 1
Set flag on device -:ens33.20:- Should be visible in /proc/net/vlan/ens33.20
启用接口
[root@localhost ~]# ifconfig ens33.10 up
[root@localhost ~]# ifconfig ens33.20 up
3、分别在两台主机上基于两个VLAN子接口创建两个macvlan网络:mac10和mac20
[root@localhost ~]# docker network create -d macvlan --subnet=172.16.10.0/24 --gateway=172.16.10.1 -o parent=ens33.10 mac10
25cb085f82961b8dfbd0c2b20247b48ecbbae77f14c0d08e48374cc6fa009a79
[root@localhost ~]# docker network create -d macvlan --subnet=172.16.20.0/24 --gateway=172.16.20.1 -o parent=ens33.20 mac20
3ce05325a4f2241c5f5829523f9489151697f938f3e7e4a75a1161ed1a9aa048
[root@localhost ~]#
4、分别在 node1 和 node2 上运行容器,并指定不同的 macvlan 网络
// host1
# docker run -itd --name c1 --ip=172.16.10.10 --network mac10 busybox
# docker run -itd --name c2 --ip=172.16.20.11 --network mac20 busybox
// host2
# docker run -itd --name c3 --ip=172.16.10.12 --network mac10 busybox
# docker run -itd --name c4 --ip=172.16.20.13 --network mac20 busybox
注意:
docker容器创建时会自动生成mac地址,加上docker容器很容易被我们日常性铲除重建,所以随着次数增多,会导致网络中存在大量的唯一MAC地址,可能对现有网络产生影响。所以建议在创建容器的时候手工指定MAC地址。
参数:--mac-address=D0:EE:6A:1D:3C:62 ,可以取这里在线生成http://www.metools.info/other/o66.html
如果在docker容器启动的时候不指定IP地址,则会被自动分配IP。当你为macvlan设置的网段和宿主机同一个网段的情况下,这个自动分配的IP并不是从路由器DHCP服务获取的,所以很容易出现IP冲突问题,故强烈建议当macvlan的网段和宿主机网段同网段时候要手工指定一个没有给宿主机网络已经占用的IP地址。
5、测试
c1 ping c3:
[root@localhost ~]# docker exec -it c1 ping 172.16.10.12
PING 172.16.10.12 (172.16.10.12): 56 data bytes
64 bytes from 172.16.10.12: seq=0 ttl=64 time=0.859 ms
64 bytes from 172.16.10.12: seq=1 ttl=64 time=1.442 ms
64 bytes from 172.16.10.12: seq=2 ttl=64 time=0.804 ms
c2 ping c4:
[root@localhost ~]# docker exec -it c2 ping 172.16.20.13
PING 172.16.20.13 (172.16.20.13): 56 data bytes
64 bytes from 172.16.20.13: seq=0 ttl=64 time=0.511 ms
64 bytes from 172.16.20.13: seq=1 ttl=64 time=0.920 ms
64 bytes from 172.16.20.13: seq=2 ttl=64 time=0.963 ms
使用macVLAN模式的容器,无法ping通宿主机,宿主机也无法ping通该容器,对其他同网段的服务器和容器都可以互联。
即:同一个macvlan下的网络能ping通,不同的macvlan网络之间不能通信。但是更准确的说法是:不同的macvlan网络不能在二层上通信。在三层可以通过网关进行通信.
扩展:
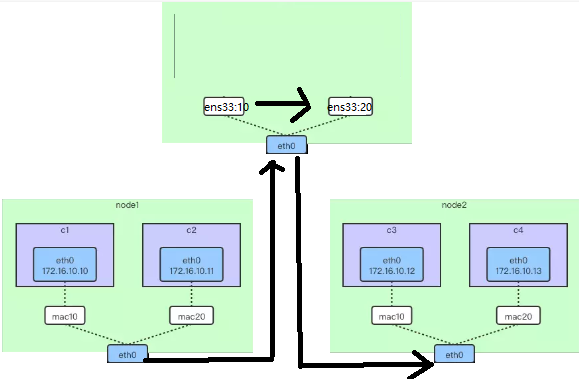
重新找一台主机 host3,通过打开 ip_forward 把它改造成一台路由器,用来打通两个 macvlan 网络,大概的图示如下所示:
6、配置不同网段进行通信
1、配置vlan需要vconfig命令,由于centos7上没有自带vconfig命令,所以需要安装vconfig
1.1、配置epel源:
[root@localhost ~]# yum install epel-release -y
1.2、安装vconfig:
[root@localhost ~]# yum install vconfig -y
1.3、加载modprobe 8021q模块
[root@localhost ~]# modprobe 8021q
1.4、开启路由转发
[root@localhost ~]# vim /etc/sysctl.d/99-sysctl.conf
net.ipv4.ip_forward = 1
:wq
[root@localhost ~]# sysctl -p
net.ipv4.ip_forward = 1
2、然后创建两个 VLAN 子接口,一个作为 macvlan 网络 mac10 的网关,一个作为 mac20 的网关。
[root@localhost ~]# vconfig add ens33 10
Added VLAN with VID == 10 to IF -:ens33:-
[root@localhost ~]# vconfig add ens33 20
Added VLAN with VID == 20 to IF -:ens33:-
[root@localhost ~]# vconfig set_flag ens33.10 1 1
Set flag on device -:ens33.10:- Should be visible in /proc/net/vlan/ens33.100
[root@localhost ~]# vconfig set_flag ens33.20 1 1
Set flag on device -:ens33.20:- Should be visible in /proc/net/vlan/ens33.200
3、对 vlan 子接口配置网关 IP 并启用
[root@localhost ~]# ifconfig ens33.10 172.16.10.1 netmask 255.255.255.0 up
[root@localhost ~]# ifconfig ens33.20 172.16.20.1 netmask 255.255.255.0 up
4、配置iptables
iptables -t nat -A POSTROUTING -o ens33.10 -j MASQUERADE
iptables -t nat -A POSTROUTING -o ens33.20 -j MASQUERADE
iptables -A FORWARD -i ens33.10 -o ens33.20 -m state --state RELATED,ESTABLISHED -j ACCEPT
iptables -A FORWARD -i ens33.20 -o ens33.10 -m state --state RELATED,ESTABLISHED -j ACCEPT
iptables -A FORWARD -i ens33.10 -o ens33.20 -j ACCEPT
iptables -A FORWARD -i ens33.20 -o ens33.10 -j ACCEPT
5、测试:
同主机下的两个网段
[root@localhost ~]# docker exec -it c2 ping 172.16.10.10
PING 172.16.10.10 (172.16.10.10): 56 data bytes
64 bytes from 172.16.10.10: seq=0 ttl=63 time=1.174 ms
^C
--- 172.16.10.10 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 1.174/1.174/1.174 ms
跨主机的不同网段:
[root@localhost ~]# docker exec -it c1 ping 172.16.20.13
PING 172.16.20.13 (172.16.20.13): 56 data bytes
64 bytes from 172.16.20.13: seq=0 ttl=63 time=1.861 ms
为什么配置 VLAN 子接口,配上 IP 就可以通了,我们可以看下路由表就知道了。
首先看容器 c1 的路由:
[root@localhost ~]# docker exec -it c1 ip r
default via 172.16.10.1 dev eth0
172.16.10.0/24 dev eth0 scope link src 172.16.10.10
我们在创建容器的时候指定了网关 172.16.10.1,所以数据包自然会被路由到 host3 的接口。
再来看下 host3 的路由:
[root@localhost ~]# ip r
default via 192.168.1.1 dev ens33 proto static metric 100
172.16.10.0/24 dev ens33.10 proto kernel scope link src 172.16.10.1
172.16.20.0/24 dev ens33.20 proto kernel scope link src 172.16.20.1
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
192.168.1.0/24 dev ens33 proto kernel scope link src 192.168.1.165 metric 100
192.168.122.0/24 dev virbr0 proto kernel scope link src 192.168.122.1
可以看到,去往 172.16.10.0/24 网段的数据包会从 ens33.10 出去,同理 172.16.20.0/24 网段也是,再加上 host3 的 ip_forward打开,这就打通了两个 macvlan 网络之间的通路。
(3)、外部方案
一、flannel的UDP与VXLAN与host-gw
在介绍flannel网络实现方案之前,先回顾下docker网络实现方案。
docker网络模式有bridge、host、none。新版本docker出现了macvlan、overlay跨主机网络通信方案。
桥接模式的实现:首先docker在默认安装的情况下,启动后会默认建立docker0 linux网桥设备,该网桥设备拥有一个私有网络地址及子网,通常使用子网中第一个没有被占用的地址。例如:127.17.0.1,然后docker容器在启动的时候会连接到网桥设备上,并分配一个子网地址。容器连接到网桥的网络接口会把docker0设备作为网关。创建容器时,docker会创建一对网络设备接口,并把它们放到独立命名的空间中:一个网络设备放到容器的网络命名空间中例如eth0,另一个网络设备会放到宿主机的网络命名空间中。例如vethXXXXXX,并连接到docker0网桥设备上。所以如果仔细观察容器内部网卡设备信息和宿主机的网卡信息。会发现这一对网络设备是一一对应的。当然宿主机上其它容器也会连接到docker0网桥设备上,这样就实现了宿主机内容器的通信;
flannel三层网络实现方式:
需求:
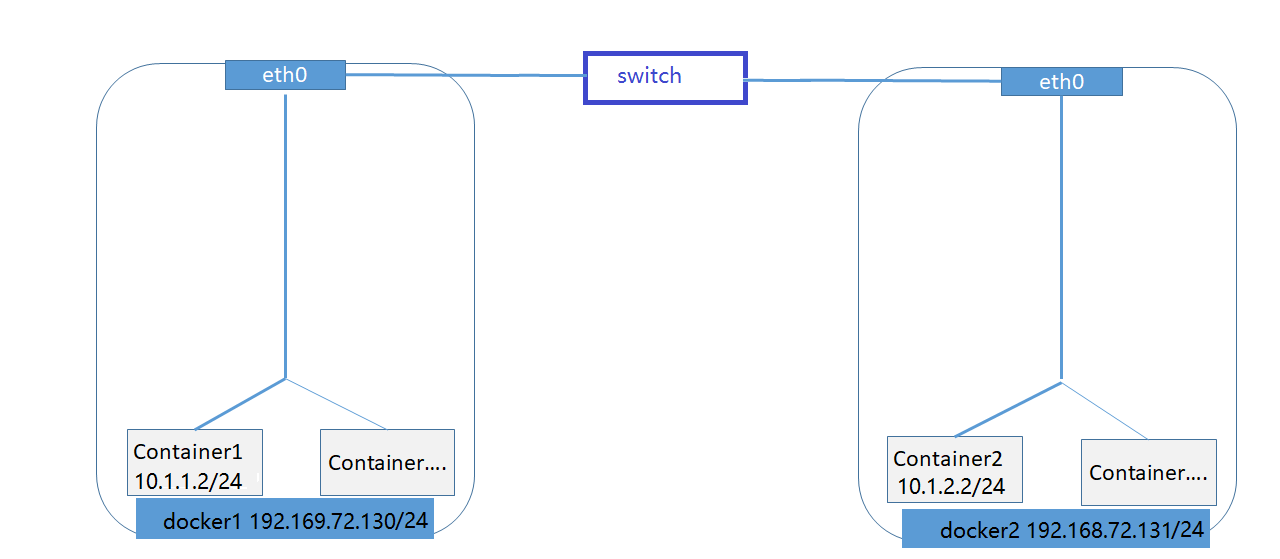
docker1(192.168.72.130)上的container1(10.1.1.2)需要跨主机访问docker2(192.168.72.131)上的container2(10.1.2.2)。对于flannel是如何实现的?
UDP跨主机通信方式:(已废弃)
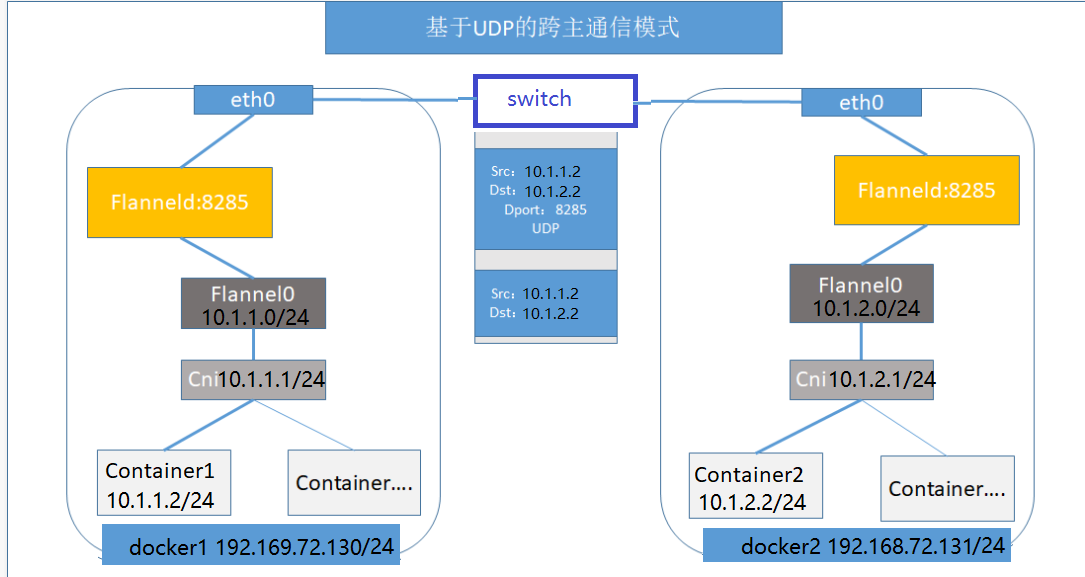
如上图所示:首先flannel会在各个节点上创建路由规则,这些路由规则存储在etcd中,跟宿主机节点IP一一对应。然后在docker1上,container1跨主机访问docker2上的container2,因为container2的IP地址为10.1.2.2,根据路由规则,从而进入到flannel0设备中。最后flannel0看到container1要访问的IP地址为10.1.2.2的容器,因为flannel在etcd中存储着子网和宿主机IP的对应关系,所以能够找到10.1.2.2对应的宿主机IP为192.168.72.131,进而开始组装UDP数据包发送到目的主机。当然这个请求得以完成的原因是每个节点上都启动一个flannel udp进程,都监听着8285端口,所以docker1通过flanneld进程吧数据包发送给docker2的flanneld进程的相应端口即可。
可以看出flannel UDP模式提供了一个三层OverLay网络,这就好比在不同宿主机的容器上打通了一条隧道,容器不用关心IP地址即可直接通信。它首先对发出端的数据包进行UDP封装,然后在接收端进行解包,进而把包发送到目的容器地址。但是这里面有一个非常严重的问题,就是flannel UDP进程运行在用户态,而数据的交互和传递则在内核态完成,这就造成了为了传递数据,需要内核态和用户态的频繁切换,这个切换过程有一定性能损耗代价,所以UDP模式已经废弃。
flannel是CoreOS公司开发的跨主机通信网络解决方案,它的主要思路是:预先留出一个网段,每个主机使用其中一部分,然后每个容器被分配不同的ip;让所有的容器认为大家在同一个直连的网络,底层通过UDP/VxLAN等进行报文的封装和转发。它会为每个host分配一个subnet,容器从这个subnet中获取IP地址,这个IP地址在各个host主机组成的集群中是全局唯一的,其框架如下:
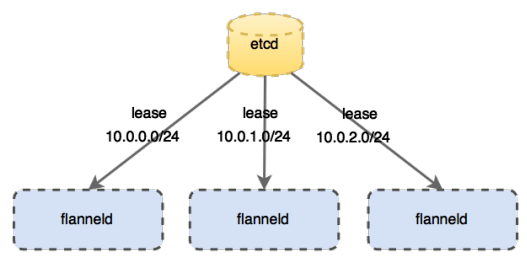
- 每个节点上有一个叫
flanneld的agent,负责为每个主机分配和管理子网; - 全局的网络配置存储
etcd负责存储主机容器子网的映射关系; - 数据包在主机之间发展是由
backend来实现的,常见的backend有VXLAN和host-gw两种模式。
VXLAN跨主机通信方式
VXLAN(虚拟可扩展局域网)
VXLAN(Virtual Extensible LAN)是一种网络虚拟化技术,中文名为虚拟扩展局域网,将链路层的以太网包封装到UDP包中进行传输,VXLAN最初是由Vmare、Cisco开发,主要解决云环境下多用户的二层网络隔离。我们常听到的公有云厂商宣称支持VPC,实际底层就是使用VXLAN实现的。
VXLAN packet的结构:
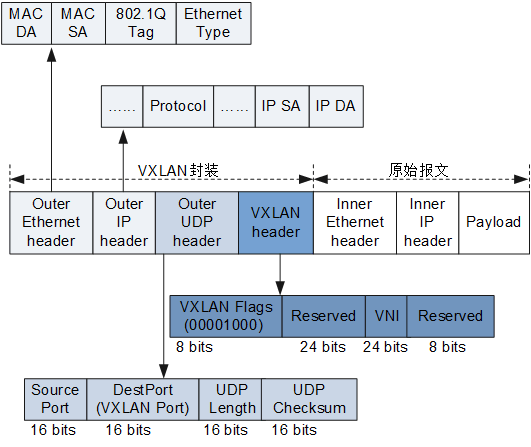
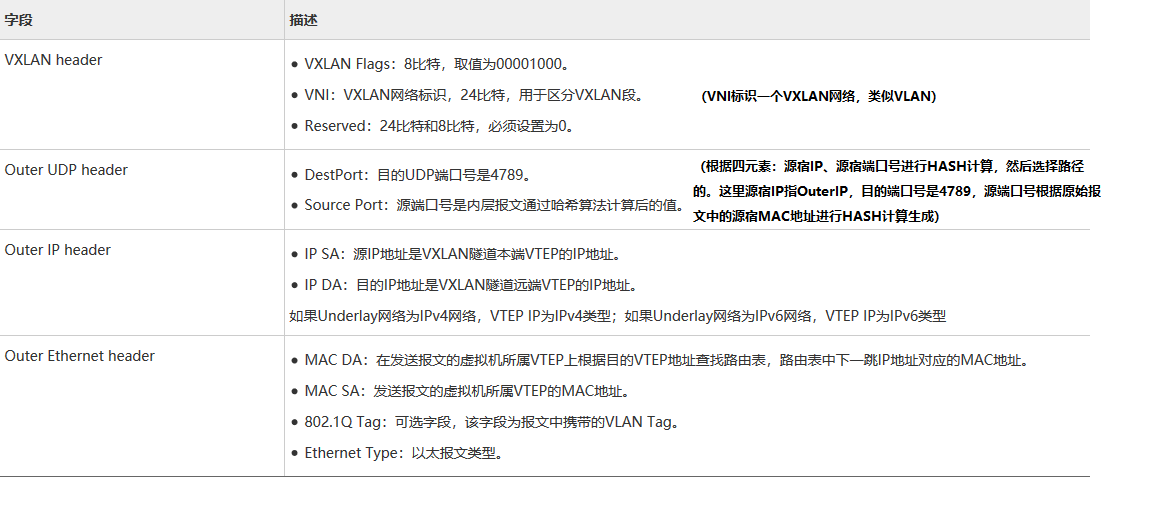
VxLAN主要解决的问题:
1、服务器虚拟化技术,允许在物理机上运行多个MAC地址各不相同的虚拟机,随着数量的增加,交换机上的MAC地址表将剧烈膨胀,甚至需要MAC覆盖。
2、数据中心多以VLAN为虚拟机划分网络,但是VLAN数量受制于VLAN(802.1Q)协议4096,这远远满足不了现实的需求。对于同网段主机的通信而言,报文通过查询MAC表进行二层转发。服务器虚拟化后,数据中心中VM的数量比原有的物理机发生了数量级的增长,伴随而来的便是虚拟机网卡MAC地址数量的空前增加。此时,处于接入侧的二层设备表示“我要Hold不住了”!
3、多租户环境的要求,其每个租户都有自己隔离的网络环境,导致物理网络中每个租户所分配的MAC地址和VLAN ID会存在重叠的可能。
4、Spanning Tree Protocol (STP)算法会产生大量多路路径冗余。
5、支持远距离虚拟机迁移,避免处理复杂的L2 (VLAN)网络环境。
6、ToR(Top of Rack) Switch链接着物理server,它记录着各个server/VM相连的MAC地址映射表。当地址映射表满时,ToR就会停止学习新的地址,这样就会导致网络泛洪,直到有记录过期被换出,腾出空闲表项。
VXLAN术语介绍:
VTEP:用于建立VXLAN隧道的端点设备称为VTEP,封装和解封装在VTEP节点上进行。他也是网络的边缘设备,是VXLAN隧道的起点和终点。
VNI:VXLAN网络标识符,占用VXLAN报头24位。一个VNI代表了一个租户,属于不同VNI的虚拟机之间不能直接进行二层通信。VXLAN报文封装时,给VNI分配了足够的空间使其可以支持海量租户的隔离。
VXLAN隧道:“VXLAN隧道”便是用来传输经过VXLAN封装的报文的,它是建立在两个VTEP之间的一条虚拟通道。
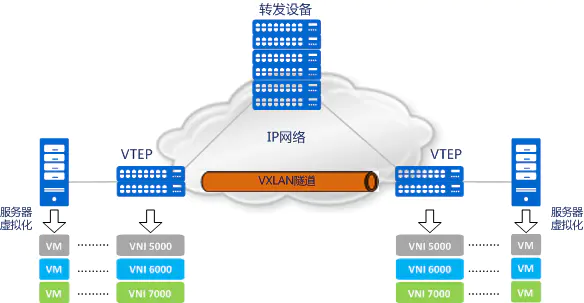
VXLAN的ARP请求过程:
VM1——VTEP1——物理交换机——VTEP2——VM2
1、VM1使用广播发送ARP请求查找VM2的MAC地址。
2、VTEP1收到VM1的广播后,查找自己的MAC地址表,如果下联终端没有将封装报文为VXLAN,内层VNI为5000,外层目的地址为VXLAN组播地址,外层源IP为VTEP1地址。
3、通过多播组VTEP2接受到VTEP1的报文,解封装后。记录报文的内层VNI、外层源VTEP1的IP、内层MAC地址。
4、VTEP2通过广播将数据包广播到自己连接的终端下面。
5、VM2接受到ARP请求后,做出回应。
6、VTEP2接受到VM2的回应后,查找流表,发现需要发送给VTEP1,重新把数据包进行封装为VXLAN并以单播的形式发送给VTEP1.
7、VTEP1收到回应后,记录内层VNI、外层源VTEP2的IP、内层VM2的MAC地址。
8、VTEP1解封装后转发给VM1。至此VM1收到了VM2的MAC地址。
数据传输过程:
1、VM1给VM2发送了一个TCP报文。
2、VTEP1收到报文后检查VM1和VM2是否属于一个VNI,(如果不属于将转发给VXLAN网关)检查后属于一个VNI,需要转发给VTEP2。
3、VTEP1封装VXLAN报文以单播的形式发送给VTEP2。
4、VTEP2收到报文后解封装,查找流表。VM2是自己下联终端。
5、VTEP2单播的形式发送给VM2,至此一个报文发送完毕。
总结:关于VXLAN的本质就一句话概括,就是将三层网络数据封装在虚拟二层网络中。通过二层互通实现三层网络不同网段IP互通,同时突破了同一个VLAN只有2049个子网的限制,VXLAN使用VNI(24 bit)来标识VXLAN网络,故而有(2^24)个子网。
VXLAN模式是Flannel默认和推荐的模式,使用VXLAN模式时,它会为每个节点分配一个24位子网 。flanneld会在宿主机host上创建一个 VTEP 设备(flannel.1)和一个网桥cni0。(flannel.1)就是VXLAN隧道的起/始点,VNI=1,实现对VXLAN报文的解封装。
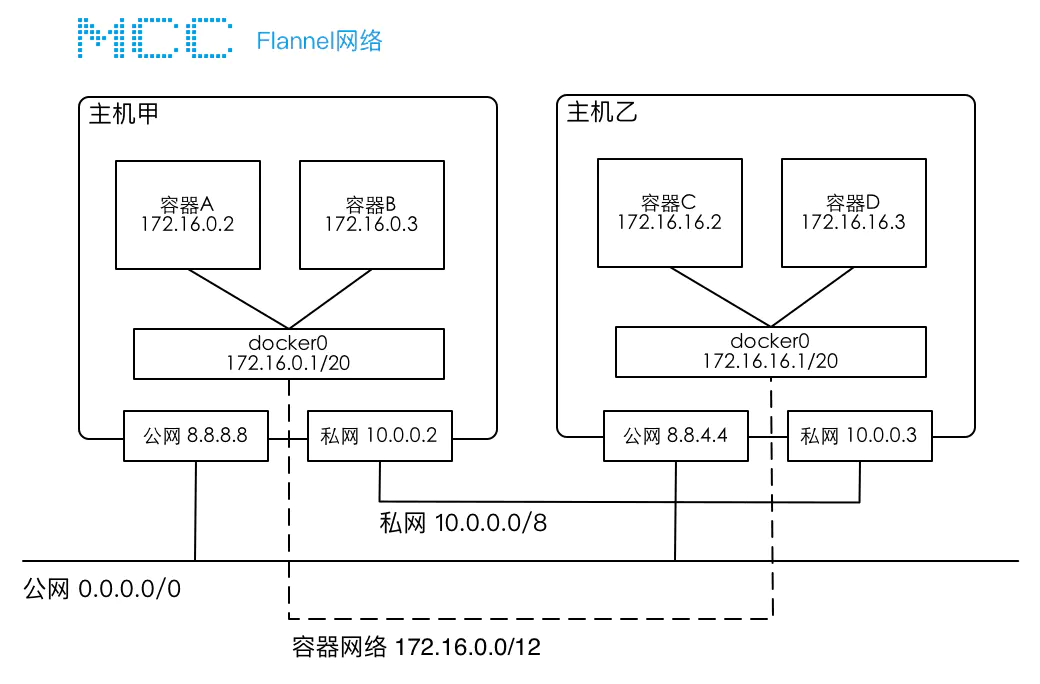
某公司有一个简单的集群网络,在该集群内,有两台服务器甲和乙,每台服务器上都有两张网卡,分别连接公网和私网,两台服务器可以通过私网进行互联,在两个服务器节点上分别安装了Docker,并且运行了A/B/C/D 4个容器。每台服务器节点上都有一个docker0网桥,这是docker启动后初始化的虚拟设备,每个容器都与docker0网桥相连且容器的IP地址由docker自动分配。
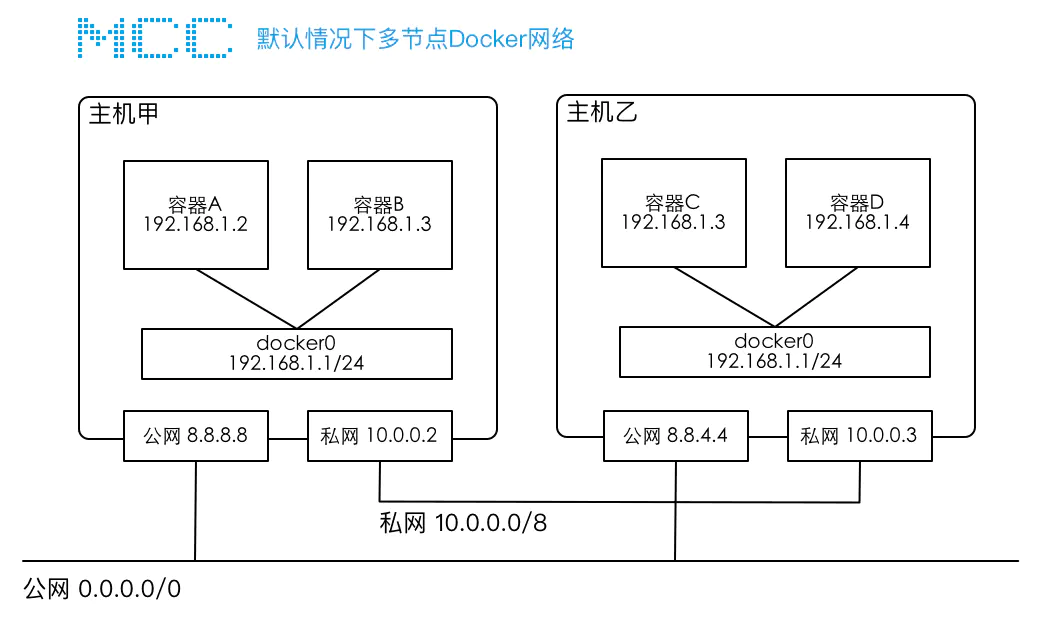
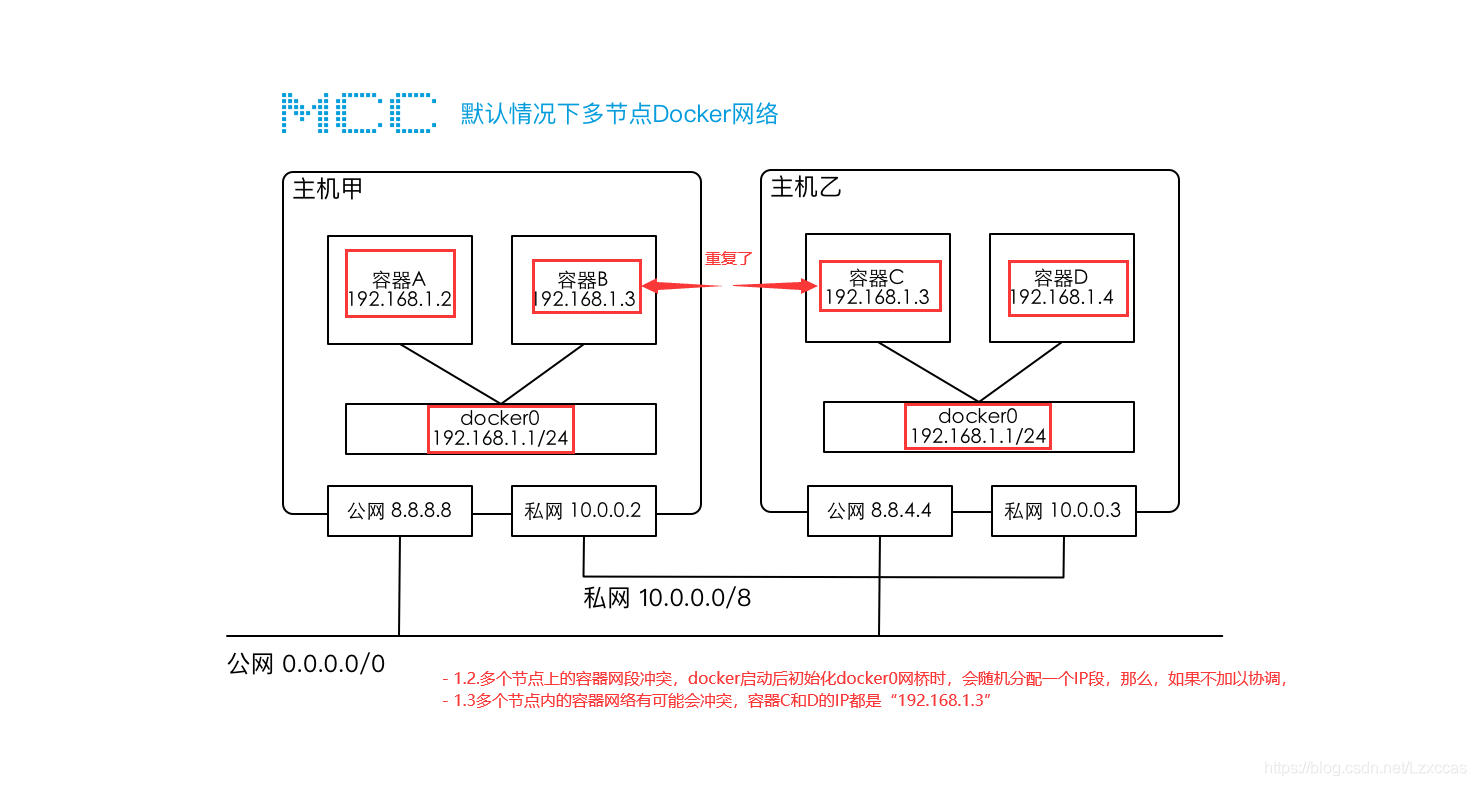
默认情况下两台主机不支持跨主机容器的互联,原因是:
- 跨主机访问容器没有有效路由,比如,容器A要访问容器D,请求的地址为 192.168.1.4 ,但是主机甲并不知道该将这个IP发送到那个网络设备上,主机甲也不知道主机乙内部有个容器D。
- 多个节点上的容器网段冲突,docker启动后初始化docker0网桥时,会随机分配一个IP段,如果不加以协调,多个节点内的容器网络有可能会冲突,比如上图中两个网络都采用了 192.168.1.1/24 网段,在这种情况下,就会导致容器IP冲突,比如 B 和 C。
Flannel实现的容器的跨主机通信通过如下过程实现
1.每个主机上安装并运行etcd和flannel;
2.在etcd中规划配置所有主机的docker0子网范围。
3.每个主机上的flanneld根据etcd中的配置,为本主机的docker0分配子网,保证所有主机上的docker0网段不重复,并将结果(即本主机上的docker0子网信息和本主机IP的对应关系)存入etcd库中,这样etcd库中就保存了所有主机。
上的docker子网信息和本主机IP的对应关系;
4.当需要与其他主机上的容器进行通信时,查找etcd数据库,找到目的容器的子网所对应的outip(目的宿主机的IP);
5.将原始数据包封装在VXLAN或UDP数据包中,IP层以outip为目的IP进行封装;
6.由于目的IP是宿主机IP,因此路由是可达的;
7.VXLAN或UDP数据包到达目的宿主机解封装,解出原始数据包,最终到达目的容器。
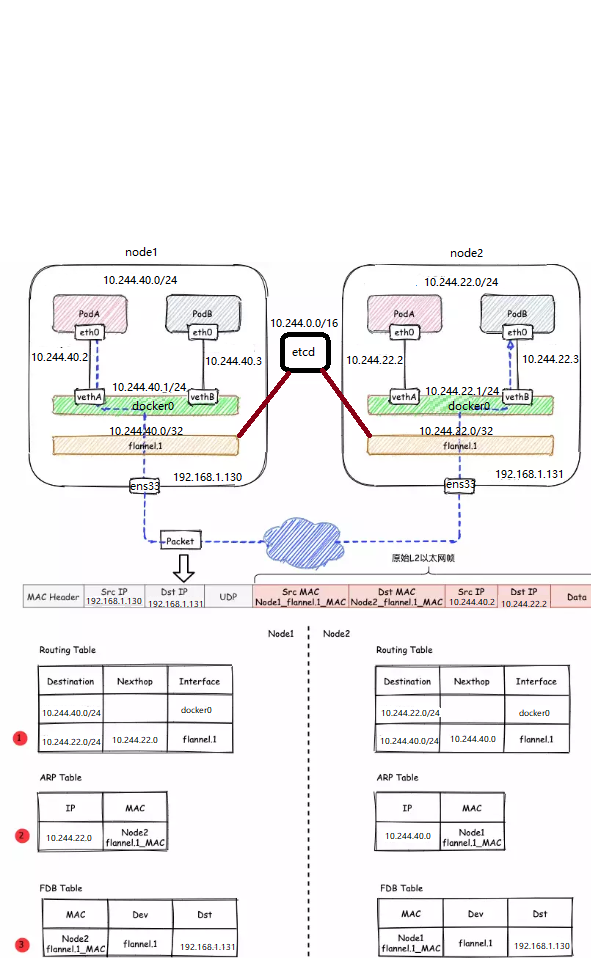
Flannel的工作原理
1.数据从源容器中发出后,经由所在主机的docker0虚拟网卡转发到flannel0虚拟网卡,这是个P2P的虚拟网卡,flanneld服务监听在网卡的另外一端。
2.Flannel通过Etcd服务(重点)维护了一张节点间的路由表,该张表里保存了各个节点主机的子网网段信息,flannel默认使用etcd作为配置和协调中心,首先使用etcd设置集群的整体网络。
3.源主机的flanneld服务将原本的数据内容UDP封装后根据自己的路由表投递给目的节点的flanneld服务,数据到达以后被解包,然后直接进入目的节点的flannel0虚拟网卡,然后被转发到目的主机的docker0虚拟网卡,最后就像本机容器通信一样的由docker0路由到达目标容器。
这样整个数据包的传递就完成了,这里需要解释三个问题:
1.UDP封装是怎么回事
- 在UDP的数据内容部分其实是另一个ICMP(也就是ping命令)的数据包。原始数据是在起始节点的Flannel服务上进行UDP封装的,
- 投递到目的节点后就被另一端的Flannel服务还原成了原始的数据包,两边的Docker服务都感觉不到这个过程的存在
2.为什么每个节点上的Docker会使用不同的IP地址段
因为Flannel通过Etcd分配了每个节点可用的IP地址段后,偷偷的修改了Docker的启动参数。在运行了Flannel服务的节点上可以查看到Docker服务进程运行参数
ps aux|grep docker|grep “bip”
例如“–bip=182.48.25.1/24”这个参数,它限制了所在节点容器获得的IP范围。这个IP范围是由Flannel自动分配的,由Flannel通过保存在Etcd服务中的记录确保它们不会重复。
3.为什么在发送节点上的数据会从docker0路由到flannel0虚拟网卡,在目的节点会从flannel0路由到docker0虚拟网卡?
例如现在有一个数据包要从IP为10.1.15.2的容器发到IP为10.1.20.3的容器。根据数据发送节点的路由表,它只与10.1.0.0/16匹配这条记录匹配,因此数据从docker0出来以后就被投递到了flannel0。同理在目标节点,由于投递的地址是一个容器,因此目的地址一定会落在docker0对于的10.1.20.1/24这个记录上,自然的被投递到了docker0网卡。
flannel是CoreOS公司开发的跨主机通信网络解决方案,它会为每个host分配一个subnet,容器从这个subnet中获取IP地址,这个IP地址在各个host主机组成的集群中是全局唯一的,其框架如下:
- 每个节点上有一个叫
flanneld的agent,负责为每个主机分配和管理子网; - 全局的网络配置存储
etcd负责存储主机容器子网的映射关系; - 数据包在主机之间发展是由
backend来实现的,常见的backend有VXLAN和host-gw两种模式。
实验:搭建flannel网络,使得不同宿主机之间的各个容器能后互相通信。(基于vxlan)
架构图:
| 主机名 | IP地址 | 应用 | 网关 |
|---|---|---|---|
| 主机1 | 192.168.1.130 | etcd、docker、flannel | 192.168.1.1 |
| 主机2 | 192.168.1.131 | etcd、docker、flannel | 192.168.1.1 |
1、安装etcd(两台主机)
1、安装etcd服务
[root@localhost ~]# wget https://github.com/etcd-io/etcd/releases/download/v3.5.4/etcd-v3.5.4-linux-amd64.tar.gz
[root@localhost ~]# tar xf etcd-v3.5.4-linux-amd64.tar.gz
[root@localhost ~]# cd etcd-v3.5.4-linux-amd64/
[root@localhost etcd-v3.3.10-linux-amd64]# mv etcd* /usr/local/sbin/
[root@localhost ~]#cd ..
[root@localhost ~]# etcdctl version
etcdctl version: 3.5.4
API version: 3.5
2、创建etcd服务(两台主机都配置)
2.1、配置防火墙(都执行)
[root@localhost ~]# firewall-cmd --zone=public --add-port=2379/tcp --permanent
[root@localhost ~]# firewall-cmd --zone=public --add-port=2380/tcp --permanent
[root@localhost ~]# firewall-cmd --reload
2.2、配置etcd,两个同时执行
主机1:
ETCDCTL_API=2 etcd --enable-v2 --name etcd1 --data-dir /var/lib/etcd/etcd1 --listen-peer-urls http://192.168.1.130:2380 --listen-client-urls http://192.168.1.130:2379 ,http://127.0.0.1:2379 --advertise-client-urls http://192.168.1.130:2379 --initial-advertise-peer-urls http://192.168.1.130:2380 --initial-cluster-state new --initial-cluster-token etcd-test --initial-cluster etcd1= http://192.168.1.130:2380 ,etcd2=http://192.168.1.131:2380 &
主机2:
ETCDCTL_API=2 etcd --enable-v2 --name etcd2 --data-dir /var/lib/etcd/etcd1 --listen-peer-urls http://192.168.1.131:2380 --listen-client-urls http://192.168.1.131:2379 ,http://127.0.0.1:2379 --advertise-client-urls http://192.168.1.131:2379 --initial-advertise-peer-urls http://192.168.1.131:2380 --initial-cluster-state new --initial-cluster-token etcd-test --initial-cluster etcd1= http://192.168.1.130:2380 ,etcd2=http://192.168.1.131:2380 &
name:节点名称
data-dir 指定节点的数据存储目录
listen-peer-urls: 监听URL,用于与其他节点通讯
listen-client-urls: 对外提供服务的地址:比如 http://ip:2379 ,http://127.0.0.1:2379 ,客户端会连接到这里和 etcd 交互
initial-advertise-peer-urls: 该节点同伴监听地址,这个值会告诉集群中其他节点
initial-cluster 集群中所有节点的信息,格式为 node1= http://ip1:2380,node2=http://ip2:2380 ,… 。注意:这里的 node1 是节点的 --name 指定的名字;后面的 ip1:2380 是 --initial-advertise-peer-urls 指定的值
initial-cluster-state: 新建集群的时候,这个值为 new ;假如已经存在的集群,这个值为 existing
initial-cluster-token :创建集群的 token,这个值每个集群保持唯一。这样的话,如果你要重新创建集群,即使配置和之前一样,也会再次生成新的集群和节点 uuid;否则会导致多个集群之间的冲突,造成未知的错误
advertise-client-urls:对外公告的该节点客户端监听地址,这个值会告诉集群中其他节点。
查看后台的任务:
[root@localhost ~]# jobs
[1]+ 运行中 ETCDCTL_API=2 etcd --enable-v2 --name etcd1 --data-dir /var/lib/etcd/etcd1 --listen-peer-urls http://192.168.1.130:2380 --listen-client-urls http://192.168.1.130:2379 ,http://127.0.0.1:2379 --advertise-client-urls http://192.168.1.130:2379 --initial-advertise-peer-urls http://192.168.1.130:2380 --initial-cluster-state new --initial-cluster-token etcd-test --initial-cluster etcd1= http://192.168.1.130:2380 ,etcd2=http://192.168.1.131:2380 &(工作目录:~/)
3、测试etcd集群是否正常
在主机1执行 :
[root@localhost ~]# etcdctl --endpoints=192.168.1.130:2379 put 123 456
在主机2执行:
[root@localhost ~]# etcdctl --endpoints=192.168.1.130:2379 get 123
123
456
从上面可以看出,主机1上创建的数据主机2上也能看到,表示etcd集群正常工作了
查看两个节点的健康状态
[root@localhost ~]# etcdctl endpoint health --endpoints http://192.168.1.130:2380 ,http://192.168.1.131:2380
http://192.168.1.131:2380 is healthy: successfully committed proposal: took = 6.792199ms
http://192.168.1.130:2380 is healthy: successfully committed proposal: took = 11.337122ms
4、配置地址池
4.1、定义网络ip池
主机1:
[root@localhost ~]# vim netetcd.json
{ "Network": "10.244.0.0/16","SubnetLen": 24,"Backend":{"Type":"vxlan"}}
:wq
Network 定义该网络的 IP 池为 10.244.0.0/16。
SubnetLen 指定每个主机分配到的 subnet 大小为 24 位,即10.244.X.0/24。
Backend 为 vxlan,即主机间通过 vxlan 通信。
4.2、将写好的键值对追加到etcd配置文件里
[root@localhost ~]# ETCDCTL_API=2 etcdctl --endpoints http://192.168.1.130:2379 set /docker/network/config < /root/netetcd.json
{ "Network": "10.244.0.0/16","SubnetLen": 24,"Backend":{"Type":"vxlan"}}
4.3、主机2测试:
[root@localhost ~]# ETCDCTL_API=2 etcdctl --endpoints http://192.168.1.130:2379 get /docker/network/config
{ "Network": "10.244.0.0/16","SubnetLen": 24,"Backend":{"Type":"vxlan"}}
2、安装flannel
1.下载并配置flannel(两主机都安装)
[root@localhost ~]# wget https://github.com/flannel-io/flannel/releases/download/v0.17.0/flanneld-amd64
[root@localhost ~]# chmod +x flanneld-amd64
2、执行flannel(两台都执行)
[root@localhost ~]# ./flanneld-amd64 -etcd-endpoints=http://192.168.1.130:2379 -iface=ens33 -etcd-prefix=/docker/network &
3、查看后台是否在运行
[root@localhost ~]# jobs
[1]- 运行中 ETCDCTL_API=2 etcd --enable-v2 --name etcd1 --data-dir /var/lib/etcd/etcd1 --listen-peer-urls http://192.168.1.130:2380 --listen-client-urls http://192.168.1.130:2379 ,http://127.0.0.1:2379 --advertise-client-urls http://192.168.1.130:2379 --initial-advertise-peer-urls http://192.168.1.130:2380 --initial-cluster-state new --initial-cluster-token etcd-test --initial-cluster etcd1= http://192.168.1.130:2380 ,etcd2=http://192.168.1.131:2380 &(工作目录:~/etcd-v3.5.4-linux-amd64)
[2]+ 运行中 ./flanneld-amd64 -etcd-endpoints=http://192.168.1.130:2379 -iface=ens33 -etcd-prefix=/docker/network &
会在当前的主机创建一个flannel.1网卡,
4、查看创建的网卡
主机1:
[root@localhost ~]# ip a
6: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN
link/ether 02:19:8a:92:62:c8 brd ff:ff:ff:ff:ff:ff
inet 10.244.40.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::19:8aff:fe92:62c8/64 scope link
valid_lft forever preferred_lft forever
主机2:
[root@localhost ~]# ip a
6: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN
link/ether 3e:23:f7:dd:c4:30 brd ff:ff:ff:ff:ff:ff
inet 10.244.22.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::3c23:f7ff:fedd:c430/64 scope link
valid_lft forever preferred_lft forever
并且两个主机都存在了flannel的路由:
主机1:
root@localhost ~]# ip r
10.244.22.0/24 via 10.244.22.0 dev flannel.1 onlink
主机2:
[root@localhost ~]# ip r
10.244.40.0/24 via 10.244.40.0 dev flannel.1 onlink
这个路由地址是从主机上申请出来的地址,就拿主机来说,我的flannel.1的网段为10.0.244.40.0/32,通过路由查看我们可以看到我去往10.244.22.0网段经过flannel.1网卡,而零个主机的flannel.1网卡地址是由etcd进行随机分配的,我们之前设置的是10.244.0.0/16
也就是这两个网卡的地址是从10.244.0.0/16这个里面取子网划分并获取的,前两位10.244都是一样的,所以两个主机就可以进行跨主机通信。我们可以通过查看subnet.env文件查看两个主机地址:
主机1:
[root@localhost ~]# cat /var/run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.40.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=false
主机2:
[root@localhost ~]# cat /var/run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.22.1/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=false
3、配置docker
1、修改docker的配置文件
主机1:
[root@localhost ~]# vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --bip=10.244.40.1/24 --mtu=1450
:wq
[root@localhost ~]# systemctl daemon-reload
[root@localhost ~]# systemctl restart docker
[root@localhost ~]# ip a
5: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN
link/ether 02:42:3d:2f:19:64 brd ff:ff:ff:ff:ff:ff
inet 10.244.40.1/24 brd 10.244.40.255 scope global docker0
valid_lft forever preferred_lft forever
6: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN
link/ether 02:19:8a:92:62:c8 brd ff:ff:ff:ff:ff:ff
inet 10.244.40.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::19:8aff:fe92:62c8/64 scope link
valid_lft forever preferred_lft forever
主机2:
[root@localhost ~]# vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --bip=10.244.22.1/24 --mtu=1450
:wq
[root@localhost ~]# systemctl daemon-reload
[root@localhost ~]# systemctl restart docker
[root@localhost ~]# ip a
5: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN
link/ether 02:42:78:90:88:15 brd ff:ff:ff:ff:ff:ff
inet 10.244.22.1/24 brd 10.244.22.255 scope global docker0
valid_lft forever preferred_lft forever
6: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN
link/ether 3e:23:f7:dd:c4:30 brd ff:ff:ff:ff:ff:ff
inet 10.244.22.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::3c23:f7ff:fedd:c430/64 scope link
valid_lft forever preferred_lft forever
2、配置防火墙(两台都配置)
[root@localhost ~]# iptables -I INPUT -s 192.168.1.0/24 -j ACCEPT
[root@localhost ~]# iptables -I INPUT -s 192.168.1.0/24 -j ACCEPT
我的宿主机两个都为192.168.1.0网段!
4、测试:
主机1运行:
[root@localhost ~]# docker run -dit --name box1 busybox
[root@localhost ~]# docker run -dit --name box2 busybox
查看box1、box2的ip地址为10.244.40.2和10.244.40.2
主机2:
[root@localhost ~]# docker run -dit --name box3 busybox
[root@localhost ~]# docker run -dit --name box3 busybox
查看box3、box4的ip地址为10.244.22.2和10.244.22.3
进行ping测试,box1pingbox3
[root@localhost ~]# docker exec -it box2 ping 10.244.22.2
PING 10.244.22.2 (10.244.22.2): 56 data bytes
64 bytes from 10.244.22.2: seq=0 ttl=62 time=0.855 ms
64 bytes from 10.244.22.2: seq=1 ttl=62 time=0.973 ms
64 bytes from 10.244.22.2: seq=2 ttl=62 time=1.583 ms
box4pingbox2:
[root@localhost ~]# docker exec -it box4 ping 10.244.40.3
PING 10.244.40.3 (10.244.40.3): 56 data bytes
64 bytes from 10.244.40.3: seq=0 ttl=62 time=0.888 ms
docker通过Flannel可以实现各容器间的相互通信,即宿主机和容器,容器和容器之间都能相互通信。
来看看跨节点Node1和Node2之间的容器互通式如何通信的?
- 发送端Node1:在Node1的PodA(假设含一个容器)中发起对Node2的PodB(假设另一个容器)的ping测
ping 10.244.22.2,ICMP报文经过docker0网桥后交由flannel.1设备处理。flannel.1设备是一个VXLAN类型的设备,负责VXLAN封包解包。 因此,在发送端,flannel.1将原始L2报文封装成VXLAN UDP报文,然后从ens33发送。 - 接收端:Node2收到UDP报文,发现是一个VXLAN类型报文,交由
flannel.1进行解包。根据解包后得到的原始报文中的目的IP,将原始报文经由docker0网桥发送给PodB。
哪些数据包要经过flannel.1处理:
flanneld从etcd中可以获取所有节点的子网情况,以此为依据为各节点配置路由,将属于非本节点的子网IP都路由到flannel.1处理,本节点的子网路由到docker0网桥处理。
[root@localhost ~]# ip r
....
10.244.22.0/24 via 10.244.22.0 dev flannel.1 onlink
# Node2子网为10.244.22.0/24,Node2的PodID都交由flannel.1处理
10.244.40.0/24 dev docker0 proto kernel scope link src 10.244.40.1
Node1子网为10.244.40.0/24, 本机PodIP都交由docker0处理
...
如果节点信息有变化,flanneld也会从etcd中同步更新路由信息。
flannel.1的封包过程:
VXLAN的封包是将二层以太网帧封装到四层UDP报文中的过程。
原始L2帧:
要生成原始的L2帧, flannel.1 需要得知:
-
内层源/目的IP地址
-
内层源/目的MAC地址
内层的源/目的IP地址是已知的,即为PodA/PodB的PodIP,在图例中,分别为10.224.40.2和10.224.22.2。 内层源/目的MAC地址要结合路由表和ARP表来获取。根据路由表①得知: -
1)下一跳地址是10.224.22.0,关联ARP表②,得到下一跳的MAC地址,也就是目的MAC地址:
Node2_flannel.1_MAC;

-
2)报文要从
flannel.1虚拟网卡发出,因此源MAC地址为flannel.1的MAC地址。
要注意的是,这里ARP表的表项②并不是通过ARP学习得到的,而是flanneld预先为每个节点设置好的,由flanneld负责维护,没有过期时间。
有了上面的信息, flannel.1 就可以构造出内层的2层以太网帧:

外层VXLAN UDP报文:
要将原始L2帧封装成VXLAN UDP报文, flannel.1 还需要填充源/目的IP地址。我们知道VTEP是VXLAN隧道的起点或终点。因此,目的IP地址即为对端VTEP的IP地址,通过FDB表获取。在FDB表③中,dst字段表示的即为VXLAN隧道目的端点(对端VTEP)的IP地址,也就是VXLAN DUP报文的目的IP地址。FDB表也是由 flanneld 在每个节点上预设并负责维护的。

FDB表(Forwarding database)用于保存二层设备中MAC地址和端口的关联关系,就像交换机中的MAC地址表一样。在二层设备转发二层以太网帧时,根据FDB表项来找到对应的端口。例如cni0网桥上连接了很多veth pair网卡,当网桥要将以太网帧转发给Pod时,FDB表根据Pod网卡的MAC地址查询FDB表,就能找到其对应的veth网卡,从而实现联通。
可以使用 bridge fdb show 查看FDB表:
主机1:
[root@localhost ~]# bridge fdb show | grep flannel.1
3e:23:f7:dd:c4:30 dev flannel.1 dst 192.168.1.131 self permanent
源IP地址信息来自于 flannel.1 网卡设置本身,根据 local 192.168.1.130 可以得知源IP地址为192.168.1.130。
主机1
[root@localhost ~]# ip -d a show flannel.1
6: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN
link/ether 02:19:8a:92:62:c8 brd ff:ff:ff:ff:ff:ff promiscuity 0
vxlan id 1 local 192.168.1.130 dev ens33 srcport 0 0 dstport 8472 nolearning ageing 300
inet 10.244.40.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
inet6 fe80::19:8aff:fe92:62c8/64 scope link
valid_lft forever preferred_lft forever
至此, flannel.1 已经得到了所有完成VXLAN封包所需的信息,最终通过 eth0 发送一个VXLAN UDP报文:
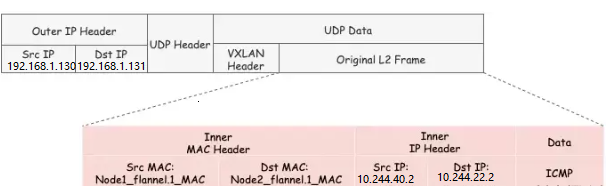
即:把原始L2数据包封装在了UDP报文中,外层IP可二层直通,二层互通以后再VTEP端点进行VXLAN解封装后进行交互。
Flannel的VXLAN模式通过静态配置路由表,ARP表和FDB表的信息,结合VXLAN虚拟网卡 flannel.1 ,实现了所有容器同属一个大二层网络的VXLAN网络模型。
Flannel数据转发之host-gw模式
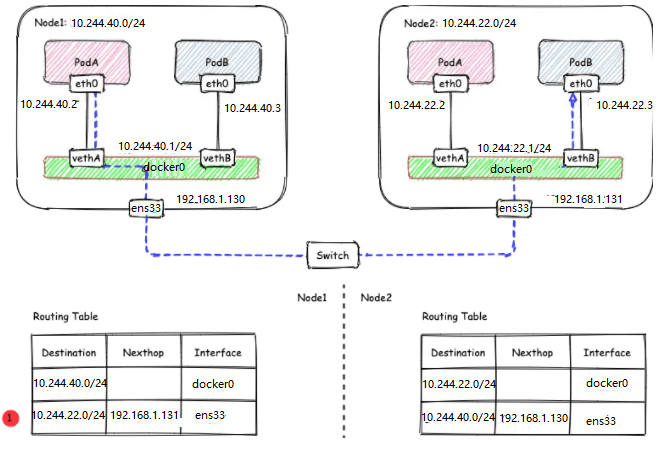
host-gw的工作原理就是将每个flannel子网转发地址设置成了该子网对应的宿主机的IP地址,通过这个过程,容器在通信过程中就减少了封包和解包的性能损耗。也就是直接宿主机的物理网卡进行转发数据。实验如下:
接上方的实验:
1、修改地址池将vxlan改为host-gw
主机1:
[root@localhost ~]# vim netetcd.json
{ "Network": "10.244.0.0/16","SubnetLen": 24,"Backend":{"Type":"host-gw"}}
:wq
2、将写好的键值对追加到etcd配置文件里
主机1:
[root@localhost ~]# ETCDCTL_API=2 etcdctl --endpoints http://192.168.1.130:2379 set /docker/network/config < /root/netetcd.json
{ "Network": "10.244.0.0/16","SubnetLen": 24,"Backend":{"Type":"host-gw"}}
主机2:
[root@localhost ~]# ETCDCTL_API=2 etcdctl --endpoints http://192.168.1.130:2379 get /docker/network/config
{ "Network": "10.244.0.0/16","SubnetLen": 24,"Backend":{"Type":"host-gw"}}
可以看到同步过来了
3、重新启动flannel
两个主机都要:
1、先jobs查看那个是flannel
[root@localhost ~]# jobs
[1]- 运行中 ETCDCTL_API=2 etcd --enable-v2 --name etcd1 --data-dir /var/lib/etcd/etcd1 --listen-peer-urls http://192.168.1.130:2380 --listen-client-urls http://192.168.1.130:2379 ,http://127.0.0.1:2379 --advertise-client-urls http://192.168.1.130:2379 --initial-advertise-peer-urls http://192.168.1.130:2380 --initial-cluster-state new --initial-cluster-token etcd-test --initial-cluster etcd1= http://192.168.1.130:2380 ,etcd2=http://192.168.1.131:2380 &(工作目录:~/etcd-v3.5.4-linux-amd64)
[2]+ 运行中 ./flanneld-amd64 -etcd-endpoints=http://192.168.1.130:2379 -iface=ens33 -etcd-prefix=/docker/network &
2、将flannel调到前台然后ctrl+c结束进程
[root@localhost ~]# fg 2
./flanneld-amd64 -etcd-endpoints=http://192.168.1.130:2379 -iface=ens33 -etcd-prefix=/docker/network
^C
3、再次运行flannel
[root@localhost ~]# ./flanneld-amd64 -etcd-endpoints=http://192.168.1.130:2379 -iface=ens33 -etcd-prefix=/docker/network &
4、查看重新分配的地址:
主机1:
[root@localhost ~]# cat /var/run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.40.1/24
FLANNEL_MTU=1500
FLANNEL_IPMASQ=false
主机2:
[root@localhost ~]# cat /var/run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.22.1/24
FLANNEL_MTU=1500
FLANNEL_IPMASQ=false
可以看到两个ip没有什么变化,这是因为缓存,变化的只有mtu值。
4、重新配置docker
修改两个主机的mtu值
主机1:
[root@localhost ~]# vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --bip=10.244.40.1/24 --mtu=1500
:wq
主机2:
[root@localhost ~]# vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --bip=10.244.22.1/24 --mtu=1500
:wq
两台执行:
[root@localhost ~]# systemctl daemon-reload
[root@localhost ~]# systemctl restart docker
测试:
将两台主机的docker启动起来:
[root@localhost ~]# docker start $(docker ps -qa)
box1 ping box3
[root@localhost ~]# docker exec -it box1 ping 10.244.22.2
PING 10.244.22.2 (10.244.22.2): 56 data bytes
64 bytes from 10.244.22.2: seq=0 ttl=62 time=0.986 ms
64 bytes from 10.244.22.2: seq=1 ttl=62 time=1.357 ms
通讯过程:
- 同UDP、VXLAN模式一致,通过box1的路由表IP包到达docker0,到达docker0的IP包匹配到主机1中的路由规则10.244.22.0/24,且网关为192.168.1.131,即主机2,所以内核将ip包发送给主机2,ip包通过物理网络到达主机2的ens33;
- 到达主机2的ens33 的ip包匹配到主机2上的路由表10.244.40.1/24,ip包转发给docker0, docker0将ip包转发给连接在docker0上的box2。
通过上述这个过程可以看出这台主机的host就充当了容器通信路径里的网关,IP封装成帧的时候,会使路由表中的下一跳来设置目的MAC地址,它会经过二层网络达到宿主机,但同时这个限制也是有问题的,首先要求我们必须保证集群内部所有主机二层网络必须是连通的,然后在大规模集群路由表的动态更新也存在一定压力。采用host-gw模式后,flanneld的唯一作用就是负责主机上路由表的动态更新。
我们查看下主机1的路由表信息:
[root@localhost ~]# ip r
........
10.244.22.0/24 via 192.168.1.131 dev ens33
主机2子网的下一跳地址指向主机2的 ip地址。
10.244.40.0/24 dev docker0 proto kernel scope link src 10.244.40.1
.........
由于没有封包解包带来的消耗,host-gw是性能最好的。不过一般在云环境下,都不支持使用host-gw的模式,在私有化部署的场景下,可以考虑。
vxlan与host-gw进行对比:
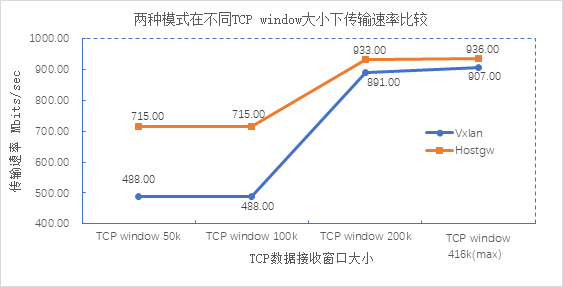
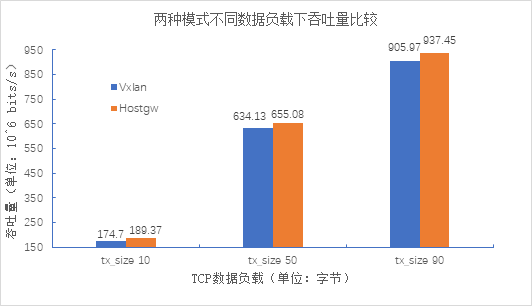
根据上面两张测试数据可以得出:1、在TCP数据接收窗口相同的情况下,host-gw平均传输速度更快,比VXLAN快约20%,实验环境下最终趋于相近的速率;2、host-gw的平均吞吐量较VXLAN模式高出约5%。由此可见,对于小规模集群、二层网络下的通信,可以优先选择host-gw;而大规模集群、三层网络下的通信更适合走VXLAN模式。
二、Weave方案:
它能够创建一个虚拟网络,用于连接部署在多台主机上的Docker容器,这样容器就像被接入了同一个网络交换机,那些使用网络的应用程序不必去配置端口映射和链接等信息。外部设备能够访问Weave网络上的应用程序容器所提供的服务,同时已有的内部系统也能够暴露到应用程序容器上。Weave能够穿透防火墙并运行在部分连接的网络上,另外,Weave的通信支持加密,所以用户可以从一个不受信任的网络连接到主机。
Weave通过创建虚拟网络使Docker容器能够跨主机通信并能够自动相互发现。通过weave网络,由多个容器构成的基于微服务架构的应用可以运行在任何地方:主机,多主机,云上或者数据中心。应用程序使用网络就好像容器是插在同一个网络交换机上一样,不需要配置端口映射,连接等。在weave网络中,使用应用容器提供的服务可以暴露给外部,而不用管它们运行在何处。类似地,现存的内部系统也可以接受来自于应用容器的请求,而不管容器运行于何处。
一个Weave网络由一系列的'peers'构成----这些weave路由器存在于不同的主机上。每个peer都由一个名字,这个名字在重启之后保持不变.这个名字便于用户理解和区分日志信息。每个peer在每次运行时都会有一个不同的唯一标识符(UID).对于路由器而言,这些标识符不是透明的,尽管名字默认是路由器的MAC地址。
Weave路由器之间建立起TCP连接,通过这个连接进行心跳握手和拓扑信息交换,这些连接可以通过配置进行加密。peers之间还会建立UDP连接,也可以进行加密,这些UDP连接用于网络包的封装,这些连接是双工的而且可以穿越防火墙。Weave网络在主机上创建一个网桥,每个容器通过veth pari连接到网桥上,容器由用户或者weave网络的IPADM分配IP地址。
weave实现原理
1、容器的网络通讯都通过route服务和网桥转发。Weave会在主机上创建一个网桥,每一个容器通过 veth pair 连接到该网桥上,同时网桥上有个 Weave router 的容器与之连接,该router会通过连接在网桥上的接口来抓取网络包(该接口工作在Promiscuous模式)。
2、在每一个部署Docker的主机(可能是物理机也可能是虚拟机)上都部署有一个W(即Weave router),它本身也可以以一个容器的形式部署。Weave run的时候就可以给每个veth的容器端分配一个ip和相应的掩码。veth的网桥这端就是Weave router容器,并在Weave launch的时候分配好ip和掩码。
3、Weave网络是由这些weave routers组成的对等端点(peer)构成,每个对等的一端都有自己的名字,其中包括一个可读性好的名字用于表示状态和日志的输出,一个唯一标识符用于运行中相互区别,即使重启Docker主机名字也保持不变,这些名字默认是mac地址。
4、每个部署了Weave router的主机都需要将TCP和UDP的6783端口的防火墙设置打开,保证Weave router之间控制面流量和数据面流量的通过。控制面由weave routers之间建立的TCP连接构成,通过它进行握手和拓扑关系信息的交换通信。 这个通信可以被配置为加密通信。而数据面由Weave routers之间建立的UDP连接构成,这些连接大部分都会加密。这些连接都是全双工的,并且可以穿越防火墙。当容器通过weave进行跨主机通信时,其网络通信模型可以参考下图:
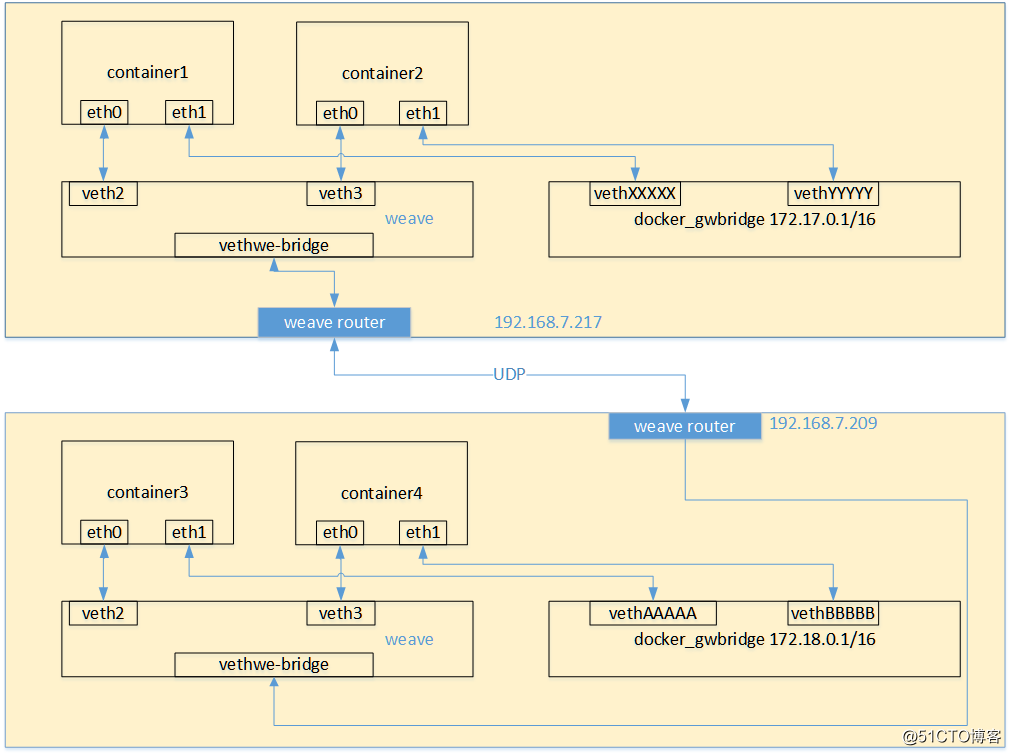
从上面的网络模型图中可以看出,对每一个weave网络中的容器,weave都会创建一个网桥,并且在网桥和每个容器之间创建一个veth pair,一端作为容器网卡加入到容器的网络命名空间中,并为容器网卡配置ip和相应的掩码,一端连接在网桥上,最终通过宿主机上weave router将流量转发到对端主机上。
其基本过程如下:
1)容器流量通过veth pair到达宿主机上weave router网桥上。
2)weave router在混杂模式下使用pcap在网桥上截获网络数据包,并排除由内核直接通过网桥转发的数据流量,例如本子网内部、本地容器之间的数据以及宿主机和本地容器之间的流量。捕获的包通过UDP转发到所其他主机的weave router端。
3)在接收端,weave router通过pcap将包注入到网桥上的接口,通过网桥的上的veth pair,将流量分发到容器的网卡上。weave默认基于UDP承载容器之间的数据包,并且可以完全自定义整个集群的网络拓扑,但从性能和使用角度来看,还是有比较大的缺陷的:
-> weave自定义容器数据包的封包解包方式,不够通用,传输效率比较低,性能上的损失也比较大。
-> 集群配置比较负载,需要通过weave命令行来手工构建网络拓扑,在大规模集群的情况下,加重了管理员的负担。
两边相同网段:(自定义)
1、配置防火墙规则
两台都要执行
由于weave通讯需要开启tcp/udp的6783端口,所以:
[root@localhost ~]# firewall-cmd --zone=public --add-port=6783/tcp --permanent
[root@localhost ~]# firewall-cmd --zone=public --add-port=6783/udp --permanent
[root@localhost ~]# firewall-cmd --zone=public --add-port=6784/udp --permanent
[root@localhost ~]# firewall-cmd --reload
[root@localhost ~]# iptables -A FORWARD -j REJECT --reject-with icmp-host-prohibited
[root@localhost ~]# iptables-save
[root@localhost ~]# setenforce 0
[root@localhost ~]# iptables -F
[root@localhost ~]# firewall-cmd --zone=public --add-port=53/udp --permanent
[root@localhost ~]# firewall-cmd --zone=public --add-port=53/tcp --permanent
或者可以直接执行者两条命令:
[root@localhost ~]# setenforce 0
[root@localhost ~]# systemctl stop firewalld
2、安装weave与启动:(两台都要安装)
1)这里选择直接从github下载二进制文件进行安装。
curl -L git.io/weave -o /usr/local/bin/weave
chmod a+x /usr/local/bin/weave
2)启动weave路由器,这个路由器其实也是以容器的形式运行的。(前提是已经启动了docker服务进程)
[root@localhost ~]# weave launch
这里如果出现
'-A FORWARD -j REJECT --reject-with icmp-host-prohibited'
will block name resolution via weaveDNS - please reconfigure your firewall.
这样情况的化,先使用weave stop命令,然后执行iptables -F 然后在weave launch启动
3)查看镜像,可以发现上面下载的weave路由容器镜像
[root@localhost ~]# docker images
REPOSITORY TAG IMA GE ID CREATED SIZE
weaveworks/weaveexec latest e8d7a2b95ca2 15 months ago 71.2MB
weaveworks/weave latest c5f94c391f12 15 months ago 61.2MB
weaveworks/weavedb latest 19661b1dbf28 15 months ago 698B
weave:是主程序,负责建立weave网络,收发数据,提供DNS服务等
weaveexec:是libnetwork CNM dirver,实现docker网络
weavedb:提供 Docker 命令的代理服务,当用户使用weave集群中的docker创建容器时,它会自动将容器添加到 weave 网络。
4)此时会发现有两个网桥,一个是Docker默认生成的,另一个是Weave生成的。
[root@localhost ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242bf3a9db6 no
weave 8000.0a71d747bda5 no vethwe-bridge
3、跨主机通讯
1)在两台机上均启动一个应用容器
先使用docker run启动好容器,然后使用weave attach命令给容器绑定IP地址
在主机1机器上启动第一个容器box1,容器ip绑定为192.168.0.2:
[root@localhost ~]# docker run -dit --name=box1 busybox
使用weave给容器绑定IP:
[root@localhost ~]# weave attach 192.168.0.2/24 box1
192.168.0.2
如果不自己指定IP,则weave或自动为你分配
查看IP地址:
[root@localhost ~]# docker exec -it box1 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
29: eth0@if30: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
31: ethwe@if32: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1376 qdisc noqueue
link/ether 1e:3d:a3:1a:f3:a6 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.2/24 brd 192.168.0.255 scope global ethwe
valid_lft forever preferred_lft forever
在主机2机器上启动第一个容器box2,容器ip绑定为192.168.0.3
[root@localhost ~]# docker run -dit --name=box2 busybox
79686b1e2612cc8e936a3308a87adf37a92d84efdf1737c61e51466a75738ccf
[root@localhost ~]# weave attach 192.168.0.3/24 box2
192.168.0.3
查看IP:
[root@localhost ~]# docker exec -it box2 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
30: eth0@if31: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
32: ethwe@if33: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1376 qdisc noqueue
link/ether 96:f4:0b:07:62:b2 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.3/24 brd 192.168.0.255 scope global ethwe
valid_lft forever preferred_lft forever
上面在docker run启动容器时,可以添加--net=none参数,这个表示容器启动后不使用默认的虚拟网卡docker0自动分配的ip,而是使用weave绑定的ip;
当然也可以选择不添加这个参数去启动容器,这样,容器启动后就会有两个网卡,即两个ip:
一个是docker0自动分配的ip,这个适用于同主机内的容器间通信,即同主机的容器使docker0分配的ip可以相互通信;另一个就是weave网桥绑定的ip。
2)容器互联
默认情况下,上面在node-1和node-2两台宿主机上创建的2个容器间都是相互ping不通的。需要使用weave connect命令在两台weave的路由器之间建立连接。
主机1:
[root@localhost ~]# weave connect 192.168.1.131
//连接的是对方宿主机的ip,注意"weave forget 192.168.1.131" 则表示断开这个连接.
此时位于两台不同主机上的相同子网段内的容器之间可以相互ping通了
主机1:
[root@localhost ~]# docker exec -it box1 ping 192.168.0.3
PING 192.168.0.3 (192.168.0.3): 56 data bytes
64 bytes from 192.168.0.3: seq=0 ttl=64 time=2.225 ms
64 bytes from 192.168.0.3: seq=1 ttl=64 time=1.115 ms
64 bytes from 192.168.0.3: seq=2 ttl=64 time=0.865 ms
主机2:
[root@localhost ~]# docker exec -it box2 ping 192.168.0.2
PING 192.168.0.2 (192.168.0.2): 56 data bytes
64 bytes from 192.168.0.2: seq=0 ttl=64 time=0.975 ms
64 bytes from 192.168.0.2: seq=1 ttl=64 time=0.623 ms
再在主机1上启动容器box3,绑定ip为192.168.0.10,在主机2上启动容器box4,绑定ip为192.168.0.11,会发现这四个在同一个子网内的容器都是可以相互ping通的!我们同时加上dns通信。
默认情况下不会使用weave的DNS,故不能用容器名进行访问。如果要使用容器主机名,可按以下方法:
主机1:
[root@localhost ~]# docker run -dit --name box3 -h box3.weave.local $(weave dns-args) busybox
[root@localhost ~]# weave attach 192.168.0.10/24 box3
192.168.0.10
[root@localhost ~]# docker exec -it box3 ping box4
PING box4 (192.168.0.11): 56 data bytes
64 bytes from 192.168.0.11: seq=0 ttl=64 time=0.793 ms
主机2:
[root@localhost ~]# docker run -dit --name box4 -h box4.weave.local $(weave dns-args) busybox
[root@localhost ~]# weave attach 192.168.0.11/24 box4
192.168.0.11
[root@localhost ~]# docker exec -it box4 ping box3
PING box3 (192.168.0.10): 56 data bytes
64 bytes from 192.168.0.10: seq=0 ttl=64 time=1.124 ms
因此:只有两个能通信的宿主机做了weave connect操作,则在他们俩上创建并weave attach绑定同网段的容器都是可以相互之间通信的!但是不同网段是不能通讯的。这样做的好处是:使用不同子网进行容器间的网络隔离了。
注意一个细节,在使用weave的时候:
1)如果使用Docker的原生网络,在容器内部是可以访问宿主机以及外部网络的。也就是说在启动容器的时候,使用了虚拟网卡docker0分配ip,
这种情况下,登陆容器后是可以ping通宿主机ip,并且可以对外联网的!
这个时候,在宿主机上是可以ping通docker0网桥的ip,但是ping不通weave网桥的ip。这个时候可以使用"weave expose 192.168.0.1/24"命令来给weave网桥添加IP,以实现容器与宿主机网络连通。如下:
默认在主机1和主机2宿主机上可以通过docker0和容器通信,但是不能通过weave网桥进行通信,如果上面启动容器的时候使用--net=none的话,容器是没有docker0这张网卡的,所以想要和宿主机通信,需要给weave网桥添加IP,以实现容器与宿主机网络连通。
主机1:
[root@localhost ~]# ping 192.168.0.2
PING 192.168.0.2 (192.168.0.2) 56(84) bytes of data.
主机2:
[root@localhost ~]# ping 192.168.0.3
PING 192.168.0.3 (192.168.0.3) 56(84) bytes of data.
默认在主机1和主机2宿主机上是ping不通box容器的weave网桥ip的
在主机1和主机2两台机器上都添加weave网桥的ip:
[root@localhost ~]# weave expose 192.168.0.1/24
[root@localhost ~]# weave expose 192.168.0.1/24
//weave hide 192.168.0.1/24表示覆盖/删除这个设置
然后再在两台宿主机上ping上面同网段内的容器,发现都可以ping通了
[root@localhost ~]# ping 192.168.0.2
PING 192.168.0.2 (192.168.0.2) 56(84) bytes of data.
64 bytes from 192.168.0.2: icmp_seq=1 ttl=64 time=0.157 ms
[root@localhost ~]# ping 192.168.0.3
PING 192.168.0.3 (192.168.0.3) 56(84) bytes of data.
64 bytes from 192.168.0.3: icmp_seq=1 ttl=64 time=1.66 ms
总结:如果不使用Docker的原生网络,即在容器启动的时候,添加--net=none,这样容器启动后,就不会使用docker0网卡分配ip。这种情况下,进入容器后发现不能访问宿主机以及外部网络的,而在宿主机上也不能ping通容器ip。这个时候添加对应容器网段的weave网桥ip,这样可以实现容器与宿主机网络连通。但是,此时在容器内部依然不能访问外部网络。
所以说,可以同时使用Docker的原生网络和weave网络来实现容器互联及容器访问外网和端口映射。使用外部网络及端口映射的时候就使用docker0网桥,需要容器互联的时候就使用weave网桥。每个容器分配两个网卡。
其他:
Weave会保证容器ip都是唯一的,并且自动负责容器ip的分配和回收,你不需要配置任何东西就能得到这个好处。如果对分配有特定需求也是可以自定义分配ip网段的,比如:在阿里云上部署。
weave默认使用的网段是10.32.0.0/12,也就是从10.32.0.0到10.47.255.255。如果这个网段已经被占用,Weave就会报错,可以在启动的时候使用--ipalloc-range参数手动指定Weave要使用的网段。
$ weave launch --ipalloc-range 10.60.0.0/12
weave网络隔离(手动指定)
指定地址参数WEAVE_CIDR
指定网段:WEAVE_CIDR=net:10.10.0.0/24
指定ip:WEAVE_CIDR=ip:10.10.10.10/24
生成环境中一般会使用指定网段能多一些。
指定网段
指定网段不能超出10.32.0.0/12的范围
如下,指定网段为10.32.2.0/24
[root@localhost ~]# docker run -e WEAVE_CIDR=net:10.32.2.0/24 -it busybox
查看ip,自动分配了ip为10.32.2.1/24
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
36: eth0@if37: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:04 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.4/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
38: ethwe@if39: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1376 qdisc noqueue
link/ether 86:55:8e:63:4e:a1 brd ff:ff:ff:ff:ff:ff
inet 10.32.2.1/24 brd 10.32.2.255 scope global ethwe
valid_lft forever preferred_lft forever
/ # ip r
default via 172.17.0.1 dev eth0
10.32.2.0/24 dev ethwe scope link src 10.32.2.1
172.17.0.0/16 dev eth0 scope link src 172.17.0.4
224.0.0.0/4 dev ethwe scope link
这时候如果使用这个容器来ping之前的bbox1的10.32.0.1/12是ping不通的
因为10.32.0.0/12和10.32.2.0/24不是同一个网段
/ # ping bbox1
PING bbox1 (10.32.0.1): 56 data bytes
指定ip:
指定ip地址为10.32.6.6/24
[root@localhost ~]# docker run -e WEAVE_CIDR=ip:10.32.6.6/24 -it busybox
https://blog.51cto.com/u_15069485/2611980
不同网段相同子网的互联:(默认weave获取IP)
1、weave安装和上面一样!
2、跨主机互联:
1、如果不恢复快照的话先删除之前创建的容器:
主机1:
[root@localhost ~]# docker rm -f box1
[root@localhost ~]# docker rm -f box3
主机2:
[root@localhost ~]# docker rm -f box2
[root@localhost ~]# docker rm -f box4
2、创建容器并启动容器
主机1:
[root@localhost ~]# docker run -dit --name box1 busybox
413b3e3948d467b0a2b4d1324e2d5251018a8f645b5842db5c23a6733c2b0180
[root@localhost ~]# weave attach box1
10.40.0.0
[root@localhost ~]# docker run -dit --name box2 busybox
5517988ffa119d9db088cc9cde4c52c0ca0302f96c755464c8dcdf33411b7c38
[root@localhost ~]# weave attach box2
10.40.0.1
主机2:
[root@localhost ~]# docker run -dit --name box3 busybox
e3a0f84fdeb9d10148cdaf5322d9990878c900a237fa7de1c52ab876ac99a2f9
[root@localhost ~]# weave attach box3
10.32.0.1
[root@localhost ~]# docker run -dit --name box4 busybox
70b74808789d3e758b0bcc14e78baf787bf26e9146cbd023fb13eb8fc1d86553
[root@localhost ~]# weave attach box4
10.32.0.2
由于之前使用weave connect 192.168.1.131打通了两个主机的通信。所以我这里就直接ping
[root@localhost ~]# docker exec -it box1 ping 10.32.0.2
PING 10.32.0.2 (10.32.0.2): 56 data bytes
64 bytes from 10.32.0.2: seq=0 ttl=64 time=1.822 ms
box1、2、3、4之间都可以互通,如过使用dns通信可以使用上面的方法。
我们从四个容器的IP分别为 10.44.0.0/12、10.44.0.1/12 10.32.0.1/12 和 10.32.0.2/12,注意掩码为 12 位,实际上这三个 IP 位于同一个 subnet 10.44.0.0/12。通过 主机1 和 主机2 之间的 VxLAN 隧道,三个容器逻辑上是在同一个 LAN 中的,当然能直接通信了。
weave网络隔离
默认网络配置下,weave是一个大的subnet,接入到同一个weave网络的所有主机的容器都从这个大的范围内获取IP,因为同属于一个subnet,容器可以直接通信。如果要实现网络隔离,可以通过环境变量WEAVE_CIDR为容器分配指定的IP。看示例:
1、在主机2上创建容器box5
[root@node2 ~]# eval $(weave env)
[root@localhost ~]# docker run -e WEAVE_CIDR=net:10.32.2.0/24 -itd --name=box5 busybox
这里-e WEAVE_CIDR=net:10.32.2.0/24参数的作用是让容器分配到10.32.2.0网段的地址,由于10.32.0.1/12和10.32.2.0/24属于不同的subnet,所以无法ping通:
[root@localhost ~]# docker exec -it box5 ping 10.32.0.1 #box3
PING 10.32.0.1 (10.32.0.1): 56 data bytes
除了使用-e WEAVE_CIDR=net:10.32.2.0/24参数指定subnet,我们还可以指定IP地址,如:
[root@localhost ~]# docker run -e WEAVE_CIDR=ip:10.32.6.5/12 -itd --name=box6 busybox
我们指定的IP为10.32.6.5/12,和box3的subnet一样,就可以ping通:
[root@localhost ~]# docker exec -it box6 ping 10.32.0.1
PING 10.32.0.1 (10.32.0.1): 56 data bytes
64 bytes from 10.32.0.1: seq=0 ttl=64 time=0.277 ms
64 bytes from 10.32.0.1: seq=1 ttl=64 time=0.060 ms
weave是一个私有的VxLAN网络,默认与外部网络隔离。外部网络如果需要访问weave中的容器需要以下操作:
[root@localhost ~]# weave expose
10.32.0.3
这个10.32.0.3会被配置到主机2的weave网桥上:
[root@localhost ~]# ip addr show weave
8: weave: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1376 qdisc noqueue state UP qlen 1000
link/ether da:b0:27:15:9a:4d brd ff:ff:ff:ff:ff:ff
inet 192.168.0.1/24 brd 192.168.0.255 scope global weave
valid_lft forever preferred_lft forever
inet 10.32.0.3/12 brd 10.47.255.255 scope global weave
valid_lft forever preferred_lft forever
inet6 fe80::d8b0:27ff:fe15:9a4d/64 scope link
valid_lft forever preferred_lft forever
weave网桥位于root namespace,它负责将容器接入到weave网络。给weave配置同一subnet的IP,其本质就是将主机2接入weave网络。主机2 现在已经可以和同一weave网络的容器进行通信了:
[root@localhost ~]# ping 10.32.0.1
PING 10.32.0.1 (10.32.0.1) 56(84) bytes of data.
64 bytes from 10.32.0.1: icmp_seq=1 ttl=64 time=0.104 ms
[root@localhost ~]# ping 10.32.0.2
PING 10.32.0.2 (10.32.0.2) 56(84) bytes of data.
64 bytes from 10.32.0.2: icmp_seq=1 ttl=64 time=0.292 ms
http://www.meixuhong.com/05-docker-network.html
三、OVS+GRE方案
OpenVSwich即开放式虚拟交换机实现,简称OVS,OVS在云计算领域应用广泛,值得我们去学习使用。
OpenVSwich是一种开源软件,通过软件的方式实现二层交换机功能,专门管理多租赁云计算网络环境,提供虚拟网络中的访问策略、网络隔离、流量监控等。
GRE即通用路由协议封装,隧道技术是一种封装技术,将网络层协议(如IP)的数据报文进行封装,使这些封装的数据报文能够在另一个网络层协议中传输。可以看作是一个虚拟点到点连接,所以建立隧道时,要配置好隧道源地址和目的地址。
实验:
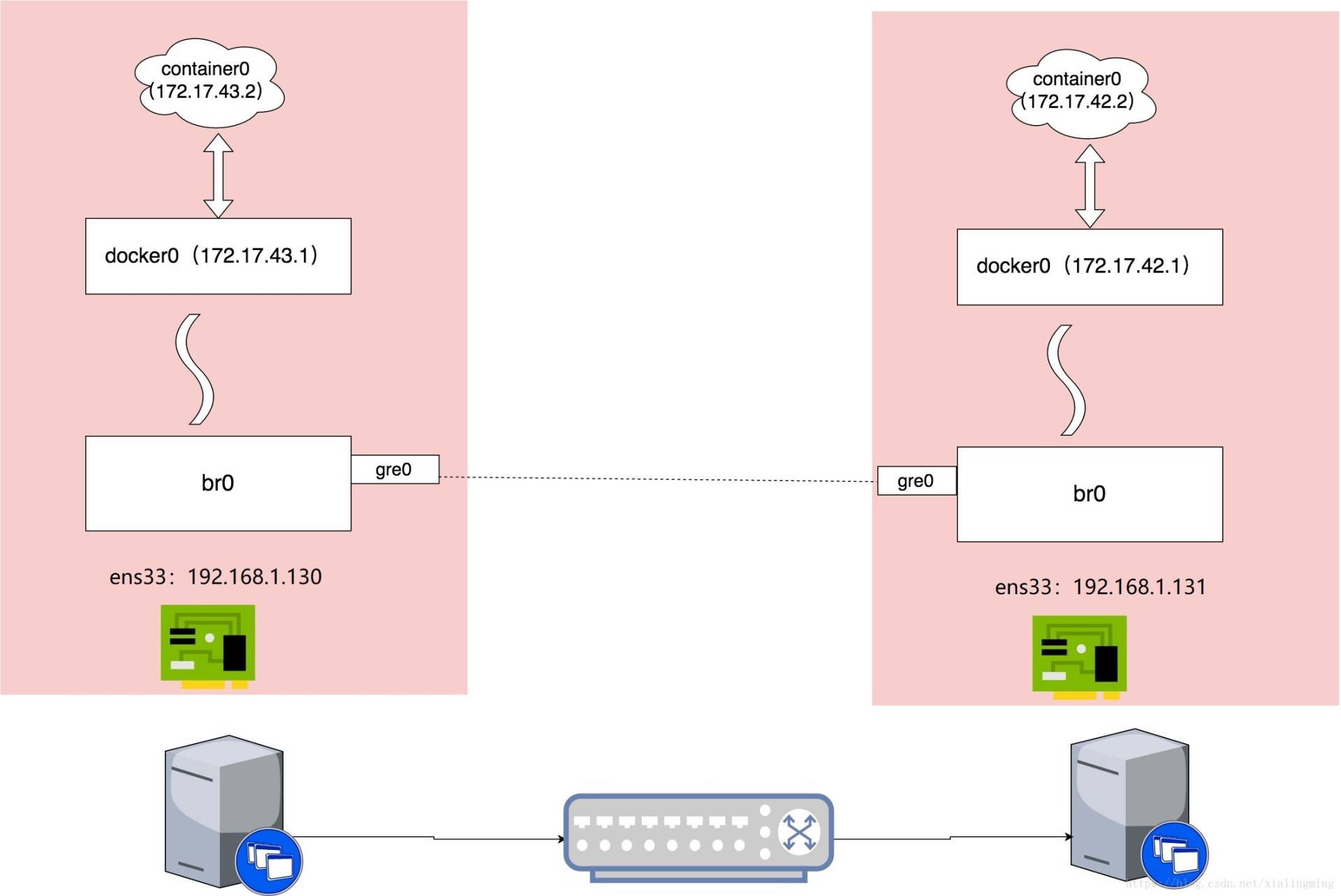
| 操作系统 | 主机 | 主机ip | 容器网段 |
|---|---|---|---|
| centos7 | 主机1 | 192.168.1.130 | 172.17.43.1/24 |
| centos7 | 主机2 | 192.168.1.131 | 172.17.42.1/24 |
1、修改docker0的网络地址:(主机1、2都要修改)并重启docker
主机1:
[root@localhost ~]# vim /etc/docker/daemon.json
{ "bip": "172.17.43.1/24" }
:wq
主机2:
[root@localhost ~]# vim /etc/docker/daemon.json
{ "bip": "172.17.42.1/24" }
:wq
[root@localhost ~]# systemctl restart docker
2、创建OVS bridge(主机1和2都配置)
1、安装 openvswitch
root@localhost ~]# setenforce 0
[root@localhost ~]# yum install -y epel-release
[root@localhost ~]# yum install -y centos-release-openstack-train
[root@localhost ~]# yum install -y openvswitch libibverbs
[root@localhost ~]# systemctl start openvswitch
# 检查ovs-vsctl命令是否可用
[root@localhost ~]# ovs-vsctl show
c4c362d3-7cd9-47da-9c2d-3363357f56c5
ovs_version: "2.12.0"
2、创建br0网桥
[root@localhost ~]# ovs-vsctl add-br br0
3、查看br0网桥
[root@localhost ~]# ifconfig br0
br0: flags=4098<BROADCAST,MULTICAST> mtu 1500
ether 5e:9d:f9:0b:cc:4a txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
3、配置gre端口
1、将gre0接口加入到网桥obr0, 远程IP写对端IP(创建一个GRE隧道并添加到网桥中)
主机1:
[root@localhost ~]# ovs-vsctl add-port br0 gre0 -- set Interface gre0 type=gre option:remote_ip=192.168.1.131
注意,这里的IP地址为主机2的IP地址!
主机2:
[root@localhost ~]# ovs-vsctl add-port br0 gre0 -- set Interface gre0 type=gre option:remote_ip=192.168.1.130
主机1、2都操作:
2、将br0网桥加入docker0网桥
[root@localhost ~]# brctl addif docker0 br0
3、启动br0网桥
[root@localhost ~]# ip link set dev br0 up
4、启动docker0网桥
[root@localhost ~]# ip link set dev docker0 up
5、添加路由条目
[root@localhost ~]# ip route add 172.17.0.0/16 dev docker0
注意:由于主机1和主机2的网络掩码为24,因此16位就可以包含这2个网络了。
6、查看网桥信息:
[root@localhost ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242131e5efd no br0
4、进行容器测试
1、创建容器
主机1:
[root@localhost ~]# docker run -itd --name box1 busybox
主机2:
[root@localhost ~]# docker run -itd --name box2 busybox
2、关闭防火墙(都关闭)
[root@localhost ~]# systemctl stop firewalld
3、查看box2IP并进行ping测试:
主机2:
[root@localhost ~]# docker exec -it box2 ip a
11: eth0@if12: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:2a:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.42.2/24 brd 172.17.42.255 scope global eth0
box1 ping box2 :
[root@localhost ~]# docker exec -it box1 ping 172.17.42.2
PING 172.17.42.2 (172.17.42.2): 56 data bytes
64 bytes from 172.17.42.2: seq=0 ttl=63 time=5.036 ms
64 bytes from 172.17.42.2: seq=1 ttl=63 time=0.666 ms
box2 ping box1:
[root@localhost ~]# docker exec -it box2 ping 172.17.43.2
PING 172.17.43.2 (172.17.43.2): 56 data bytes
64 bytes from 172.17.43.2: seq=0 ttl=63 time=4.360 ms
64 bytes from 172.17.43.2: seq=1 ttl=63 time=2.052 ms
https://www.cnblogs.com/xiao987334176/p/11405416.html
https://cloud.tencent.com/developer/article/1831538
四、利用Calico实现docker容器跨主机互联
Calico是一个纯三层的虚拟网络,它会为每个容器分配一个ip,每个host都是router,把不同host的容器连接起来,从而实现跨主机间容器通信。与vxlan不同的是,calico网络不对数据包进行额外封装,不需要NAT和端口映射,扩展性和 性能都很好。Calico网络提供了Docker DNS服务, 容器之间可以通过hostname访问。
Calico的通信过程:
Calico把每个操作系统的协议栈当作一个路由器,认为所有的容器是连接在这个路由器上的网络终端,在路由器之间运行标准的路由协议-BGP,然后让他们自己去学习这个网络拓扑该如何转发。
Calico网络方式(两种)
1)IPIP
从字面来理解,就是把一个IP数据包又套在一个IP包里,即把 IP 层封装到 IP 层的一个 tunnel,看起来似乎是浪费,实则不然。它的作用其实基本上就相当于一个基于IP层的网桥!一般来说,普通的网桥是基于mac层的,根本不需 IP,而这个 ipip 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。ipip 的源代码在内核 net/ipv4/ipip.c 中可以找到。
2)BGP
边界网关协议(Border Gateway Protocol, BGP)是互联网上一个核心的去中心化自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而使用基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议。BGP,通俗的讲就是讲接入到机房的多条线路(如电信、联通、移动等)融合为一体,实现多线单IP,BGP 机房的优点:服务器只需要设置一个IP地址,最佳访问路由是由网络上的骨干路由器根据路由跳数与其它技术指标来确定的,不会占用服务器的任何系统。
当容器通过calico进行跨主机通信时,其网络通信模型如下图所示:
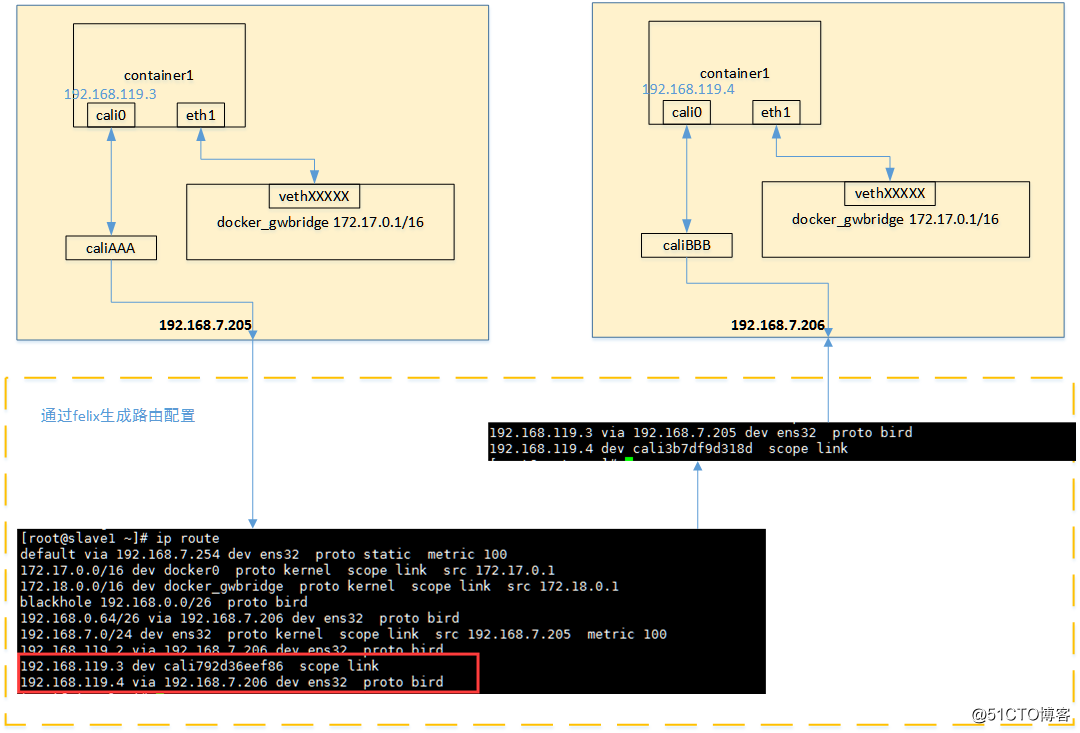
从上图可以看出,当容器创建时,calico为容器生成veth pair,一端作为容器网卡加入到容器的网络命名空间,并设置IP和掩码,一端直接暴露在宿主机上,
并通过设置路由规则,将容器IP暴露到宿主机的通信路由上。于此同时,calico为每个主机分配了一段子网作为容器可分配的IP范围,这样就可以根据子网的CIDR为每个主机生成比较固定的路由规则。
当容器需要跨主机通信时,主要经过下面的简单步骤:
- 容器流量通过veth pair到达宿主机的网络命名空间上。
- 根据容器要访问的IP所在的子网CIDR和主机上的路由规则,找到下一跳要到达的宿主机IP。
- 流量到达下一跳的宿主机后,根据当前宿主机上的路由规则,直接到达对端容器的veth pair插在宿主机的一端,最终进入容器。
从上面的通信过程来看,跨主机通信时,整个通信路径完全没有使用NAT或者UDP封装,性能上的损耗确实比较低。但正式由于calico的通信机制是完全基于三层的,这种机制也带来了一些缺陷,例如:
- calico目前只支持TCP、UDP、ICMP、ICMPv6协议,如果使用其他四层协议(例如NetBIOS协议),建议使用weave、原生overlay等其他overlay网络实现。
- 基于三层实现通信,在二层上没有任何加密包装,因此只能在私有的可靠网络上使用。
- 流量隔离基于iptables实现,并且从etcd中获取需要生成的隔离规则,有一些性能上的隐患。
(1)环境准备
192.168.1.130 docker-h1 安装docker+etcd+calicoctl
192.168.1.131 docker-h2 安装docker+etcd+calicoctl
192.168.1.132 docker-h3 安装docker+etcd+calicoctl
1、修改三个节点的主机名
[root@localhost ~]# hostnamectl set-hostname docker-h1
[root@localhost ~]# bash
[root@docker-h1 ~]#
[root@localhost ~]# hostnamectl set-hostname docker-h2
[root@localhost ~]# bash
[root@docker-h1 ~]#
[root@localhost ~]# hostnamectl set-hostname docker-h3
[root@localhost ~]# bash
[root@docker-h1 ~]#
2、配置防火墙(都执行)
[root@localhost ~]# firewall-cmd --zone=public --add-port=2379/tcp --permanent
[root@localhost ~]# firewall-cmd --zone=public --add-port=2380/tcp --permanent
[root@localhost ~]# firewall-cmd --reload
3、配置host(三台都添加)
[root@docker-h3 ~]# vim /etc/hosts
192.168.1.130 docker-h1
192.168.1.131 docker-h2
192.168.1.132 docker-h3
:wq
4、三台集机器上的ip转发功能打开
[root@docker-h1 ~]# vim /etc/sysctl.d/99-sysctl.conf
net.ipv4.ip_forward=1
[root@docker-h1 ~]# sysctl -p
net.ipv4.ip_forward = 1
(2)构建etcd集群环境
1、三个节点都要安装etcd
配置etcd集群
docker-h1节点配置
[root@docker-h1 ~]# yum install -y etcd
[root@docker-h1 ~]# cp /etc/etcd/etcd.conf /etc/etcd/etcd.conf.bak
[root@docker-h1 ~]# > /etc/etcd/etcd.conf #清空配置文件
[root@docker-h1 ~]# vim /etc/etcd/etcd.conf
#[Member]
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_NAME="docker-h1"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.1.130:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.1.130:2379"
ETCD_INITIAL_CLUSTER="docker-h1= http://192.168.1.130:2380,docker-h2=http://192.168.1.131:2380 ,docker-h3=http://192.168.1.132:2380"
:wq
docker-h2节点配置
[root@docker-h2 ~]# yum install -y etcd
[root@docker-h2 ~]# cp /etc/etcd/etcd.conf /etc/etcd/etcd.conf.bak
[root@docker-h2 ~]# > /etc/etcd/etcd.conf #清空配置文件
[root@docker-h2 ~]# vim /etc/etcd/etcd.conf
#[Member]
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_NAME="docker-h2"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.1.131:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.1.131:2379"
ETCD_INITIAL_CLUSTER="docker-h1= http://192.168.1.130:2380,docker-h2=http://192.168.1.131:2380 ,docker-h3=http://192.168.1.132:2380"
:wq
docker-h3节点配置
[root@docker-h3 ~]# yum install -y etcd
[root@docker-h3 ~]# cp /etc/etcd/etcd.conf /etc/etcd/etcd.conf.bak
[root@docker-h3 ~]# > /etc/etcd/etcd.conf #清空配置文件
[root@docker-h3 ~]# vim /etc/etcd/etcd.conf
#[Member]
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="http://0.0.0.0:2380"
ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379"
ETCD_NAME="docker-h3"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://192.168.1.132:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.1.132:2379"
ETCD_INITIAL_CLUSTER="docker-h1= http://192.168.1.130:2380,docker-h2=http://192.168.1.131:2380 ,docker-h3=http://192.168.1.132:2380"
:wq
(3)配置docker,****使docker支持etcd
1、在ExecStart区域内添加 (在--seccomp-profile 这一行的下面一行添加)
docker-h1节点:
[root@docker-h1 ~]# cp /usr/lib/systemd/system/docker.service /usr/lib/systemd/system/docker.service.bak
[root@docker-h1 ~]# vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --cluster-store=etcd://192.168.1.130:2379
:wq
[root@docker-h1 ~]# systemctl daemon-reload
[root@docker-h1 ~]# systemctl restart docker
docker-h2节点:
[root@docker-h2 ~]# cp /usr/lib/systemd/system/docker.service /usr/lib/systemd/system/docker.service.bak
[root@docker-h2 ~]# vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --cluster-store=etcd://192.168.1.131:2379
:wq
[root@docker-h2 ~]# systemctl daemon-reload
[root@docker-h2 ~]# systemctl restart docker
docker-h3节点:
[root@docker-h3 ~]# cp /usr/lib/systemd/system/docker.service /usr/lib/systemd/system/docker.service.bak
[root@docker-h3 ~]# vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --cluster-store=etcd://192.168.1.132:2379
:wq
[root@docker-h3 ~]# systemctl daemon-reload
[root@docker-h3 ~]# systemctl restart docker
2、启动etcd(都同时启动)
[root@docker-h1 ~]# systemctl enable etcd
[root@docker-h1 ~]# systemctl start etcd
如上修改并重启docker服务后, 查看各个节点,发现当前docker支持了etcd (这里以docker-h1节点为例)
[root@docker-h1 ~]# ps -ef | grep etcd
root 5560 1 0 11:04 ? 00:00:00 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --cluster-store=etcd://192.168.1.130:2379
etcd 6018 1 8 11:11 ? 00:00:09 /usr/bin/etcd --name=docker-h1 --data-dir=/var/lib/etcd/default.etcd --listen-client-urls=http://0.0.0.0:2379
root 6079 3373 0 11:13 pts/0 00:00:00 grep --color=auto etcd
3、查看集群成员(在三个节点机任意一个上面查看都可以,因为做的是集群环境):
[root@docker-h1 ~]# etcdctl member list
40e38850dd79d4e8: name=docker-h3 peerURLs=http://192.168.1.132:2380 clientURLs=http://192.168.1.132:2379 isLeader=false
5668b6b06e94b836: name=docker-h1 peerURLs=http://192.168.1.130:2380 clientURLs=http://192.168.1.130:2379 isLeader=true
9b107fbccfd1a05d: name=docker-h2 peerURLs=http://192.168.1.131:2380 clientURLs=http://192.168.1.131:2379 isLeader=false
温馨提示:
如果/etc/etcd/etcd.conf配置错误,etcd服务启动了,然后再次修改后重启etcd,发现没有生效!
查看日志命令为"journalctl -xe",发现下面错误信息:
the server is already initialized as member before, starting as etcd member...
......
simple token is not cryptographically signed
解决办法:
1) 删除各个节点的/var/lib/etcd/default.etcd/目录下的数据,即"rm -rf /var/lib/etcd/default.etcd/*"
2) 检查/etc/etcd/etcd.conf文件是否配置正确
3) 重新启动etcd服务,即"systemctl stop etcd && systemctl start etcd" , 这样新配置就会重新生效了!
(4)安装calico网络通信环境
1、三个节点最好都要先下载calico容器镜像
docker pull quay.io/calico/node:v2.6.10
[root@docker-h1 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
quay.io/calico/node v2.6.10 3b2408e59c95 3 years ago 280MB
2、安装calicoctl
这里选择v1.1.0版本(三台节点机都要安装)
[root@docker-h1 ~]# wget https://github.com/projectcalico/calicoctl/releases/download/v1.1.0/calicoctl
[root@docker-h1 ~]# chmod 755 calicoctl
[root@docker-h1 ~]# mv calicoctl /usr/local/bin/
[root@docker-h1 ~]# calicoctl --version
calicoctl version v1.1.0, build 882dd008
3、分别在个三节点上创建calico容器
docker-h1节点
[root@docker-h1 ~]# docker run --net=host --privileged --name=calico-docker-h1 -d --restart=always -e NODENAME=docker-h1 -e CALICO_NETWORKING_BACKEND=bird -e CALICO_LIBNETWORK_ENABLED=true -e IP=192.168.1.130 -e ETCD_ENDPOINTS=http://127.0.0.1:2379 -v /var/log/calico:/var/log/calico -v /var/run/calico:/var/run/calico -v /lib/modules:/lib/modules -v /run:/run -v /run/docker/plugins:/run/docker/plugins -v /var/run/docker.sock:/var/run/docker.sock quay.io/calico/node:v2.6.10
docker-h2节点
[root@docker-h2 ~]# docker run --net=host --privileged --name=calico-docker-h2 -d --restart=always -e NODENAME=docker-h2 -e CALICO_NETWORKING_BACKEND=bird -e CALICO_LIBNETWORK_ENABLED=true -e IP=192.168.1.131 -e ETCD_ENDPOINTS=http://127.0.0.1:2379 -v /var/log/calico:/var/log/calico -v /var/run/calico:/var/run/calico -v /lib/modules:/lib/modules -v /run:/run -v /run/docker/plugins:/run/docker/plugins -v /var/run/docker.sock:/var/run/docker.sock quay.io/calico/node:v2.6.10
docker-h3节点
[root@docker-h2 ~]# docker run --net=host --privileged --name=calico-docker-h3 -d --restart=always -e NODENAME=docker-h3 -e CALICO_NETWORKING_BACKEND=bird -e CALICO_LIBNETWORK_ENABLED=true -e IP=192.168.1.132 -e ETCD_ENDPOINTS=http://127.0.0.1:2379 -v /var/log/calico:/var/log/calico -v /var/run/calico:/var/run/calico -v /lib/modules:/lib/modules -v /run:/run -v /run/docker/plugins:/run/docker/plugins -v /var/run/docker.sock:/var/run/docker.sock quay.io/calico/node:v2.6.10
4、查看各个节点的calico容器创建情况 (这里以docker-h1节点为例,其他两个节点查看一样)
[root@docker-h1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d53487eec979 quay.io/calico/node:v2.6.10 "start_runit" 2 minutes ago Up 2 minutes calico-docker-h1
[root@docker-h1 ~]# ps -ef|grep calico
root 10483 10478 0 14:44 ? 00:00:00 svlogd /var/log/calico/felix
root 10484 10481 0 14:44 ? 00:00:00 svlogd /var/log/calico/confd
root 10485 10482 0 14:44 ? 00:00:00 svlogd /var/log/calico/libnetwork
root 10486 10478 4 14:44 ? 00:00:06 calico-felix
root 10487 10481 0 14:44 ? 00:00:00 confd -confdir=/etc/calico/confd -interval=5 -watch --log-level=info -node=http://127.0.0.1:2379 -client-key= -client-cert= -client-ca-keys=
root 10491 10479 0 14:44 ? 00:00:00 svlogd -tt /var/log/calico/bird
root 10492 10480 0 14:44 ? 00:00:00 svlogd -tt /var/log/calico/bird6
root 10493 10479 0 14:44 ? 00:00:00 bird -R -s /var/run/calico/bird.ctl -d -c /etc/calico/confd/config/bird.cfg
root 10494 10480 0 14:44 ? 00:00:00 bird6 -R -s /var/run/calico/bird6.ctl -d -c /etc/calico/confd/config/bird6.cfg
root 10781 3373 0 14:46 pts/0 00:00:00 grep --color=auto calico
5、查看calico状态(docker-h1为例)
[root@docker-h1 ~]# calicoctl node status
Calico process is running.
IPv4 BGP status
+---------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+---------------+-------------------+-------+----------+-------------+
| 192.168.1.131 | node-to-node mesh | up | 06:44:27 | Established |
| 192.168.1.132 | node-to-node mesh | up | 06:44:43 | Established |
+---------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
6、停止calico服务(都停止了)
[root@docker-h1 ~]# docker stop calico-docker-h1
[root@docker-h2 ~]# docker stop calico-docker-h2
[root@docker-h3 ~]# docker stop calico-docker-h3
(5)添加calico网络
1、为各个节点的calico网络添加可用的ip pool。这里采用ipip模式(即enabled为true)
docker-h1节点操作(该节点的容器网段为10.0.10.0/24。注意:子网掩码是24,故必须是*.*.*.0/24;如果是16位子网掩码,则是*.*.0.0/16)
[root@docker-h1 ~]# vim ipPool.yaml
apiVersion: v1
kind: ipPool
metadata:
cidr: 17.16.10.0/24
spec:
ipip:
enabled: true
nat-outgoing: true
disabled: false
:wq
[root@docker-h2 ~]# calicoctl create -f ipPool.yaml
Successfully created 1 'ipPool' resource(s)
docker-h2节点操作:
[root@docker-h2 ~]# vim ipPool.yaml
apiVersion: v1
kind: ipPool
metadata:
cidr: 192.10.160.0/24
spec:
ipip:
enabled: true
nat-outgoing: true
disabled: false
:wq
[root@docker-h2 ~]# calicoctl create -f ipPool.yaml
Successfully created 1 'ipPool' resource(s)
docker-h3节点操作:
[root@docker-h3 ~]# vim ipPool.yaml
apiVersion: v1
kind: ipPool
metadata:
cidr: 173.20.19.0/24
spec:
ipip:
enabled: true
nat-outgoing: true
disabled: false
:wq
[root@docker-h3 ~]# calicoctl create -f ipPool.yaml
Successfully created 1 'ipPool' resource(s)
//温馨提示:
如果是删除一个ip pool,命令是"calicoctl delete -f ipPool.yaml"
2、在任意一个节点上查看添加的ip pool情况
[root@docker-h1 ~]# calicoctl get ipPool
CIDR
17.16.10.0/24
173.20.19.0/24
192.10.160.0/24
192.168.0.0/16
fd80:24e2:f998:72d6::/64
[root@docker-h1 ~]# calicoctl get ipPool -o wide
CIDR NAT IPIP
17.16.10.0/24 true true
173.20.19.0/24 true true
192.10.160.0/24 true true
192.168.0.0/16 true false
fd80:24e2:f998:72d6::/64 false false
3、接着在上面创建的ip pool(10.16.10.1/24 、192.10.160.1/24、173.20.19.1/24 )里创建子网络。
可以从三个中选择一个或全部去创建子网络。
如下创建了calico-net1,calico-net2和calico-net3三个不同的网络。
三台节点先重启docker:
systemctl restart docker
创建命令可以在任意一个节点上执行即可。我这里在docker-h1创建:
[root@docker-h1 ~]# docker network create --driver calico --ipam-driver calico-ipam --subnet 17.16.10.0/24 calico-net1
[root@docker-h1 ~]# docker network create --driver calico --ipam-driver calico-ipam --subnet 173.20.19.0/24 calico-net2
[root@docker-h1 ~]# docker network create --driver calico --ipam-driver calico-ipam --subnet 192.10.160.0/24 calico-net3
参数解释:
--driver calico: 网络使用 calico 驱动
--ipam-driver calico-ipam: 指定使用 calico 的 IPAM 驱动管理 IP
--subnet:指定calico-net1、calico-net2、calico-net3的 IP 段
calico-net1、calico-net2、calico-net3是 global 网络,etcd 会将它们三个同步到所有主机
由于三个节点使用的是同一套etcd,所以子网络创建后,在另一个节点上可以通过docker network ls命令查看到生成的网络信息:
[root@docker-h2 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
e06c4811c9f7 bridge bridge local
8e724bc60223 calico-net1 calico global
d47a91d06e0d calico-net2 calico global
9c61d88bd43f calico-net3 calico global
d056cef19eee host host local
060dd76b27fc none null local
4、各个节点上使用上面创建的子网去创建容器.
docker-h1创建:
docker run -itd --net calico-net1 --name=box1 busybox
docker run -itd --net calico-net2 --name=box2 busybox
docker run -itd --net calico-net3 --name=box3 busybox
docker-h2创建:
docker run -itd --net calico-net1 --name=box4 busybox
docker run -itd --net calico-net2 --name=box5 busybox
docker run -itd --net calico-net3 --name=box6 busybox
docker-h3创建:
docker run -itd --net calico-net1 --name=box7 busybox
docker run -itd --net calico-net2 --name=box8 busybox
docker run -itd --net calico-net3 --name=box9 busybox
5、验证容器之间的通信
测试先的关闭防火墙:
systrmctl stop firewalld
5.1、calico-net1之间进行ping测试
box1 ping box4、7:
同一网络内的容器(即使不在同一节点主机上)可以使用容器名来访问,不同网段是不可以的。
[root@docker-h1 ~]# docker exec -it box1 ping box4
PING box4 (17.16.10.129): 56 data bytes
64 bytes from 17.16.10.129: seq=0 ttl=62 time=2.295 ms
64 bytes from 17.16.10.129: seq=1 ttl=62 time=1.011 ms
[root@docker-h1 ~]# docker exec -it box1 ping box7
PING box7 (17.16.10.193): 56 data bytes
64 bytes from 17.16.10.193: seq=0 ttl=62 time=0.800 ms
我们尝试box1 ping box6是ping不通的:
[root@docker-h1 ~]# docker exec -it box1 ping 192.10.160.128
PING 192.10.160.128 (192.10.160.128): 56 data bytes
测试结论:
-
同一个网段中容器能相互ping的通 (即使不在同一个节点上,只要创建容器时使用的是同一个子网段);
-
不在同一个子网段里的容器是相互ping不通的 (即使在同一个节点上,但是创建容器时使用的是不同子网段);
-
宿主机能ping通它自身的所有容器ip,但不能ping通其他节点上的容器ip;
-
所有节点的容器都能ping通其他节点宿主机的ip (包括容器自己所在的宿主机的ip)。
也就是说,Calico默认配置下,只允许位于同一个网络中的容器之间通信,这样即实现了容器的跨主机互连, 也能更好的达到网络隔离效果。如果位于不同网络下的容器要想通信,只能依赖Calico的Policy策略来实现了,它强大的Policy能够实现几乎任意场景的访问控制!
跨主机网络方案的对比:
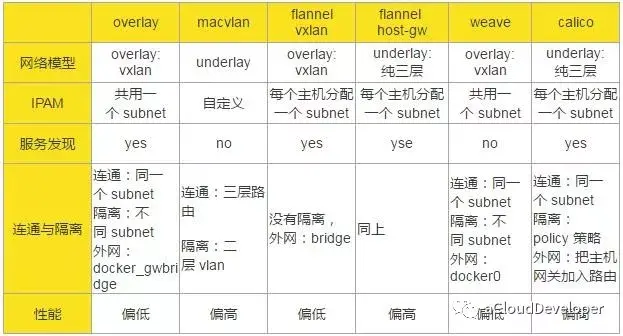

 浙公网安备 33010602011771号
浙公网安备 33010602011771号