
数据采集技术 - 第四次作业
作业①:东方财富网股票数据爬取
作业要求:
熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。
使用 Selenium 框架 + MySQL 数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网
输出信息:MySQL 数据库存储和输出格式。
1. 实验准备与设计思路
(1) 技术路线分析
我的代码主要实现了以下 5 个核心功能:
- 准备工作 (Initialization):启动浏览器,连接数据库并清空旧数据。
- 智能等待 (Smart Waiting):解决 Ajax 动态加载问题,防止抓空。
- 数据抄写与清洗 (Parsing & Cleaning):提取表格数据,并将无效字符 - 清洗为 0。
- 自动入库 (Saving):批量写入 MySQL 数据库。
- 自动翻页 (Pagination):定位无文字的翻页按钮并点击。
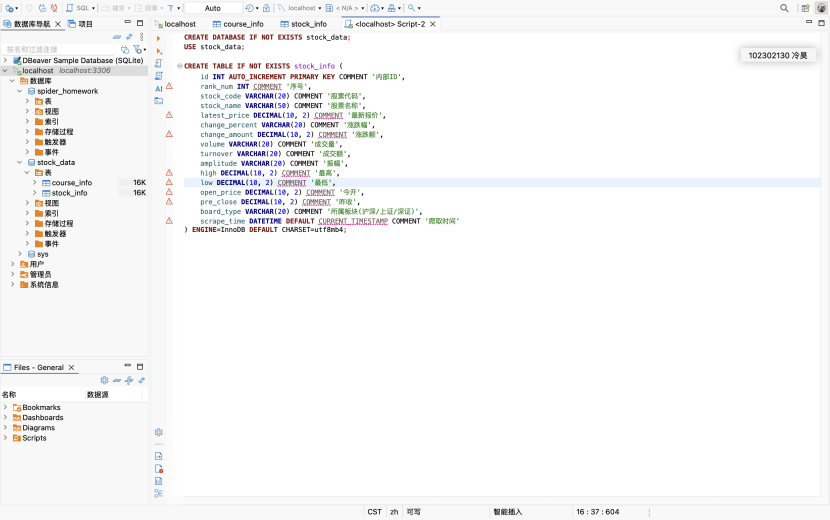
(2) 数据库表结构设计
为了存储爬取到的数据,我使用 DBeaver(或命令行)连接本地 MySQL,创建了名为 stock_data 的数据库,并在其中设计了 stock_info 表。
Python 核心代码详解
步骤 1:准备工作 (Initialization)
在初始化阶段,我们需要配置数据库连接信息,并在启动浏览器之前执行 TRUNCATE 命令清空旧数据,确保每次运行的结果都是干净的。
import pymysql
from selenium import webdriver
from selenium.webdriver.edge.options import Options as EdgeOptions
# 数据库配置
DB_CONFIG = {
'host': 'localhost', 'user': 'root', 'password': '***',
'database': 'stock_data', 'charset': 'utf8mb4'
}
class StockScraper:
def __init__(self):
print("正在连接数据库...")
self.db = pymysql.connect(**DB_CONFIG)
self.cursor = self.db.cursor()
# 关键点:启动时自动清空旧数据
self.cursor.execute("TRUNCATE TABLE stock_info")
self.db.commit()
# 启动 Edge 浏览器(禁用插件以加快速度)
options = EdgeOptions()
options.add_argument("--disable-extensions")
self.driver = webdriver.Edge(options=options)
self.driver.maximize_window()
步骤 2:智能等待 (Smart Waiting)
东方财富网的表格是 Ajax 动态加载的。为了防止代码跑得太快抓到空数据,我使用了 WebDriverWait 显式等待,直到网页中出现了 tbody tr 元素才开始后续操作。
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def run(self):
# ... (省略循环部分) ...
# 关键点:显式等待表格加载,最长等待 30 秒
WebDriverWait(self.driver, 30).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "tbody tr"))
)
time.sleep(1) # 稍微缓冲,等待数据渲染完全
步骤 3:数据抄写与清洗 (Parsing & Cleaning)
这一步负责从 HTML 表格中提取文本。由于部分新上市股票的涨跌幅显示为 -,直接存入数据库会报错,因此我在代码中增加了数据清洗逻辑。
def parse_page(self):
"""解析页面数据并清洗"""
rows = self.driver.find_elements(By.CSS_SELECTOR, 'tbody tr')
data_list = []
for row in rows:
cols = row.find_elements(By.TAG_NAME, 'td')
if len(cols) < 14: continue # 跳过无效行
# 提取 13 列数据
row_data = (
cols[0].text, cols[1].text, cols[2].text, cols[4].text,
cols[5].text, cols[6].text, cols[7].text, cols[8].text,
cols[9].text, cols[10].text, cols[11].text, cols[12].text,
cols[13].text
)
# 关键点:数据清洗,将 '-' 替换为 0
cleaned_data = tuple(0 if x == '-' else x for x in row_data)
data_list.append(cleaned_data)
# 顺便在控制台打印出来,方便检查
print(cleaned_data)
return data_list
步骤 4:自动入库 (Saving)
为了提高效率,我使用了 executemany 方法,将一整页的数据一次性批量插入 MySQL 数据库。
def save_to_mysql(self, data_list, board_name):
"""批量保存数据到 MySQL"""
sql = """
INSERT INTO stock_info
(rank_num, stock_code, stock_name, latest_price, change_percent, change_amount,
volume, turnover, amplitude, high, low, open_price, pre_close, board_type)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
# 给每条数据加上“板块名称”标签
data_with_board = [item + (board_name,) for item in data_list]
# 关键点:批量执行插入
self.cursor.executemany(sql, data_with_board)
self.db.commit()
print(f"[数据库] 已保存 {len(data_list)} 条数据")
步骤 5:自动翻页 (Pagination)
网页的“下一页”按钮是一个 > 符号,且容易被广告遮挡。我使用了 XPath //a[contains(text(), ">")] 来精准定位,并使用 JavaScript 进行点击。
# 翻页逻辑
if page < MAX_PAGES:
# 关键点:使用 XPath 定位文本包含 ">" 的链接
next_btn = self.driver.find_element(By.XPATH, '//a[contains(text(), ">")]')
# 检查按钮是否可用
if "disabled" not in next_btn.get_attribute("class"):
# 使用 JS 点击,防止被广告遮挡
self.driver.execute_script("arguments[0].click();", next_btn)
time.sleep(3) # 翻页后必须等待加载
3. 运行结果展示

4. 心得体会
通过本次作业,我对 Selenium 爬虫和数据库存储有了更深的理解,主要收获如下:
翻页的技巧:
东方财富网的“下一页”按钮没有文字,只有一个 > 符号。普通的文本查找失效了。我学会了使用 XPath 的 contains(text(), ">") 语法来定位它
数据的严谨性:
在存入 MySQL 时,我发现直接存入网页上的 - 会导致程序报错。这让我意识到数据清洗的重要性。在代码中加入简单的 if-else 判断将无效值转换为 0 后,程序就可以顺畅跑通了
这次实验让我明白了,写爬虫不仅仅是写几行代码,更重要的是分析网页结构和处理各种突发的数据异常。
作业②:中国 MOOC 网课程数据爬取
实验要求:
熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据。爬取中国 MOOC 网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)并存入 MySQL。
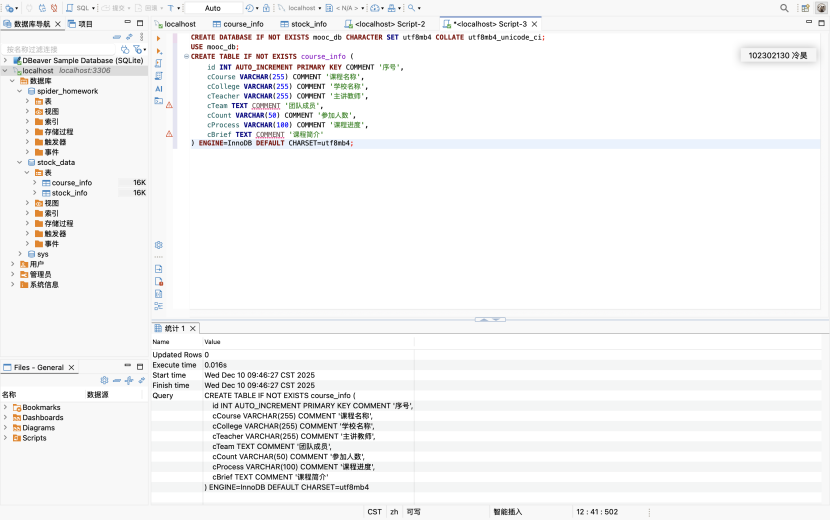
候选网站: 中国 MOOC 网(https://www.icourse163.org)
为了存储爬取到的数据,我使用 DBeaver(或命令行)连接本地 MySQL,创建了名为 mooc_db 的数据库,并在其中设计了course_info表。
核心思路:
- 模拟登录:采用“手动辅助登录”策略,程序启动后暂停,留出时间供用户扫码,绕过复杂的滑块验证码。
- 个人课程页跳转:登录后直接跳转到个人专属的课程列表页(home.htm),获取已选修的特定课程链接。
- 多窗口句柄管理:使用 window.open 打开详情页,抓取完成后关闭窗口并切回主句柄,保证程序稳定运行。
核心代码
(1) 基础配置与数据库初始化
导入 Selenium 和 PyMySQL 库,建立数据库连接。为了保证实验结果的准确性,每次运行前都会执行 TRUNCATE 清空旧数据。
from selenium import webdriver
from selenium.webdriver.common.by import By
import pymysql
import time
DB_PASSWORD = 'password' # 请替换为实际密码
MY_USER_ID = '1558819800' # 个人ID
# 连接数据库
db = pymysql.connect(host='localhost', user='root', password=DB_PASSWORD, database='mooc_db', charset='utf8mb4')
cursor = db.cursor()
# 每次运行前清空表,确保数据纯净
cursor.execute("TRUNCATE TABLE course_info;")
db.commit()
options = webdriver.ChromeOptions()
dr = webdriver.Chrome(options=options)
(2) 模拟登录与页面跳转
首先访问首页并暂停,等待用户手动扫码登录。登录完成后,直接拼接包含 userId 的 URL 跳转至个人课程列表页,并执行滚动操作以加载所有课程卡片。
步骤一:登录
dr.get("[https://www.icourse163.org/](https://www.icourse163.org/)")
input("扫码登录后按回车...")
步骤二:跳转到个人课程页
dr.get(f"[https://www.icourse163.org/home.htm?userId=](https://www.icourse163.org/home.htm?userId=){MY_USER_ID}#/home/course")
time.sleep(3)
滚动加载
dr.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
(3) 提取课程链接
筛选出属于课程详情页(包含 /course/ 或 /learn/)的链接,并进行去重处理。
步骤三:提取链接
links = dr.find_elements(By.TAG_NAME, 'a')
urls = []
for link in links:
href = link.get_attribute('href')
if href and ('/course/' in href or '/learn/' in href) and 'icourse163.org' in href:
urls.append(href)
urls = list(set(urls))
print(f"共发现 {len(urls)} 门课程")
main_window = dr.current_window_handle
(4) 循环抓取与窗口管理
遍历所有课程链接。为了保持主列表页不刷新,使用 window.open 打开新窗口进行抓取。针对 /learn/ 类型的链接,强制替换为 /course/ 以确保进入详情页获取元数据。
步骤四:循环抓取
for u in urls:
# 链接处理:强制进入详情页
if '/learn/' in u:
u = u.replace('/learn/', '/course/')
if '?tid=' in u:
u = u.split('?tid=')[0]
# 打开新窗口
dr.execute_script(f"window.open('{u}');")
dr.switch_to.window(dr.window_handles[-1])
time.sleep(3)
(5) 字段提取
使用 find_elements 方法提取课程名称、学校、教师、时间、简介等信息。通过判断返回列表的长度来确定元素是否存在,若不存在则使用默认值或备选方案(如学校名称优先抓取图片 Alt 属性)。
# 1. 课程名称
name = "未找到名称"
eles = dr.find_elements(By.TAG_NAME, 'h1')
if len(eles) > 0:
name = eles[0].text
else:
eles_span = dr.find_elements(By.XPATH, '//span[contains(@class,"course-title")]')
if len(eles_span) > 0:
name = eles_span[0].text
# 2. 学校名称 (优先抓取 Logo 图片的 alt 属性)
school = "未知学校"
img_eles = dr.find_elements(By.XPATH, '//img[contains(@class, "u-img") and @alt]')
if len(img_eles) > 0:
school = img_eles[0].get_attribute('alt')
else:
txt_eles = dr.find_elements(By.XPATH, '//div[contains(@class,"course-school")]')
if len(txt_eles) > 0:
school = txt_eles[0].text
# 3. 教师和团队
teacher = "未知"
team = "无团队"
t_eles = dr.find_elements(By.XPATH, '//h3[contains(@class, "f-fc3")]')
if len(t_eles) > 0:
teacher = t_eles[0].text
if len(t_eles) > 1:
team_list = []
for t in t_eles[1:]:
team_list.append(t.text)
team = ",".join(team_list)
# 4. 开课时间 (精准定位 term-time)
process = "未开始"
p_eles = dr.find_elements(By.XPATH, '//div[contains(@class, "term-time")]/span')
if len(p_eles) > 0:
process = p_eles[0].text
else:
p_eles2 = dr.find_elements(By.XPATH, '//div[contains(@class,"course-process")]')
if len(p_eles2) > 0:
process = p_eles2[0].text
# 5. 简介
brief = "无简介"
b_eles = dr.find_elements(By.XPATH, '//div[contains(@class, "m-infomation_content-section")]')
if len(b_eles) > 0:
brief = b_eles[0].text
else:
b_eles2 = dr.find_elements(By.XPATH, '//div[@class="m-cintro"]')
if len(b_eles2) > 0:
brief = b_eles2[0].text
# 6. 人数
count = "0"
c_eles = dr.find_elements(By.XPATH, '//*[contains(text(),"人参加")]')
if len(c_eles) > 0:
count = c_eles[0].text.replace("已有", "").replace("人参加", "").strip()
(6) 数据入库与收尾
将抓取到的有效数据插入 MySQL 数据库,随后关闭当前详情页窗口并切回主窗口,准备处理下一个链接。
# 入库
if name != "未找到名称":
sql = "INSERT INTO course_info (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief) VALUES (%s, %s, %s, %s, %s, %s, %s)"
cursor.execute(sql, (name, school, teacher, team, count, process, brief))
db.commit()
print(f"成功: {name}")
dr.close()
dr.switch_to.window(main_window)
db.close()
dr.quit()
关键元素定位分析:
为了确保抓取的数据真实有效,我对网页源码进行了详细分析:
学校名称:许多课程的学校名称是以图片 Logo 形式存在的,直接抓文字会抓空。我通过定位 //img[contains(@class, "u-img")] 并获取其 alt 属性,成功解决了这个问题。
开课时间:精准定位到详情页的 term-time 区域,获取了具体的起止日期,而不是模糊的“进行中”。
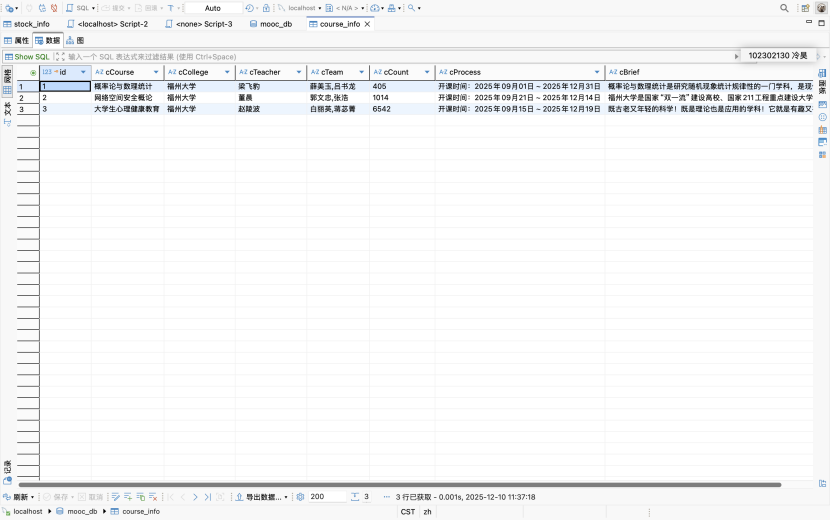
实验结果:

2. 心得体会
在进行中国 MOOC 网的爬取实验时,我主要攻克了以下几个难点,并对爬虫逻辑有了更深的理解:
- “人机协作”解决登录难题:MOOC 网的登录验证(滑块、短信等)对于纯自动化脚本来说门槛较高。我采用了 input() 暂停脚本的方式,手动完成扫码登录,再让脚本接管后续操作。这种方式既简单又高效,非常适合我们这种一次性的作业采集任务。
- 多窗口与链接清洗:在爬取过程中,我发现从列表页获取的链接有的是 /learn/(视频页),有的是 /course/(详情页)。为了统一数据来源,我在代码中加了字符串替换逻辑,强制跳转到详情页。同时,利用 window.open 和 switch_to.window 在新标签页中作业,避免了频繁后退导致的列表页刷新问题,大大提高了爬取的稳定性。
作业③
1.大数据实时分析处理实验
实验要求
掌握大数据相关服务,熟悉 Xshell 的使用。
完成华为云_大数据实时分析处理实验手册中的 Flume 日志采集任务
实验结果
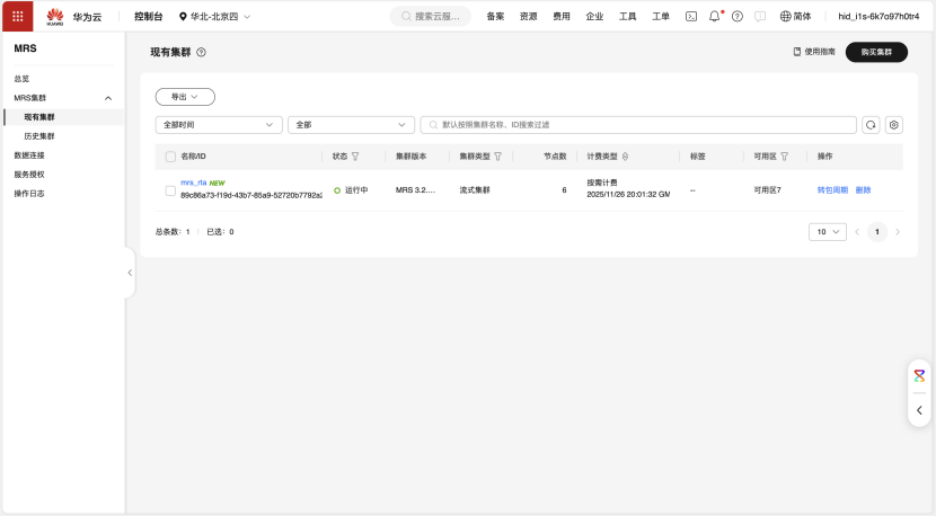
环境搭建:创建 MRS 集群:成功购买并启动了包含 Kafka 和 Flume 组件的 MRS 流式集群。
数据采集通道配置
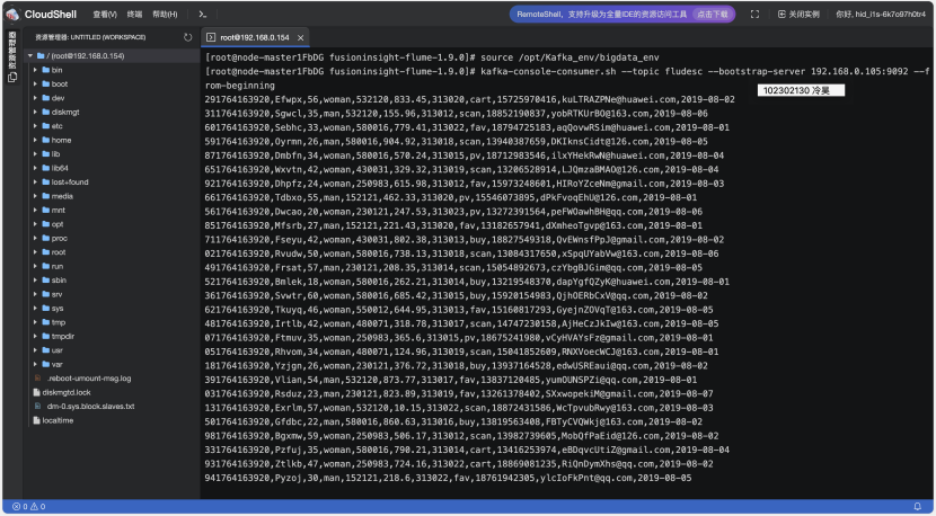
数据模拟:登录 MRS Master 节点,编写 autodatagen.py 脚本。运行脚本生成测试数据,并使用 more 命令验证数据格式。
def get_random_record():
return get_random_rowkey() + "," + get_random_name(5) + "," + \
get_random_age() + "," + get_random_sex() + "," + \
get_random_goods_no() + "," + get_random_goods_price() + "," + \
get_random_store_id() + "," + get_random_goods_type() + "," + \
get_random_tel() + "," + get_random_email(10) + "," + \
get_random_buy_time()

Kafka 配置:在 MRS 节点安装 Kafka 客户端,获取 Broker 业务 IP,创建了名为 fludesc 的 Topic。

通道联调:配置并启动 Flume。
Flume 核心配置 (properties.properties):
# Source: 监控本地目录
client.sources.s1.type = spooldir
client.sources.s1.spoolDir = /tmp/flume_spooldir
# Sink: 输出到 Kafka
client.sinks.sh1.type = org.apache.flume.sink.kafka.KafkaSink
client.sinks.sh1.kafka.topic = fludesc
client.sinks.sh1.kafka.bootstrap.servers = 192.168.0.105:9092
启动 Flume 后,启动 Kafka Console Consumer,同时运行 Python 生成脚本。观察到消费者端实时刷新出生成的数据,证明 Python -> Flume -> Kafka 链路完全打通。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号