如何一天做出新闻搜索引擎(1)——新闻的搜集与数据库的建立
@
写在前面
大家好,这一章主要来介绍如何选取爬取的页面,如何确定爬取内容的方法和怎样建立数据库。
如需查看完整源代码,请移步我的github页面,本文所讲内容在Refresh.py文件里。
其他章节请访问我的这篇博客。
1. 爬取什么
我们选取页面的原则是页面要尽可能地“整齐”。什么是“整齐”呢,请看下面两图:
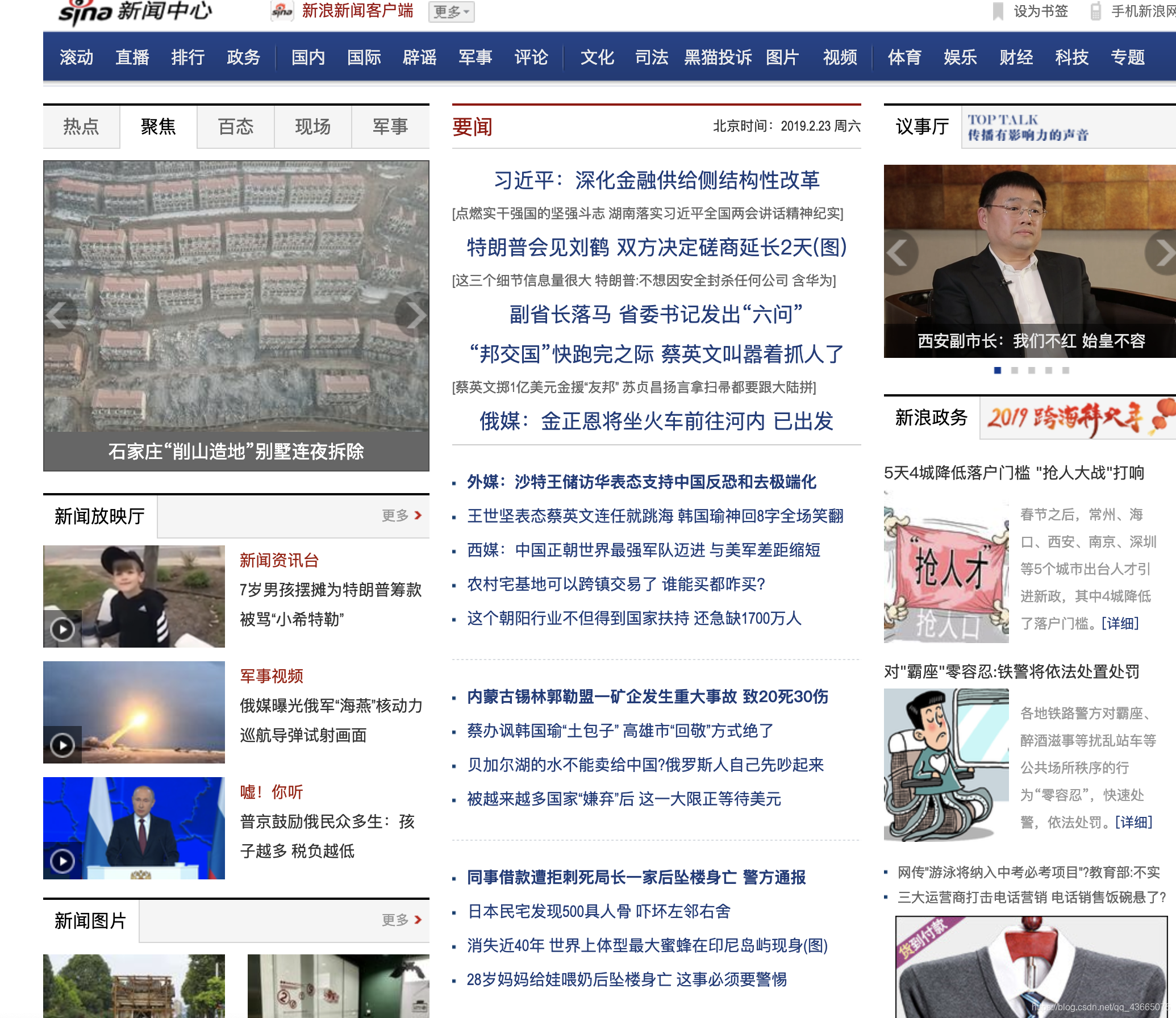
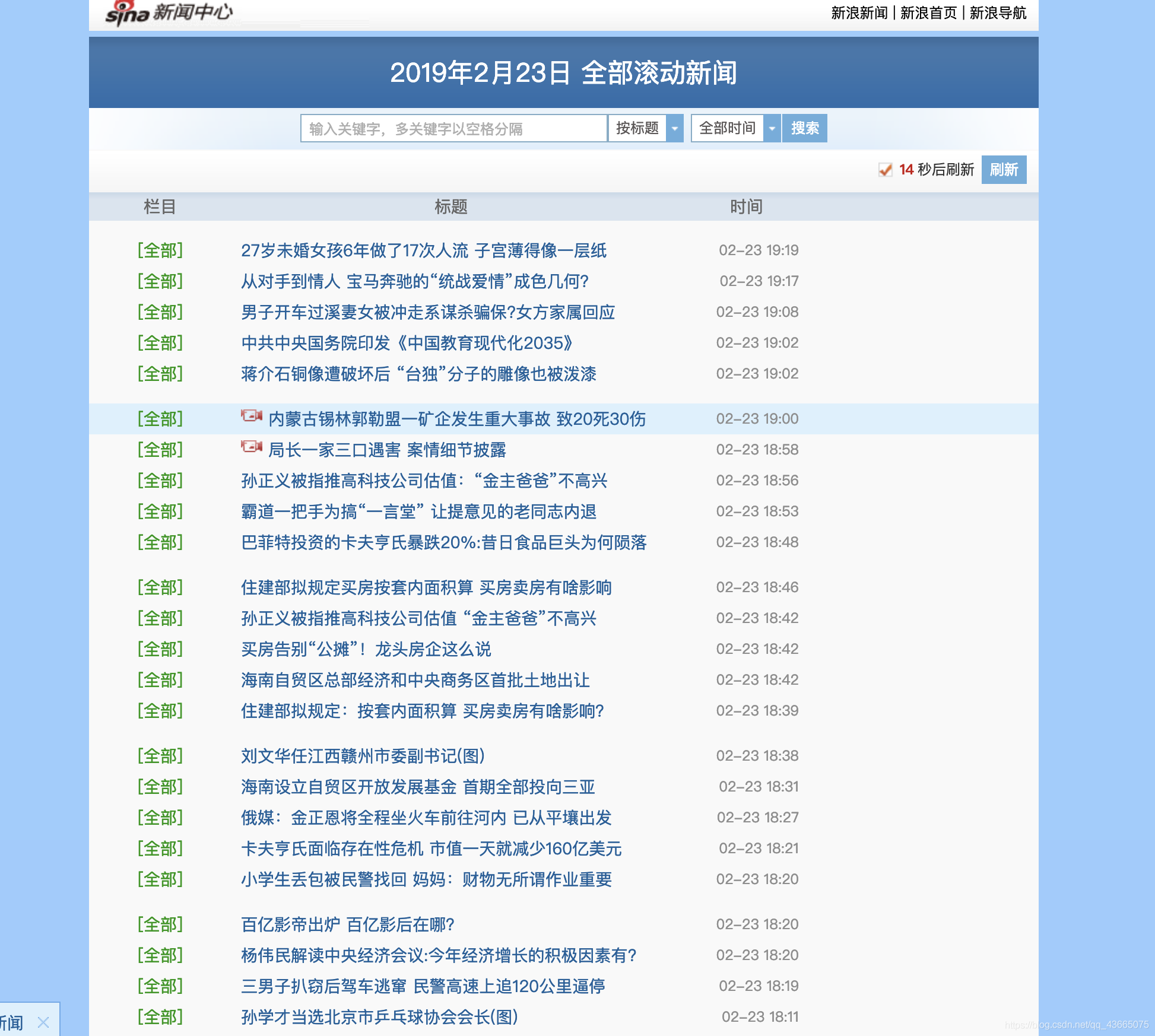
其中图一是新浪新闻的首页,图二是新浪新闻的滚动页面。显然从视觉直观来说,图二比图一更为地整齐。
为什么我们要选择比较整齐地页面进行爬取呢?原因在于这种页面的HTML代码也比较地有规律,爬网页的时候也更为地省心。比如图二的每一则新闻的代码都是这样的:

所以我们只要在爬取的过程中,找到每个c_tit类下的href就可以找到每条新闻对应的网页地址了。
2. 怎么爬
(大家可以参考网易云上的免费视频课程,当时我就是就着这个视频学的,虽然视频中的爬取方法因为新浪新闻网页架构的更改失效了,但可以从中学到网络爬虫的基本方法)
2.1 分析网页的HTML源码,找到规律
2.1.1 分析滚动页面
我们使用google的chrome浏览器进行分析。在chrome浏览器中搜索“新浪新闻”,点击进入新浪新闻主页。也就是这样:
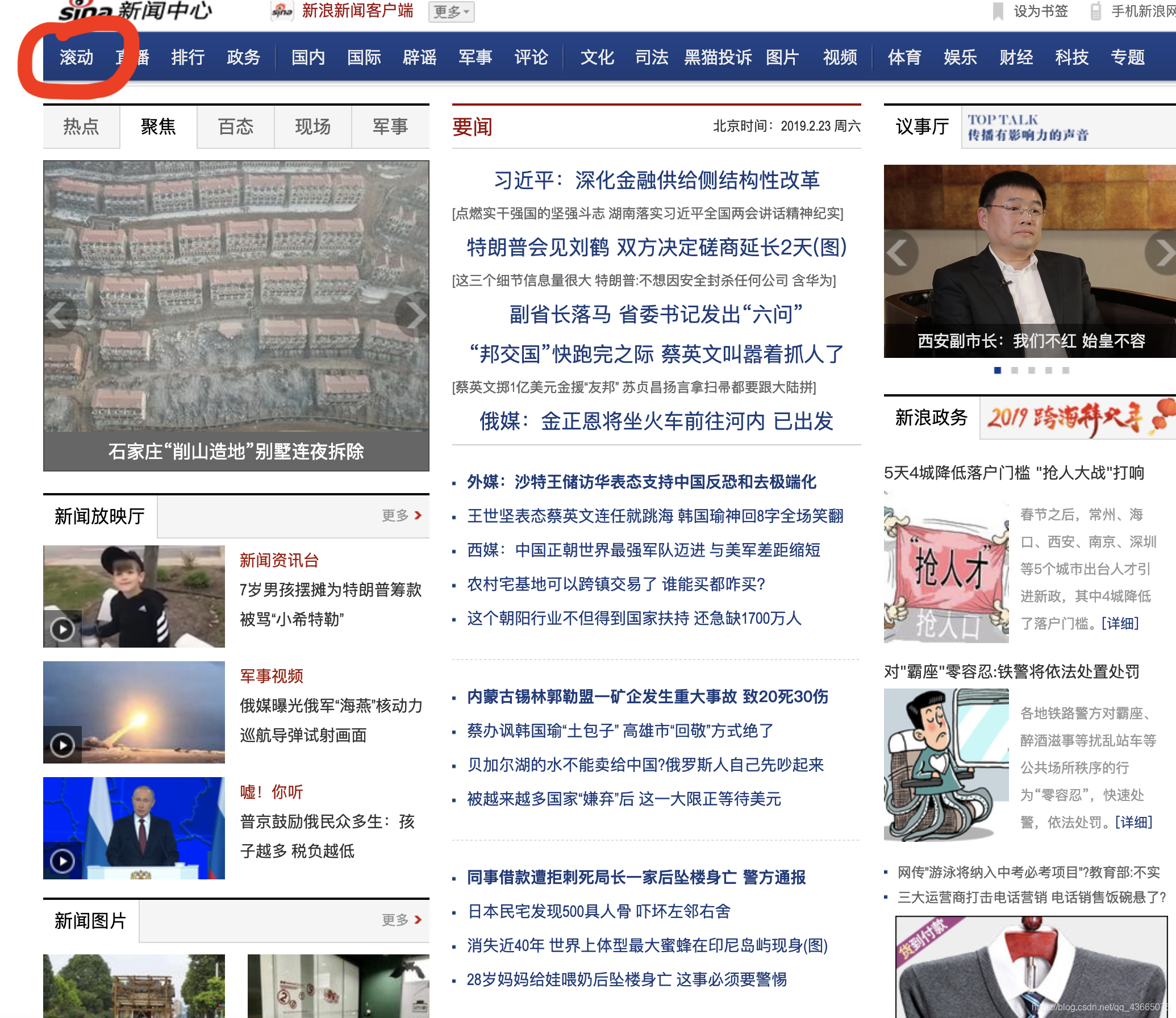
然后点击左上角的“滚动”(图中用红圈标出的地方),进入滚动页面。
之后我们进入开发者模式。如下图所示,点击“开发者工具”:
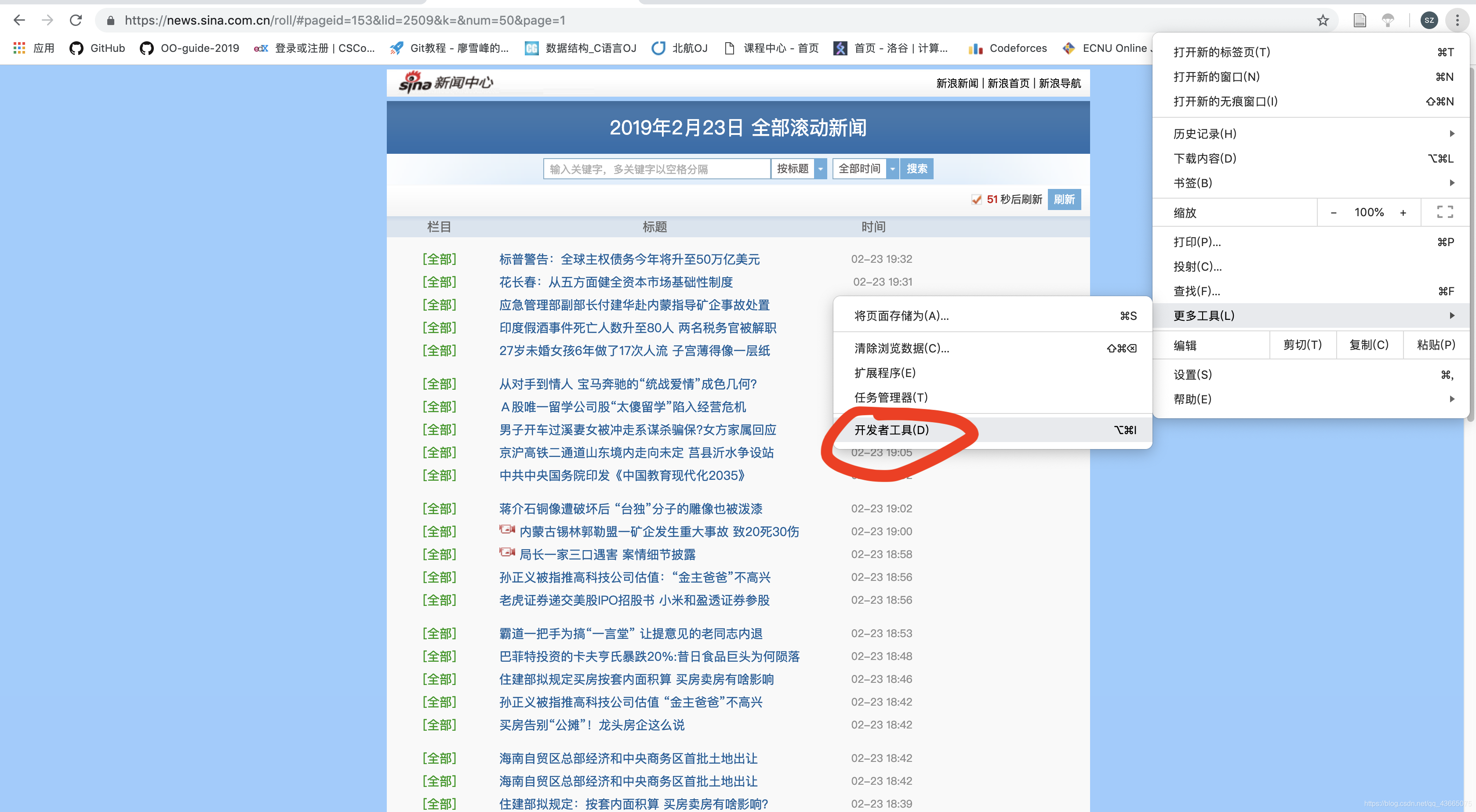
然后按下图的步骤点击:
(由于上一条新闻《27岁未婚女孩...》太过惊悚,我们选一个温和点的)
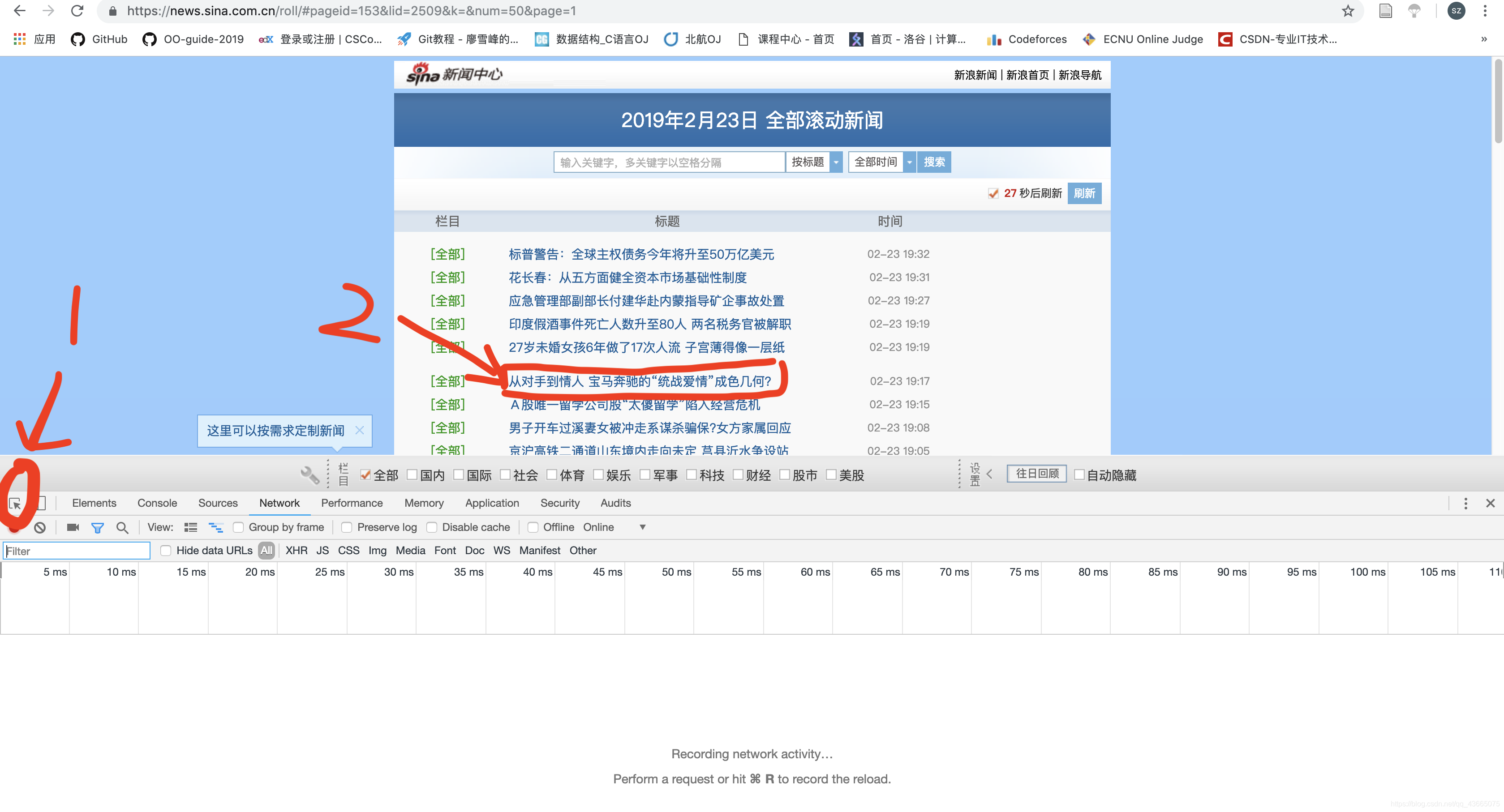
然后就出现了下图:
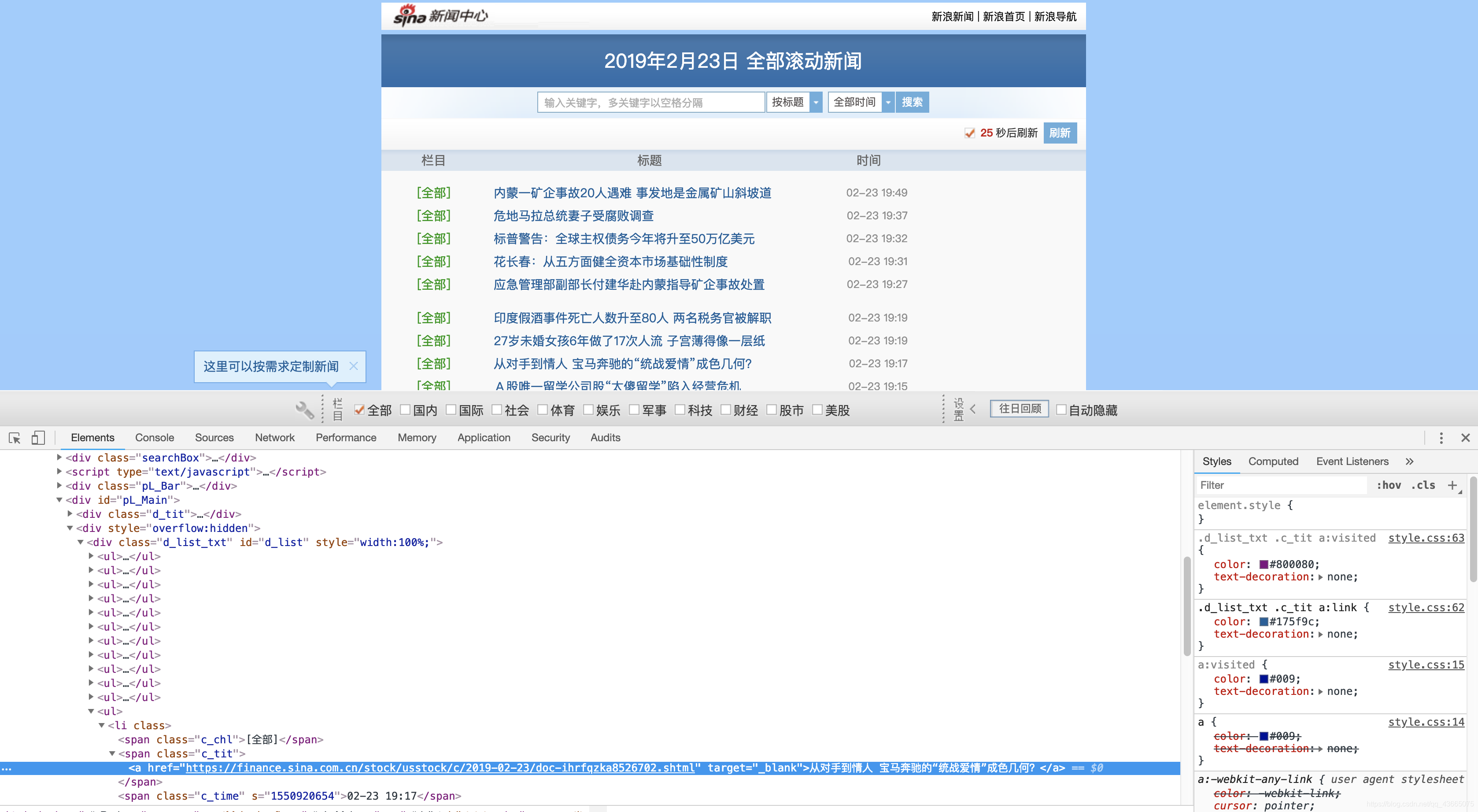
图中被选中的代码就是我们想从这个页面上提取的信息(即每条新闻的网址)。
只要知道每条新闻的网址,然后我们再访问每条新闻的页面,提取出关于该新闻的信息即可。
所以接下来我们进入这条新闻的页面,找出新闻页面的HTML代码规律。
2.1.2 分析新闻页面
我们要找的信息:新闻的标题、日期、正文和关键字。
按照之前的套路,我们打开开发者工具,并找到正文的位置:
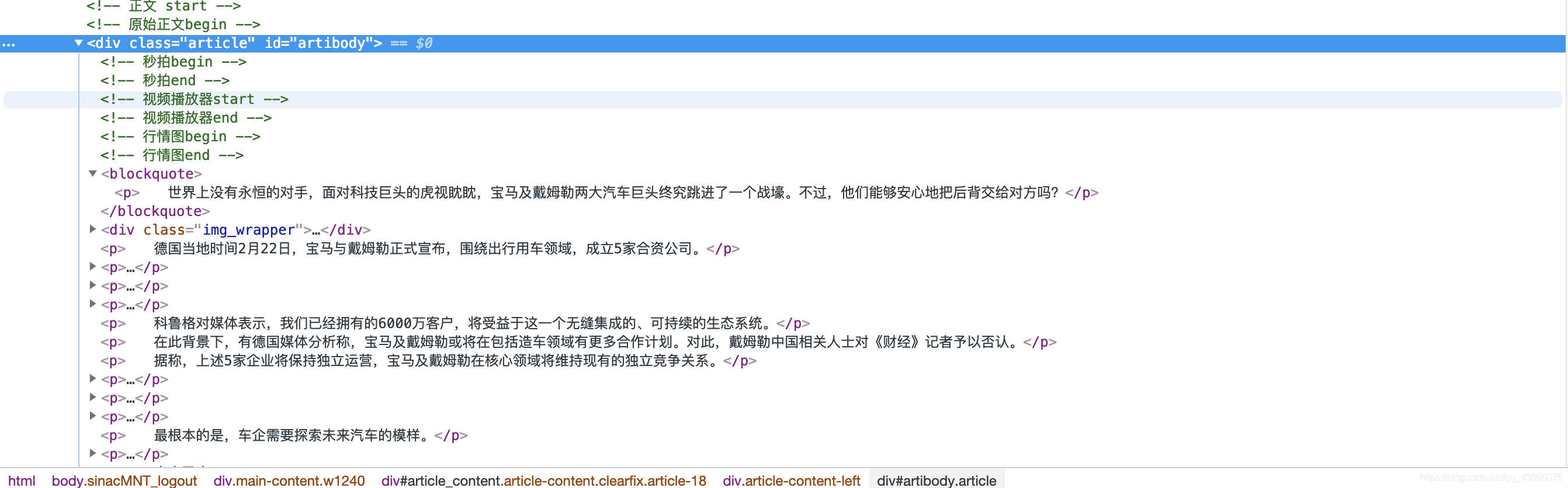
标题、日期以及关键字的寻找方法请看下文。
明确了这些,接下来我们就可以开始动手爬新闻了。😄
2.2 分析完毕,开始动手写代码爬网页
2.2.1 爬滚动页面
经过一番寻找与尝试(具体尝试的步骤请在上文所列出的视频教程中查看,说实话,当初尝试了挺久才碰巧找到的),我发现在Source中有一个feed啥的比较关键:
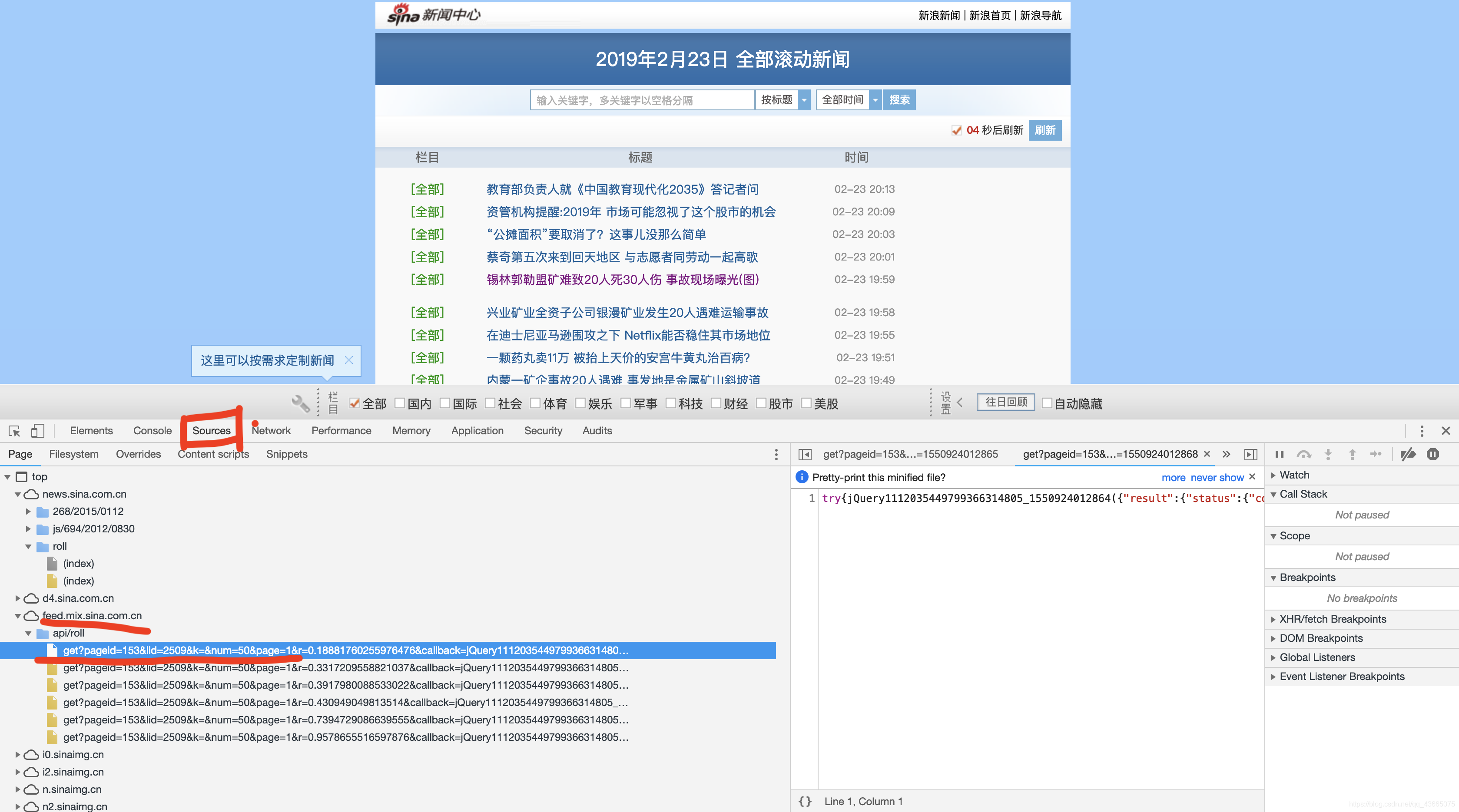
请注意红下划线的地方。我们发现地址可以拼接成:
https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=%d
的形式。其中%d可以代入数字,表示第几页的滚动页面。
后面的r=0.02768994656458923&callback=jQuery1112035449799366314805_1550924012864&_=1550924012872
与页面的实时刷新有关,我们不去管他。
然后我们编写代码去访问这个地址:(其中maxPage是我设定的滚动页面的最大页码)
for page in range(1,maxPage+1):
url = 'https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=%d'%(page)
try:
res = requests.get(url)
except:
continue
注意try -- except,因为可能有些网页是无法访问的,为了提高容错性,我们加一个try--except,如果访问错误则忽略,直接访问下一页滚动页面。
如果成功访问,我们得到的res就是一个response对象,然后对这个response对象进行处理。
把它丢进BeautifulSoup中进行解析:(BeautifulSoup是一个从HTML或XML文件中提取出数据的Python库,简单来说,他可以将文件中的标签整理成树状结构,方便查阅和应用。不了解的读者请自行百度或google)
for page in range(1,maxPage+1):
url = 'https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=%d'%(page)
#url = 'https://news.sina.com.cn/roll/#pageid=153&lid=2509&k=&num=50&page=%d'%(page)
try:
res = requests.get(url)
except:
continue
pageInfo = []
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
jd = json.loads(soup.text)
我们看jd是一个什么东东:
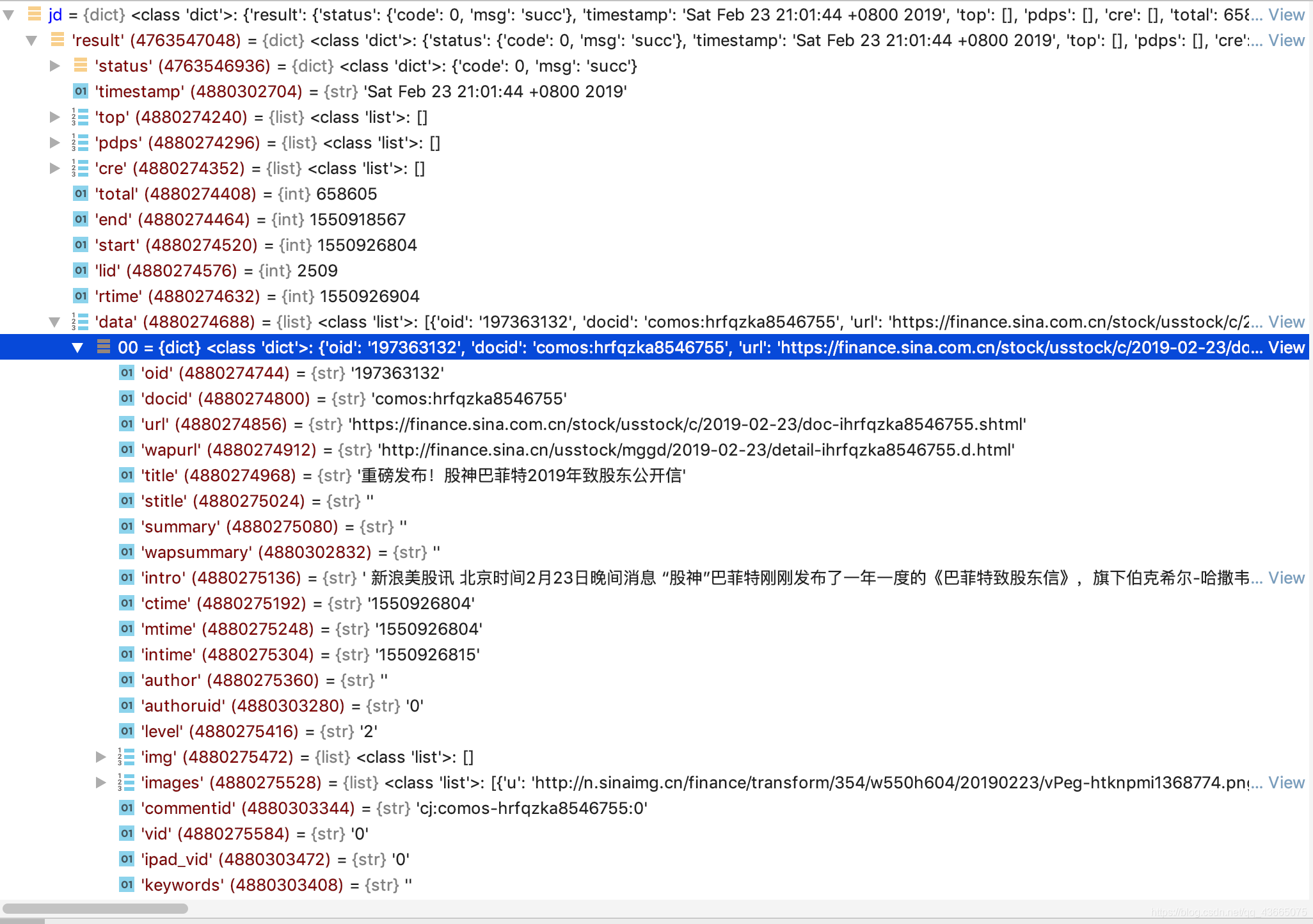
原来jd是一个字典,jd['result']['data']中的每个元素都是滚动页面中的一则新闻,里面中有很多我们要找的信息:url, title, keywords等。
for page in range(1,maxPage+1):
url = 'https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=%d'%(page)
try:
res = requests.get(url)
except:
continue
pageInfo = []
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
jd = json.loads(soup.text)
for info in jd['result']['data']:
url = info['url']
title = info['title']
keywords = info['keywords']
2.2.2 爬新闻页面
结束了吗?好像还少了点啥...对,少了时间和最重要的正文。这就要我们从每则新闻的新闻页面中爬取。
在2.2.1中我们已经得到了所有新闻的网页地址(url),我们进入这个编写一个名为getUrlInfo的函数,提取网页中的各类信息:
def getUrlInfo(url):
try:
res = requests.get(url)
res.encoding = 'utf-8'
#print(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
article = soup.select('.article p')[:-1]
article = '\n\t'.join([p.text.strip() for p in article]) #将文章中的每一段用\n\t隔开
date = soup.select('.date')[0].text
date = datetime.strptime(date, '%Y年%m月%d日 %H:%M')
result = {}
result['date'] = date
result['article'] = article
except:
return #如果出错,则返回None
return result
然后将date, article 等信息与上文的url, title, keywords合并,并将每则新闻的这些信息提取出来保存在news字典中,再将每页滚动页面中所有新闻对应的字典插入到pageInfo的数组中,最后将pageInfo中的信息插入到allPages数组中:
def dealPages(maxPage):
global allPages
allPages = []
for page in range(1,maxPage+1):
url = 'https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=%d'%(page)
try:
res = requests.get(url)
except:
continue
pageInfo = []
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
jd = json.loads(soup.text)
for info in jd['result']['data']:
url = info['url']
title = info['title']
keywords = info['keywords']
date_article = getUrlInfo(url)
if date_article == None:
continue
date = date_article['date']
date = date.strftime('%Y-%m-%d %H:%M')
article = date_article['article']
news = {}
news['url'] = url
news['title'] = title
news['keywords'] = keywords
news['date'] = date
news['article'] = article
pageInfo.append(news)
allPages.extend(pageInfo)
即
news --- 每条新闻的信息
pageInfo --- 每页滚动页面的信息
allPages --- 所有滚动页面的信息
这样,dealPages和getUrlInfo两个函数双剑合璧,页码为1-maxPage的滚动页面的信息就被我提取出来了。
3. 爬完干什么
3.1 分析新闻内容,提取出有关搜索的关键信息
首先我们要去掉新闻中与搜索无关的词。这里就要引入“停用词”的概念。
比如在一句话中:“小明和小红去北京天安门玩了”,“小红”、“小明”、“北京”、“天安门”都是对于搜索有用的信息,而“和”、“了”这些词就和搜索无关了。这些与搜索无关的词就叫“停用词”。网上有停用词的汇总,本文用的是这一个停用词表。
为了提高搜索速度,我们只针对标题和关键词进行搜索,而关键词中是没有停用词的,所以只需去掉标题中的停用词。
首先我们用jieba对标题进行分词,然后去除停用词以及标点。将剩下的词连同关键词一起作为搜索的依据。统计每个词出现的频率,计入名为Terms的字典中,再将每则新闻Terms字典汇总入Termdict的list中:
def build_TermDict():
global TermDict, N, avg_l
global allPages
TermDict.clear()
avg_l = 0 #文档平均长度,即平均每个新闻中有多少个有效词
N = len(allPages)
cloudTerm = [] #用于云图构建
for doc_id in range(0,N):
doc = allPages[doc_id]
#toCut = doc['title']*30 + doc['keywords']*15+doc['article'] #设定不同的权重
toCut = doc['title']+doc['keywords']
terms = jieba.cut_for_search(toCut)
ld = 0 #文档长度,即文章中有效词的个数
#去除标点和停用词
Terms = {}
for p in terms:
p = p.strip()
if len(p)>0 and p not in stop_words and not p.isdigit():
if p in Terms:
Terms[p] += 1
else:
Terms[p] = 1
cloudTerm.append(p)
ld += 1
avg_l += 1
#将Terms中元素加入TermDict
for p in Terms:
if p in TermDict:
TermDict[p][0] += Terms[p]
else:
TermDict[p] = [1,[]]
TermDict[p][1].append('%d\t%s\t%d\t%d'%(doc_id, doc['date'], Terms[p],ld ))
avg_l /= N
#生成云图
cloudText = ','.join(cloudTerm)
wc = WordCloud(
background_color="white", #背景颜色
max_words=200, #显示最大词数
font_path="simhei.ttf", #使用字体
min_font_size=15,
max_font_size=50,
width=400 #图幅宽度
)
wc.generate(cloudText)
wc.to_file("wordcloud.gif")
#将TermDict中文档信息合并成一个字符串,用\n隔开
for i in TermDict:
TermDict[i][1] = '\n'.join(TermDict[i][1])
ok✌️
3.2 保存入数据库
信息提取完...当然是把数据存到数据库中啊😂
数据库的好处在于:每次搜索时不需要重新提取网页中的信息,直接在数据库中查找就ok了。想象一下,如果每次搜索都要等待几分钟让程序爬取网页的信息,这酸爽,不敢相信啊。
在这里我们用sqlite3存储数据,代码如下(如不熟悉sqlite3请自行百度,网上很多讲解的😄):
def WriteInDataBase():
#将TermDict写入数据库
global TermDict
df = pandas.DataFrame(TermDict).T
db = sqlite3.connect('news.sqlite')
df.to_sql('TermDict',con = db,if_exists='replace') #如果表存在就将表替代
db.close()
#将N 和 avg_l写入txt文件中
paraF = open('parameter.txt','w')
paraF.write('%d\t%d'%(N,avg_l))
paraF.close()
#将allPages写入数据库
df = pandas.DataFrame(allPages)
db = sqlite3.connect('news.sqlite')
df.T.to_sql('allPages',con = db,if_exists='replace') #如果表存在就将表替代
db.close()
4. 刷新一下,马上回来
到此为止,搜索新闻、处理新闻信息以及建立数据库的工作就完成了,我们最后用一个refresh函数来将上面写的函数串在一起,完成刷新的工作:
def refresh():
global maxPage
global allPages, TermDict, stop_words, N, avg_l
#处理滚动页面
allPages = []
dealPages(maxPage)
#构建列表stop_words,包含停用词和标点
stop_words = []
build_StopWords()
#构建TermDict
TermDict={}
N = 0
avg_l = 0
build_TermDict()
#将TermDict转化为pandas中的DataFrame,再写入数据库sqlite
WriteInDataBase()
小小地测试一下,嗯,不错:
if __name__ == '__main__':
refresh()
这样,这一章的任务——新闻的搜集与数据库的建立,就完成了😄
写在后面
如需查看完整源代码,请移步我的github页面,本文所讲内容在Refresh.py文件里。
如有不当,欢迎大神指出!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号