关于 Elasticsearch 内存占用及分配
转自:https://segmentfault.com/a/1190000018558875?utm_source=sf-similar-article
Elasticsearch 和 Lucene 对内存使用情况: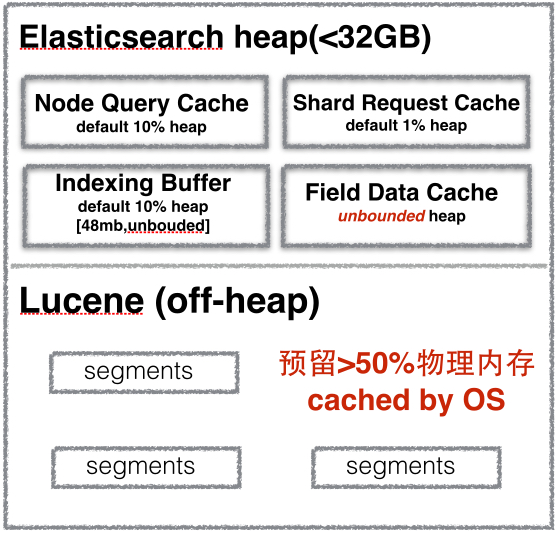
Elasticsearch 限制的内存大小是 JAVA 堆空间的大小,不包括Lucene 缓存倒排索引数据空间。
- Lucene 中的 倒排索引 segments 存储在文件中,为提高访问速度,都会把它加载到内存中,从而提高 Lucene 性能。所以建议至少留系统一半内存给Lucene。
-
Node Query Cache (负责缓存f ilter 查询结果),每个节点有一个,被所有 shard 共享,filter query查询结果要么是 yes 要么是no,不涉及 scores 的计算。
集群中每个节点都要配置,默认为:indices.queries.cache.size:10% -
Indexing Buffer 索引缓冲区,用于存储新索引的文档,当其被填满时,缓冲区中的文档被写入磁盘中的 segments 中。节点上所有 shard 共享。
缓冲区默认大小:indices.memory.index_buffer_size: 10%
如果缓冲区大小设置了百分百则indices.memory.min_index_buffer_size用于这是最小值,默认为 48mb。indices.memory.max_index_buffer_size用于最大大小,无默认值。 -
Shard Request Cache 用于缓存请求结果,但之缓存request size为0的。比如说 hits.total, aggregations 和 suggestions.
默认最大为indices.requests.cache.size:1% -
Field Data Cache 字段缓存重要用于对字段进行排序、聚合是使用。因为构建字段数据缓存代价昂贵,所以建议有足够的内训来存储。
Fielddata 是 延迟 加载。如果你从来没有聚合一个分析字符串,就不会加载 fielddata 到内存中,也就不会使用大量的内存,所以可以考虑分配较小的heap给Elasticsearch。因为heap越小意味着Elasticsearch的GC会比较快,并且预留给Lucene的内存也会比较大。。
如果没有足够的内存保存fielddata时,Elastisearch会不断地从磁盘加载数据到内存,并剔除掉旧的内存数据。剔除操作会造成严重的磁盘I/O,并且引发大量的GC,会严重影响Elastisearch的性能。
Elasticsearch默认安装后设置的内存是1GB,这是远远不够用于生产环境的。
有两种方式修改Elasticsearch的堆内存:
- 设置环境变量:
export ES_HEAP_SIZE=10g在es启动时会读取该变量; - 启动时作为参数传递给es:
./bin/elasticsearch -Xmx10g -Xms10g
给es分配内存时要注意,至少要分配一半儿内存留给 Lucene。
分配给 es 的内存最好不要超过 32G ,因为如果堆大小小于 32 GB,JVM 可以利用指针压缩,这可以大大降低内存的使用:每个指针 4 字节而不是 8 字节。如果大于32G 每个指针占用 8字节,并且会占用更多的内存带宽,降低了cpu性能。
还有一点, 要关闭 swap 内存交换空间,禁用swapping。频繁的swapping 对服务器来说是致命的。
总结:给es JVM栈的内存最好不要超过32G,留给Lucene的内存越大越好,Lucene把所有的segment都缓存起来,会加快全文检索。
参考文档:
https://nereuschen.github.io/...
https://www.elastic.co/guide/...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号