

途知·Bilibili多模态数据采集与AI融合解析
摘要:本文记述了在“途知·智能旅行助手”项目中,针对 Bilibili 视频平台进行多模态数据采集的技术实现。不同于传统的文本爬虫,本模块创新性地构建了 “Selenium会话托管 + yt-dlp音频流分离 + Paraformer语音转写 + LLM智能摘要” 的完整流水线,解决了动态渲染、强反爬风控及非结构化视听数据清洗等难题。
一、解题思路与架构设计
- 核心难点
本次任务的目标是采集福州热门景点在 Bilibili 上的相关视频数据。与传统文本平台不同,B 站的核心价值在于视频内容(UP主的口语解说)以及弹幕互动。
- 反爬虫机制 (HTTP 412):B 站视频流接口对 Cookie 校验极严 。
- 非结构化数据清洗:如何将视频音频转化为可被数据库存储的文本是最大挑战 。
- 动态渲染:评论区采用 Ajax 懒加载,静态解析无效 。
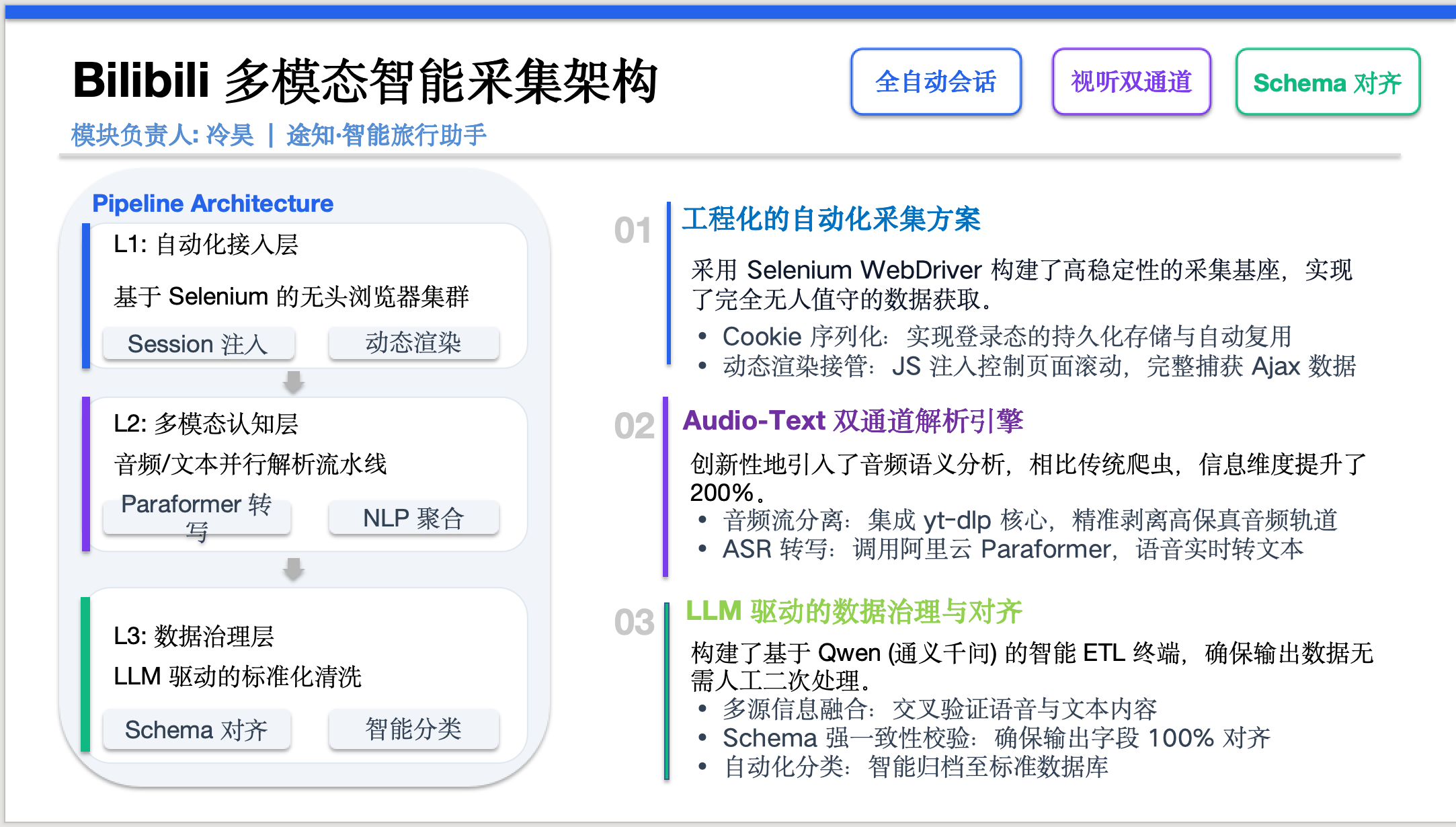
- 系统架构设计 (Pipeline)
针对上述难点,我设计了 L1-L2-L3 三层架构:
![image]()
二、具体实现过程
- 身份伪装与会话托管 (L1)
为了规避 B 站的风控,我使用 Selenium WebDriver 接管浏览器。为了避免每次运行都扫码,我编写了 Cookie 序列化 逻辑,将登录态保存为 Netscape 格式文件,供后续工具链复用 。
关键代码:
# 将 Selenium Cookie 转换为 Netscape 格式供 yt-dlp 使用
try:
with open(COOKIES_FILE, "w", encoding="utf-8") as f:
f.write("# Netscape HTTP Cookie File\n")
cookies = driver.get_cookies()
for cookie in cookies:
# 格式化写入 Netscape 标准格式
f.write(f"{domain}\t{flag}\t{path}\t{secure}\t{expiry}\t{name}\t{value}\n")
except:
print("Cookie 保存失败")
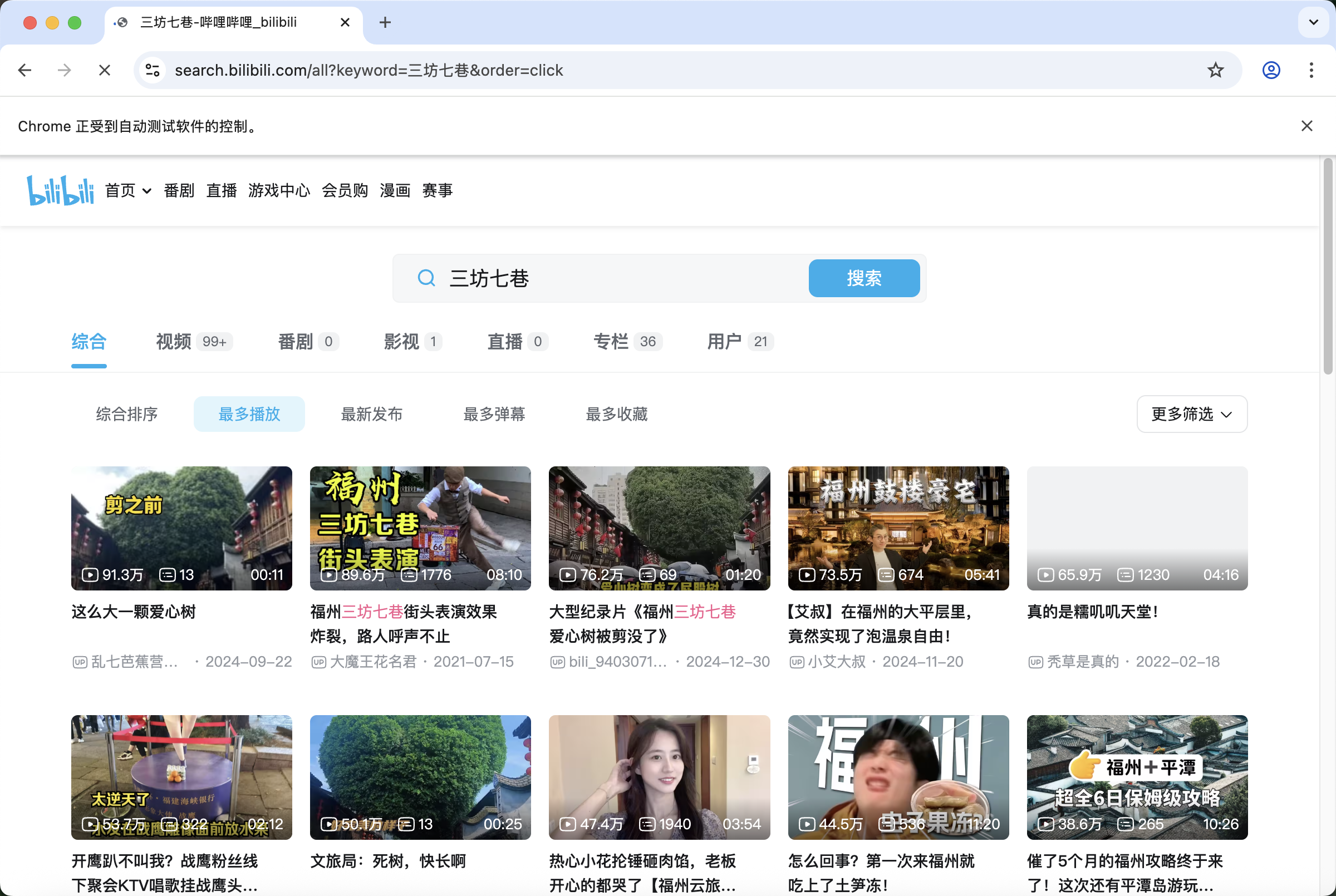
2. 模拟搜索与视频定位
系统通过 SEARCH_MAP 字典解决异构数据源命名不一致问题(如“金刚腿”映射为“福州 金刚腿”),提高搜索召回率 。
关键代码:
# 智能搜索映射,优化召回率
SEARCH_MAP = {
"金刚腿": "福州 金刚腿",
"沈葆祯故居": "福州 沈葆祯故居",
# ...
}
search_keyword = SEARCH_MAP.get(keyword, keyword)
driver.get(f"https://search.bilibili.com/all?keyword={search_keyword}")
3. 视听双通道解析 (L2)
这是本模块的核心。我没有下载庞大的视频画面,而是使用 yt-dlp 仅提取 m4a 音频流,并利用 Selenium 抓取动态渲染的简介与评论 。
关键代码:
def _download_audio(url, output_name, cookies_file):
ydl_opts = {
'format': 'bestaudio[ext=m4a]/bestaudio', # 仅下载音频
'cookiefile': cookies_file, # 注入 Cookie
'quiet': True,
}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
ydl.download([url])

4. AI 智能清洗与摘要 (L3)
原始的语音转写文本非常冗长。我接入阿里云 DashScope,先用 Paraformer 进行语音转写,再用 Qwen-Turbo 大模型将“语音+简介+评论”融合为结构化的景点介绍 。
关键代码:
def _call_ai_summary(audio, page, spot):
prompt = f"""
你是一个旅游数据专家。请根据以下关于景点“{spot}”的数据(语音+评论):
1. 总结一段150字左右的介绍,去除广告。
2. 判断分类。
【素材】:{combined[:3000]}
"""
resp = dashscope.Generation.call(model=dashscope.Generation.Models.qwen_turbo, prompt=prompt)

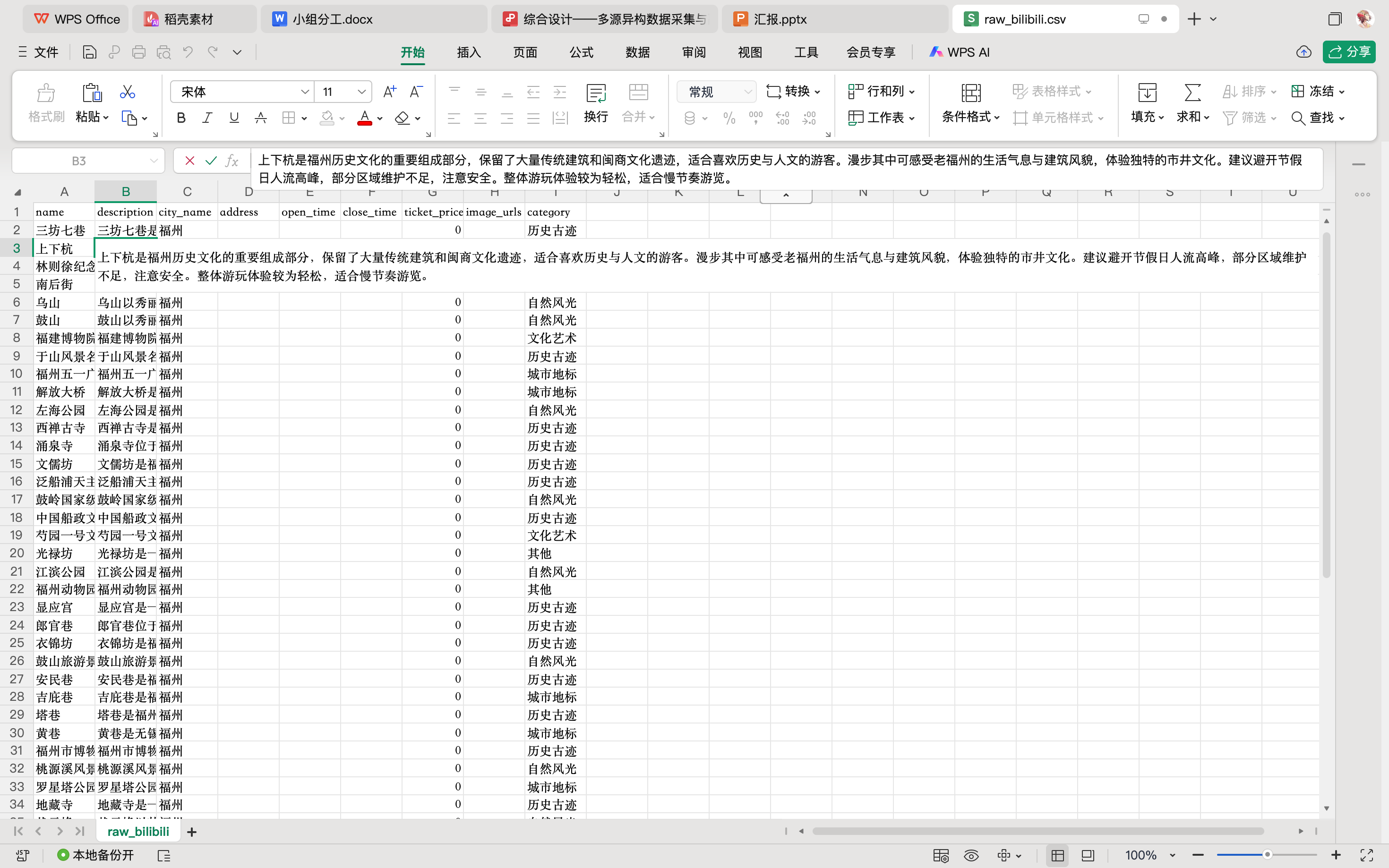
三、最终成果展示
经过清洗的数据被写入 CSV 文件,字段包含景点名称、AI 生成的精炼描述、以及自动判别的分类,完全符合数据库 Schema 标准。
四、总结
本次开发实现了从传统的 HTML Parsing 到 Audio Processing + AGI 的跨越。通过引入音频维度,我们不仅看到了景点的“样子”,还听到了博主的“真实评价”,这是纯文本爬虫无法比拟的优势。
代码源:https://gitee.com/wsmlhqqwwn/LH/blob/master/bilibili/bilibili.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号