
高并发系统设计(二十九):【计数系统设计】面对海量数据的计数器要如何做?50万QPS下如何设计未读数系统?
面对海量数据的计数器要如何做?
刷微博、点赞热搜,如果有抽奖活动,再转发一波,其实就是微博场景下的计数数据,细说起来,它主要有几类:
- 微博的评论数、点赞数、转发数、浏览数、表态数等等;
- 用户的粉丝数、关注数、发布微博数、私信数等等。
微博维度的计数代表了这条微博受欢迎的程度,用户维度的数据(尤其是粉丝数),代表了这个用户的影响力,因此大家会普遍看重这些计数信息。并且在很多场景下都需要查询计数数据(比如首页信息流页面、个人主页面),计数数据访问量巨大,所以需要设计计数系统维护它。
但在设计计数系统时,不少人会出现性能不高、存储成本很大的问题,比如,把计数与微博数据存储在一起,这样每次更新计数的时候都需要锁住这一行记录,降低了写入的并发。
计数在业务上的特点
- 数据量巨大。微博系统中微博条目的数量早已经超过了千亿级别,仅仅计算微博的转发、评论、点赞、浏览等核心计数,其数据量级就已经在几千亿的级别。更何况微博条目的数量还在不断高速地增长,并且随着微博业务越来越复杂,微博维度的计数种类也可能会持续扩展(比如说增加了表态数),因此,仅仅是微博维度上的计数量级就已经过了万亿级别。除此之外,微博的用户量级已经超过了10亿,用户维度的计数量级相比微博维度来说虽然相差很大,但是也达到了百亿级别。那么如何存储这些过万亿级别的数字,对我们来说就是一大挑战。
- 访问量大,对于性能的要求高。微博的日活用户超过2亿,月活用户接近5亿,核心服务(比如首页信息流)访问量级到达每秒几十万次,计数系统的访问量级也超过了每秒百万级别,而且在性能方面,它要求要毫秒级别返回结果。
- 最后,对于可用性、数字的准确性要求高。一般来讲,用户对于计数数字是非常敏感的,比如你直播了好几个月,才涨了1000个粉,突然有一天粉丝数少了几百个,那么你是不是会琢磨哪里出现问题,或者打电话投诉直播平台?
支撑高并发的计数系统要如何设计
刚开始设计计数系统的时候,假如要存储微博维度(微博的计数,转发数、赞数等等)的数据,可以这么设计表结构:以微博ID为主键,转发数、评论数、点赞数和浏览数分别为单独一列,这样在获取计数时用一个SQL语句就搞定了。
select repost_count, comment_count, praise_count, view_count from t_weibo_count where weibo_id = ?
后来,随着微博的不断壮大,之前的计数系统面临了很多的问题和挑战。
比如微博用户量和发布的微博量增加迅猛,计数存储数据量级也飞速增长,而MySQL数据库单表的存储量级达到几千万的时候,性能上就会有损耗。所以考虑使用分库分表的方式分散数据量,提升读取计数的性能。
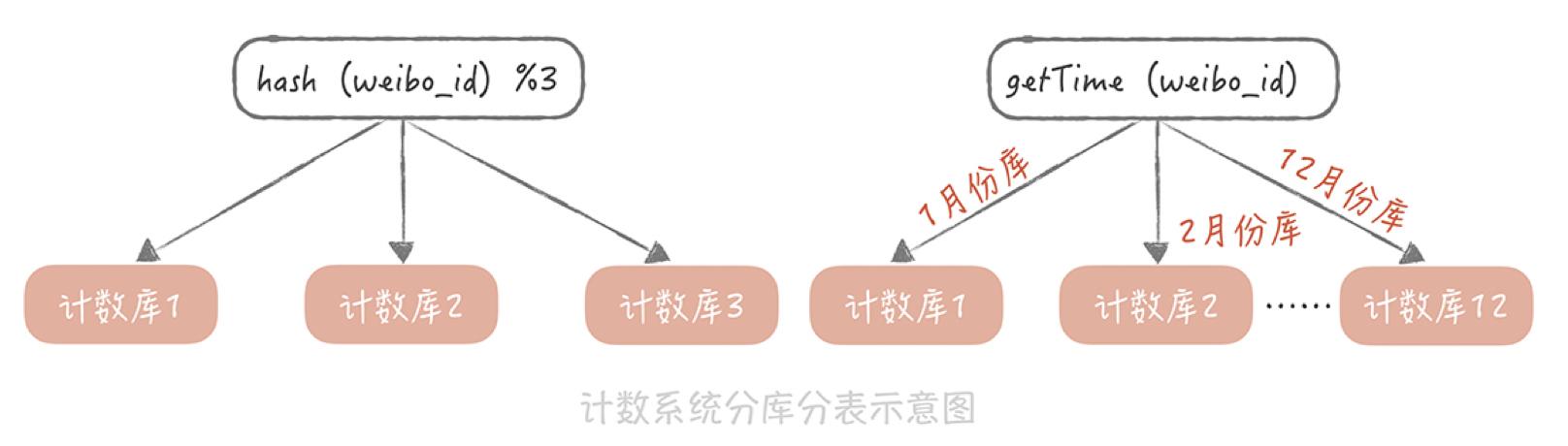
用“weibo_id”作为分区键,在选择分库分表的方式时,考虑了下面两种:
- 一种方式是选择一种哈希算法对weibo_id计算哈希值,然后依据这个哈希值计算出需要存储到哪一个库哪一张表中,具体的方式你可以回顾一下第9讲数据库分库分表的内容;
- 另一种方式是按照weibo_id生成的时间来做分库分表,ID的生成最好带有业务意义的字段,比如生成ID的时间戳。所以在分库分表的时候,可以先依据发号器的算法反解出时间戳,然后按照时间戳来做分库分表,比如,一天一张表或者一个月一张表等等。
与此同时,计数的访问量级也有质的飞越。在微博最初的版本中,首页信息流里面是不展示计数数据的,那么使用MySQL也可以承受当时读取计数的访问量。但是后来在首页信息流中也要展示转发、评论和点赞等计数数据了。而信息流的访问量巨大,仅仅靠数据库已经完全不能承担如此高的并发量了。于是考虑使用Redis来加速读请求,通过部署多个从节点来提升可用性和性能,并且通过Hash的方式对数据做分片,也基本上可以保证计数的读取性能。然而,这种数据库+缓存的方式有一个弊端:无法保证数据的一致性,比如,如果数据库写入成功而缓存更新失败,就会导致数据的不一致,影响计数的准确性。所以完全抛弃了MySQL,全面使用Redis来作为计数的存储组件。

除了考虑计数的读取性能之外,由于热门微博的计数变化频率相当高,也需要考虑如何提升计数的写入性能。比如,每次在转发一条微博的时候,都需要增加这条微博的转发数,那么如果明星发布结婚、离婚的微博,瞬时就可能会产生几万甚至几十万的转发。如果是你的话,要如何降低写压力呢?
可能已经想到用消息队列来削峰填谷了,也就是说,我们在转发微博的时候向消息队列写入一条消息,然后在消息处理程序中给这条微博的转发计数加1。这里需要注意的一点, 可以通过批量处理消息的方式进一步减小Redis的写压力,比如像下面这样连续更改三次转发数(用SQL来表示来方便你理解):
UPDATE t_weibo_count SET repost_count = repost_count + 1 WHERE weibo_id = 1;
UPDATE t_weibo_count SET repost_count = repost_count + 1 WHERE weibo_id = 1;
UPDATE t_weibo_count SET repost_count = repost_count +1 WHERE weibo_id = 1;
这个时候,可以把它们合并成一次更新:
UPDATE t_weibo_count SET repost_count = repost_count + 3 WHERE weibo_id = 1;
如何降低计数系统的存储成本
Redis是使用内存来存储信息,相比于使用磁盘存储数据的MySQL来说,存储的成本不可同日而语,比如一台服务器磁盘可以挂载到2个T,但是内存可能只有128G,这样磁盘的存储空间就是内存的16倍。而Redis基于通用性的考虑,对于内存的使用比较粗放,存在大量的指针以及额外数据结构的开销,如果要存储一个KV类型的计数信息,Key是8字节Long类型的weibo_id,Value是4字节int类型的转发数,存储在Redis中之后会占用超过70个字节的空间,空间的浪费是巨大的。
对原生Redis做一些改造,采用新的数据结构和数据类型来存储计数数据。
- 一是原生的Redis在存储Key时是按照字符串类型来存储的,比如一个8字节的Long类型的数据,需要8(sdshdr数据结构长度)+ 19(8字节数字的长度)+1(’\0’)=28个字节,如果我们使用Long类型来存储就只需要8个字节,会节省20个字节的空间;
- 二是去除了原生Redis中多余的指针,如果要存储一个KV信息就只需要8(weibo_id)+4(转发数)=12个字节,相比之前有很大的改进。
同时使用一个大的数组来存储计数信息,存储的位置是基于weibo_id的哈希值来计算出来的,具体的算法像下面展示的这样:
插入时:
h1 = hash1(weibo_id) //根据微博ID计算Hash
h2 = hash2(weibo_id) //根据微博ID计算另一个Hash,用以解决前一个Hash算法带来的冲突
for s in 0,1000
pos = (h1 + h2*s) % tsize //如果发生冲突,就多算几次Hash2
if(isempty(pos) || isdelete(pos))
t[ pos ] = item //写入数组
查询时:
for s in 0,1000
pos = (h1 + h2*s) % tsize //依照插入数据时候的逻辑,计算出存储在数组中的位置
if(!isempty(pos) && t[pos]==weibo_id)
return t[pos]
return 0
删除时:
insert(FFFF) //插入一个特殊的标
微博的计数有转发数、评论数、浏览数、点赞数等等,如果每一个计数都需要存储weibo_id,那么总共就需要8(weibo_id)*4(4个微博ID)+4(转发数) + 4(评论数) + 4(点赞数) + 4(浏览数)= 48字节。可以把相同微博ID的计数存储在一起,这样就只需要记录一个微博ID,省掉了多余的三个微博ID的存储开销,存储空间就进一步减少了。
微博计数的数据具有明显的热点属性:越是最近的微博越是会被访问到,时间上久远的微博被访问的几率很小。所以为了尽量减少服务器的使用,我们考虑给计数服务增加SSD磁盘,然后将时间上比较久远的数据dump到磁盘上,内存中只保留最近的数据。当我们要读取冷数据的时候,使用单独的I/O线程异步地将冷数据从SSD磁盘中加载到一块儿单独的Cold Cache中。
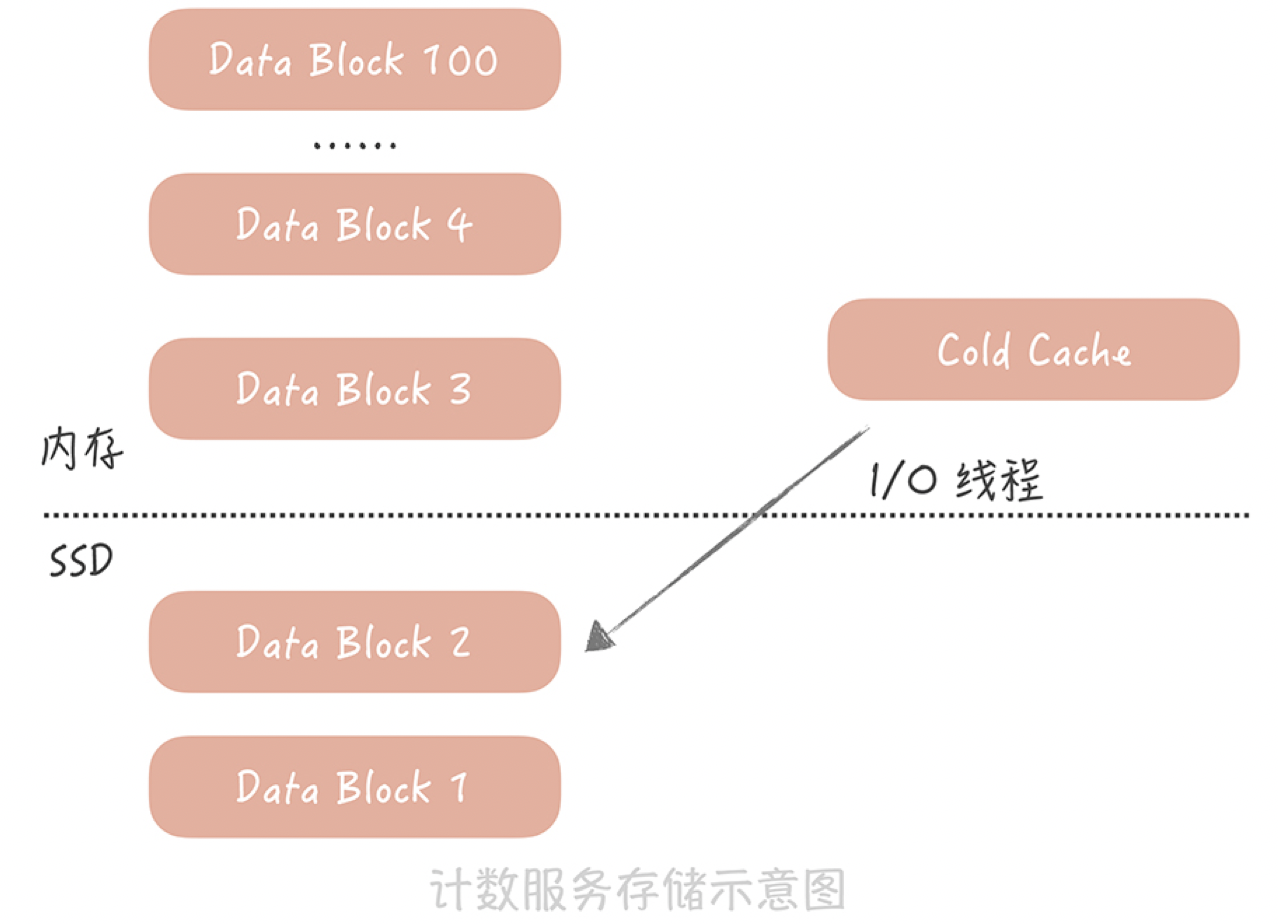
总结:
1、一开始用mysql进行计数,后来加入了主从架构,分库分表架构。
2、因为计数访问量太大了,加入了缓存,但是这个会造成相应的那个缓存和数据库数据不一致,如果要保证一性的话,就需要采用内存队列,对于同一个id的数量只能用单线程进行处理,这个会造成性能问题。
3、后来直接抛弃了mysql,直接用redis cluster来支持计数服务,因为redis通过rdb和aof来支持持久化,可以通过设置保证至少有一台从redis机器同步了数据,从redis来做相应的那个持久化操作达到数据不丢失,因为原生的redis数据结构会占用比较多的字节,这里直接进行改造,让redis的数据结构占用内存加少。
4、但是redis是全内存的,随着量越来越大肯定没法支持了,这里进行改造,引入ssd,支持把冷数据放到ssd中,热数据在内存中,当要访问冷数据时利用一个线程异步把冷数据加载到一个cold cache里面去。这个有很多开源的实现,如Pika,SSDB用ssd来替代内存存储冷数据。
50万QPS下如何设计未读数系统?
未读数也是系统中一个常见的模块,以微博系统为例,可看到有多个未读计数的场景,比如:
- 当有人@你、评论你、给你的博文点赞或者给你发送私信的时候,你会收到相应的未读提醒;
- 在早期的微博版本中有系统通知的功能,也就是系统会给全部用户发送消息,通知用户有新的版本或者有一些好玩的运营活动,如果用户没有看,系统就会给他展示有多少条未读的提醒。
- 在浏览信息流的时候,如果长时间没有刷新页面,那么信息流上方就会提示你在这段时间有多少条信息没有看。
第一个需求,要如何记录未读数呢?
可以在计数系统中增加一块儿内存区域,以用户ID为Key存储多个未读数,当有人@ 你时,增加你的未读@的计数;当有人评论你时,增加你的未读评论的计数,以此类推。当你点击了未读数字进入通知页面,查看@ 你或者评论你的消息时,重置这些未读计数为零。
那么系统通知的未读数是如何实现的呢?能用通用计数系统实现吗?答案是不能的,因为会出现一些问题。
系统通知的未读数要如何设计
假如你的系统中只有A、B、C三个用户,那么你可以在通用计数系统中增加一块儿内存区域,并且以用户ID为Key来存储这三个用户的未读通知数据,当系统发送一个新的通知时,会循环给每一个用户的未读数加1,这个处理逻辑的伪代码就像下面这样:
List<Long> userIds = getAllUserIds();
for(Long id : userIds) {
incrUnreadCount(id);
}
似乎简单可行,但随着系统中的用户越来越多,这个方案存在两个致命的问题。
获取全量用户就是一个比较耗时的操作,相当于对用户库做一次全表的扫描,这不仅会对数据库造成很大的压力,而且查询全量用户数据的响应时间是很长的,对于在线业务来说是难以接受的。如果你的用户库已经做了分库分表,那么就要扫描所有的库表,响应时间就更长了。不过有一个折中的方法, 那就是在发送系统通知之前,先从线下的数据仓库中获取全量的用户ID,并且存储在一个本地的文件中,然后再轮询所有的用户ID,给这些用户增加未读计数。
这似乎是一个可行的技术方案,然而它给所有人增加未读计数,会消耗非常长的时间。你计算一下,假如你的系统中有一个亿的用户,给一个用户增加未读数需要消耗1ms,那么给所有人都增加未读计数就需要100000000 * 1 /1000 = 100000秒,也就是超过一天的时间;即使你启动100个线程并发的设置,也需要十几分钟的时间才能完成,而用户很难接受这么长的延迟时间。
另外,使用这种方式需要给系统中的每一个用户都记一个未读数的值,而在系统中,活跃用户只是很少的一部分,大部分的用户是不活跃的,甚至从来没有打开过系统通知,为这些用户记录未读数显然是一种浪费。
通过上面的内容,你可以知道为什么我们不能用通用计数系统实现系统通知未读数了吧?那正确的做法是什么呢?
要知道,系统通知实际上是存储在一个大的列表中的,这个列表对所有用户共享,也就是所有人看到的都是同一份系统通知的数据。不过不同的人最近看到的消息不同,所以每个人会有不同的未读数。因此,你可以记录一下在这个列表中每个人看过最后一条消息的ID,然后统计这个ID之后有多少条消息,这就是未读数了。
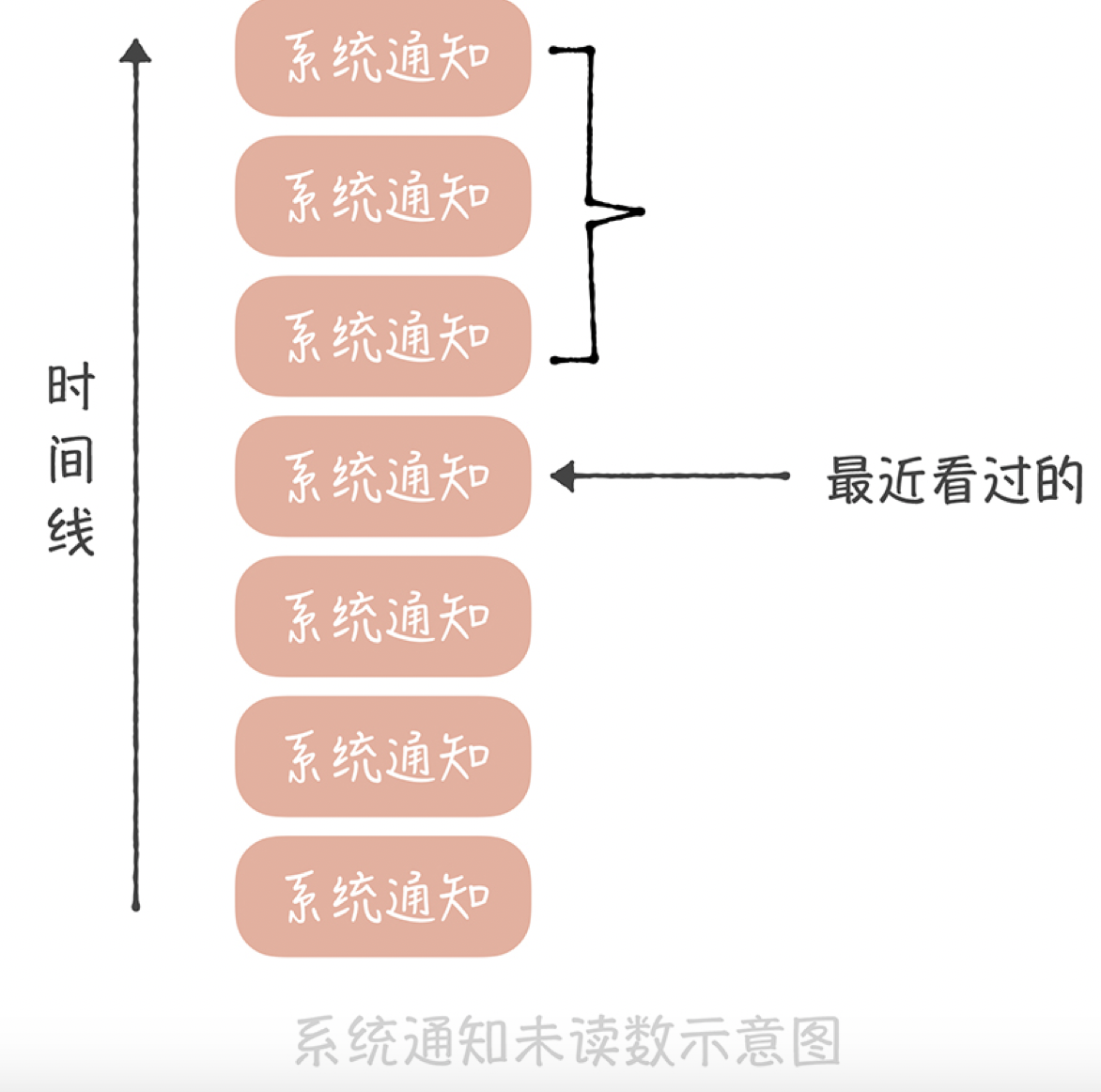
这个方案在实现时有这样几个关键点:
- 用户访问系统通知页面需要设置未读数为0,我们需要将用户最近看过的通知ID设置为最新的一条系统通知ID;
- 如果最近看过的通知ID为空,则认为是一个新的用户,返回未读数为0;
- 对于非活跃用户,比如最近一个月都没有登录和使用过系统的用户,可以把用户最近看过的通知ID清空,节省内存空间。
这是一种比较通用的方案,即节省内存,又能尽量减少获取未读数的延迟。 这个方案适用的另一个业务场景是全量用户打点的场景,比如像下面这张微博截图中的红点。
这个红点和系统通知类似,也是一种通知全量用户的手段,如果逐个通知用户,延迟也是无法接受的。因此可以采用和系统通知类似的方案。
首先为每一个用户存储一个时间戳,代表最近点过这个红点的时间,用户点了红点,就把这个时间戳设置为当前时间;然后也记录一个全局的时间戳,这个时间戳标识最新的一次打点时间,如果你在后台操作给全体用户打点,就更新这个时间戳为当前时间。而在判断是否需要展示红点时,只需要判断用户的时间戳和全局时间戳的大小,如果用户时间戳小于全局时间戳,代表在用户最后一次点击红点之后又有新的红点推送,那么就要展示红点,反之,就不展示红点了
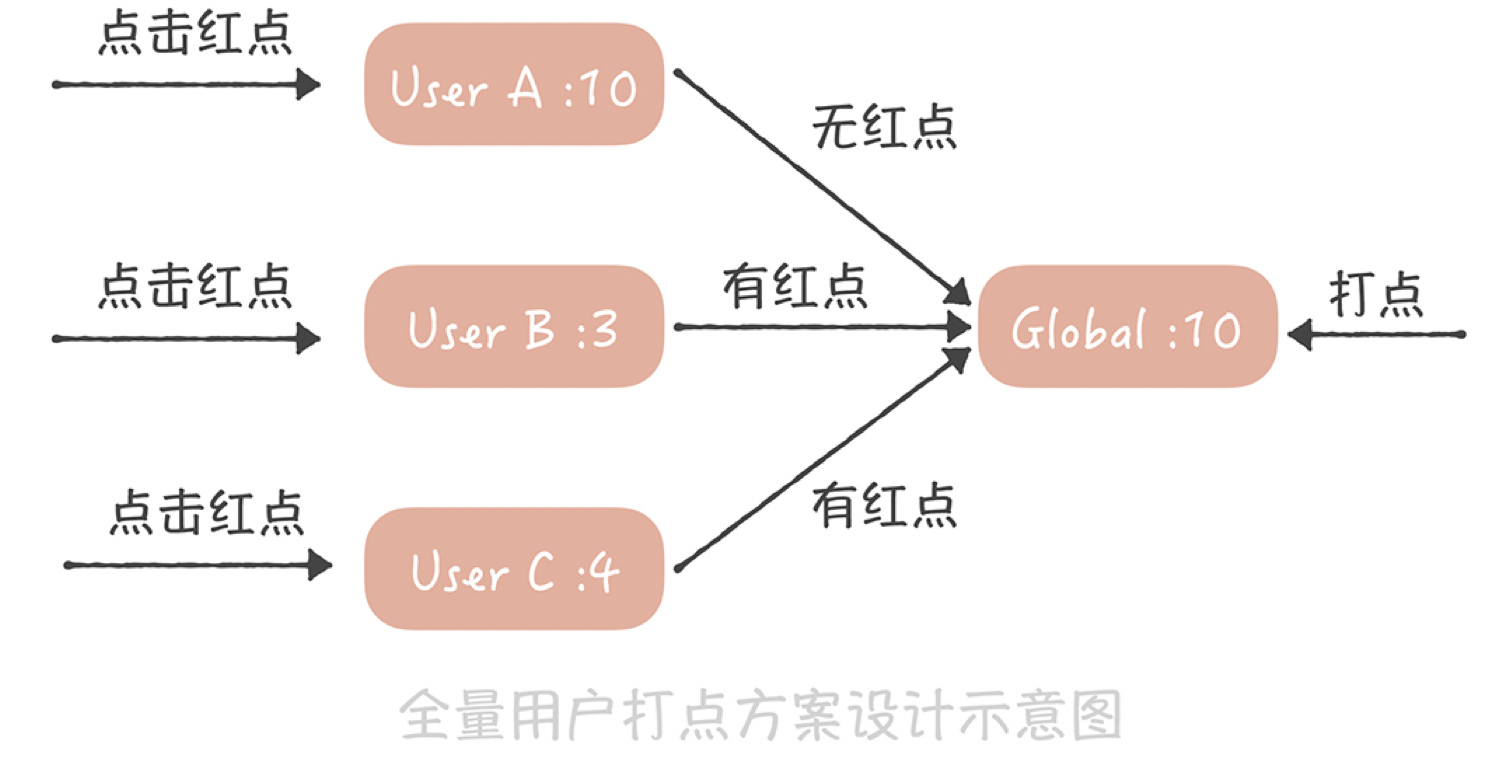
这两个场景的共性是全部用户共享一份有限的存储数据,每个人只记录自己在这份存储中的偏移量,就可以得到未读数了。
你可以看到,系统消息未读的实现方案不是很复杂,它通过设计避免了操作全量数据未读数,如果你的系统中有这种打红点的需求,那我建议你可以结合实际工作灵活使用上述方案。
最后一个需求关注的是微博信息流的未读数,在现在的社交系统中,关注关系已经成为标配的功能,而基于关注关系的信息流也是一种非常重要的信息聚合方式,因此,如何设计信息流的未读数系统就成了你必须面对的一个问题。
如何为信息流的未读数设计方案
信息流的未读数之所以复杂主要有这样几点原因。
- 首先,微博的信息流是基于关注关系的,未读数也是基于关注关系的,就是说,你关注的人发布了新的微博,那么你作为粉丝未读数就要增加1。如果微博用户都是像我这样只有几百粉丝的“小透明”就简单了,你发微博的时候系统给你粉丝的未读数增加1不是什么难事儿。但是对于一些动辄几千万甚至上亿粉丝的微博大V就麻烦了,增加未读数可能需要几个小时。假设你是杨幂的粉丝,想了解她实时发布的博文,那么如果当她发布博文几个小时之后,你才收到提醒,这显然是不能接受的。所以未读数的延迟是你在涉及方案时首先要考虑的内容。
- 其次,信息流未读数请求量极大、并发极高,这是因为接口是客户端轮询请求的,不是用户触发的。也就是说,用户即使打开微博客户端什么都不做,这个接口也会被请求到。在几年前,请求未读数接口的量级就已经接近每秒50万次,这几年随着微博量级的增长,请求量也变得更高。而作为微博的非核心接口,我们不太可能使用大量的机器来抗未读数请求,因此,如何使用有限的资源来支撑如此高的流量是这个方案的难点。
- 最后,它不像系统通知那样有共享的存储,因为每个人关注的人不同,信息流的列表也就不同,所以也就没办法采用系统通知未读数的方案。
那要如何设计能够承接每秒几十万次请求的信息流未读数系统呢?你可以这样做:
- 首先,在通用计数器中记录每一个用户发布的博文数;
- 然后在Redis或者Memcached中记录一个人所有关注人的博文数快照,当用户点击未读消息重置未读数为0时,将他关注所有人的博文数刷新到快照中;
- 这样,他关注所有人的博文总数减去快照中的博文总数就是他的信息流未读数。
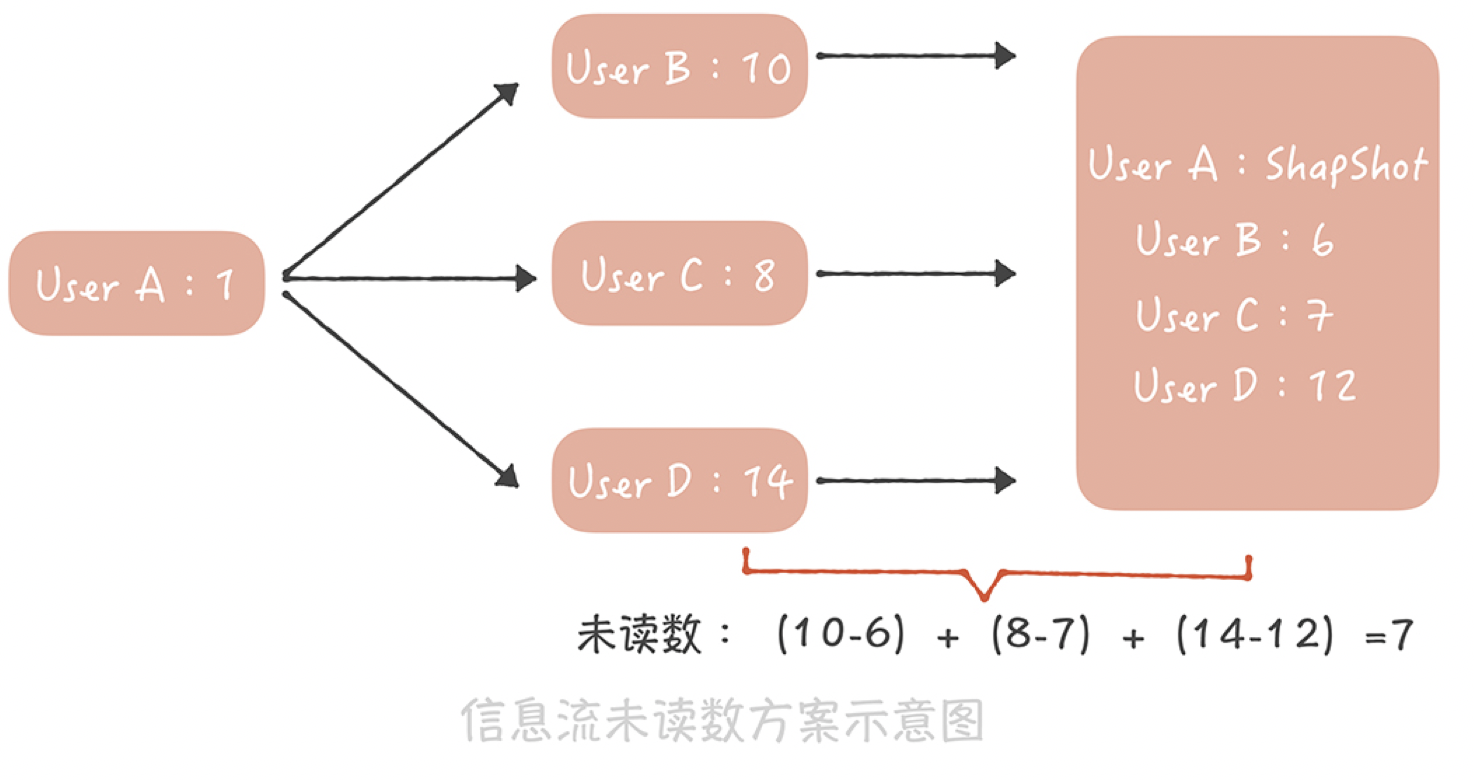
假如用户A,像上图这样关注了用户B、C、D,其中B发布的博文数是10,C发布的博文数是8,D发布的博文数是14,而在用户A最近一次查看未读消息时,记录在快照中的这三个用户的博文数分别是6、7、12,因此用户A的未读数就是(10-6)+(8-7)+(14-12)=7。
这个方案设计简单,并且是全内存操作,性能足够好,能够支撑比较高的并发,事实上微博团队仅仅用16台普通的服务器就支撑了每秒接近50万次的请求,这就足以证明这个方案的性能有多出色,因此,它完全能够满足信息流未读数的需求。
当然了这个方案也有一些缺陷,比如说快照中需要存储关注关系,如果关注关系变更的时候更新不及时,那么就会造成未读数不准确;快照采用的是全缓存存储,如果缓存满了就会剔除一些数据,那么被剔除用户的未读数就变为0了。但是好在用户对于未读数的准确度要求不高(未读10条还是11条,其实用户有时候看不出来),因此,这些缺陷也是可以接受的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号