大文件排序
设想你有一个20GB的文件,每行一个字符串,说明如何对这个文件进行排序。
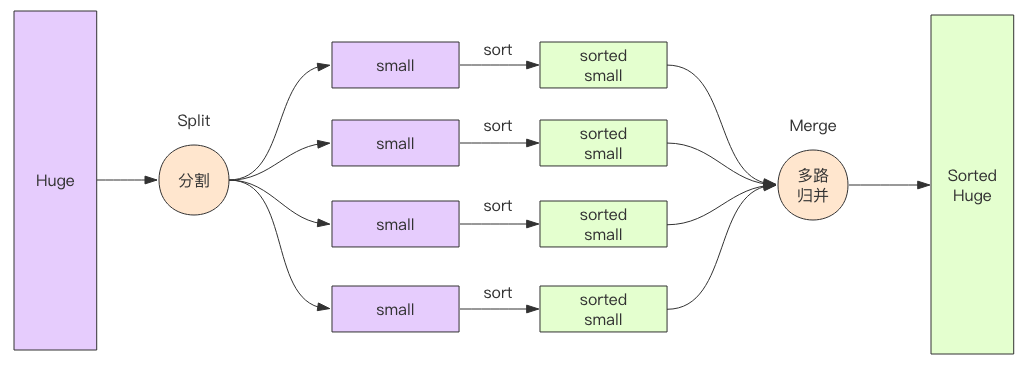
内存肯定没有20GB大,所以不可能采用传统排序法。但是可以将文件分成许多块,每块xMB,针对每个快各自进行排序,存回文件系统。
然后将这些块逐一合并,最终得到全部排好序的文件。
外排序的一个例子是外归并排序(External merge sort),它读入一些能放在内存内的数据量,在内存中排序后输出为一个顺串(即是内部数据有序的临时文件),处理完所有的数据后再进行归并。[1][2]比如,要对900MB的数据进行排序,但机器上只有100 MB的可用内存时,外归并排序按如下方法操作:
- 读入100 MB的数据至内存中,用某种常规方式(如快速排序、堆排序、归并排序等方法)在内存中完成排序。
将排序完成的数据写入磁盘。 - 重复步骤1和2直到所有的数据都存入了不同的100 MB的块(临时文件)中。在这个例子中,有900 MB数据,单个临时文件大小为100 MB,所以会产生9个临时文件。
- 读入每个临时文件(顺串)的前10 MB( = 100 MB / (9块 + 1))的数据放入内存中的输入缓冲区,最后的10 MB作为输出缓冲区。(实践中,将输入缓冲适当调小,而适当增大输出缓冲区能获得更好的效果。)
- 执行九路归并算法,将结果输出到输出缓冲区。一旦输出缓冲区满,将缓冲区中的数据写出至目标文件,清空缓冲区。一旦9个输入缓冲区中的一个变空,就从这个缓冲区关联的文件,读入下一个10M数据,除非这个文件已读完。这是“外归并排序”能在主存外完成排序的关键步骤 -- 因为“归并算法”(merge algorithm)对每一个大块只是顺序地做一轮访问(进行归并),每个大块不用完全载入主存。
多路归并的思路主要是堆:
从 K 个序列中各取一个元素,并记录每个元素的来源数组,建立一个含 K 个元素的小根堆。此时堆顶就是最小的元素,取出堆顶元素,并从堆顶元素的来源序列中取下一个元素放入堆顶,然后向下调整。在向下调整过程中需要和其两个子结点比较,需要比较 2 次。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号