[Go爬虫01]古诗文网爬取诗文(并发)
0. 前提
要做Go的爬虫就要有Go的HTTP编程的基础、以及一定的正则表达式基础,当然正则表达式属于是博大精深了,只是简单的小爬虫,只需要用文中提到的用法即可。
关于这一篇博客主要涉及到的是:
- 如何确定要爬取的url以及内容
- 如何找特殊标识来定位元素
- 如何应对取多个元素
- 如何应对html中独特标识含有换行
- 如何消除文本中的多余符号
1. 确定要爬取的URL及内容
我们的目标就是这个这个网址https://so.gushiwen.cn/shiwens/中的诗文,包括诗词的标题、作者(朝代)、内容。

先多看几页找一找这些页面显示的内容以及url的一些特点。观察后发现,点击下一页会变化的只有url上的page=?,这就代表了页码;再者每一首诗词确实都是由三部分组成,包括标题、作者、内容。
知道了以上的信息,确定了我们要爬取的信息(下面三个红框的内容),就可以着手写程序了。

2. 获取网站源代码
① 流程
做爬虫,需要明确自己程序的工作流程,这样写代码的可读性高,思路更加清晰。大体的流程如下图所示:

当然上面不一定正确,因为最终的代码是并发的。
② 获取源代码
package main
import (
"fmt"
"net/http"
"os"
"strconv"
)
func main() {
var start, end int // 爬取的起始页和终止页
fmt.Println("请输入起始页(≥1):")
fmt.Scan(&start)
fmt.Println("请输入终止页(≥起始页):")
fmt.Scan(&end)
SpiderRun(start, end) // 启动爬虫
}
func SpiderRun(start, end int) {
fmt.Printf("正在爬取%d - %d页的内容", start, end)
f, err := os.Create("古诗文.txt") // 创建文件存放爬取的内容
if err != nil {
return
}
defer f.Close() // 程序结束后关闭文件
for i := start; i <= end; i++ { // 单独的爬取每一页
SpiderPage(i, f)
}
}
func SpiderPage(i int, f *os.File) {
url := "https://so.gushiwen.cn/shiwens/default.aspx?page=" + strconv.Itoa(i) // 获取这一页的url
fmt.Println("正在爬取第%d页:%s", i, url)
pageHtml, err := SpiderGet(url) // 获取这一页的源代码
if err != nil {
return
}
f.Write([]byte(pageHtml))
}
func SpiderGet(url string) (pageHtml string, err error) {
resp, err1 := http.Get(url) // 向网站发送get请求
if err1 != nil {
err = err1
return
}
defer resp.Body.Close() // 关闭响应体
buf := make([]byte, 1024*8) // 用来接收返回的内容
for {
n, _ := resp.Body.Read(buf)
if n == 0 { // 当n == 0时代表已经读取完毕。
break
}
pageHtml += string(buf[:n]) // 将读取到的内容以string格式存放
}
return
}
通过以上代码就能够获取到网站的所有源代码信息了,只要在其中检索、提取我们需要的内容就可以了。上面的代码也算是小型爬虫的通用模式了。
3. 数据加工(检索提取数据)
① 检索源代码
这个时候,我们要通过F12开发者模式或者鼠标右键网页选择查看网页源代码去对源代码进行一个分析。
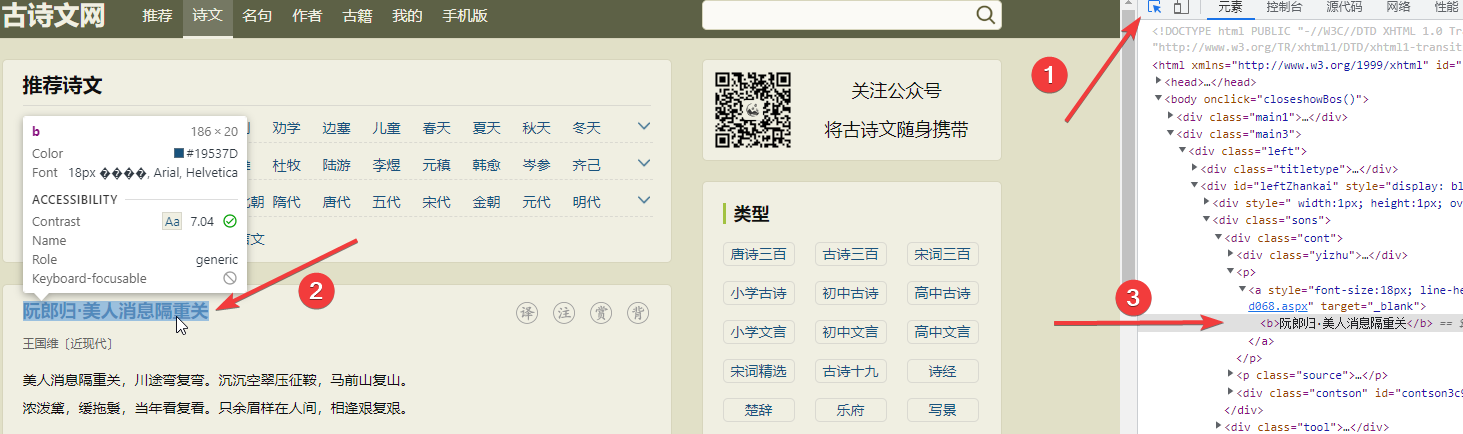
F12打开开发这模式之后,点击箭头所指向的标志,再点击想要查找的元素,可以快速在源代码中定位元素(如③所指)。
ps. 我自己在使用的时候F12的搜索很怪,可能是没用明白,因此在F12中找完标签以后就去查看网页源代码里搜索。
② 通过独特标识定位元素
这时候我们需要找到这些元素独特的辨识标志,也就是让我们能够准确定位的一个标识,它们大概率有一个共同的并且与其他元素不同的标志,这就要考验我们的耐心了(正则查找就是这样,之前用python也有用过xpath查找的方法与这种方式就不太相同了)。
通过在开发者模式中ctrl+f搜索东西;第一个标题,我们发现每一个标题必然是在<b></b>内(因为一页只有10首诗词),这时候这个就可以来帮助我们定位了。
ps. 如果开发者模式里的搜索不好用,可以去右键查看网页源代码,通过ctrl + f来搜索!
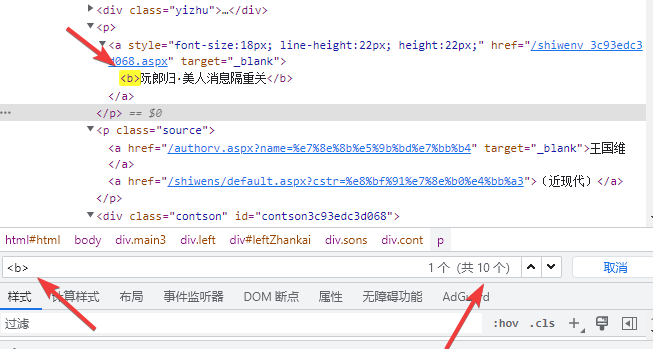
re := regexp.MustCompile(`<b>(.+?)</b>`)
content := re.FindAllStringSubmatch(pageHtml, -1)
这里就要用到上面的两个语句了。在regexp.MustCompile()里面就是想好了的正则表达式,其中(.+?)就是最好用的一种选中方法,他代表把<b>和</b>之间的所有内容作为一个小组全部记录下来。
而下面的语句就是用你指定的规则去找全部符合规定的数据,-1代表全部。
此时,遍历content,第一个参数是下标不需要,第二个参数是一个二维数组。
for _, y := range content {
txtContent += y[1] + "\n"
}
其中y[0]一定表示的是完整的匹配上的字符串也就是<b>xxx</b>。从y[1]开始就是你设置好的小组按顺序排序,如果只有一个()那么就只有一个小组。y[1]的内容就是xxx。
之后也就是这个流程,找到作者、内容的独特元素即可,后面只挑重点来讲。
③ 取多个元素、html换行
后来我们发现作者和朝代其实是分开的两个部分;并且作者和内容的标志之间有换行。

一步步来,我们先把这个特定的格式复制下来。

之后我们把所有每首诗不同的地方(如herf、id等)给变成.+?注意这里不需要加()。
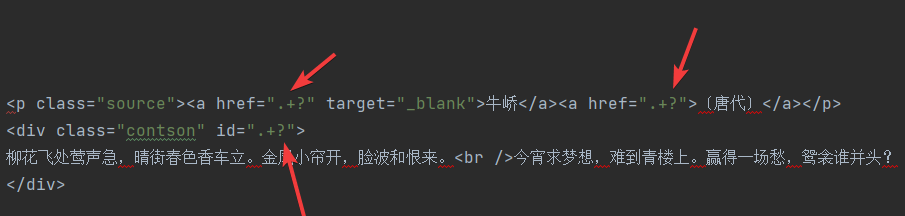
最后我们用\s来接收回车,把需要提取的信息(.+?)即可。
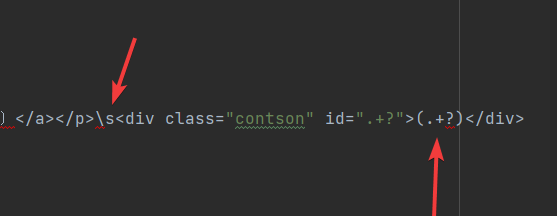
最终我们得到如下的表达式:
<p class="source"><a href=".+?" target="_blank">(.+?)</a><a href=".+?">(.+?)</a></p>\s<div class="contson" id=".+?">(.+?)</div>
可以看得出来我们有三个(.+?)和三个.+?,有什么区别呢?加上括号他会用来匹配字符串并且保留下来,而如果不加括号,他只会用来匹配字符串而不会被保留。
很显然我们需要保留下来需要的信息,因此需要加括号。
最后你会发现这样是错误的,无法匹配到字符,我也是刚发现。
问题出在文章中有换行,而正则表达式中的.不能够匹配换行符,因此会产生错误,这里只需要把最后一个(.+?)换成([/s/S]+?)就可以解决问题了。
[/s/S]就可以匹配任意一个字符,包括换行符,详细百度正则表达式查询。
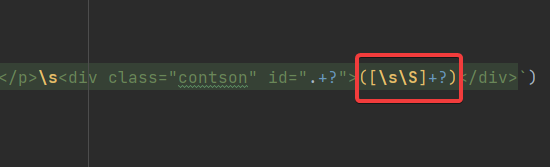
此时我的匹配以及拼接代码如下:
re1 := regexp.MustCompile(`<b>(.+?)</b>`)
title := re1.FindAllStringSubmatch(pageHtml, -1)
re2 := regexp.MustCompile(`<p class="source"><a href=".+?" target="_blank">(.+?)</a><a href=".+?">(.+?)</a></p>\s<div class="contson" id=".+?">([\s\S]+?)</div>`)
content := re2.FindAllStringSubmatch(pageHtml, -1)
for j := 0; j < 10; j++ {
txtContent += title[j][1] + "\n" + content[j][1] + content[j][2] + content[j][3] + "\n"
}
f.Write([]byte(txtContent))
因为每页有10首诗词,因此这里设置了一个[0,10)的循环,前面提到过title是一个二维的string数组,第一维代表的是第几个符合正则的文段,第二维就是我们通过()来进行的分组。
因此按照上面的方法就可以初步的得到古诗文:

这就涉及到我们数据处理的最后一个问题,这些东西怎么处理掉?
④ 消除文本中多余的字符
只需要借助strings.Replace()进行一个文本的替换就可以了。多试几次就能成功,实践是检验真理的唯一标准。
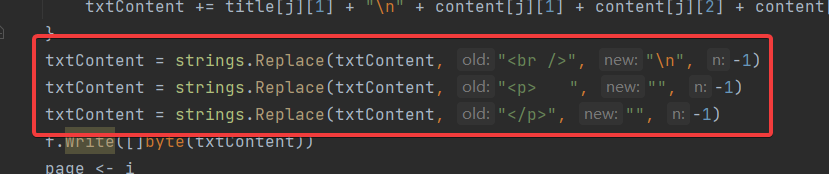
最终代码(并发):
并发是借助了通道来让程序不会因为主协程结束而结束。通道的用法不再赘述。
package main
import (
"fmt"
"net/http"
"os"
"regexp"
"strconv"
"strings"
)
func main() {
var start, end int // 爬取的起始页和终止页
fmt.Println("请输入起始页(≥1):")
fmt.Scan(&start)
fmt.Println("请输入终止页(≥起始页):")
fmt.Scan(&end)
SpiderRun(start, end) // 启动爬虫
}
func SpiderRun(start, end int) {
fmt.Printf("正在爬取%d - %d页的内容\n", start, end)
f, err := os.Create("古诗文.txt") // 创建文件存放爬取的内容
if err != nil {
return
}
defer f.Close() // 程序结束后关闭文件
page := make(chan int)
for i := start; i <= end; i++ { // 单独的爬取每一页
go SpiderPage(i, f, page)
}
for i := start; i <= end; i++ {
fmt.Printf("第%d页已经完成\n", <-page) // 防止主程序完成直接退出。
}
}
func SpiderPage(i int, f *os.File, page chan int) {
var txtContent string
url := "https://so.gushiwen.cn/shiwens/default.aspx?page=" + strconv.Itoa(i) // 获取这一页的url
fmt.Printf("正在爬取第%d页:%s\n", i, url)
pageHtml, err := SpiderGet(url) // 获取这一页的源代码
if err != nil {
return
}
re1 := regexp.MustCompile(`<b>(.+?)</b>`)
title := re1.FindAllStringSubmatch(pageHtml, -1)
re2 := regexp.MustCompile(`<p class="source"><a href=".+?" target="_blank">(.+?)</a><a href=".+?">(.+?)</a></p>\s<div class="contson" id=".+?">([\s\S]+?)</div>`)
content := re2.FindAllStringSubmatch(pageHtml, -1)
for j := 0; j < 10; j++ {
txtContent += title[j][1] + "\n" + content[j][1] + content[j][2] + content[j][3] + "\n"
}
txtContent = strings.Replace(txtContent, "<br />", "\n", -1)
txtContent = strings.Replace(txtContent, "<p> ", "", -1)
txtContent = strings.Replace(txtContent, "</p>", "", -1)
f.Write([]byte(txtContent))
page <- i
}
func SpiderGet(url string) (pageHtml string, err error) {
resp, err1 := http.Get(url) // 向网站发送get请求
if err1 != nil {
err = err1
return
}
defer resp.Body.Close() // 关闭响应体
buf := make([]byte, 1024*8) // 用来接收返回的内容
for {
n, _ := resp.Body.Read(buf)
if n == 0 { // 当n == 0时代表已经读取完毕。
break
}
pageHtml += string(buf[:n]) // 将读取到的内容以string格式存放
}
return
}
ps.做完以后发现,诗文只有4页,再往后改page只会重复第4页,不过重要的是方法和思想,代码本身倒是其次的了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号