
中国大学排名
我爬取了中国大学排名
代码如下(代码过长一张图截不下)
import requests
from bs4 import BeautifulSoup
import bs4
import xlwt
def getHTMLText(url):####用request库爬取页面源代码,储存在 r.text里
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return""
from bs4 import BeautifulSoup
import bs4
import xlwt
def getHTMLText(url):####用request库爬取页面源代码,储存在 r.text里
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return""
def fillUnivList(ulist,html):####用bs4模块对爬取到的源代码进行分析,find到相应的数据
soup=BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
ulist.append([tds[0].string,tds[1].string,tds[2].string,tds[3].string])
#####接下来对数据进行填充排版
def printUnivList(ulist,num):
workbook = xlwt.Workbook(encoding = 'utf-8')
# 创建一个worksheet
worksheet = workbook.add_sheet('My Worksheet')
worksheet.col(1).width = 5000
list1=[]
list1.extend(['排名','学校名称','省市','总分'])
l2=[]
for i in range(4):
worksheet.write(0,i, label = list1[i])
for i in range(num):
u=ulist[i]
l2.extend([u[0],u[1],u[2],u[3]])
for i in range(1,num+1):
for p in range(4):
worksheet.write(i,p, label = l2[(i-1)*4+p])
workbook.save('王思然的作业.xls')
def main():
uinfo=[]
url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html'
html=getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,10) ######前十名
main()
soup=BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
ulist.append([tds[0].string,tds[1].string,tds[2].string,tds[3].string])
#####接下来对数据进行填充排版
def printUnivList(ulist,num):
workbook = xlwt.Workbook(encoding = 'utf-8')
# 创建一个worksheet
worksheet = workbook.add_sheet('My Worksheet')
worksheet.col(1).width = 5000
list1=[]
list1.extend(['排名','学校名称','省市','总分'])
l2=[]
for i in range(4):
worksheet.write(0,i, label = list1[i])
for i in range(num):
u=ulist[i]
l2.extend([u[0],u[1],u[2],u[3]])
for i in range(1,num+1):
for p in range(4):
worksheet.write(i,p, label = l2[(i-1)*4+p])
workbook.save('王思然的作业.xls')
def main():
uinfo=[]
url='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2018.html'
html=getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,10) ######前十名
main()
生成了表格![]()
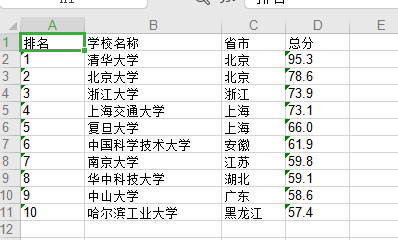
开始用python生成图像
代码如下
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
df=pd.read_excel('王思然的作业.xls')
x=df['学校名称']
y=df['总分']
plt.bar(x,y,label='分数')
plt.xlabel('学校')
plt.ylabel('分数')
plt.legend()
plt.show()
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
df=pd.read_excel('王思然的作业.xls')
x=df['学校名称']
y=df['总分']
plt.bar(x,y,label='分数')
plt.xlabel('学校')
plt.ylabel('分数')
plt.legend()
plt.show()
结果图![]()
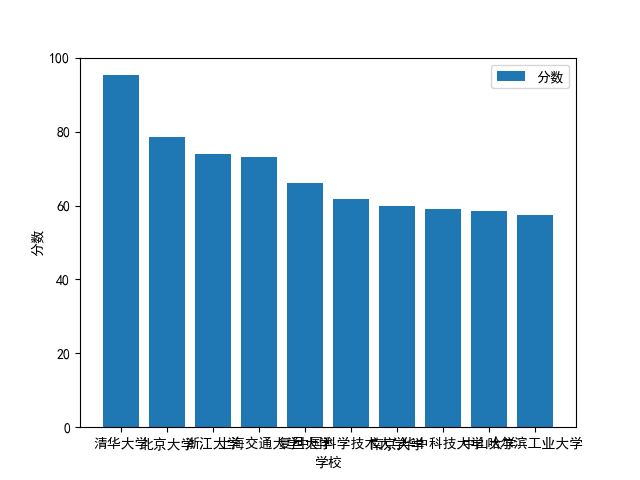

 浙公网安备 33010602011771号
浙公网安备 33010602011771号