DFS序
转自:https://blog.csdn.net/qq_36368339/article/details/79236467
树通常有多种类型,但其终归是非线性结构,操作起来有时总是那么费时。
例如:POJ 3321
给你一棵树,树上每个节点都有1个苹果,然后你对一个节点操作,如果有苹果就拿走,没苹果就放上,然后询问你以x为根的子树上共有多少个苹果。
每次更新都要遍历一遍,查询也要遍历一遍,时间复杂度很高。如果能转化成线性结构就可以了,就可以用线段树或者树状数组等其他方法对树高效更新和查询。
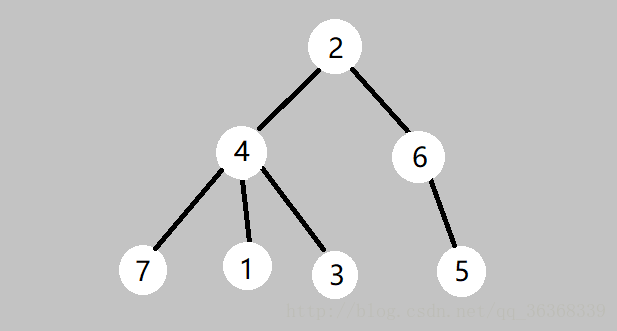
dfs有一个很好的性质:一棵子树所在的位置处于一个连续区间中。
DFS序就是将树形结构转化为线性结构,用dfs遍历一遍这棵树,进入到x节点有一个in时间戳,递归退出时有一个out
时间戳,x节点的两个时间戳之间遍历到的点,就是根为x的子树的所有节点,他们的dfs进入时间戳是递增的。同时两个时间戳构成了一个区间,x节点在这段区间的最左端,这个区间就是一棵根节点为x的子树,对于区间的操作就是其他维护方式的应用了。
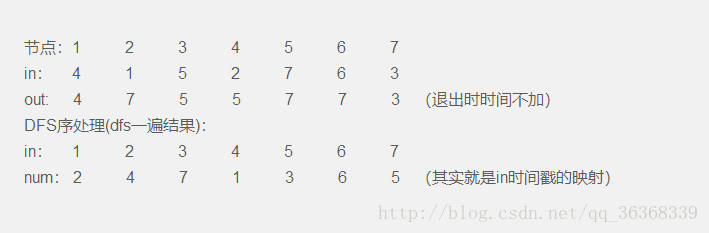
1 int time = 0; 2 inline void dfs(int x, int fa) { 3 in[x] = ++time; //进入的时间戳 4 num[time] = x; //生成新的线性结构 5 for(int i = 0; i < G[x].size(); i++) { 6 int cnt = G[x][i]; 7 if(cnt == fa) continue; 8 dfs(cnt, x); 9 } 10 out[x] = time; //出去的时间戳 11 }
in[x]表示映射的DFS预处理出的线性结构,也就是说x是原始节点,in[x]是x节点的新位置,num[t]表示第t个节点的编号,num[in[x]]表示的还是x。num是新序列,in表示是新序列的下标,in[x]~out[x]是x为根结点的子树,划分为一个区间。
ps:可以在纸上模拟画画.
回到最初问题:
单点更新,区间查询,将这个树的DFS序预处理出来,线段树维护区间和。用num[L]建树(建树时小心,产生了新序列),in[x]单点更新,in[x]~out[x]区间查询,问题即可解决。
多说一句:上图的dfs序是:2471365; 欧拉序是:24741434265

 浙公网安备 33010602011771号
浙公网安备 33010602011771号