


Spark SQL 及其DataFrame的基本操作
1.Spark SQL出现的 原因是什么?
Spark SQL出现是因为关系数据库已经不能满足各种在大数据时代新增的用户需求。首先,用户需要在不同的结构化和非结构化数据中执行各种操作。其次,用户需要执行像机器学习和图像处理等等高级分析,在实际应用中,也经常需要融合关系查询和分析复杂算法。
2.用spark.read 创建DataFrame
读取文本文件时用spark,read.text('people.txt')或spark.read.format('text').load('people.txt')
读取JSON文件时用spark,read.json('people.json')或spark.read.format('json').load('people.json')
读取Parquet本文件时用spark,read.parquet('people.parquet')或spark.read.format('parquet').load('people.parquet')
3.观察从不同类型文件创建DataFrame有什么异同?
4.观察Spark的DataFrame与Python pandas的DataFrame有什么异同?
pandas中的DataFrame是一种表格型数据结构,它按照列结构存储,它含有一组有序的列,每列可以是不同的值,但每一列只能有一种数据类型。在Spark中,DataFrame是基于 RDD 实现的。实际存储与RDD一致,基于行存储。
Spark SQL DataFrame的基本操作
创建:
spark.read.text()
file='file:///usr/local/spark/examples/src/main/resources/people.txt' df=spark.read.text(file)

spark.read.json()
file='file:///usr/local/spark/examples/src/main/resources/people.json' df=spark.read.json(file)

打印数据
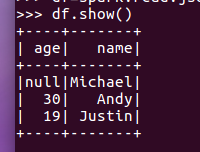
df.show()默认打印前20条数据,df.show(n)
打印概要
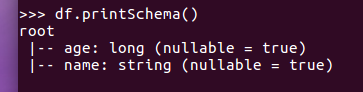
df.printSchema()
查询总行数
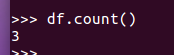
df.count()
df.head(3) #list类型,list中每个元素是Row类

输出全部行
df.collect() #list类型,list中每个元素是Row类

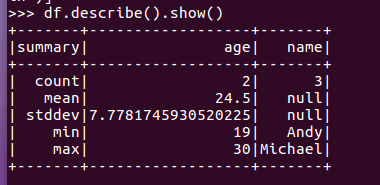
查询概况
df.describe().show()
取列
df['name']
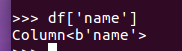
df.name
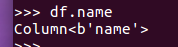
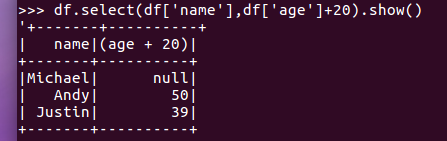
df.select()
df.select(df['name'],df['age']+20).show()
df.filter()
df.filter(df['age']>20).show()

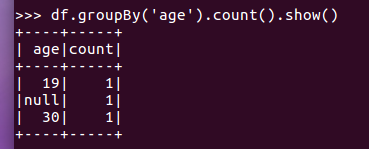
df.groupBy()
df.groupBy('age').count().show()
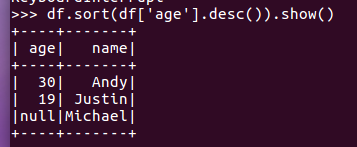
df.sort()
df.sort(df['age'].desc()).show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号