一.docker介绍(2)
docker介绍
6.docker联合文件系统:
docker主要是基于 Namespace、cgroups 和联合文件系统这三大核心技术实现的。
联合文件系统(Union File System,Unionfs)是一种分层的轻量文件系统,它可以把很多的目录内容联合挂载到同一目录下,从而形成一个单一的文件系统,这种特性可以让使用者像是使用一个目录一样使用联合文件系统。
联合文件系统是Docker镜像和容器的基础,因为它可以使Docker可以把镜像做成分层结构,从而使得镜像的每一层都可以被共享。例如mysql、php两个都是基于Centos7镜像构建的,那么这两个业务镜像在物理机上只需要存储一次 CentOS 7 这个基础镜像即可,从而节省大量存储空间。
联合文件系统在主机上使用多层目录存储,但最终呈现给用户的则是一个普通单层的文件系统,我们把多层以单一层的方式呈现出来的过程叫作联合挂载。
说到这儿,你有没有发现,联合文件系统只是一个概念,真正实现联合文件系统才是关键,那如何实现呢?其实实现方案有很多,Docker 中最常用的联合文件系统有三种:AUFS、Devicemapper 和 OverlayFS。
1.AUFS文件系统
AUFS 是 Docker 最早使用的文件系统驱动,多用于 Ubuntu 和 Debian 系统中。在 Docker 早期,OverlayFS 和 Devicemapper 相对不够成熟,AUFS 是最早也是最稳定的文件系统驱动。docker现在使用的是OverlayFS2文件系统。 接下来,我们就看看如何配置 Docker 的 AUFS 模式。
配置docker的AUFS模式
AUFS目前并未被合并到Linux内核主线,所以只有Ubuntu和Debian等少数****操作系统支持AUFS,使用以下作用命令可以查看系统是否支持AUFS:
$ grep aufs /proc/filesystems
nodev aufs
执行上面命令后,如果输出结果包含aufs,则代表当前操作系统支持aufs。AUFS 推荐在 Ubuntu 或 Debian 操作系统下使用,如果你想要在 CentOS 等操作系统下使用 AUFS,需要单独安装 AUFS 模块(生产环境不推荐在 CentOS 下使用 AUFS,如果你想在 CentOS 下安装 AUFS 用于研究和测试,可以参考这个链接),安装完成后使用上述命令输出结果中有aufs即可。
当确认完操作系统支持 AUFS 后,你就可以配置 Docker 的启动参数了。
在/etc/docker下新建daemon.json文件,写入以下内容:
{
"storage-driver": "aufs"
}
重启docker并查看是否修改为AUFS存储方式:
service docker restart
docker info
查看 Storage Driver:的选项是否为 Storage Driver: aufs。是证明配置已经生效,配置生效后就可以使用 AUFS 为 Docker 提供联合文件系统了。
AUFS工作原理:
AUFS是联合文件系统,意味着它在主机上使用多层目录存储,每一个目录在AUFS中都叫做分支,而在docker中则称为层(layer),但最终呈现给用户的则是一个普通单层的文件系统,我们把多层以单一层的方式呈现出来的过程叫做联合挂载****。
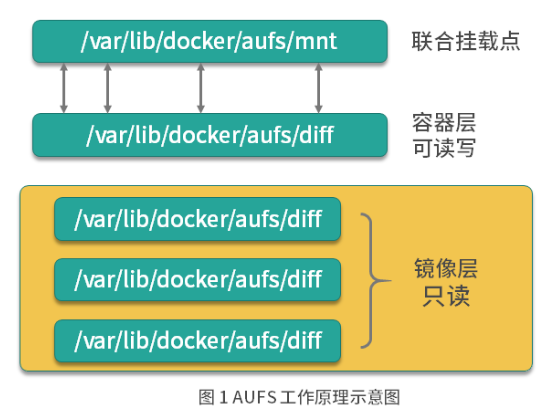
每一个镜像层和容器层都是 /var/lib/docker 下的一个子目录,镜像层和容器层都在 aufs/diff 目录下,每一层的目录名称是镜像或容器的 ID 值,联合挂载点在 aufs/mnt 目录下,mnt 目录是真正的容器工作目录。
下面我们针对aufs文件夹下的各目录结构,在创建容器前后的变化做详细的讲述!
当一个镜像未生成容器的时候,AUFS的存储结构如下:AUFS的工作目录在/var/lib/docker/aufs/下。
-
diff文件夹:存储镜像内容的文件夹,每一层都存储在以镜像层ID命名的子文件夹中。
-
layers文件夹:存储镜像层关系的元数据,在diff文件夹下的每个镜像层在这里都会有个文件,文件的内容为该镜像的父级镜像的ID。
-
mnt文件夹:联合关挂载点目录,未生成容器时,该目录为空。
当一个镜像已经生成容器的时候,AUFS存储结构会发生以下变化: -
diff 文件夹:当容器运行时,会在 diff 目录下生成容器层。
-
layers 文件夹:增加容器层相关的元数据。
-
mnt 文件夹:容器的联合挂载点,这和容器中看到的文件内容一致。
以上便是 AUFS 的工作原理,那你知道容器的在工作过程中是如何使用 AUFS 的吗?
AUFS的工作过程中对文件的操作分为读取文件和修改文件。
(1)读取文件
当我们在容器读取文件的时候,可能会有以下场景。
- 文件在容器层存在时:当文件存在于容器层的时候,直接从容器层读取。
- 当文件在容器层中不存在时:当容器运行时需要读取某个文件,如果容器层中不存在时,则从镜像层查找该文件,然后读取文件内容。
- 文件即存在镜像层,又存在容器层:当我们读取的文件既存在于镜像层,又存在于容器层时,将会从容器层读取该文件。【由于写时复制(看(2)),所以此时肯定是修改过的文件才会复制到容器层,所以应该读取容器层的文件】。
(2)修改文件
AUFS对文件的修改采用的是写时复制的工作机制,这种工作机制可以最大程度的节省空间。具体的文件操作机制如下:
-
第一次修改文件:当我们第一次在容器中修改某个文件时,AUFS会触发写时复制操作,AUFS首先从镜像层复制文件到容器层,然后再执行对应的操作。
注意:AUFS写时复制的操作将会复制整个文件,如果文件过大将会大大降低文件系统的性能,所以当我们又大量文件需要需要被修改时,AUFS可能会出现明显的延迟。这个问题不要担心,因为写时复制只在第一次修改文件的时候触发。下次再修改就不需要进行复制。 -
删除文件或目录:当文件或目录被删除时,AUFS并不会真正从镜像中删除它,因为镜像层是只读的,AUFS会创建一个特殊的文件或文件夹,这种特殊的文件或文件夹会阻止容器的访问。
利用ubuntu镜像进行实验:
1、运行容器并在容器中创建文件:
docker run -it ubuntu bin/bash
root@86a66e158d97:/# ls
bin boot dev etc home lib lib32 lib64 libx32 media mnt opt proc root run sbin srv sys tmp usr var
root@86a66e158d97:/# touch /home/test.txt
root@86a66e158d97:/# echo hello world > /home/test.txt
root@86a66e158d97:/# cat /home/test.txt
hello world
2.查看ubuntu镜像文件的rootfs
docker image inspect ubuntu
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:c5ec52c98b3193052e15d783aca2bef10d8d829fa0d58fedfede511920b8f997"
上面这个Layers的值是你在pull镜像的层数!
根据输出结果显示,ubuntu的rootfs文件包含一层,都是 Ubuntu 操作系统文件与目录的一部分。
3、查看容器的镜像层和容器层的标识。
docker run -dit ubuntu
cd /sys/fs/aufs/si_a9ebb2b9 #注意si_a9ebb2b9 是随机生成的。
cat *
/var/lib/docker/aufs/diff/49c605d6605be5ed2d60cc97fedf0193b56e1684e1721f5b1fc1c50563e0e957=rw
/var/lib/docker/aufs/diff/49c605d6605be5ed2d60cc97fedf0193b56e1684e1721f5b1fc1c50563e0e957-init=ro+wh
/var/lib/docker/aufs/diff/9e9cd76bc90618bf2d3193406701ef6b4361f61547fc04ef8642c8d8b18c2c8e=ro+wh
通过上面的输出结果可以看出,在目录/var/lib/docker/aufs/diff 下的容器层文件和镜像层文件分别为:
可读写的容器层:(这一层是从镜像层复制出来的)
49c605d6605be5ed2d60cc97fedf0193b56e1684e1721f5b1fc1c50563e0e957
以下的都是只读镜像层:
49c605d6605be5ed2d60cc97fedf0193b56e1684e1721f5b1fc1c50563e0e957-init
9e9cd76bc90618bf2d3193406701ef6b4361f61547fc04ef8642c8d8b18c2c8e

Init 层。它是一个以“-init”结尾的层,夹在只读层和读写层之间。Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。
需要这样一层的原因是,这些文件本来属于只读的 Ubuntu 镜像的一部分,但是用户往往需要在启动容器时写入一些指定的值比如 hostname,所以就需要在可读写层对它们进行修改。可是,这些修改往往只对当前的容器有效,我们并不希望执行 docker commit 时,把这些信息连同可读写层一起提交掉。
查看 /var/lib/docker/aufs/diff 验证:
ls /var/lib/docker/aufs/diff
49c605d6605be5ed2d60cc97fedf0193b56e1684e1721f5b1fc1c50563e0e957
49c605d6605be5ed2d60cc97fedf0193b56e1684e1721f5b1fc1c50563e0e957-init
9e9cd76bc90618bf2d3193406701ef6b4361f61547fc04ef8642c8d8b18c2c8e
进入diff文件夹,查看对应的文件信息
cd /var/lib/docker/aufs/diff
cd 49c605d6605be5ed2d60cc97fedf0193b56e1684e1721f5b1fc1c50563e0e957
root@hack:/var/lib/docker/aufs/diff/49c605d6605be5ed2d60cc97fedf0193b56e1684e1721f5b1fc1c50563e0e957/home# ls
test.txt
root@hack:/var/lib/docker/aufs/diff/49c605d6605be5ed2d60cc97fedf0193b56e1684e1721f5b1fc1c50563e0e957/home# cat test.txt
hello world
通过输出结果显示,容器中新建的数据信息存储在容器层中。
修改镜像文件层:
cd /var/lib/docker/aufs/diff/9e9cd76bc90618bf2d3193406701ef6b4361f61547fc04ef8642c8d8b18c2c8e
vim etc/apt/sources.list
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
:wq
进入容器然后更新apt查看是否将源换为了aliyun源
docker exec -it 86a66e158d97 /bin/bash
root@86a66e158d97:/# apt-get update
Get:1 http://mirrors.aliyun.com/ubuntu bionic-security InRelease [88.7 kB]
Get:2 http://mirrors.aliyun.com/ubuntu bionic-updates InRelease [88.7 kB]
Get:3 http://mirrors.aliyun.com/ubuntu bionic-proposed InRelease [242 kB]
Get:4 http://mirrors.aliyun.com/ubuntu bionic-backports InRelease [74.6 kB]
Get:5 http://mirrors.aliyun.com/ubuntu bionic InRelease [242 kB]
Get:6 http://mirrors.aliyun.com/ubuntu bionic-security/universe Sources [368 kB]
上述结果说明在容器中对source.list文件进行修改后,它被拷贝到了容器层然后被修改了。这就是AUFS读取文件的特性。他会从镜像层复制到容器层。
但是如果在容器里修改source.list文件,他会从镜像层复制这个文件,然后进行修改。镜像的source.list不会被修改,
最终,这三层都被联合挂载到 /var/lib/docker/aufs/mnt 目录下,表现为一个完整的 Ubuntu 操作系统供容器使用。
cd /var/lib/docker/aufs/mnt/49c605d6605be5ed2d60cc97fedf0193b56e1684e1721f5b1fc1c50563e0e957
root@hack:/var/lib/docker/aufs/mnt/49c605d6605be5ed2d60cc97fedf0193b56e1684e1721f5b1fc1c50563e0e957# ls
bin boot dev etc home lib lib32 lib64 libx32 media mnt opt proc root run sbin srv sys tmp usr var
以上就是通过联合文件系统组合成的容器!
2.Devicemapper文件系统
思考一个问题:在centos系统中,怎样实现镜像和容器的分层结构?
什么是Devicemapper文件系统?
Dervicemapper是linux内核提供的框架,从linux内核2.6.9版本开始引入,Dervicemapper与AUFS不同,AUFS是文件系统,而Devicemapper是一种映射块设备的技术框架****。Dervicemapper提供了一种将物理设备映射到虚拟块设备的机制,目前linux下比较流行的LVM(Logical Volume Manager是linux下对磁盘分区进行管理的一种机制)和软件磁盘阵列(将多个较小的磁盘整合为一个较大的磁盘设备用于扩大磁盘存储和提供数据可用性)都是基于Dervicemapper机制实现的。
Dervicemapper****关键技术:
Dervicemapper将主要的工作部分分为用户空间和内核空间。
- 用户空间负责配置具体的设备映射策略与相关的内核空间控制逻辑,例如逻辑设备dm-a(Dervicemapper通过技术模拟的一个模拟设备)如何与物理设备sda相关联,怎么建立逻辑设备和物理设备的映射关系。
- 内核空间则负责用户空间配置的关联关系发现,例如当IO请求到达虚拟机设备dm-a时,内核空间负责接管IO请求,然后处理和过滤这些IO请求并转发到具体的物理设备上。
这种架构类似于C/S(客户端/服务器端)架构的工作模式,客户端负责具体的规则定义和配置下发,服务端根据客户端的规则来执行具体的处理任务。
Dervicemapper的核心理念:
Dervicemapper的工作机制主要围绕三个核心概念:
- 映射设备(mapped device):即对外提供逻辑设备,它是由Dervicemapper模拟的一个虚拟设备,并不是真正的存在于宿主机(物理机)上的物理设备。
- 目标设备(target dervice):目标设备是映射设备对应的物理设备或者物理设备的某一个逻辑分段,是真正存在于物理机上的设备。
- 映射表(map table):映射表记录了映射设备到目标设备的映射关系。它记录了映射设备在目标设备的起始地址、范围和目标设备的类型等变量。
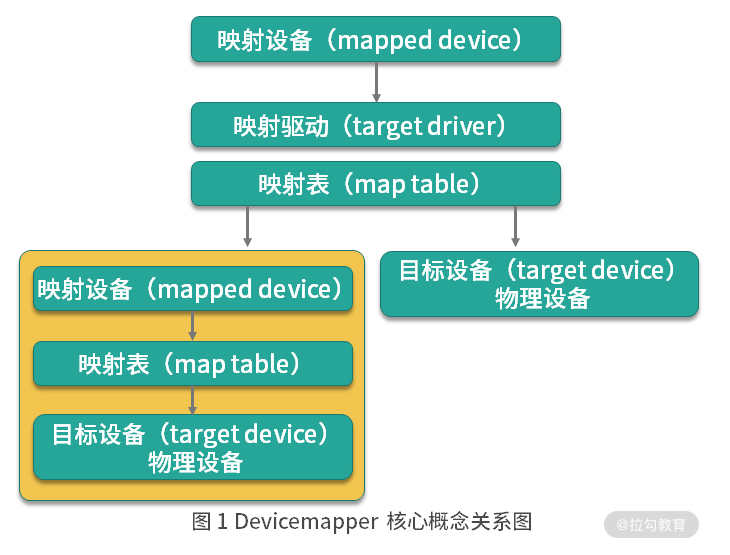
从上图我们可以看出:映射设备通过映射表关联到具体的物理目标设备上。其实,映射设备不仅可以通过映射表关联到物理目标设备,也可以关联到虚拟目标设备,然后虚拟目标设备在通过映射表关联到物理目标设备。也就是俗称的套娃。
Devicemapper在内核中通过很多模块化的映射驱动(target driver)插件实现了对真正IO请求拦截、过滤和转发工作。例如Raid、软件加密、瘦供给(Thin Provisioning)等。其中瘦供给模块是Docker使用Dervicemapper技术框架中非常重要的模块。
瘦供给(Thin Provisioning)
瘦供给的意思就是动态分配,这跟传统的固定分配不一样。传统的固定分配时无论我们用多少都一次性分配一个较大的空间。这样可能导致空间浪费。而瘦供给是我们需要多少磁盘空间,存储驱动就帮我们分配多少磁盘空间。
这样的分配机制就好比一群人围着一个大锅吃饭,负责分配食物的人每次都给你分一点分量,当你感觉到食物不够的时候再去申请食物,而当你吃饱了就不需要再去申请食物了,从而避免了食物的浪费,节约食物可以分配给更多需要的人。
那么Docker是如何通过瘦供给进行分层存储文件的?
Docker采用了瘦供给的快照(snapshot)技术。
快照是数据在某一个时间的存储状态。快照的主要作用是对数据进行备份,当存储节点发生故障时,可以使用已经备份的快照将数据恢复到某一个时间点,类似于Vmare的快照技术。而基于Dervicemapper的Docker中的数据分层存储也是基于快照实现****的。
Docker使用Dervicemapper实现存储数据和镜像分层共享的实现
当Docker使用Dervicemapper作为文件存储驱动时,Docker将镜像和容器文件存储在瘦供给池(thinpool)中,并将这些内容挂载在/var/lib/docker/devicemapper/目录下。
这些目录存储Docker的容器和镜像的相关数据,目录的数据内容和功能说明如下:
* dervicemapper目录(/var/lib/docker/devicemapper/devicemapper/):存储镜像和容器的实际内容,该目录由一个或多个块设备构成。
* metdata目录(/var/lib/docker/devicemapper/metdata/):包含了Devicemapper本身配置的元数据信息,以json的形式配置,这些元数据记录了镜像层和容器层之间的关联信息。
* mnt目录(/var/lib/docker/devicemapper/mnt/):是容器的联合挂载点目录,未生成容器的时候,该目录为空,而当容器存在时,该目录下的内容和容器的内容一致。
Dervicemapper使用专用的块设备实现镜像的存储,并且像AUFS一样使用了写时复制的技术来保障最大程度节省存储空间,所以Devicemapper的镜像分层也是依赖快照来实现的。
Devicemapper的每一个镜像层都是其下一层的快照,最底层的镜像层是我们的瘦供给池,通过这种方式实现镜像分层有以下优点:
- 相同的镜像层,仅在磁盘上存储一次。例如:我有10个运行中的busybox容器,底层使用了busybox镜像,那么busybox镜像只需要在磁盘上存储一次即可。
- 快照是写时复制策略的实现,也就是说,当我们需要对文件进行修改时,文件才会被复制到读写层。
- 相比对文件系统加锁的机制,Devicemapper工作在块级别,因此可以实现同时修改和读写层中的多个块设备,比文件系统效率更高。
当我们需要读取数据时,如果数据存在底层快照中,则向底层快照查询数据并读取。当我们需要写数据时,则向瘦供池动态申请存储空间生成读写层,然后把数据复制到读写层进行修改。Devicemapper默认每次申请的大小时64K或者64K的倍数,因此每次新生成的读写层的大小都是64K或者64K的倍数。
以下是一个运行中的ubuntu16.04容器的示意图:
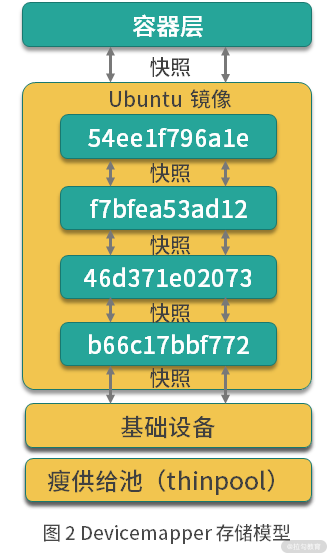
这个ubuntu16.04镜像一共有4层,每一层镜像都是下一层的快照,镜像的最底层是基础设备的快照。当容器运行时,容器时基于镜像的快照。所以,Devicemapper实现镜像分层的根本原理就是快照。
如何在Docker中配置Devicemapper
Docker的Devicemapper模式有两种:第一种是loop-ivm模式,该模式主要用来开发和测试使用;第二种是direct-lvm模式,该模式推荐在生产环境使用。
direct-lvm模式配置:
1.创建新的硬盘
2.配置磁盘
1.查看新添加的磁盘
[root@bogon ~]# fdisk -l /dev/sdb
磁盘 /dev/sdb:21.5 GB, 21474836480 字节,41943040 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
2.创建物理卷
pvcreate /dev/sdb
3.创建卷组
vgcreate docker /dev/sdb
4.创建逻辑卷
4.1创建瘦供给池逻辑卷
lvcreate --wipesignatures y -n thinpool docker -l 95%VG
4.2创建 metadata lv
lvcreate --wipesignatures y -n thinpoolmeta docker -l 1%VG
数据LV大小为VG的95%,元数据LV大小为VG的1%,剩余的4%空间用来自动扩展。
5.把池转换为thin池并将 thinpool lv 的 chunksize 改为 512KB,并且将前 4KB 字节清零。
lvconvert -y --zero n -c 512k --thinpool docker/thinpool --poolmetadata docker/thinpoolmeta
6.创建一个thinpool的profile
vim /etc/lvm/profile/docker-thinpool.profile
activation {
thin_pool_autoextend_threshold=80
thin_pool_autoextend_percent=20
}
:wq
定义一个百分比的阈值,表明触发 lvm 自动扩容前,已用空间占比。
thin_pool_autoextend_threshold = 80
每次扩容 thin pool 空间的比例
thin_pool_autoextend_percent = 20
7.应用配置
lvchange --metadataprofile docker-thinpool docker/thinpool
注意: docker-thinpool 即刚才创建的 profile 文件名的前缀,不需要加.profile,而且要在etc/lvm/profile 目录下运行此命令。 执行完毕后不要mount,不要格式化 lv。
3、安装docker并使用以下命令启动和停止已经运行的容器:
1.安装docker查看centos安装docker
systemctl start docker
systemctl stop docker
2.配置docker
vim /etc/docker/daemon.json
{
"storage-driver": "devicemapper",
"storage-opts": [
"dm.thinpooldev=/dev/mapper/docker-thinpool",
"dm.use_deferred_removal=true",
"dm.use_deferred_deletion=true"
]
}
systemctl daemon-reload
systemctl restart docker
4.验证 Docker 的文件驱动模式:
docker info
5.查看对应的设备:
lsblk /dev/sdb
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 0 20G 0 disk
├─docker-thinpool_tmeta 253:2 0 204M 0 lvm
│ └─docker-thinpool 253:4 0 19G 0 lvm
└─docker-thinpool_tdata 253:3 0 19G 0 lvm
└─docker-thinpool 253:4 0 19G 0 lvm
3.Overlay2文件系统
Overlay2是一个性能更好的联合文件系统。
Overlay2虽然好,但是又一定的条件限制。
- Docker版本必须大于17.06.02.
- 如果使用的操作系统是RHEL或Centos。linux内核版本必须使用3.10.0-514或者更高的版本,其他linux发行版本的内核版本必须大于4.0(ubuntu、debian),可以使用uname -a查看内核版本。
- overlay2最好搭配 xfs 文件系统使用,并且使用 xfs 作为底层文件系统时,d_type必须开启,可以使用以下命令验证 d_type 是否开启。
[root@bogon ~]# xfs_info /var/lib/docker | grep ftype
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
当输出结果中有ftype=1时,表示d_type已经开启,如果你的输出结果为ftype=0,则需要重启格式化磁盘目录,命令如下:
mkfs.xfs -f -n ftype=1 /dev/sd?
?代表第几块磁盘
另外,在生产环境中,推荐挂载 /var/lib/docker 目录到单独的磁盘或者磁盘分区,这样可以避免该目录写满影响主机的文件写入,并且把挂载信息写入到 /etc/fstab,防止机器重启后挂载信息丢失。
挂载配置中推荐开启 pquota,这样可以防止某个容器写文件溢出导致整个容器目录空间被占满。写入到 /etc/fstab 中的内容如下:
$UUID /var/lib/docker xfs defaults,pquota 0 0
其中 UUID 为 /var/lib/docker 所在磁盘或者分区的 UUID 或者磁盘路径。
如果你的操作系统无法满足上面的任何一个条件,那我推荐你使用 AUFS 或者 Devicemapper 作为你的 Docker 文件系统驱动。
通常情况下, overlay2 会比 AUFS 和 Devicemapper 性能更好,而且更加稳定,因为 overlay2 在 inode 优化上更加高效。因此在生产环境中推荐使用 overlay2 作为 Docker 的文件驱动。
下面我通过实例来教你如何初始化 /var/lib/docker 目录,为后面配置 Docker 的overlay2文件驱动做准备。初始化是为了不占用系统空间且有格外的磁盘,如果不想将docker的数据单独出来下面的步骤可以不弄。因为安装完成后的docker文件驱动时是使用的是overlay2.
1、添加一块硬盘:

2、使用lsblk(linux查看磁盘信息命令)查看本机磁盘信息:
[root@bogon ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 19G 0 part
├─centos-root 253:0 0 17G 0 lvm /
└─centos-swap 253:1 0 2G 0 lvm [SWAP]
sdb 8:16 0 20G 0 disk
sr0 11:0 1 4.2G 0 rom /run/media/root/CentOS 7 x86_64
目的:将/var/lib/docker挂载到sdb1分区上。
2、进行磁盘划分并将文件类型格式化为xfs
1.磁盘划分
[root@bogon ~]# fdisk /dev/sdb
欢迎使用 fdisk (util-linux 2.23.2)。
更改将停留在内存中,直到您决定将更改写入磁盘。
使用写入命令前请三思。
Device does not contain a recognized partition table
使用磁盘标识符 0x2c70e37b 创建新的 DOS 磁盘标签。
命令(输入 m 获取帮助):n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p): p
分区号 (1-4,默认 1):1
起始 扇区 (2048-41943039,默认为 2048):
将使用默认值 2048
Last 扇区, +扇区 or +size{K,M,G} (2048-41943039,默认为 41943039):
将使用默认值 41943039
分区 1 已设置为 Linux 类型,大小设为 20 GiB
命令(输入 m 获取帮助):p
磁盘 /dev/sdb:21.5 GB, 21474836480 字节,41943040 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0x2c70e37b
设备 Boot Start End Blocks Id System
/dev/sdb1 2048 41943039 20970496 83 Linux
命令(输入 m 获取帮助):wq
2.使用mkfs命令格式化磁盘sdb1
mkfs.xfs -f -n ftype=1 /dev/sdb1
3、将挂载信息写入到/etc/fstab,保证系统重启挂载目录不会丢失。
echo "/dev/sdb1 /var/lib/docker xfs defaults,pquota 0 0" >> /etc/fstab
4、使挂载目录生效并查看挂载信息
[root@bogon ~]# mount -a
[root@bogon ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 19G 0 part
├─centos-root 253:0 0 17G 0 lvm /
└─centos-swap 253:1 0 2G 0 lvm [SWAP]
sdb 8:16 0 20G 0 disk
└─sdb1 8:17 0 20G 0 part /var/lib/docker
sr0 11:0 1 4.2G 0 rom /run/media/root/CentOS 7 x86_64
可以看到此时/var/lib/docker目录已经被挂载到了sdb1这个磁盘上。使用xfs_info命令验证d_type是否已经成功开启。
[root@bogon ~]# xfs_info /var/lib/docker | grep ftype
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
可以看到输出结果为 ftype=1,证明 d_type 已经被成功开启。
准备好 /var/lib/docker 目录后,我们就可以配置 Docker 的文件驱动为 overlay2。
5、停止已经运行的容器:
systemctl stop docker
6、备份/var/lib/docker目录:
cp -au /var/lib/docker/ /var/lib/docker.bak
7、修改daemon.json文件
vim /etc/docker/daemon.json
{
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.size=20G",
"overlay2.override_kernel_check=true"
]
}
:wq
其中:
storage-driver参数指定使用overlay2文件驱动。
overlay2参数表示限制每个容器根目录大小为20G。限制每个容器的磁盘空间大小是通过 xfs 的 pquota 特性实现,overlay2.size 可以根据不同的生产环境来设置这个值的大小。我推荐你在生产环境中开启此参数,防止某个容器写入文件过大,导致整个 Docker 目录空间溢出。
7、启动docker并查看配置是否生效
systemctl start docker
docker info
[root@bogon ~]# docker info
Client:
Context: default
Debug Mode: false
Plugins:
app: Docker App (Docker Inc., v0.9.1-beta3)
buildx: Docker Buildx (Docker Inc., v0.8.1-docker)
scan: Docker Scan (Docker Inc., v0.17.0)
Server:
Containers: 0
Running: 0
Paused: 0
Stopped: 0
Images: 0
Server Version: 20.10.14
Storage Driver: overlay2
Backing Filesystem: xfs
Supports d_type: true
Native Overlay Diff: true
userxattr: false
Logging Driver: json-file
Cgroup Driver: cgroupfs
。。。。。。。。。。。。。。。。
可以看到 Storage Driver 已经变为 overlay2,并且 d_type 也是 true。至此,Docker 已经配置完成。
overlay2的工作原理:
overlay2和AUFS类似,它将所有目录称之为层(layer),overlay2的目录是镜像和容器分层的基础,而把这些层统一展现到同一的目录下的过程称为联合挂载(union mount),overlay2目录的下一层叫作lowerdir,上一层叫作upperdir,联合挂载后的结果叫作merged。
总的来说overlay2是这样存储文件的:overlay2将镜像层和容器层都放在单独的目录,并且有唯一的ID,每一层仅存储发生变化的文件,最终使用联合挂载技术将容器层和镜像层的所有文件统一挂载到容器里,使得容器中看到完整的系统文件。
注意:overlay2文件系统最多支持128个层数叠加,也就是说Dockerfile最多写128行!
验证:
下面我们通过拉取一个Ubuntu操作系统的镜像来查看overlay2是如何存放镜像文件的。
首先拉取Ubuntu16.04镜像
[root@bogon ~]# docker pull ubuntu:16.04
16.04: Pulling from library/ubuntu
58690f9b18fc: Pull complete
b51569e7c507: Pull complete
da8ef40b9eca: Pull complete
fb15d46c38dc: Pull complete
Digest: sha256:20858ebbc96215d6c3c574f781133ebffdc7c18d98af4f294cc4c04871a6fe61
Status: Downloaded newer image for ubuntu:16.04
docker.io/library/ubuntu:16.04
可以看到镜像一共被分为四层拉取,拉取完镜像后我们查看一下overlay2的目录:
[root@bogon overlay2]# ls -l /var/lib/docker/overlay2/
总用量 0
drwx--x---. 4 root root 72 4月 10 20:27 255439e82dc0b274e136c222edbdfb127293aea60a035d68dc76843b6251d2a1
drwx--x---. 4 root root 55 4月 10 20:27 256f8203bd2e390b1a46452a1a1116a8c9f0fc92f97bd7bea10dcd57d163e9ad
drwx--x---. 4 root root 72 4月 10 20:27 753c4cb77209c663f81c6493bf7474cc2b6cca02e1f989e2300437e1171ea930
brw-------. 1 root root 8, 17 4月 10 20:01 backingFsBlockDev
drwx--x---. 3 root root 47 4月 10 20:27 fc774f426aaf204addfe2801f2b1c3e124053fe683177f524579b451bed00f87
drwx------. 2 root root 142 4月 10 20:27 l
可以看到overlay2目录下出现了四个镜像层目录和一个I目录,我们首先来查看一个I目录的内容:
[root@bogon overlay2]# ls -l /var/lib/docker/overlay2/l
总用量 0
lrwxrwxrwx. 1 root root 72 4月 10 20:27 3DCBAD25PCVDLLTRPOH4ANXEYD -> ../255439e82dc0b274e136c222edbdfb127293aea60a035d68dc76843b6251d2a1/diff
lrwxrwxrwx. 1 root root 72 4月 10 20:27 4QBAYS7RATXH7J327SSXLG6C42 -> ../256f8203bd2e390b1a46452a1a1116a8c9f0fc92f97bd7bea10dcd57d163e9ad/diff
lrwxrwxrwx. 1 root root 72 4月 10 20:27 F2LJYFUKS5KRY4XDQP4QRNCBVG -> ../fc774f426aaf204addfe2801f2b1c3e124053fe683177f524579b451bed00f87/diff
lrwxrwxrwx. 1 root root 72 4月 10 20:27 FACN4BRQ646CITRACGUMQ7B2XU -> ../753c4cb77209c663f81c6493bf7474cc2b6cca02e1f989e2300437e1171ea930/diff
可以看到I目录是一堆软连接,把一些较短的随机串软连到镜像层的diff文件夹下,这样做是为了避免达到mount命令参数的长度限制。
下面我们查看任意一个镜像层下的文件内容:
[root@bogon overlay2]# ls -l /var/lib/docker/overlay2/255439e82dc0b274e136c222edbdfb127293aea60a035d68dc76843b6251d2a1/
总用量 8
-rw-------. 1 root root 0 4月 10 20:27 committed
drwxr-xr-x. 3 root root 17 4月 10 20:27 diff
-rw-r--r--. 1 root root 26 4月 10 20:27 link
-rw-r--r--. 1 root root 57 4月 10 20:27 lower
drwx------. 2 root root 6 4月 10 20:27 work
镜像层的link文件内容为该镜像层的短ID,diff文件夹为该镜像层的改动内容,lower文件为该层的所有父层镜像的短ID。
我们可以通过docker image inspect命令来查看某个镜像的层次关系,例如我想查看刚刚下载的Ubuntu镜像之间的层级关系,可以使用以下命令:
[root@bogon overlay2]# docker image inspect ubuntu:16.04
................................
"GraphDriver": {
"Data": {
"LowerDir": "/var/lib/docker/overlay2/255439e82dc0b274e136c222edbdfb127293aea60a035d68dc76843b6251d2a1/diff:/var/lib/docker/overlay2/753c4cb77209c663f81c6493bf7474cc2b6cca02e1f989e2300437e1171ea930/diff:/var/lib/docker/overlay2/fc774f426aaf204addfe2801f2b1c3e124053fe683177f524579b451bed00f87/diff",
"MergedDir": "/var/lib/docker/overlay2/256f8203bd2e390b1a46452a1a1116a8c9f0fc92f97bd7bea10dcd57d163e9ad/merged",
"UpperDir": "/var/lib/docker/overlay2/256f8203bd2e390b1a46452a1a1116a8c9f0fc92f97bd7bea10dcd57d163e9ad/diff",
"WorkDir": "/var/lib/docker/overlay2/256f8203bd2e390b1a46452a1a1116a8c9f0fc92f97bd7bea10dcd57d163e9ad/work"
},
。..........................
其中 MergedDir 代表当前镜像层在 overlay2 存储下的目录,LowerDir 代表当前镜像的父层关系,使用冒号分隔,冒号最后代表该镜像的最底层.
下面我们将镜像层运行起来称为容器:
docker run -dit --name ubuntu001 ubuntu:16.04
我们使用docker inspect命令来查看一下容器的工作目录:
docker inspect ubuntu001
...........................
"GraphDriver": {
"Data": {
"LowerDir": "/var/lib/docker/overlay2/8f9bcd2acc4cbcfe23dcff4335b532680685a10d7bd7e749b2f59e598695cf3d-init/diff:/var/lib/docker/overlay2/256f8203bd2e390b1a46452a1a1116a8c9f0fc92f97bd7bea10dcd57d163e9ad/diff:/var/lib/docker/overlay2/255439e82dc0b274e136c222edbdfb127293aea60a035d68dc76843b6251d2a1/diff:/var/lib/docker/overlay2/753c4cb77209c663f81c6493bf7474cc2b6cca02e1f989e2300437e1171ea930/diff:/var/lib/docker/overlay2/fc774f426aaf204addfe2801f2b1c3e124053fe683177f524579b451bed00f87/diff",
"MergedDir": "/var/lib/docker/overlay2/8f9bcd2acc4cbcfe23dcff4335b532680685a10d7bd7e749b2f59e598695cf3d/merged",
"UpperDir": "/var/lib/docker/overlay2/8f9bcd2acc4cbcfe23dcff4335b532680685a10d7bd7e749b2f59e598695cf3d/diff",
"WorkDir": "/var/lib/docker/overlay2/8f9bcd2acc4cbcfe23dcff4335b532680685a10d7bd7e749b2f59e598695cf3d/work"
},
...............................................
MergedDir 的内容即为容器层的工作目录,LowerDir 为容器所依赖的镜像层目录。 然后我们查看下 overlay2 目录下的内容:
[root@localhost ~]# ls -l /var/lib/docker/overlay2/
总用量 0
drwx--x---. 4 root root 72 4月 10 20:27 255439e82dc0b274e136c222edbdfb127293aea60a035d68dc76843b6251d2a1
drwx--x---. 4 root root 72 4月 10 20:58 256f8203bd2e390b1a46452a1a1116a8c9f0fc92f97bd7bea10dcd57d163e9ad
drwx--x---. 4 root root 72 4月 10 20:27 753c4cb77209c663f81c6493bf7474cc2b6cca02e1f989e2300437e1171ea930
drwx--x---. 5 root root 69 4月 10 21:55 8f9bcd2acc4cbcfe23dcff4335b532680685a10d7bd7e749b2f59e598695cf3d
drwx--x---. 4 root root 72 4月 10 21:55 8f9bcd2acc4cbcfe23dcff4335b532680685a10d7bd7e749b2f59e598695cf3d-init
brw-------. 1 root root 8, 17 4月 10 21:54 backingFsBlockDev
drwx--x---. 3 root root 47 4月 10 20:27 fc774f426aaf204addfe2801f2b1c3e124053fe683177f524579b451bed00f87
drwx------. 2 root root 210 4月 10 21:55 l
可以看到 overlay2 目录下增加了容器层相关的目录,我们再来查看一下容器层下的内容:
ls -l /var/lib/docker/overlay2/8f9bcd2acc4cbcfe23dcff4335b532680685a10d7bd7e749b2f59e598695cf3d
总用量 8
drwxr-xr-x. 2 root root 6 4月 10 21:55 diff
-rw-r--r--. 1 root root 26 4月 10 21:55 link
-rw-r--r--. 1 root root 144 4月 10 21:55 lower
drwxr-xr-x. 1 root root 6 4月 10 21:55 merged
drwx------. 3 root root 18 4月 10 21:55 work
link和lower文件与镜像层的功能一致,link文件内容为该容器层的短ID,lower文件为该层的所有父镜像的短ID。diff目录为容器的读写层,容器内的修改文件都会在diff中出现,merged目录为分层文件联合挂载后的结果,也是容器内的工作目录。总的来说:overlay2 是这样储存文件的:overlay2将镜像层和容器层都放在单独的目录,并且有唯一 ID,每一层仅存储发生变化的文件,最终使用联合挂载技术将容器层和镜像层的所有文件统一挂载到容器中,使得容器中看到完整的系统文件。
那么overlay2如何读取、修改文件?
overlay2的工作过程中对文件的操作分别为读取文件和修改文件。
(1)读取文件:
容器内进程读取文件分为以下三种情况。
- 当文件在容器层中不存在:当容器中的进程需要读取某个文件时,如果容器层中不存在该文件,则从镜像层查找该文件,然后读取文件内容。
- 文件在容器层中存在:当文件存在于容器层并且不存在镜像层时,直接从容器层读取文件。
- 文件即存在于镜像层,又存在于容器层:当我们读取的文件既存在于镜像层,又存在于容器层时,将会从容器层读取该文件。(由于写时复制,所以此时肯定是再次修改过的文件才会复制到容器层,所以这里应该读取容器层的文件)。
(2)修改文件或目录:
overlay2对文件的修改采用的是写时复制的工作机制,这种工作机制可以最大程度的节省空间。具体的文件操作机制如下:
-
第一次修改文件:当我们第一次在容器中修改某个文件时,overlay2会触发写时复制操作,overlay2首先从镜像层复制文件到容器层,然后再容器层执行对应的文件修改操作。
overlay2 写时复制的操作将会复制整个文件,如果文件过大,将会大大降低文件系统的性能,因此当我们有大量文件需要被修改时,overlay2 可能会出现明显的延迟。好在,写时复制操作只在第一次修改文件时触发,对日常使用没有太大影响。 -
删除文件或目录****:当文件或目录被删除时,overlay2并不会真正从镜像中删除它,因为镜像层是只读的,overlay2会创建一个特殊的文件或目录,这种特殊的文件或目录会阻止容器的访问。
结语:
overlay2目前已经是docker官方推荐的文件系统,也是目前安装Docker时默认的文件系统,因为overlay2在生产环境中不仅有着较高的性能,它的稳定性也极其突出。但是overlay2的使用还是有一定条件的。所以,在生产环境中如果你的环境满足overlay2的条件,请尽量使用overlay2作为docker的联合文件系统。
7、namespace实现资源隔离
Docker是使用linux的Namespace技术实现资源隔离的。
Namespace是linux内核的一个特性,该特性可以实现在同一主机系统中,对进程ID、主机名、用户ID、文件名、网络和进程间通信等资源的隔离。Docker利用Linux内核的Namespace特性,实现了每个容器的资源相互隔离,从而保证容器内部只能访问到自己Namespace的资源。
linux5.6内核提供了8种类型的Namespace:
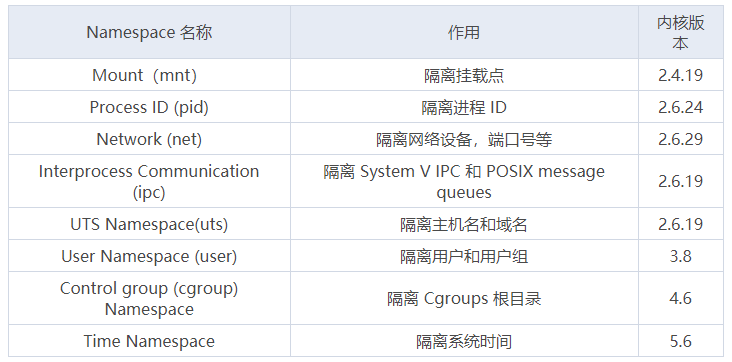
虽然 Linux 内核提供了8种 Namespace,但是最新版本的 Docker 只使用了其中的前6 种,分别为Mount Namespace、PID Namespace、Net Namespace、IPC Namespace、UTS Namespace、User Namespace。
用户可以在/proc/[pid]/ns目录下看到指向不同namespace的文件,效果如下图:
形如[4026531839]这就是namespace号。
[root@localhost ~]# ls -l /proc/$$/ns
总用量 0
lrwxrwxrwx. 1 root root 0 4月 12 20:07 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 root root 0 4月 12 20:07 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 root root 0 4月 12 20:07 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 4月 12 20:07 pid -> pid:[4026531836]
lrwxrwxrwx. 1 root root 0 4月 12 20:07 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 4月 12 20:07 uts -> uts:[4026531838]
其中$$是shell中表示当前运行的进程ID号
如果两个进程指向的namespace编号相同,就说明它们在同一个namespace下,否则便在不同namespace里面。
各种Namespace的作用?
(1)Mount Namespace
Mount Namespace是linux内核实现的第一个Namespace,从内核的2.4.19版本开始加入。它可以用来隔离不同的进程或进程组看到的挂载点。通俗的说,就是可以实现在不同的进程中看到不同的挂载目录。使用Mount Namespace可以实现容器内只能看到自己挂载信息,在容器内的挂载操作不会影响主机的挂载目录。
下面我们通过一个实例来演示下Mount Namespace。使用的工具是unshare。这是util-linux工具包中的一个工具,centos7系统默认已经集成了该工具。使用unshare命令可以实现创建并访问不同类型的Namespace。
首先我们使用以下命令创建一个bash进程并且新建一个Mount Namespace:
[root@localhost ~]# unshare --mount --fork /bin/bash
执行完上述命令后,这时候我们在主机上创建了一个新的Mount Namespace,并且当前命令窗口加入了新创建的Mount Namespace。下面我通过一个例子来验证下,在独立的 Mount Namespace 内创建挂载目录是不影响主机的挂载目录的。
首先在/tmp目录下创建一个目录。
mkdir /tmp/tmpfs
创建好目录后使用mount命令挂载一个tmpfs类型的目录,命令如下:
mount -t tmpfs -o size=20m tmpfs /tmp/tmpfs
然后使用df命令查看一下已经挂载的目录信息:
[root@localhost ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root 17G 5.2G 12G 31% /
devtmpfs 1.3G 0 1.3G 0% /dev
tmpfs 1.3G 0 1.3G 0% /dev/shm
tmpfs 1.3G 0 1.3G 0% /sys/fs/cgroup
tmpfs 1.3G 9.2M 1.3G 1% /run
tmpfs 266M 4.0K 266M 1% /run/user/42
tmpfs 266M 28K 266M 1% /run/user/0
/dev/sr0 4.3G 4.3G 0 100% /run/media/root/CentOS 7 x86_64
/dev/sdb1 20G 327M 20G 2% /var/lib/docker
overlay 20G 327M 20G 2% /var/lib/docker/overlay2/b404b19d110e3dfb51b4fca297dad3a030c27219f68a6f063ab5484e23999a9f/merged
/dev/sda1 1014M 179M 836M 18% /boot
tmpfs 20M 0 20M 0% /tmp/tmpfs
可以看到/tmp/tmpfs目录已经被正确挂载。为了验证主机上并没有挂载此目录,我们新打开一个命令窗口,同样执行df命令查看主机的挂载信息。
[root@localhost ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root 17G 5.2G 12G 31% /
devtmpfs 1.3G 0 1.3G 0% /dev
tmpfs 1.3G 0 1.3G 0% /dev/shm
tmpfs 1.3G 9.2M 1.3G 1% /run
tmpfs 1.3G 0 1.3G 0% /sys/fs/cgroup
/dev/sdb1 20G 327M 20G 2% /var/lib/docker
/dev/sda1 1014M 179M 836M 18% /boot
tmpfs 266M 4.0K 266M 1% /run/user/42
tmpfs 266M 24K 266M 1% /run/user/0
/dev/sr0 4.3G 4.3G 0 100% /run/media/root/CentOS 7 x86_64
overlay 20G 327M 20G 2% /var/lib/docker/overlay2/b404b19d110e3dfb51b4fca297dad3a030c27219f68a6f063ab5484e23999a9f/merged
可以看到主机上并没有挂载/tmp/tmpfs,可见我们独立的Mount Namespace中执行mount操作不会影响主机。
为了进一步验证我们的想法,我们继续在执行过unahsre命令的窗口查看一下当前进程的 Namespace 信息,命令如下:
[root@localhost ~]# ls -l /proc/$$/ns/
总用量 0
lrwxrwxrwx. 1 root root 0 4月 12 20:51 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 root root 0 4月 12 20:51 mnt -> mnt:[4026532726]
lrwxrwxrwx. 1 root root 0 4月 12 20:51 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 4月 12 20:51 pid -> pid:[4026531836]
lrwxrwxrwx. 1 root root 0 4月 12 20:51 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 4月 12 20:51 uts -> uts:[4026531838]
然后新打开一个命令行窗口,使用相同的命令查看一下主机上的 Namespace 信息:
[root@localhost ~]# ls -l /proc/$$/ns/
总用量 0
lrwxrwxrwx. 1 root root 0 4月 12 20:52 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 root root 0 4月 12 20:52 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 root root 0 4月 12 20:52 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 4月 12 20:52 pid -> pid:[4026531836]
lrwxrwxrwx. 1 root root 0 4月 12 20:52 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 4月 12 20:52 uts -> uts:[4026531838]
通过对比两次命令的输出结果,我们可以看到,除了Mount Namespace的ID值不一样外,其他Namespace的ID值均一致。
使用unshare的mount namespace:
lrwxrwxrwx. 1 root root 0 4月 12 20:51 mnt -> mnt:[4026532726]
新创建的命令终端:
lrwxrwxrwx. 1 root root 0 4月 12 20:52 mnt -> mnt:[4026531840]
通过以上结果我们可以得出结论,使用unshare命令可以新建Mount Namespace,并且在新建的Mount Namespace内mount是和外部完全隔离的。
(2)PID Namespace
PID Namespace的作用是是用来隔离进程。在不同的PID Namespace中,进程可以拥有相同的PID号,利用PID Namespace可以实现每个容器的主进程为1号进程。而容器内的进程在主机上却拥有不同的PID。例如一个进程在主机上PID为122,使用PID Namespace可以实现该进程在容器内查看到的PID为1。
下面我们通告一个实例来演示下PID Namespace的作用,首先我们使用以下命令创建一个bash进程,并且新建一个PID Namespace:
unshare --pid --fork --mount-proc /bin/bash
执行完上述命令后,我们在主机上创建一个新的PID Namespace,并且当前命令窗口加入了新创建的PID Namespace。在当前的命令窗口使用ps aux命令查看下进程信息:
[root@localhost ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 116688 3288 pts/1 S 17:08 0:00 /bin/bash
root 31 0.0 0.0 151064 1792 pts/1 R+ 19:02 0:00 ps aux
通告上述命令输出结果可以看到当前Namespace下bash为1号的进程,而且我们也看不到主机上的其他进程信息。
(3)****UTS Namespace
UTS Namespace主要是用来隔离主机名的,它允许每个UTS Namespace拥有一个独立的主机名。例如我们的主机名称为docker,使用UTS Namespace可以实现在容器内的主机名称为lagoudocker或者其他任意自定义的主机名。
同样我们通过一个实例来验证UTS Namespace的作用,首先我们使用unshare命令创建一个UTS Namespace:
unshare --uts --fork /bin/bash
创建好UTS Namespace后,当前命令窗口已经处于一个独立的UTS Namespace中,下面我们使用hostname命令(hostname也可以用来查看主机名称)设置一下主机名:
hostname -b mydocker
然后我们查看下主机名:
[root@localhost ~]# hostname
mydocker
通过上面命令的输出,我们可以看到当前UTS Namespace内的主机名已经被修改为mydocker。然后我们新打开一个命令终端,使用hostname命令查看:
[root@localhost ~]# hostname
localhost
可以看到并没有被修改,由此可以验证UTS Namespace可以用来隔离主机名。
(4)IPC Namespace
IPC Namespace主要是用来隔离进程间的通信的。例如PID Namespace和IPC Namespace一起使用可以实现同一IPC Namespace内的进程可以彼此通信。,不同IPC Namespace的进程却不能通信。
同样我们通过一个实例来验证下IPC Namespace的作用。首先我们使用unshare命令创建一个IPC Namespace:
unshare --ipc --fork /bin/bash
下面我们要借助两个命令来实现对IPC Namespace的验证。
- ipcs -q命令:用来查看系统间通信队列列表。
- ipcmk -Q命令:用来创建系统间通信队列。
我们首先使用ipcs -q命令查看一下当前IPC Namespace下的系统通信列表:
[root@localhost ~]# ipcs -q
--------- 消息队列 -----------
键 msqid 拥有者 权限 已用字节数 消息
[root@localhost ~]#
可以看到当前无任何系统通信队列。然后我们使用ipcmk -Q命令创建一个系统通信队列:
[root@localhost ~]# ipcmk -Q
消息队列 id:0
[root@localhost ~]#
再次使用ipcs -q查看当前IPC Namespace下的系统通信队列列表:
[root@localhost ~]# ipcs -q
--------- 消息队列 -----------
键 msqid 拥有者 权限 已用字节数 消息
0xf761d851 0 root 644 0 0
可以看到我们成功的创建了一个系统通信队列,然后我们新打开一个命令行窗口,使用ipcs -q命令查看一下主机的系统通信队列:
[root@localhost ~]# ipcs -q
--------- 消息队列 -----------
键 msqid 拥有者 权限 已用字节数 消息
通过上面的实验,可以发现在单独的IPC Namespace内创建的系统通信队列在主机上无法看到。即IPC Namespace实现了系统通信队列的隔离。
(5)User Namespace
UserNamespace是用来隔离用户和用户组的,一个比较典型的应用场景就是在主机上以非root用户运行的进程可以在一个单独的User Namespace中映射成root用户。使用UserNamespace
可以实现进程在容器里拥有root权限,而在主机上却只是root用户。
UserNamespace的创建是可以不使用root权限的。下面我们以普通用户的身份创建一个User Namespace,命令如下:
useradd data
su data
[data@localhost ~]$ unshare --user -r /bin/bash
Centos7默认允许创建的UserNamespace为0.如果执行上述命令失败(unshare 命令返回的错误为 unshare: unshare failed: Invalid argument )或者如下:
[data@localhost ~]$ unshare --user -r /bin/bash
unshare: unshare 失败: 无效的参数
需要使用以下命令修改系统允许创建的UserNamespace数量,命令为:
su root
echo 65535 > /proc/sys/user/max_user_namespaces
su data
然后再次创建。
[data@localhost ~]$ unshare --user -r /bin/bash
执行id命令查看当前用户的信息:
[root@localhost root]# id
uid=0(root) gid=0(root) 组=0(root),65534(nfsnobody) 环境=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
通过上面的输出命令我们可以看到在新的User Namespace内已经是root用户了。下面我们使用只有root用户才可以执行的reboot命令来验证下,在当前命令窗口执行:
[root@localhost root]# reboot
Failed to open /dev/initctl: 权限不够
Failed to talk to init daemon.
(6)Net Namespace
Net Namespace是用来隔离网络设备、IP地址和端口等信息的。Net Namespace可以让每个进程拥有自己独立的IP地址、端口和网卡的信息。例如主机IP地址为192.168.72.130,容器内可以设置独立的IP地址为192.168.1.1。
我们使用ip addr查看当前网卡信息:
[root@localhost ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:59:2d:20 brd ff:ff:ff:ff:ff:ff
inet 192.168.72.130/24 brd 192.168.72.255 scope global dynamic ens33
valid_lft 956sec preferred_lft 956sec
inet6 fe80::3ec9:8ac8:a043:639a/64 scope link
valid_lft forever preferred_lft forever
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN qlen 1000
link/ether 52:54:00:ea:6a:1f brd ff:ff:ff:ff:ff:ff
inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0
valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN qlen 1000
link/ether 52:54:00:ea:6a:1f brd ff:ff:ff:ff:ff:ff
同样使用普通用户!然后我们使用以下命令创建一个Net Namespace:
su data
[data@localhost root]$ sudo unshare --net --fork /bin/bash
我们信任您已经从系统管理员那里了解了日常注意事项。
总结起来无外乎这三点:
#1) 尊重别人的隐私。
#2) 输入前要先考虑(后果和风险)。
#3) 权力越大,责任越大。
[sudo] data 的密码:
[root@localhost ~]#
同样我们使用ip addr查看:
[root@localhost ~]# ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
可以看到。宿主机上有lo、eth0、docker0等网络设备,而我们新建的NetNamespace内则于主机上的网络设备不同。
为什么Docker需要Namespace
Linux内核从2002年2.4.19版本开始加入了Mount Namespace,而直到内核3.8版本加入了User Namespace才为容器提供了足够的支持功能。
当Docker新建一个容器时,它会创建这六种Namespace,然后将容器中的进程加入到这些Namespace之中,使得Docker容器中的进程只能看到当前Namespace中的系统资源。
正时由于Docker使用了linux的这些Namespace技术,才实现了Docker容器的隔离。
最后,试想下,当我们使用 docker run --network=host 命令启动容器时,容器是否和主机共享同一个 NetNamespace?
答:这种方式启动容器,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。
可以启动一个 network=host 的容器使用 ls -l /proc/$$/ns/ 命令验证下,可以发现 Net Namespace的编号和主机上是一样的。所以,Docker不建议使用这种方式。
[zz@localhost myworkspace]$$ docker run -it --name mybusybox1 --network=host busybox sh
/ # ls -l /proc/$$/ns
total 0
lrwxrwxrwx 1 root root 0 Dec 19 12:42 ipc -> ipc:[4026532742]
lrwxrwxrwx 1 root root 0 Dec 19 12:42 mnt -> mnt:[4026532740]
lrwxrwxrwx 1 root root 0 Dec 19 12:42 net -> net:[4026531956]
lrwxrwxrwx 1 root root 0 Dec 19 12:42 pid -> pid:[4026532743]
lrwxrwxrwx 1 root root 0 Dec 19 12:42 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Dec 19 12:42 uts -> uts:[4026532741]
然后新打开一个命令行窗口,使用相同的命令查看一下主机上的 Namespace 信息:
[zz@localhost myworkspace]$ ls -l /proc/$$/ns/
total 0
lrwxrwxrwx. 1 zz zz 0 Dec 19 20:34 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 zz zz 0 Dec 19 20:34 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 zz zz 0 Dec 19 20:34 net -> net:[4026531956]
lrwxrwxrwx. 1 zz zz 0 Dec 19 20:34 pid -> pid:[4026531836]
lrwxrwxrwx. 1 zz zz 0 Dec 19 20:34 user -> user:[4026531837]
lrwxrwxrwx. 1 zz zz 0 Dec 19 20:34 uts -> uts:[4026531838]
发现 Net Namespace的编号和主机上是一样的,都是[4026531956]。
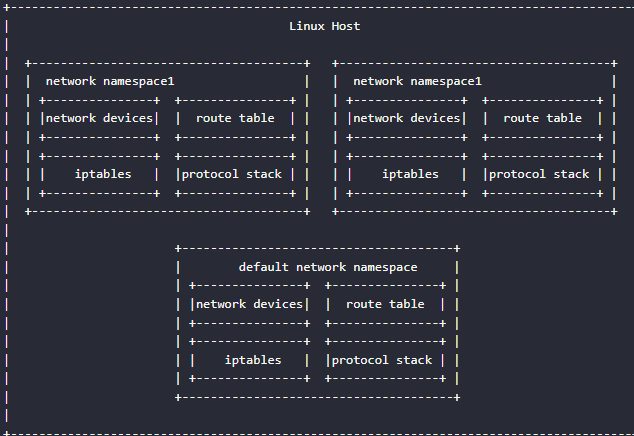
veth设备是虚拟以太网设备.它们可以充当网络命名空间之间的隧道,以创建到另一个命名空间中的物理网络设备的桥接,但也可以用作独立的网络设备。
veth设备总是以互连的对创建。可以使用以下命令创建一对:
ip link add <p1-name> type veth peer name <p2-name>
在上面,p1-name 和 p2-name 是分配给两个相连端点的名称。在对中的一个设备上传输的数据包立即在另一设备上接收。如下图所示。当任何一个设备关闭时,这对设备的链接状态就会关闭。下面的线可以理解为veth pair。

由于network namespace隔离了网络相关的全局资源,所以从网络的角度来看,一个network namespace可以看作一个独立的虚拟主机,即使在同一个主机上创建的两个network namespace,相互之间缺省也是不能进行网络通信的。
veth提供了一种连接两个network namespace的方法。如果我们把上图中网线两端的网卡分别放入两个不同的network namespace,就可以把这两个network namespace连起来,形成一个点对点的二层网络,如下图所示:

下面我们通过试验来实现上图中的网络拓扑。
1、首先创建两个network namespace ns1和ns2。
[root@localhost ~]# ip netns add ns1
[root@localhost ~]# ip netns add ns2
2、创建一个veth pair线路
[root@localhost ~]# ip link add veth-ns1 type veth peer name veth-ns2
3、将veth pair一段的虚拟网卡放入到ns1,另一端放到ns2,这样就相当于采用网线将两个network namespace连接起来了
[root@localhost ~]# ip link set veth-ns1 netns ns1
[root@localhost ~]# ip link set veth-ns2 netns ns2
4、为两各网卡分配Ip地址,两个网卡都处于同一网段192.168.1.0/24,并开启
[root@localhost ~]# ip -n ns1 addr add 192.168.1.1/24 dev veth-ns1
[root@localhost ~]# ip -n ns2 addr add 192.168.1.2/24 dev veth-ns2
[root@localhost ~]# ip -n ns1 link set veth-ns1 up
[root@localhost ~]# ip -n ns2 link set veth-ns2 up
5、从ns1 ping ns2 的ip地址:
[root@localhost ~]# ip netns exec ns1 ping 192.168.1.2
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=0.081 ms
64 bytes from 192.168.1.2: icmp_seq=2 ttl=64 time=0.095 ms
64 bytes from 192.168.1.2: icmp_seq=3 ttl=64 time=0.035 ms
通过上面的实验我们可知veth实现了点对点的虚拟连接,可以通过veth连接两个namespace接入同一个二层网络。在物理网络中,如果需要连接多台主机,我们会使用网桥或者称之为交换机。linux也提供了网桥的虚拟实现。下面我们通过linux bridge来进行实验。
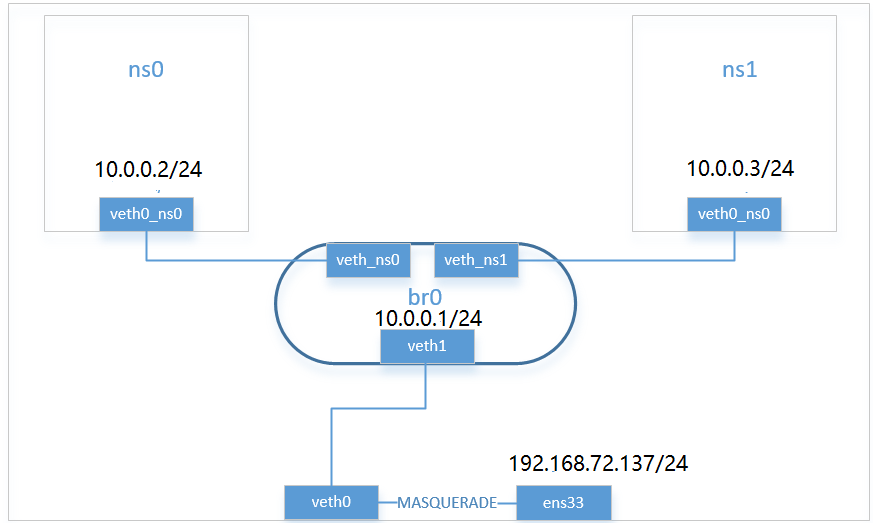
1.创建两个netns
[root@localhost ~]# ip netns add ns0
[root@localhost ~]# ip netns add ns1
2、为每个netns各添加一个网卡,类型为veth
[root@localhost ~]# ip link add veth0_ns0 type veth peer name veth_ns0
[root@localhost ~]# ip link add veth0_ns1 type veth peer name veth_ns1
[root@localhost ~]# ip link set veth0_ns0 netns ns0
[root@localhost ~]# ip link set veth0_ns1 netns ns1
3、查看netns下的网络
[root@localhost ~]# ip netns exec ns0 ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
7: veth0_ns0@if6: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 76:04:a8:90:f6:c9 brd ff:ff:ff:ff:ff:ff link-netnsid 0
[root@localhost ~]# ip netns exec ns1 ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
9: veth0_ns1@if8: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether ba:e6:61:21:18:8c brd ff:ff:ff:ff:ff:ff link-netnsid 0
可以看到ns0和ns1分别新增接口veth0_ns0,veth0_ns1。
[root@localhost ~]# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT qlen 1000
link/ether 00:0c:29:20:e2:a4 brd ff:ff:ff:ff:ff:ff
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT qlen 1000
link/ether 52:54:00:ea:6a:1f brd ff:ff:ff:ff:ff:ff
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast master virbr0 state DOWN mode DEFAULT qlen 1000
link/ether 52:54:00:ea:6a:1f brd ff:ff:ff:ff:ff:ff
5: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT
link/ether 02:42:76:1e:b6:a4 brd ff:ff:ff:ff:ff:ff
6: veth_ns0@if7: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 7e:18:0e:d2:47:34 brd ff:ff:ff:ff:ff:ff link-netnsid 0
8: veth_ns1@if9: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 7e:6b:f4:bd:0b:07 brd ff:ff:ff:ff:ff:ff link-netnsid 1
通过网卡序号可以看到veth0_ns0(7)和veth_ns0(6)为一对veth,veth0_ns1(9)和veth_ns1(8)为一对veth.
4、为ns0和ns1的接口配置IP并启动
ip netns exec ns0 ip addr add 10.0.0.2/24 dev veth0_ns0
ip netns exec ns0 ip link set dev veth0_ns0 up
ip netns exec ns1 ip addr add 10.0.0.3/24 dev veth0_ns1
ip netns exec ns1 ip link set dev veth0_ns1 up
5、查看ns0和ns1的网卡信息并进行测试
[root@localhost ~]# ip netns exec ns0 ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
7: veth0_ns0@if6: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN qlen 1000
link/ether 76:04:a8:90:f6:c9 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.0.1/24 scope global veth0_ns0
valid_lft forever preferred_lft forever
[root@localhost ~]# ip netns exec ns1 ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
9: veth0_ns1@if8: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN qlen 1000
link/ether ba:e6:61:21:18:8c brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.0.2/24 scope global veth0_ns1
valid_lft forever preferred_lft forever
进行ping测试:
[root@localhost ~]# ip netns exec ns0 ping 10.0.0.3
PING 10.0.0.3 (10.0.0.3) 56(84) bytes of data.
可以看到ping不通,这是因为两个ns相互独立,所以就ping不通。
6、创建linux bridge并添加ns0和ns1的veth pair:veth_ns0和veth_ns1
[root@localhost ~]# ip link add br0 type bridge
[root@localhost ~]# ip link set dev br0 up
[root@localhost ~]# ip link set dev veth_ns0 up
[root@localhost ~]# ip link set dev veth_ns1 up
[root@localhost ~]# ip link set dev veth_ns0 master br0
[root@localhost ~]# ip link set dev veth_ns1 master br0
查看br0的信息,可以看到ns0和ns1的pair veth都已经连接到br0.
[root@localhost ~]# ip add show br0
10: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP qlen 1000
link/ether 7e:18:0e:d2:47:34 brd ff:ff:ff:ff:ff:ff
inet6 fe80::c08b:55ff:fe06:1551/64 scope link
valid_lft forever preferred_lft forever
[root@localhost ~]# ip add show master br0
6: veth_ns0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UP qlen 1000
link/ether 7e:18:0e:d2:47:34 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::7c18:eff:fed2:4734/64 scope link
valid_lft forever preferred_lft forever
8: veth_ns1@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UP qlen 1000
link/ether 7e:6b:f4:bd:0b:07 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::7c6b:f4ff:febd:b07/64 scope link
valid_lft forever preferred_lft forever
7、进行ping测试
[root@localhost ~]# ip netns exec ns0 ping 10.0.0.3
PING 10.0.0.3 (10.0.0.3) 56(84) bytes of data.
64 bytes from 10.0.0.3: icmp_seq=1 ttl=64 time=0.079 ms
64 bytes from 10.0.0.3: icmp_seq=2 ttl=64 time=0.053 ms
8、配置到宿主机的通信:
1、首先创建veth pair,其中一个连接到br0
[root@localhost ~]# ip link add veth0 type veth peer name veth1
ip netns exec br0 ip addr add 10.0.0.1/24 dev veth0_ns1
[root@localhost ~]# ip link set dev veth0 up
[root@localhost ~]# ip link set dev veth1 up
[root@localhost ~]# ip link set dev veth1 master br0
ifconfig br0 10.0.0.1/24 up #给br0配置ip地址
2、host上添加到达10.0.0.0/24网络的路由,其中10.0.0.1为br0的地址
ip route add 10.0.0.0/24 via 10.0.0.1
3、ns0和ns1内部添加默认网关路由(注意必须是网关路由)
[root@localhost ~]# ip netns exec ns0 ip route add default via 10.0.0.1 dev veth0_ns0
[root@localhost ~]# ip netns exec ns1 ip route add default via 10.0.0.1 dev veth0_ns1
4、host主机添加对10.0.0.0/24网段的SNAT
iptables -t nat -A POSTROUTING -s 10.0.0.0/24 ! -o br0 -j MASQUERADE
5、这样就构造了一个模仿docker bridge的网络,ns0就可以ping通外部网关了
[root@localhost ~]# ip netns exec ns0 ping 192.168.72.2
PING 192.168.72.2 (192.168.72.2) 56(84) bytes of data.
64 bytes from 192.168.72.2: icmp_seq=1 ttl=127 time=0.471 ms
64 bytes from 192.168.72.2: icmp_seq=2 ttl=127 time=0.495 ms
6、测试ping外网:
[root@localhost ~]# ip netns exec ns1 ping 114.114.114.114
PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data.
64 bytes from 114.114.114.114: icmp_seq=1 ttl=127 time=28.1 ms
64 bytes from 114.114.114.114: icmp_seq=2 ttl=127 time=39.6 ms
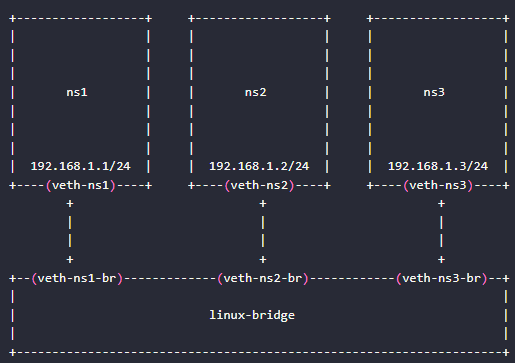
1、创建三个namespace
[root@localhost ~]# ip netns add ns1
[root@localhost ~]# ip netns add ns2
[root@localhost ~]# ip netns add ns3
2、创建一个linux bridge网桥
[root@localhost ~]# brctl addbr linux-bridge
liunx-bridge可以修改为其他的
3、创建veth pair ,然后将veth pair一端的虚拟网卡加入到namespace。在将另一端通过brctl addif加入到网桥上,这样就相当于用一条网线将三个namespace连接到了网桥上。
[root@localhost ~]# ip link add veth-ns1 type veth peer name veth-ns1-br
[root@localhost ~]# ip link set veth-ns1 netns ns1
[root@localhost ~]# brctl addif linux-bridge veth-ns1-br
[root@localhost ~]# ip link add veth-ns2 type veth peer name veth-ns2-br
[root@localhost ~]# ip link set veth-ns2 netns ns2
[root@localhost ~]# brctl addif linux-bridge veth-ns2-br
[root@localhost ~]# ip link add veth-ns3 type veth peer name veth-ns3-br
[root@localhost ~]# ip link set veth-ns3 netns ns3
[root@localhost ~]# brctl addif linux-bridge veth-ns3-br
4、为三个namespace中的虚拟网卡设置ip地址,这些ip地址处于同一网段192.168.1.0/24中
[root@localhost ~]# ip -n ns1 addr add local 192.168.1.1/24 dev veth-ns1
[root@localhost ~]# ip -n ns2 addr add local 192.168.1.2/24 dev veth-ns2
[root@localhost ~]# ip -n ns3 addr add local 192.168.1.3/24 dev veth-ns3
5、开启网桥和虚拟网卡状态为up
[root@localhost ~]# ip link set linux-bridge up
[root@localhost ~]# ip link set veth-ns1-br up
[root@localhost ~]# ip link set veth-ns2-br up
[root@localhost ~]# ip link set veth-ns3-br up
[root@localhost ~]# ip -n ns1 link set veth-ns1 up
[root@localhost ~]# ip -n ns2 link set veth-ns2 up
[root@localhost ~]# ip -n ns3 link set veth-ns3 up
6、测试三个namespace之间是否可以ping
[root@localhost ~]# ip netns exec ns1 ping 192.168.1.2
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=0.085 ms
^C
--- 192.168.1.2 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.085/0.085/0.085/0.000 ms
[root@localhost ~]# ip netns exec ns1 ping 192.168.1.3
PING 192.168.1.3 (192.168.1.3) 56(84) bytes of data.
64 bytes from 192.168.1.3: icmp_seq=1 ttl=64 time=0.082 ms
通过上面的实验,我们验证了可以使用linux bridge来将多个namespace连接到同一个二层网络中。在分配IP地址的时候,我们只为veth在namespace中那一端的虚拟网卡分配了地址,而没有为加入bridge那一端分配地址。这是因为bridge是工作在二层上的,只会处理以太包,包括ARP解析,以太数据包的转发和泛洪;并不会进行三层(IP)的处理,因此不需要三层的IP地址。
三层转发:
如果两个namespace处于不同的子网,那么就不能通过brige进行连接,而是需要通过路由器进行三层转发。然而Linux并未像提供虚拟网桥一样也提供一个虚拟路由器设备,原因是Linux自身就具备有路由器功能。
路由器的工作原理是这样的:路由器上有2到多个网络接口,每个网络接口处于不同的三层子网上。路由器会根据内部的路由转发表将从一个网络接口中收到的数据包转发到另一个网络接口,这样就实现了不同三层子网之间的互通。Linux内核提供了IP Forwarding功能,启用IP Forwarding后,就可以在不同的网络接口中转发IP数据包,相当于实现了路由器的功能。
下面我们试验将两个不同三层子网中的namespace通过Linux自身的路由功能连接起来,该试验的网络拓扑如下图所示。注意图中下方的路由器并未对应一个物理或者虚拟的路由器设备,而是采用了一个带两个虚拟网卡的namespace来实现,由于Linux内核启用了IP forwading功能,因此ns-router namespace可以在其两个处于不同子网的网卡之间进行IP数据包转发,实现了路由功能。
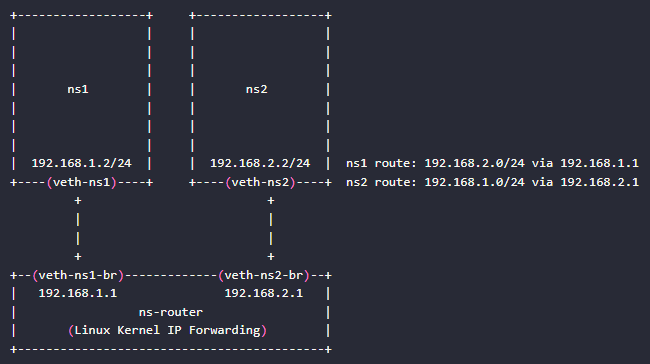
1、开启路由转发功能:
[root@localhost ~]# vim /etc/sysctl.d/99-sysctl.conf
net.ipv4.ip_forward=1
:wq
[root@localhost ~]# sysctl -p
net.ipv4.ip_forward = 1
[root@localhost ~]#
2、创建三个namespace
[root@localhost ~]# ip netns add ns1
[root@localhost ~]# ip netns add ns2
[root@localhost ~]# ip netns add ns-router
2、创建veth pair,并使用veth veir 将ns1和ns2连接到由ns-router实现的路由器上
[root@localhost ~]# ip link add veth-ns1 type veth peer name veth-ns1-router
[root@localhost ~]# ip link set veth-ns1 netns ns1
[root@localhost ~]# ip link set veth-ns1-router netns ns-router
[root@localhost ~]# ip link add veth-ns2 type veth peer name veth-ns2-router
[root@localhost ~]# ip link set veth-ns2 netns ns2
[root@localhost ~]# ip link set veth-ns2-router netns ns-router
3、为虚拟网卡设置ip地址,ns1和ns2分别为192.168.1.0/24和192.168.2.0/24两个子网上,而ns-router的两个网卡则分别连接到了这两个子网上。
[root@localhost ~]# ip -n ns1 addr add 192.168.1.2/24 dev veth-ns1
[root@localhost ~]# ip -n ns2 addr add 192.168.2.2/24 dev veth-ns2
[root@localhost ~]# ip -n ns-router addr add 192.168.1.1/24 dev veth-ns1-router
[root@localhost ~]# ip -n ns-router addr add 192.168.2.1/24 dev veth-ns2-router
4、将网卡状态设置为up
[root@localhost ~]# ip -n ns1 link set veth-ns1 up
[root@localhost ~]# ip -n ns2 link set veth-ns2 up
[root@localhost ~]# ip -n ns-router link set veth-ns1-router up
[root@localhost ~]# ip -n ns-router link set veth-ns2-router up
5、添加路由:
ip netns exec ns1 ip route add 192.168.2.0/24 via 192.168.1.1
ip netns exec ns2 ip route add 192.168.1.0/24 via 192.168.2.1
5、测试:
[root@localhost ~]# ip netns exec ns1 ping 192.168.2.2
PING 192.168.2.2 (192.168.2.2) 56(84) bytes of data.
64 bytes from 192.168.2.2: icmp_seq=1 ttl=63 time=0.094 ms
[root@localhost ~]# ip netns exec ns2 ping 192.168.1.2
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_seq=1 ttl=63 time=0.049 ms
连接到外部网络:
前面在介绍Linux bridge时我们讲到,从网络角度上来说,bridge是一个二层设备,因此并不需要设置IP。但Linux bridge虚拟设备比较特殊:我们可以认为bridge自带了一张网卡,这张网卡在主机上显示的名称就是bridge的名称。这张网卡在bridge上,因此可以和其它连接在bridge上的网卡和namespace进行二层通信;同时从主机角度来看,虚拟bridge设备也是主机default network namespace上的一张网卡,在为该网卡设置了IP后,可以参与主机的路由转发。
通过给bridge设置一个IP地址,并将该IP设置为namespace的缺省网关,可以让namespace和主机进行网络通信。如果在主机上再添加相应的路由,可以让namespace和外部网络进行通信。
下面显示了为Linux bridge设备br0设置了IP地址后的逻辑网络视图。注意下图中Linux bridge(br0)和路由器(default network namespace)上出现了br0这张网卡,即这张网卡同时在二层上工作于Linux bridge中,在三层上工作于default network namespace中。
当将br0设置为缺省网关后,可以从ns1和ns2连接到主机网络192.168.72.137/24上。此时数据流向是这样的:ns1–(网桥)–>br0–(IP Forwarding)–>192.168.72.137/24
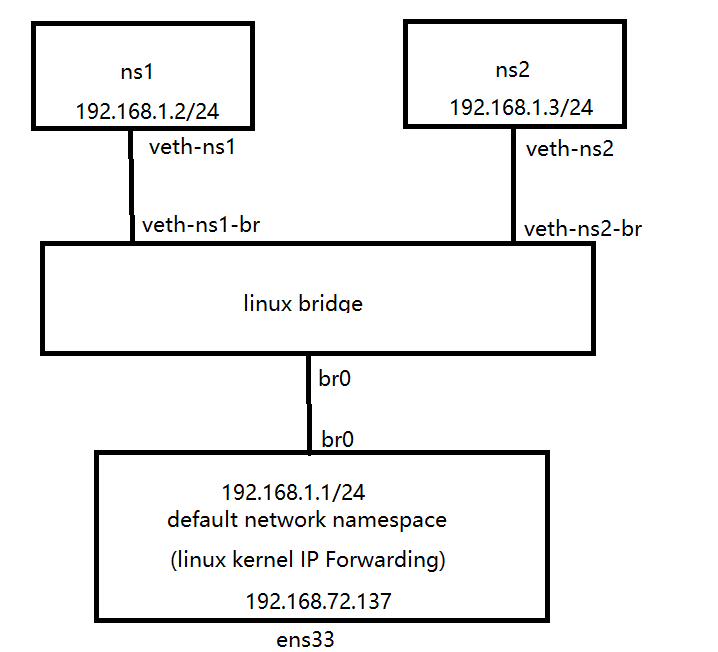
1.创建namespace和bridge
[root@localhost ~]# ip netns add ns1
[root@localhost ~]# ip netns add ns2
[root@localhost ~]# brctl addbr br0
2、通过veth pair将ns1和ns2连接到bridges上
[root@localhost ~]# ip link add veth-ns1 type veth peer name veth-ns1-br
[root@localhost ~]# ip link set veth-ns1 netns ns1
[root@localhost ~]# brctl addif br0 veth-ns1-br
[root@localhost ~]# ip link add veth-ns2 type veth peer name veth-ns2-br
[root@localhost ~]# ip link set veth-ns2 netns ns2
[root@localhost ~]# brctl addif br0 veth-ns2-br
3、为ns1,ns2和br0设置IP地址
[root@localhost ~]# ip -n ns1 addr add local 192.168.1.2/24 dev veth-ns1
[root@localhost ~]# ip -n ns2 addr add local 192.168.1.3/24 dev veth-ns2
[root@localhost ~]# ip add add local 192.168.1.1/24 dev br0
4、将bridge和虚拟网卡的状态设置为up
[root@localhost ~]# ip link set br0 up
[root@localhost ~]# ip link set veth-ns1-br up
[root@localhost ~]# ip link set veth-ns2-br up
[root@localhost ~]# ip -n ns1 link set veth-ns1 up
[root@localhost ~]# ip -n ns2 link set veth-ns2 up
此时ns1和ns2可以通信,但是和宿主机通不了信。原因是地址不在同一子网上且没有相应的路由。
5、在ns1和ns2中设置br0的IP为缺省网关
[root@localhost ~]# ip netns exec ns1 ip route add default via 192.168.1.1
[root@localhost ~]# ip netns exec ns2 ip route add default via 192.168.1.1
6、进行ping宿主机:
[root@localhost ~]# ip netns exec ns1 ping 192.168.72.137
PING 192.168.72.137 (192.168.72.137) 56(84) bytes of data.
64 bytes from 192.168.72.137: icmp_seq=1 ttl=64 time=0.796 ms
[root@localhost ~]# ip netns exec ns2 ping 192.168.72.137
PING 192.168.72.137 (192.168.72.137) 56(84) bytes of data.
64 bytes from 192.168.72.137: icmp_seq=1 ttl=64 time=0.075 ms
7、配置访问外网
[root@localhost ~]# iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -j MASQUERADE
[root@localhost ~]# ip netns exec ns1 ping 114.114.114.114
PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data.
64 bytes from 114.114.114.114: icmp_seq=1 ttl=127 time=40.5 ms
可以连接两个不同主机上处于不同子网中的namespace。让我们考虑下面的网络拓扑:
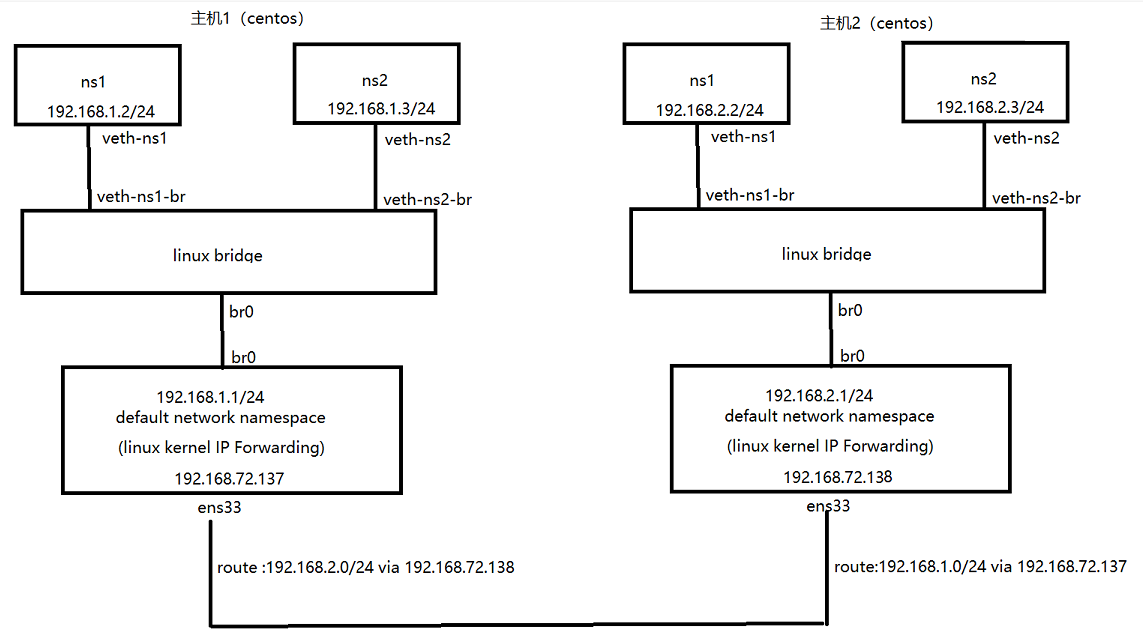
主机1配置:上面已经配置,我们进行配置主机2:
1.创建namespace和bridge
[root@localhost ~]# ip netns add ns1
[root@localhost ~]# ip netns add ns2
[root@localhost ~]# brctl addbr br0
2、通过veth pair将ns1和ns2连接到bridges上
[root@localhost ~]# ip link add veth-ns1 type veth peer name veth-ns1-br
[root@localhost ~]# ip link set veth-ns1 netns ns1
[root@localhost ~]# brctl addif br0 veth-ns1-br
[root@localhost ~]# ip link add veth-ns2 type veth peer name veth-ns2-br
[root@localhost ~]# ip link set veth-ns2 netns ns2
[root@localhost ~]# brctl addif br0 veth-ns2-br
3、为ns1,ns2和br0设置IP地址
[root@localhost ~]# ip -n ns1 addr add local 192.168.2.2/24 dev veth-ns1
[root@localhost ~]# ip -n ns2 addr add local 192.168.2.3/24 dev veth-ns2
[root@localhost ~]# ip add add local 192.168.2.1/24 dev br0
4、将bridge和虚拟网卡的状态设置为up
[root@localhost ~]# ip link set br0 up
[root@localhost ~]# ip link set veth-ns1-br up
[root@localhost ~]# ip link set veth-ns2-br up
[root@localhost ~]# ip -n ns1 link set veth-ns1 up
[root@localhost ~]# ip -n ns2 link set veth-ns2 up
此时ns1和ns2可以通信,但是和宿主机通不了信。原因是地址不在同一子网上且没有相应的路由。
5、在ns1和ns2中设置br0的IP为缺省网关
[root@localhost ~]# ip netns exec ns1 ip route add default via 192.168.2.1
[root@localhost ~]# ip netns exec ns2 ip route add default via 192.168.2.1
6、进行ping宿主机:
[root@localhost ~]# ip netns exec ns1 ping 192.168.72.138
PING 192.168.72.137 (192.168.72.137) 56(84) bytes of data.
64 bytes from 192.168.72.137: icmp_seq=1 ttl=64 time=0.796 ms
[root@localhost ~]# ip netns exec ns2 ping 192.168.72.138
PING 192.168.72.137 (192.168.72.137) 56(84) bytes of data.
64 bytes from 192.168.72.137: icmp_seq=1 ttl=64 time=0.075 ms
7、配置访问外网
[root@localhost ~]# iptables -t nat -A POSTROUTING -s 192.168.2.0/24 -j MASQUERADE
[root@localhost ~]# ip netns exec ns1 ping 114.114.114.114
PING 114.114.114.114 (114.114.114.114) 56(84) bytes of data.
64 bytes from 114.114.114.114: icmp_seq=1 ttl=127 time=40.5 ms
开始配置两个主机的路由:
主机1:
[root@localhost ~]# ip route add 192.168.2.0/24 via 192.168.72.138
主机2:
[root@localhost ~]# ip route add 192.168.1.0/24 via 192.168.72.137
通过在左边主机上添加到右边容器网络192.168.2.0/24的路由,可以让左边的容器网络192.168.1.0/24中的容器发出的IP数据包到达右边的192.168.2.0/24网络。同理,通过在右边主机上添加相应的路由,可以让右边的容器发出的IP数据包到达左边的192.168.1.0/24网络。
测试:
主机1:
[root@localhost ~]# ip netns exec ns1 ping 192.168.2.3
PING 192.168.2.3 (192.168.2.3) 56(84) bytes of data.
64 bytes from 192.168.2.3: icmp_seq=1 ttl=62 time=1.43 ms
主机2:
[root@localhost ~]# ip netns exec ns1 ping 192.168.1.2
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_seq=1 ttl=62 time=0.858 ms
从左边的ns1 (192.168.1.2)ping 右边的 ns1(192.168.2.2),数据流向是这样的:
- ns1向外发送一个ICMP数据包,源地址为192.168.1.2,目的地址为192.168.2.2。
- 因为目的地址192.168.2.2和源地址192.168.1.2不在同一子网上,因此数据包被发送到缺省网关192.168.1.1,也就是Linux bridge内部的自带网卡br0。
- br0同时也是主机default network namespace中的一张网卡,因此br0收到该数据包后,主机根据路由条目192.168.2.0/24 via 192.168.72.138判断应该将该数据包发送到192.168.72.138,也就是右边主机的网卡地址上。
- 右边主机在收到该数据包后,根据本地的直连路由将数据包发送到br0 192.168.2.1上。
- br0将数据包发送到目的地址192.168.2.2上。
8.Docker容器监控原理:
我们知道了Docker是基于Namespace、Cgroups和联合文件系统实现的,其中Cgroups不仅可以用于容器资源的限制,还乐意提供容器的资源使用率。无论何种监控方案的实现,底层数据都来源于Cgroups。
Cgroups的工作目录为/sys/fs/cgroup,/sys/fs/cgroup目录下包含了Cgroups的所有内容。Cgroups包含很多子系统,可以用来对不同的资源进行限制。例如对CPU、内存、PID、磁盘IO等资源进行限制和监控。
为了更详细的了解Cgroups的子系统,我们通过ls -l 命令查看/sys/fs/cgroup文件夹,可以看到很多目录:
[root@localhost ~]# ll /sys/fs/cgroup/
总用量 0
drwxr-xr-x. 5 root root 0 4月 17 15:10 blkio
lrwxrwxrwx. 1 root root 11 4月 17 15:10 cpu -> cpu,cpuacct
lrwxrwxrwx. 1 root root 11 4月 17 15:10 cpuacct -> cpu,cpuacct
drwxr-xr-x. 6 root root 0 4月 17 15:10 cpu,cpuacct
drwxr-xr-x. 3 root root 0 4月 17 15:10 cpuset
drwxr-xr-x. 5 root root 0 4月 17 15:10 devices
drwxr-xr-x. 3 root root 0 4月 17 15:10 freezer
drwxr-xr-x. 3 root root 0 4月 17 15:10 hugetlb
drwxr-xr-x. 5 root root 0 4月 17 21:05 memory
lrwxrwxrwx. 1 root root 16 4月 17 15:10 net_cls -> net_cls,net_prio
drwxr-xr-x. 3 root root 0 4月 17 15:10 net_cls,net_prio
lrwxrwxrwx. 1 root root 16 4月 17 15:10 net_prio -> net_cls,net_prio
drwxr-xr-x. 3 root root 0 4月 17 15:10 perf_event
drwxr-xr-x. 3 root root 0 4月 17 15:10 pids
drwxr-xr-x. 5 root root 0 4月 17 15:10 systemd
这些目录代表了 Cgroups 的子系统,Docker 会在每一个 Cgroups 子系统下创建 docker 文件夹。这里如果你对 Cgroups 子系统不了解的话,不要着急,后续我会在第 10 课时对 Cgroups 子系统做详细讲解,这里你只需要明白容器监控数据来源于 Cgroups 即可。
监控系统是如何获取容器的内存限制的?
下面我们以 memory 子系统(memory 子系统是Cgroups 众多子系统的一个,主要用来限制内存使用,讲解一下监控组件是如何获取到容器的资源限制和使用状态的(即容器的内存限制)。
我们首先在主机上使用以下命令启动一个资源限制为 1 核 2G 的 nginx 容器:
$ docker run --name=nginx --cpus=1 -m=2g --name=nginx -d nginx
## 这里输出的是容器 ID
51041a74070e9260e82876974762b8c61c5ed0a51832d74fba6711175f89ede1
注意:如果你已经创建过名称为 nginx 的容器,请先使用 docker rm -f nginx 命令删除已经存在的 nginx 容器。
容器启动后,我们通过命令行的输出可以得到容器的 ID,同时 Docker 会在/sys/fs/cgroup/memory/docker目录下以容器 ID 为名称创建对应的文件夹。
下面我们查看一下/sys/fs/cgroup/memory/``docker目录下的文件:
$ sudo ls -l /sys/fs/cgroup/memory/docker
total 0
drwxr-xr-x 2 root root 0 Sep 2 15:12 51041a74070e9260e82876974762b8c61c5ed0a51832d74fba6711175f89ede1
-rw-r--r-- 1 root root 0 Sep 2 14:57 cgroup.clone_children
--w--w--w- 1 root root 0 Sep 2 14:57 cgroup.event_control
-rw-r--r-- 1 root root 0 Sep 2 14:57 cgroup.procs
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.failcnt
--w------- 1 root root 0 Sep 2 14:57 memory.force_empty
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.kmem.failcnt
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.kmem.limit_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.kmem.max_usage_in_bytes
-r--r--r-- 1 root root 0 Sep 2 14:57 memory.kmem.slabinfo
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.kmem.tcp.failcnt
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.kmem.tcp.limit_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.kmem.tcp.max_usage_in_bytes
-r--r--r-- 1 root root 0 Sep 2 14:57 memory.kmem.tcp.usage_in_bytes
-r--r--r-- 1 root root 0 Sep 2 14:57 memory.kmem.usage_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.limit_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.max_usage_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.memsw.failcnt
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.memsw.limit_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.memsw.max_usage_in_bytes
-r--r--r-- 1 root root 0 Sep 2 14:57 memory.memsw.usage_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.move_charge_at_immigrate
-r--r--r-- 1 root root 0 Sep 2 14:57 memory.numa_stat
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.oom_control
---------- 1 root root 0 Sep 2 14:57 memory.pressure_level
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.soft_limit_in_bytes
-r--r--r-- 1 root root 0 Sep 2 14:57 memory.stat
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.swappiness
-r--r--r-- 1 root root 0 Sep 2 14:57 memory.usage_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 14:57 memory.use_hierarchy
-rw-r--r-- 1 root root 0 Sep 2 14:57 notify_on_release
-rw-r--r-- 1 root root 0 Sep 2 14:57 tasks
可以看到 Docker 已经创建了以容器 ID 为名称的目录,我们再使用 ls 命令查看一下该目录的内容:
$ sudo ls -l /sys/fs/cgroup/memory/docker/51041a74070e9260e82876974762b8c61c5ed0a51832d74fba6711175f89ede1
total 0
-rw-r--r-- 1 root root 0 Sep 2 15:21 cgroup.clone_children
--w--w--w- 1 root root 0 Sep 2 15:13 cgroup.event_control
-rw-r--r-- 1 root root 0 Sep 2 15:12 cgroup.procs
-rw-r--r-- 1 root root 0 Sep 2 15:12 memory.failcnt
--w------- 1 root root 0 Sep 2 15:21 memory.force_empty
-rw-r--r-- 1 root root 0 Sep 2 15:21 memory.kmem.failcnt
-rw-r--r-- 1 root root 0 Sep 2 15:12 memory.kmem.limit_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 15:21 memory.kmem.max_usage_in_bytes
-r--r--r-- 1 root root 0 Sep 2 15:21 memory.kmem.slabinfo
-rw-r--r-- 1 root root 0 Sep 2 15:21 memory.kmem.tcp.failcnt
-rw-r--r-- 1 root root 0 Sep 2 15:21 memory.kmem.tcp.limit_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 15:21 memory.kmem.tcp.max_usage_in_bytes
-r--r--r-- 1 root root 0 Sep 2 15:21 memory.kmem.tcp.usage_in_bytes
-r--r--r-- 1 root root 0 Sep 2 15:21 memory.kmem.usage_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 15:12 memory.limit_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 15:12 memory.max_usage_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 15:21 memory.memsw.failcnt
-rw-r--r-- 1 root root 0 Sep 2 15:12 memory.memsw.limit_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 15:21 memory.memsw.max_usage_in_bytes
-r--r--r-- 1 root root 0 Sep 2 15:21 memory.memsw.usage_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 15:21 memory.move_charge_at_immigrate
-r--r--r-- 1 root root 0 Sep 2 15:21 memory.numa_stat
-rw-r--r-- 1 root root 0 Sep 2 15:13 memory.oom_control
---------- 1 root root 0 Sep 2 15:21 memory.pressure_level
-rw-r--r-- 1 root root 0 Sep 2 15:21 memory.soft_limit_in_bytes
-r--r--r-- 1 root root 0 Sep 2 15:21 memory.stat
-rw-r--r-- 1 root root 0 Sep 2 15:21 memory.swappiness
-r--r--r-- 1 root root 0 Sep 2 15:12 memory.usage_in_bytes
-rw-r--r-- 1 root root 0 Sep 2 15:21 memory.use_hierarchy
-rw-r--r-- 1 root root 0 Sep 2 15:21 notify_on_release
-rw-r--r-- 1 root root 0 Sep 2 15:21 tasks
由上可以看到,容器 ID 的目录下有很多文件,其中 memory.limit_in_bytes 文件代表该容器内存限制大小,单位为 byte,我们使用 cat 命令(cat 命令可以查看文件内容)查看一下文件内容:
$ sudo cat /sys/fs/cgroup/memory/docker/51041a74070e9260e82876974762b8c61c5ed0a51832d74fba6711175f89ede1/memory.limit_in_bytes
2147483648
这里可以看到memory.limit_in_bytes 的值为2147483648,转换单位后正好为 2G,符合我们启动容器时的内存限制 2G。
通过 memory 子系统的例子,我们可以知道监控组件通过读取 memory.limit_in_bytes 文件即可获取到容器内存的限制值。了解完容器的内存限制我们来了解一下容器的内存使用情况。
监控系统是如何获取容器的内存使用状态的?
内存使用情况存放在 memory.usage_in_bytes 文件里,同样我们也使用 cat 命令查看一下文件内容:
cat /sys/fs/cgroup/memory/docker/51041a74070e9260e82876974762b8c61c5ed0a51832d74fba6711175f89ede1/memory.usage_in_bytes
4259840
可以看到当前内存的使用大小为 4259840 byte,约为 4 M。了解了内存的监控,下面我们来了解下网络的监控数据来源。
监控系统是如何获取网络的监控数据的?
网络的监控数据来源是从 /proc/{PID}/net/dev 目录下读取的,其中 PID 为容器在主机上的进程 ID****。下面我们首先使用 docker inspect 命令查看一下上面启动的 nginx 容器的 PID,命令如下:
$ docker inspect nginx |grep Pid
"Pid": 27348,
"PidMode": "",
"PidsLimit": 0,
可以看到容器的 PID 为 27348,使用 cat 命令查看一下 /proc/27348/net/dev 的内容:
$ sudo cat /proc/27348/net/dev
Inter-| Receive | Transmit
face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed
lo: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
eth0: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
/proc/27348/net/dev 文件记录了该容器里每一个网卡的流量接收和发送情况,以及错误数、丢包数等信息。可见容器的网络监控数据都是定时从这里读取并展示的。
总结一下,容器的监控原理其实就是定时读取 Linux主机上相关的文件并展示给用户。
9.cgroups实现资源限制
使用不同的Namespace,可以实现容器中的进程看不到别的容器的资源,但是有个问题:容器内的进程仍然可以任意的使用主机CPU、内存等资源。如果某一个容器使用的主机过多,可能导致主机的资源竞争,进而影响业务,那如果我们想限制一个容器资源的使用(如CPU、内存等)应该如何做呢?
这里就需要linux内核的另一个核心技术:cgroups。
cgroups(control groups)是linux内核的一个功能,它可以实现限制进程或者进程组的资源(如CPU、内存、磁盘IO等)。
cgroups目前已经成为systemd、Docker、linux Containers(LXC)等技术的基础。
cgroups功能及核心概念
cgroups主要提供了如下功能:
- 资源限制:限制资源的使用量,例如我们可以通过限制某个业务的内存上限,从而保护主机其他业务的正常运行。
- 优先级控制:不同的组可以有不同的资源(CPU、磁盘IO等)使用优先级。
- 资源审计:计算控制组的资源使用情况。也就是统计硬件资源的使用量。
- 控制:控制进程的挂起或恢复。
了解cgroups可以为我们提供什么功能,下面我们看下cgroups是如何实现这些功能的。
cgroups功能的实现依赖于三个核心概念:子系统、控制组、层级树。
- 子系统(subsystem):是一个内核的组件,一个子系统代表一类资源调度控制器。例如内存子系统可以限制内存的使用量,CPU子系统可以限制CPU的使用时间。
子系统可以控制什么东西?利用libcgroup-tools工具包来验证:
[root@localhost memtester-4.2.2]# yum -y install libcgroup-tools
列出系统中所有的cgroup组:
[root@localhost memtester-4.2.2]# lscgroup
net_cls,net_prio:/
pids:/
freezer:/
perf_event:/
blkio:/
cpu,cpuacct:/
cpu,cpuacct:/mydocker
devices:/
devices:/user.slice
devices:/system.slice
devices:/system.slice/udisks2.service
devices:/system.slice/colord.service
devices:/system.slice/wpa_supplicant.service
devices:/system.slice/packagekit.service
devices:/system.slice/upower.service
devices:/system.slice/crond.service
devices:/system.slice/atd.service
devices:/system.slice/gdm.service
devices:/system.slice/libvirtd.service
devices:/system.slice/cups.service
devices:/system.slice/sshd.service
devices:/system.slice/tuned.service
devices:/system.slice/postfix.service
devices:/system.slice/NetworkManager.service
devices:/system.slice/ksmtuned.service
devices:/system.slice/firewalld.service
devices:/system.slice/rtkit-daemon.service
devices:/system.slice/polkit.service
devices:/system.slice/vmtoolsd.service
devices:/system.slice/accounts-daemon.service
devices:/system.slice/lvm2-lvmetad.service
devices:/system.slice/systemd-logind.service
devices:/system.slice/alsa-state.service
devices:/system.slice/systemd-journald.service
devices:/system.slice/abrt-oops.service
devices:/system.slice/systemd-udevd.service
devices:/system.slice/libstoragemgmt.service
devices:/system.slice/vgauthd.service
devices:/system.slice/avahi-daemon.service
devices:/system.slice/rngd.service
devices:/system.slice/rsyslog.service
devices:/system.slice/dbus.service
devices:/system.slice/ModemManager.service
devices:/system.slice/bluetooth.service
devices:/system.slice/auditd.service
devices:/system.slice/abrt-xorg.service
devices:/system.slice/irqbalance.service
devices:/system.slice/smartd.service
devices:/system.slice/gssproxy.service
devices:/system.slice/abrtd.service
devices:/system.slice/chronyd.service
hugetlb:/
memory:/
memory:/mydocker
cpuset:/
查看subsystem可以控制的硬件:
[root@localhost memtester-4.2.2]# lssubsys -a
cpuset
cpu,cpuacct
memory
devices
freezer
net_cls,net_prio
blkio
perf_event
hugetlb
pids
以上都存在于/sys/fs/cgroup/目录
[root@localhost memtester-4.2.2]# ll /sys/fs/cgroup/
总用量 0
drwxr-xr-x. 2 root root 0 4月 17 15:10 blkio
lrwxrwxrwx. 1 root root 11 4月 17 15:10 cpu -> cpu,cpuacct
lrwxrwxrwx. 1 root root 11 4月 17 15:10 cpuacct -> cpu,cpuacct
drwxr-xr-x. 3 root root 0 4月 17 15:10 cpu,cpuacct
drwxr-xr-x. 2 root root 0 4月 17 15:10 cpuset
drwxr-xr-x. 4 root root 0 4月 17 15:10 devices
drwxr-xr-x. 2 root root 0 4月 17 15:10 freezer
drwxr-xr-x. 2 root root 0 4月 17 15:10 hugetlb
drwxr-xr-x. 3 root root 0 4月 17 18:57 memory
lrwxrwxrwx. 1 root root 16 4月 17 15:10 net_cls -> net_cls,net_prio
drwxr-xr-x. 2 root root 0 4月 17 15:10 net_cls,net_prio
lrwxrwxrwx. 1 root root 16 4月 17 15:10 net_prio -> net_cls,net_prio
drwxr-xr-x. 2 root root 0 4月 17 15:10 perf_event
drwxr-xr-x. 2 root root 0 4月 17 15:10 pids
drwxr-xr-x. 4 root root 0 4月 17 15:10 systemd
可以看到目录中的内容是比命令查看到的多,是因为有几个软链接文件。
# 以下三个都属于cpu,cpuacct
cpu -> cpu,cpuacct
cpuacct -> cpu,cpuacct
cpu,cpuacct
# 以下三个都属于net_cls,net_prio
net_cls -> net_cls,net_prio
net_prio -> net_cls,net_prio
net_cls,net_prio
subsystem可以控制的内容分布代表什么?
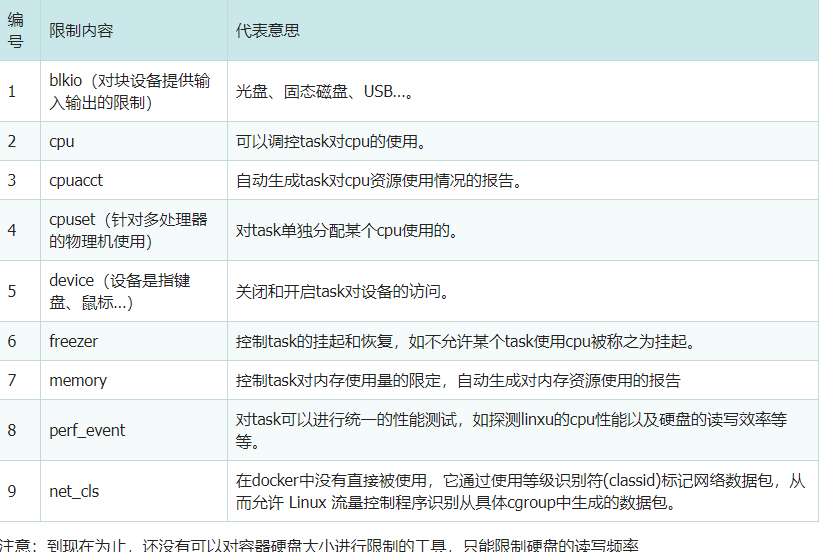
注意:到现在为止,还没有可以对容器硬盘大小进行限制的工具,只能限制硬盘的读写频率****。
控制组(cgroup):表示一组进程和一组带有参数的子系统的关联关系。例如,一个进程使用了CPU子系统来限制CPU的使用时间,则这个进程和CPU子系统的关联称为控制组。
- 层级树(hierarchy****):是由一系列的控制组按照树状结构排列组成的。这种排列的方式可以使得控制组拥有父子关系,子控制组默认拥有父控制组的属性。也就是子控制组会继承于父控制组。例如:系统中定义了一个控制组c1,限制了CPU可以使用1核,然后另外一个控制组c2想实现既限制CPU使用1核,同时限制内存使用2G,那么c2就可以直接继承c1,无需重复定义CPU限制。
- task:表示系统中某一进程的ID。
关系:一个cgroup里可以有多个task,subsystem相当于控制cgroup限制的类型,hierarchy里可以有很多个cgroup,一个系统可以有很多个hierarchy****。
层级树的四大规则:
传统的进程启动,是以init为根起点,也叫父进程,由他创建子进程作为子节点,而每个子节点
还可以创建新的子节点,这样就形成了树状结构。而cgroup的结构和它的结构类似,子节点继承父节点的属性。他们最大的 不同在于系统的cgroup构成的层级树允许有多个存在。如果进程是以init为根节点形成一个树,那cgroup的模型由多个层级树来构成。
如果只有一个层级数,所有的task都会受到一个subsystem的限制,这会给不需要这种限制的task造成麻烦。
1.同一层级树(hierarchy)可以附加一个或多个子系统(subsystem)。
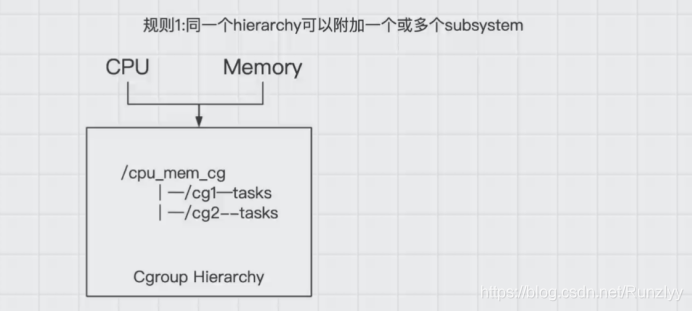
可以看到在一个层级树中,有一个cpu_mem_cg的cgroup组下有两个子节点cg1和cg2.如上图所示,也就意味着在cpu_mem_cg的组中,附加了cpu和mem内存两个子系统。同时来控制cg1和cg2的cpu和内存的硬件资源。相当于一个层级树可以限制更多的类型。例如cpu、Memory、磁盘IO。
2.一个子系统可以附加到多个层级树中,但是仅仅是可以附加到多个没有任何子系统的层级树中。
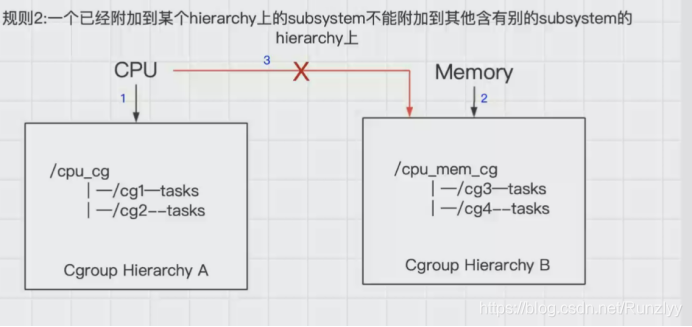
如上图所示,cpu子系统先附加到层级树A上,同时就不能附加到层级树B上,(例如:层次树A限制了内存的使用为500M,但是层次树B是限制1G,这样会发生冲突)因为B上已经有了一个mem子系统,如果B和A同时都是没有任何子系统时,cpu子系统可以同时附加到A和B两个层级树中。言外之意就是如果多个层级树都没有子系统,这个时候一个cpu子系统依次可以附加到这些层级树中。
3.一个进程(task)不能属于同一层次树(hierarchy)的不同cgroup中,仅仅可以属于不同的hierarchy中的不同cgroup中。
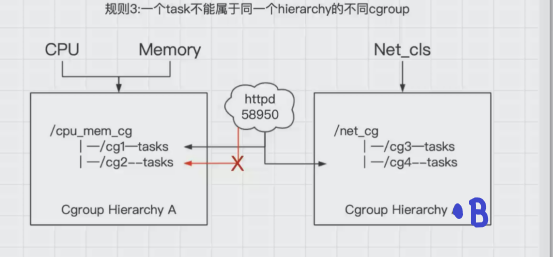
系统每次新建一个层级树(hierarchy)时,默认的构成了新的层级树的初始化的cgroup,这个cgroup被称为root cgroup,对于你自己成功的层级树(hierarchy)来说,task只能存在这个层级树的一个cgroup当中,意思就是一个层级树中不能出现两个相同的task,但是它可以存在不同的层级树中的其他cgroup。
如果要将一个层级树cgroup中的task添加到这个层级树的其他cgroup时,会被从之前task所在的cgroup移除。
例如:httpd已经加入到层级树(hierarchy)A中的cg1中,且pid为58950,此时就不能将这个httpd进程放入到cg2中,不然cg1中的httpd进程就会被删除,但是可以放到层级树(hierarchy)B的cg3控制组中。
其实是为了防止出现进程矛盾,如:在层级树A中的cg1中存在httpd进程,这时cpu对cg1的限制使用率为30%,cg2的限制使用率为50%,如果再将httpd进程添加到cg2中,这时httpd的cpu使用率限制就有了矛盾。
4.****刚fork出的子进程在初始状态与父进程处于同一个cgroup.
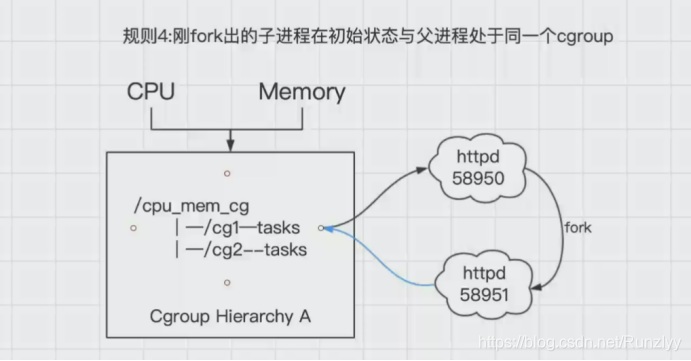
进程task新开的一个子进程(child_task)默认是和原来的task在同一个cgroup中,但是child_task允许被移除到该层级树的其他不同的cgroup中。
当fork刚完成之后,父进程和子进程是完全独立的
如图中所示中,httpd58950进程,当有人访问时,会fork出另外一个子进程httpd58951,这个时候默认httpd58951和httpd58950都在cg1中,他们的关系也是父子进程,httpd58951是可以移动到cg2中,这时候就改变了他们的关系,都变为了独立的进程。
cgroups的三个核心概念中,子系统是核心的概念,因为子系统是真正实现某类资源的限制的基础。
cgroup的特点:
cgroup管理可以管理到线程级别。
所有线程功能都是subsystem(子系统)统一管理方式。
子进程和父进程在同一cgroup里,只需要控制父进进程就可以实现对子进程的控制,
cgroup的子系统实例:
下面我们通过一个实例演示在centos7上默认都启动了哪些子系统。
我们先通过mount命令查看一下当前系统已经挂载的cgroups信息:
[root@localhost ~]# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
通过输出,可以看到当前系统已经挂载了我们常用的cgroups子系统。例如CPU、memory、pids等我们常用的cgroups子系统。这些子系统中,cpu和memory子系统是容器环境中使用最多的子系统。下面对这两个子系统作详细的介绍。
(1)CPU子系统
首先以CPU子系统为例,演示一下cgroups如恶化限制进程的cpu使用时间。由于cgroups的操作很多需要用到root权限。所以我们要确保已经切换到了root用户!
一****、在CPU子系统创建cgroup
cgroups的创建方法很简单,只需要在相应的子系统下创建目录即可。下面我们到cpu子系统下创建测试文件夹。
cpu子系统的工作目录:
/sys/fs/cgroup/cpu/
创建文件夹:
[root@localhost ~]# mkdir /sys/fs/cgroup/cpu/mydocker
执行完上述命令后,我们查看下我们新建的目录下发生了什么?
[root@localhost ~]# ls -l /sys/fs/cgroup/cpu/mydocker/
总用量 0
-rw-r--r--. 1 root root 0 4月 17 15:22 cgroup.clone_children
--w--w--w-. 1 root root 0 4月 17 15:22 cgroup.event_control
-rw-r--r--. 1 root root 0 4月 17 15:22 cgroup.procs
-r--r--r--. 1 root root 0 4月 17 15:22 cpuacct.stat
-rw-r--r--. 1 root root 0 4月 17 15:22 cpuacct.usage
-r--r--r--. 1 root root 0 4月 17 15:22 cpuacct.usage_percpu
-rw-r--r--. 1 root root 0 4月 17 15:22 cpu.cfs_period_us
-rw-r--r--. 1 root root 0 4月 17 15:22 cpu.cfs_quota_us
-rw-r--r--. 1 root root 0 4月 17 15:22 cpu.rt_period_us
-rw-r--r--. 1 root root 0 4月 17 15:22 cpu.rt_runtime_us
-rw-r--r--. 1 root root 0 4月 17 15:22 cpu.shares
-r--r--r--. 1 root root 0 4月 17 15:22 cpu.stat
-rw-r--r--. 1 root root 0 4月 17 15:22 notify_on_release
-rw-r--r--. 1 root root 0 4月 17 15:22 tasks
由上可以看到我们夏娜金的目录下被自动创建了很多的文件,其中cpu.cfs_quota_us文件代表在某一阶段限制的CPU时间总量,单位为微秒。例如:我们想限制某个进程最多使用1核CPU,就在这个文件里写入100000(100000代表限制1个核),tasks文件中写入进程的ID(如果要限制多个进程ID,在tasks文件中使用换行符分隔即可)。
echo 100000 > /sys/fs/cgroup/cpu/mydocker/cpu.cfs_quota_us
为了实验的准确性,我们这里使用0.5核,也就是:
echo 50000 > /sys/fs/cgroup/cpu/mydocker/cpu.cfs_quota_us
此时,我们所需要的cgroup就创建好了。
二、创建进程并加入到cgroup
这里为了方便演示,我先把当前运行的shell进程加入到cgroup,然后在当前shell运行cpu耗时任务(这里利用到了继承,子进程会继承父进程的cgroup)。
使用以下命令将shell进程加入到cgroup:
echo $$ > /sys/fs/cgroup/cpu/mydocker/tasks
查看下tasks的内容:
[root@localhost ~]# cat /sys/fs/cgroup/cpu/mydocker/tasks
3118
3478
其中第一个进程ID为当前shell的主进程,也就是说当前shell主进程为3118.
三、执行CPU耗时任务并验证
使用以下命令制造一个死循环来提升cpu使用率:
while true;do echo;done;
执行完上述命令后,我们新打开一个shell窗口,使用top -p命令查看当前cpu使用率,-p参数后面跟进程ID,我这里是3118.
top -p 3118
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3118 root 20 0 116880 3564 1904 R 35.0 0.1 3:04.60 bash
通过上面输出,此时cpu使用率已经被限制到了50%以下。
(2)memory子系统
一、在memory子系统下创建cgroup
[root@localhost ~]# mkdir /sys/fs/cgroup/memory/mydocker
同样,我们查看新创建的目录下:
[root@localhost ~]# ls /sys/fs/cgroup/memory/mydocker
cgroup.clone_children memory.kmem.tcp.max_usage_in_bytes memory.oom_control
cgroup.event_control memory.kmem.tcp.usage_in_bytes memory.pressure_level
cgroup.procs memory.kmem.usage_in_bytes memory.soft_limit_in_bytes
memory.failcnt memory.limit_in_bytes memory.stat
memory.force_empty memory.max_usage_in_bytes memory.swappiness
memory.kmem.failcnt memory.memsw.failcnt memory.usage_in_bytes
memory.kmem.limit_in_bytes memory.memsw.limit_in_bytes memory.use_hierarchy
memory.kmem.max_usage_in_bytes memory.memsw.max_usage_in_bytes notify_on_release
memory.kmem.slabinfo memory.memsw.usage_in_bytes tasks
memory.kmem.tcp.failcnt memory.move_charge_at_immigrate
memory.kmem.tcp.limit_in_bytes memory.numa_stat
其中memory.limit_in_bytes文件代表内存使用总量,单位为byte****。
例如,这里我希望对内存使用限制为1G,则向memory.lint_in_bytes文件写入1073741824,命令如下:
[root@localhost ~]# echo 1073741824 > /sys/fs/cgroup/memory/mydocker/memory.limit_in_bytes
二、创建进程并加入cgroup
同样把当前shell进程ID写入tasks文件内:
[root@localhost ~]# echo $$ > /sys/fs/cgroup/memory/mydocker/tasks
查看下进程ID:3118
[root@localhost memtester-4.2.2]# cat /sys/fs/cgroup/memory/mydocker/tasks
3118
6986
三·、借助memtester工具进行测试
1.安装memtester
1.安装gcc
[root@localhost ~]# yum -y install gcc
2.下载安装包并安装
[root@localhost tmp]# cd /tmp
wget http://pyropus.ca./software/memtester/old-versions/memtester-4.2.2.tar.gz --no-check-certificate
[root@localhost tmp]# tar xf memtester-4.2.2.tar.gz
[root@localhost tmp]# cd memtester-4.2.2/
[root@localhost memtester-4.2.2]# make && make install
[root@localhost memtester-4.2.2]# cp memtester /bin/memtester
安装好memtester后,我们执行以下命令:
[root@localhost memtester-4.2.2]# memtester 1500M 1
memtester version 4.2.2 (64-bit)
Copyright (C) 2010 Charles Cazabon.
Licensed under the GNU General Public License version 2 (only).
pagesize is 4096
pagesizemask is 0xfffffffffffff000
want 1500MB (1572864000 bytes)
got 1500MB (1572864000 bytes), trying mlock ...已杀死
该命令会申请1500M内存,并且做内存测试。由于上面我们对当前shell进程内存限制为1G,当memtester使用的内存达到1G时,cgroup便将memtester杀死。
上面最后一行的输出结果表示memtester想要1500M内存,但是由于cgroup限制,达到了内存使用上限然后被杀死了。
我们可以使用以下命令,降低内存申请,将内存申请调整为500M
[root@localhost memtester-4.2.2]# memtester 500M 1
memtester version 4.2.2 (64-bit)
Copyright (C) 2010 Charles Cazabon.
Licensed under the GNU General Public License version 2 (only).
pagesize is 4096
pagesizemask is 0xfffffffffffff000
want 500MB (524288000 bytes)
got 500MB (524288000 bytes), trying mlock ...locked.
Loop 1/1:
Stuck Address : ok
Random Value : ok
Compare XOR : ok
Compare SUB : ok
Compare MUL : ok
Compare DIV : ok
Compare OR : ok
Compare AND : ok
Sequential Increment: ok
Solid Bits : ok
Block Sequential : ok
Checkerboard : ok
Bit Spread : ok
Bit Flip : ok
Walking Ones : ok
Walking Zeroes : ok
8-bit Writes : ok
16-bit Writes : ok
Done.
可以看到此时的memtester已经成功的申请到500M内存并且正常的完成了内存的测试。
删除cgroups
上面创建的cgroups如果不想使用了,直接删除创建的文件夹即可。
例如我想删除内存下的mydocker目录,使用以下命令即可:
rmdir /sys/fs/cgroup/memory/mydocker/
Docker如何使用cgroups
首先我们使用以下命令创建一个nginx容器:
docker run -dit --name nginx01 -m=1g nginx
上述命令创建并启动一个nginx容器,并且限制内存为1G。然后我们进入到cgroups内存子目录,使用ls命令查看一下该目录下的内容:
[root@localhost /]# ll /sys/fs/cgroup/memory/
总用量 0
-rw-r--r--. 1 root root 0 4月 17 15:10 cgroup.clone_children
--w--w--w-. 1 root root 0 4月 17 15:10 cgroup.event_control
-rw-r--r--. 1 root root 0 4月 17 15:10 cgroup.procs
-r--r--r--. 1 root root 0 4月 17 15:10 cgroup.sane_behavior
drwxr-xr-x. 3 root root 0 4月 17 21:10 docker
...................................
通过上面的输出内容可以看到,该目录下有一个docker目录,该目录正是docker在内存子系统下创建的。我们进入到docker目录下查看一下相关内容:
[root@localhost /]# ll /sys/fs/cgroup/memory/docker
总用量 0
drwxr-xr-x. 2 root root 0 4月 17 21:11 90aa9acdce94e804dffb7416d6363c2420eb33b9a7b0c4ec77db1b4adf1b4f00
-rw-r--r--. 1 root root 0 4月 17 21:09 cgroup.clone_children
--w--w--w-. 1 root root 0 4月 17 21:09 cgroup.event_control
-rw-r--r--. 1 root root 0 4月 17 21:09 cgroup.procs
-rw-r--r--. 1 root root 0 4月 17 21:09 memory.failcnt
--w-------. 1 root root 0 4月 17 21:09 memory.force_empty
-rw-r--r--. 1 root root 0 4月 17 21:09 memory.kmem.failcnt
可以看到docker的目录下有一个一串随机ID的目录,该目录名字就是我们我们创建nginx容器的ID。然后我们进入到该目录,查看一下该容器的memory.limit_in_bytes文件内容:
[root@localhost /]# cat /sys/fs/cgroup/memory/docker/90aa9acdce94e804dffb7416d6363c2420eb33b9a7b0c4ec77db1b4adf1b4f00/me
mory.limit_in_bytes
1073741824
可以看到内存限制值为1G。
事实上,Docker 创建容器时,Docker 会根据启动容器的参数,在对应的 cgroups 子系统下创建以容器 ID 为名称的目录, 然后根据容器启动时设置的资源限制参数, 修改对应的 cgroups 子系统资源限制文件, 从而达到资源限制的效果。
另外,请注意 cgroups 虽然可以实现资源的限制,但是不能保证资源的使用。例如,cgroups 限制某个容器最多使用 1 核 CPU,但不保证总是能使用到 1 核 CPU,当 CPU 资源发生竞争时,可能会导致实际使用的 CPU 资源产生竞争。
https://blog.csdn.net/RunzIyy/article/details/105113747

 浙公网安备 33010602011771号
浙公网安备 33010602011771号