爬取京东商品评论信息
(一)、选题的背景
在这个科技飞速发展的时代,网上购物十分流行,对于一些商品的好坏,可以加以评论。做这一选题的目的主要是运用爬虫来爬取商品的评论信息,并加以分析。爬取京东商品的评论数据并加以分析,通过顾客对商品的客观评价,总结得出顾客对商品评论的热词,得出顾客对某一类商品的关注点;对商品的打分与时间间隔的关系等相关信息,得出产品的质量是否有保障,这产品是否实用等。
(二)、主题式网络爬虫设计方案
1.主题式网络爬虫名称
爬取京东商品评论信息
2.主题式网络爬虫爬取的内容与数据特征分析
爬取内容:京东商品的热门评论十大关键词、打分、热词。
数据特征分析:网页文本。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
爬取京东售卖的商品下的评论信息,得出其关键词,并分析顾客打分与打分时间的关系。
主要用到的库有python的requests、json、csv、time、pandas、jieba、matplotlib.pyplot、numpy。
(三)、主题页面的结构特征分析
1.主题页面的结构与特征分析
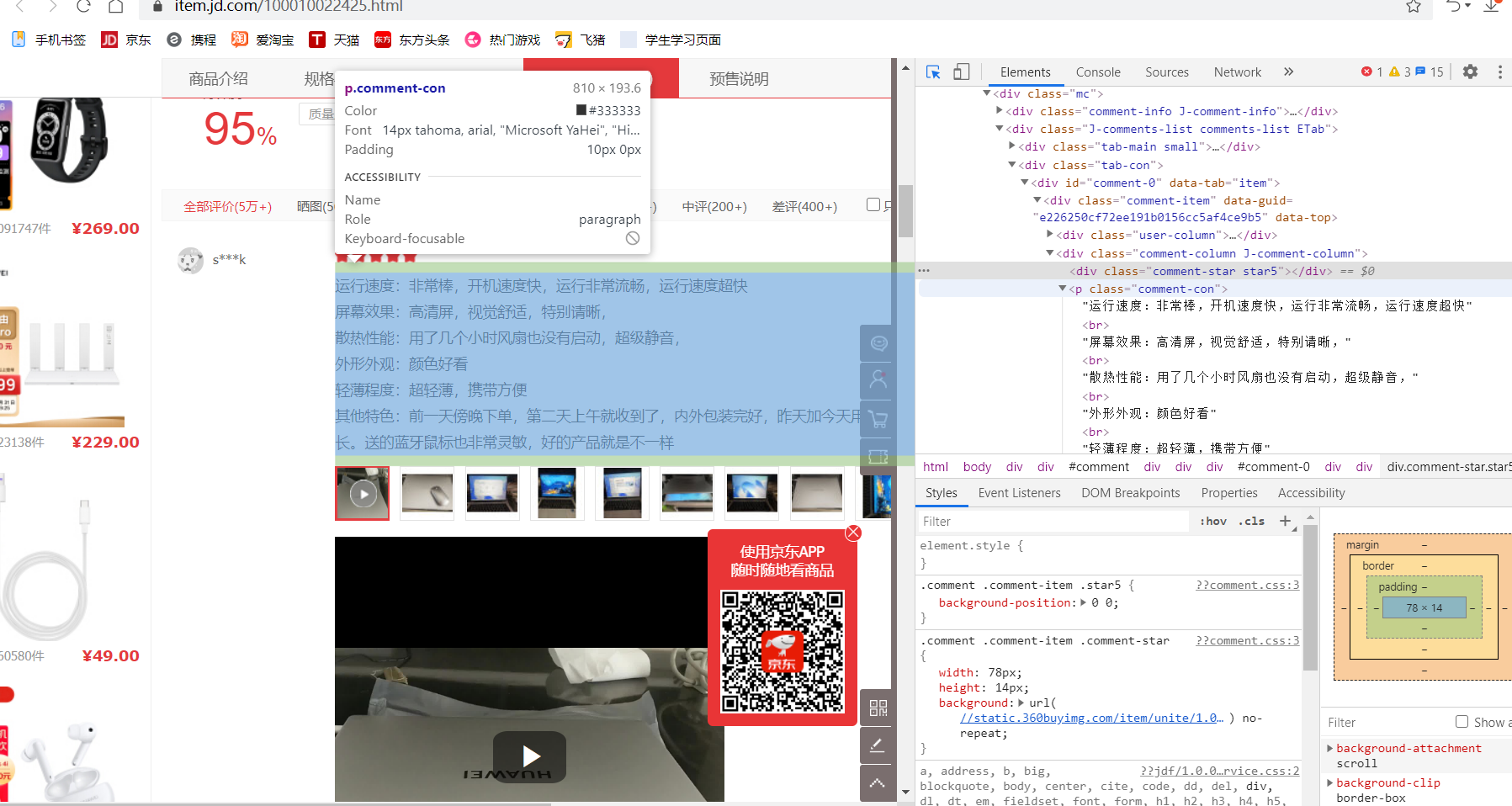
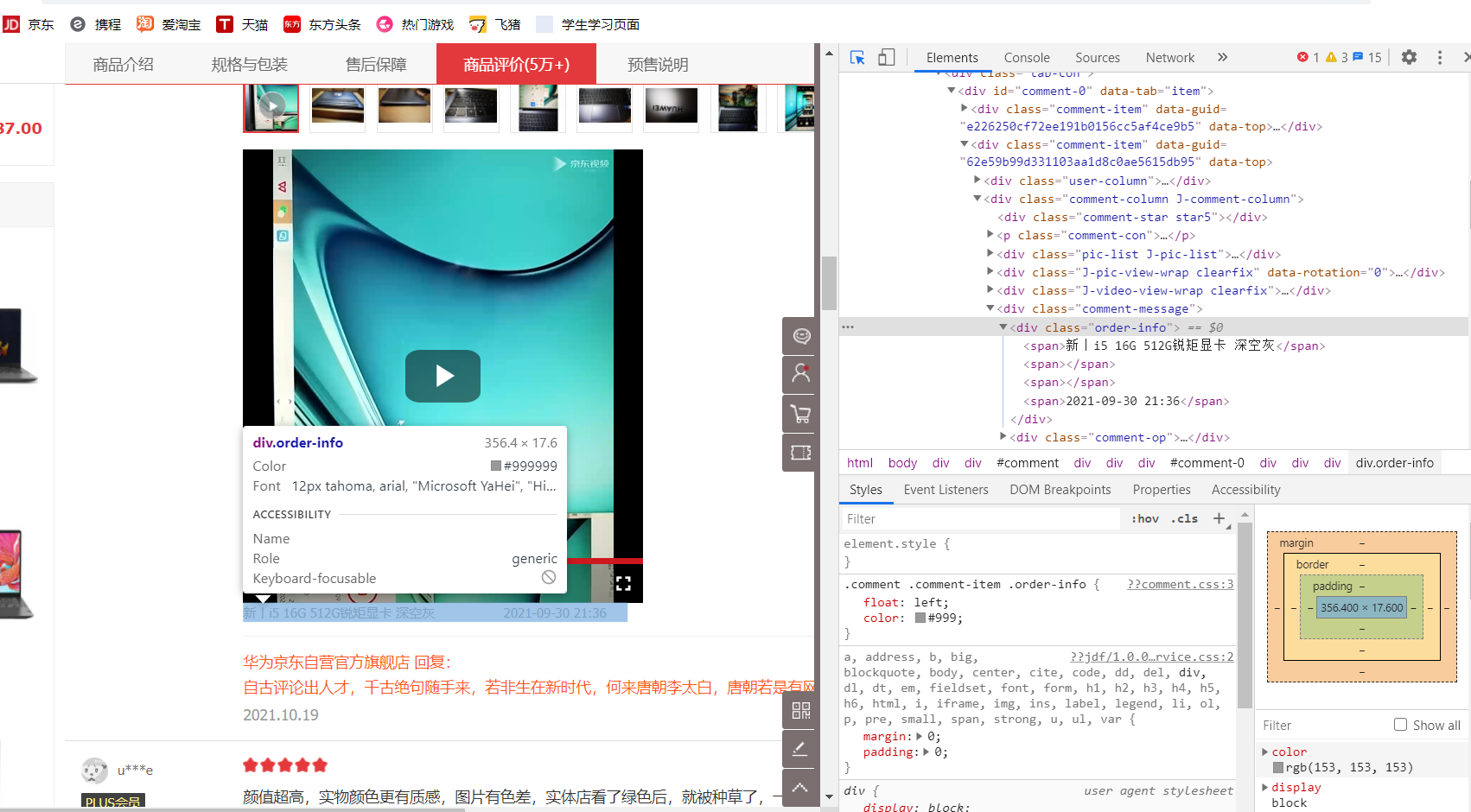
2.Htmls 页面解析
每条评论的文字信息都有这个标签:<p class="comment-con">开头,每条评论的时间都有<span>开头,</span>结尾。
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
查找方法:find 遍历方法:for循环
(四)、网络爬虫程序设计
1.数据爬取与采集
1 def jd_crawl_comment(item_id,pagenum): 2 3 list_ =[] 4 start_page = 1 5 end_page = pagenum 6 for p in range(start_page, end_page + 1): 7 print(p) 8 #productid = 3048505 9 url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv995&productId='+str(item_id)+'&score=0&sortType=5&page={}&pageSize=10&isShadowSku=0&fold=1' 10 url = url.format(p) 11 print(url) 12 #仿造请求头,骗过浏览器 13 headers = { 14 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36', 15 'Referer': 'https://item.jd.com/1981570.html' 16 } 17 #发起请求 18 #request = urllib.request.Request(url=url, headers=headers) 19 #得到响应 20 content = requests.get(url=url,headers=headers).content.decode('gbk') 21 #去掉多余得到json格式 22 content = content.strip('fetchJSON_comment98vv995();') 23 print(content)
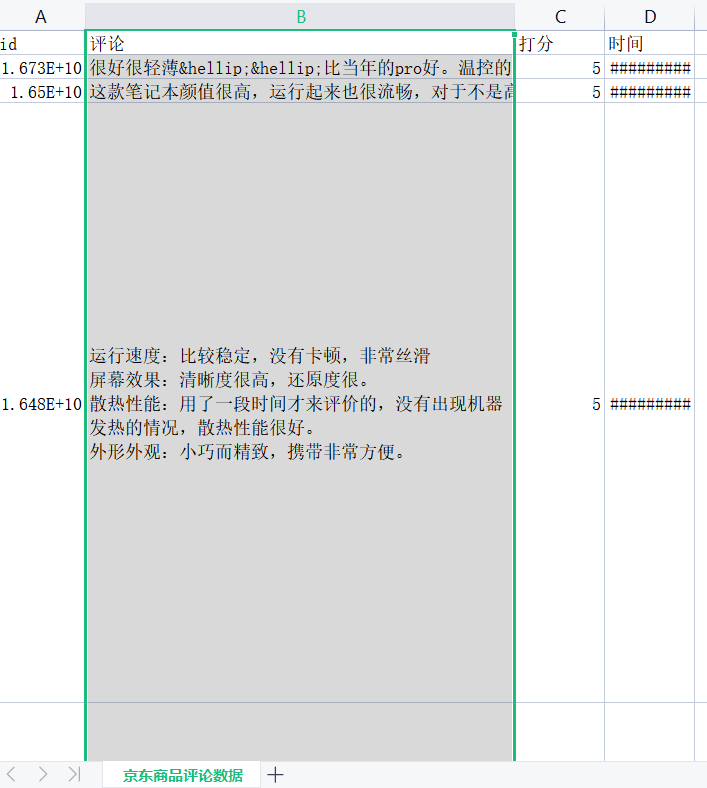
2.对数据进行清洗和处理
保存商品评论数据.csv:
1 def jd_crawl_comment(item_id,pagenum): 2 3 list_ =[] 4 start_page = 1 5 end_page = pagenum 6 for p in range(start_page, end_page + 1): 7 print(p) 8 #productid = 3048505 9 url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv995&productId='+str(item_id)+'&score=0&sortType=5&page={}&pageSize=10&isShadowSku=0&fold=1' 10 url = url.format(p) 11 print(url) 12 #仿造请求头,骗过浏览器 13 headers = { 14 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36', 15 'Referer': 'https://item.jd.com/1981570.html' 16 } 17 #发起请求 18 #request = urllib.request.Request(url=url, headers=headers) 19 #得到响应 20 content = requests.get(url=url,headers=headers).content.decode('gbk') 21 #去掉多余得到json格式 22 content = content.strip('fetchJSON_comment98vv995();') 23 print(content) 24 obj = json.loads(content) 25 26 comments = obj['comments'] 27 print(comments) 28 fp = open('jingdong.txt', 'a', encoding='gbk') 29 for comment in comments: 30 # print(comment) 31 name = comment['referenceName'] 32 33 id = comment['id'] 34 35 con = comment['content'] 36 37 creationTime = comment['creationTime'] 38 39 img_url = comment['userImageUrl'] 40 score = comment['score'] 41 item = { 42 'name': name, 43 'id': id, 44 'con': con, 45 'time': creationTime, 46 'img_url': img_url, 47 } 48 string = str(item) 49 50 print(id, con, score, creationTime) 51 list_.append([id, con, score, creationTime]) 52 fp.write(string + '\n') 53 54 fp.close() 55 print('%s-page---finish' % p) 56 #print(list_) 57 time.sleep(5) 58 return list_ 59 def write_to_csv(list_,header,outputfile): 60 with open(outputfile, 'w', encoding='utf8', newline='') as f: 61 writer = csv.writer(f) 62 writer.writerow(header) 63 for l in list_: 64 writer.writerow(l) 65 f.close()

3.文本分析
生成商品评论数据.csv词云图:
1 def wordcloud_京东_商品评论(filename,output): 2 # 生成词云的方法 3 f = open(filename,encoding='utf8') 4 data = pd.read_csv(f) 5 6 string = '' 7 comments = data['评论'] 8 for c in comments: 9 string += str(c) + '\n' 10 print(string) 11 cut = " ".join(jieba.cut(string)) 12 # stopwords remove 13 stopwords = ['其他', '很多', '不是', '非常', '这个', '那个', '真的', '可以', '没有'] 14 for word in stopwords: 15 cut = cut.replace(word,'') 16 d = path.dirname(__file__) 17 18 cloud = WordCloud( # 设置字体,不指定就会出现乱码 19 scale=4, 20 font_path=path.join(d, 'simhei.ttf'), 21 background_color='white', 22 max_words=2000, 23 max_font_size=1550, 24 min_font_size=2, 25 collocations=False, 26 relative_scaling=0.4, 27 prefer_horizontal=1) 28 wc = cloud.generate_from_text(cut) 29 wc.to_file(output)
运行结果如下:

4.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图)
整理数据得出十大关键词:
1 def 词频_京东商品评论_柱状图(inputfile, topN): 2 # 柱状图显示词频前N 3 f = open(inputfile, encoding='utf8') 4 data = pd.read_csv(f) 5 6 string = '' 7 comments = data['评论'] 8 for c in comments: 9 string += str(c) + '\n' 10 print(string) 11 12 txt = string 13 words = jieba.lcut(txt) 14 dic_ = {} #创建字典 15 stopwords = ['其他', '很多', '不是', '非常', '这个', '那个', '真的', '可以', '没有',"就是","这里"] 16 17 for word in words: 18 if len(word) == 1: 19 continue 20 else: 21 rword = word 22 dic_[rword] = dic_.get(rword,0) + 1 23 for word in stopwords: 24 try: 25 del(dic_[word]) 26 except: 27 pass 28 items = list(dic_.items()) 29 # 排序 按词频率 30 items.sort(key=lambda x:x[1], reverse =True) 31 32 labels = [] 33 sizes = [] 34 n = topN 35 wordlist = list() 36 for i in range(n): 37 word,count = items[i] 38 labels.append(word) 39 sizes.append(count) 40 wordlist.append(word) 41 42 plt.rcParams['font.sans-serif'] = ['SimHei'] 43 plt.rcParams['axes.unicode_minus'] = False 44 f, ax = plt.subplots() 45 # 横向图 46 rect = ax.barh(range(len(sizes)), sizes, tick_label='') 47 plt.yticks(np.arange(len(labels)), labels) 48 plt.legend((rect,), ("前十关键词",)) 49 plt.savefig('前十关键词.jpg') 50 return labels,sizes
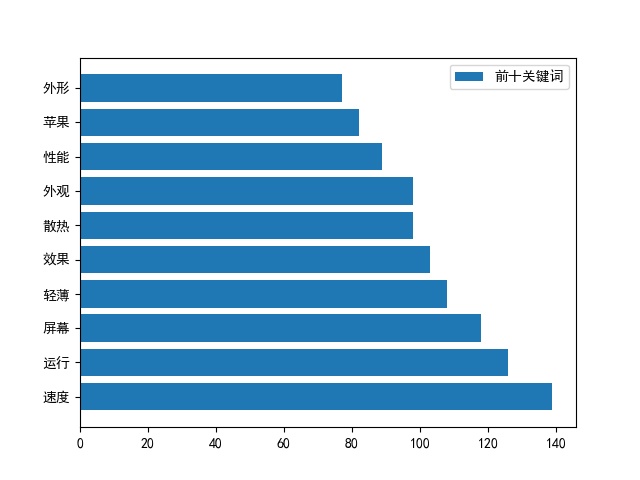
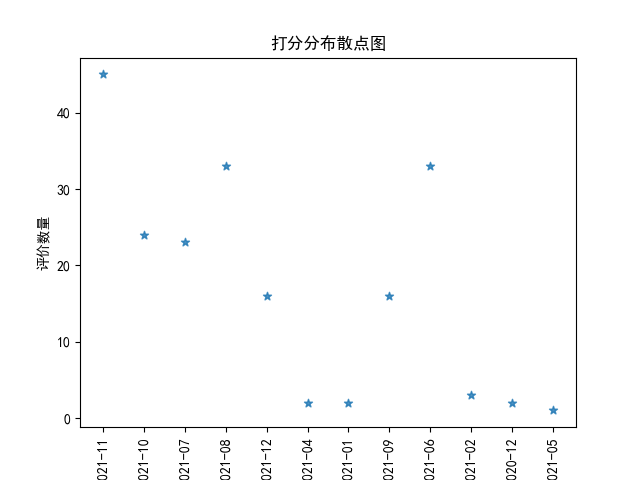
5.根据数据之间的关系,分析产品评价数量和时间之间的相关系数,画出散点图。
def 评价_时间_分布散点图(inputfile,output,title,columns): if inputfile.endswith('.xlsx') or inputfile.endswith('.xls'): data = pd.read_excel(inputfile) else: f = open(inputfile, encoding='utf8') data = pd.read_csv(f) timing = data['时间'] dic_ = {} for t in timing: print(t) t = t.split(' ')[0] t = t.split('-') month = t[0]+'-'+t[1] # 从具体时间中 提取出月份的数据 if month not in dic_.keys(): dic_[month] = 1 else: dic_[month] +=1 plt.scatter(dic_.keys(),dic_.values(),alpha=0.8,marker='o') plt.rcParams['font.sans-serif'] = 'simhei' plt.title(title) plt.xlabel('月份') plt.xticks(rotation='vertical') plt.ylabel('评价数量') plt.savefig(output) #plt.show()
运行结果如下:
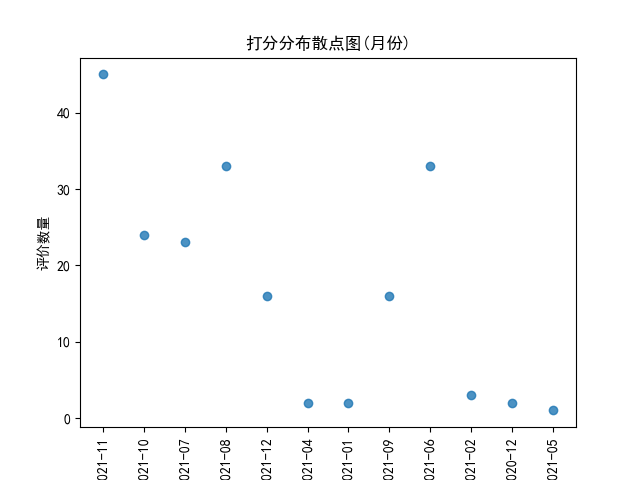
6.数据持久化

7.将以上各部分的代码汇总,附上完整程序代码
1 import requests 2 import json 3 import csv 4 import time 5 def jd_crawl_comment(item_id,pagenum): 6 7 list_ =[] 8 start_page = 1 9 end_page = pagenum 10 for p in range(start_page, end_page + 1): 11 print(p) 12 #productid = 3048505 13 url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv995&productId='+str(item_id)+'&score=0&sortType=5&page={}&pageSize=10&isShadowSku=0&fold=1' 14 url = url.format(p) 15 print(url) 16 #仿造请求头,骗过浏览器 17 headers = { 18 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36', 19 'Referer': 'https://item.jd.com/1981570.html' 20 } 21 #发起请求 22 #request = urllib.request.Request(url=url, headers=headers) 23 #得到响应 24 content = requests.get(url=url,headers=headers).content.decode('gbk') 25 #去掉多余得到json格式 26 content = content.strip('fetchJSON_comment98vv995();') 27 print(content) 28 obj = json.loads(content) 29 30 comments = obj['comments'] 31 print(comments) 32 fp = open('jingdong.txt', 'a', encoding='gbk') 33 for comment in comments: 34 # print(comment) 35 name = comment['referenceName'] 36 37 id = comment['id'] 38 39 con = comment['content'] 40 41 creationTime = comment['creationTime'] 42 43 img_url = comment['userImageUrl'] 44 score = comment['score'] 45 item = { 46 'name': name, 47 'id': id, 48 'con': con, 49 'time': creationTime, 50 'img_url': img_url, 51 } 52 string = str(item) 53 54 print(id, con, score, creationTime) 55 list_.append([id, con, score, creationTime]) 56 fp.write(string + '\n') 57 58 fp.close() 59 print('%s-page---finish' % p) 60 #print(list_) 61 time.sleep(5) 62 return list_ 63 def write_to_csv(list_,header,outputfile): 64 with open(outputfile, 'w', encoding='utf8', newline='') as f: 65 writer = csv.writer(f) 66 writer.writerow(header) 67 for l in list_: 68 writer.writerow(l) 69 f.close() 70 71 if __name__ == "__main__": 72 list_ = jd_crawl_comment(100009464799,pagenum=20) 73 outputfile = '京东商品评论数据.csv' 74 header = ['id','评论','打分','时间'] 75 write_to_csv(list_,header,outputfile) 76 77 import pandas as pd 78 from os import path 79 import jieba 80 import numpy as np 81 import matplotlib.pyplot as plt 82 from wordcloud import WordCloud 83 84 def wordcloud_京东_商品评论(filename,output): 85 # 生成词云的方法 86 f = open(filename,encoding='utf8') 87 data = pd.read_csv(f) 88 89 string = '' 90 comments = data['评论'] 91 for c in comments: 92 string += str(c) + '\n' 93 print(string) 94 cut = " ".join(jieba.cut(string)) 95 # stopwords remove 96 stopwords = ['其他', '很多', '不是', '非常', '这个', '那个', '真的', '可以', '没有'] 97 for word in stopwords: 98 cut = cut.replace(word,'') 99 d = path.dirname(__file__) 100 101 cloud = WordCloud( # 设置字体,不指定就会出现乱码 102 scale=4, 103 font_path=path.join(d, 'simhei.ttf'), 104 background_color='white', 105 max_words=2000, 106 max_font_size=1550, 107 min_font_size=2, 108 collocations=False, 109 relative_scaling=0.4, 110 prefer_horizontal=1) 111 wc = cloud.generate_from_text(cut) 112 wc.to_file(output) 113 114 115 116 117 def 词频_京东商品评论_柱状图(inputfile, topN): 118 # 柱状图显示词频前N 119 f = open(inputfile, encoding='utf8') 120 data = pd.read_csv(f) 121 122 string = '' 123 comments = data['评论'] 124 for c in comments: 125 string += str(c) + '\n' 126 print(string) 127 128 txt = string 129 words = jieba.lcut(txt) 130 dic_ = {} #创建字典 131 stopwords = ['其他', '很多', '不是', '非常', '这个', '那个', '真的', '可以', '没有',"就是","这里"] 132 133 for word in words: 134 if len(word) == 1: 135 continue 136 else: 137 rword = word 138 dic_[rword] = dic_.get(rword,0) + 1 139 for word in stopwords: 140 try: 141 del(dic_[word]) 142 except: 143 pass 144 items = list(dic_.items()) 145 # 排序 按词频率 146 items.sort(key=lambda x:x[1], reverse =True) 147 148 labels = [] 149 sizes = [] 150 n = topN 151 wordlist = list() 152 for i in range(n): 153 word,count = items[i] 154 labels.append(word) 155 sizes.append(count) 156 wordlist.append(word) 157 158 plt.rcParams['font.sans-serif'] = ['SimHei'] 159 plt.rcParams['axes.unicode_minus'] = False 160 f, ax = plt.subplots() 161 # 横向图 162 rect = ax.barh(range(len(sizes)), sizes, tick_label='') 163 plt.yticks(np.arange(len(labels)), labels) 164 plt.legend((rect,), ("前十关键词",)) 165 plt.savefig('前十关键词.jpg') 166 return labels,sizes 167 def 评价_时间_分布散点图(inputfile,output,title,columns): 168 if inputfile.endswith('.xlsx') or inputfile.endswith('.xls'): 169 data = pd.read_excel(inputfile) 170 else: 171 f = open(inputfile, encoding='utf8') 172 data = pd.read_csv(f) 173 timing = data['时间'] 174 dic_ = {} 175 for t in timing: 176 177 print(t) 178 t = t.split(' ')[0] 179 t = t.split('-') 180 month = t[0]+'-'+t[1] 181 # 从具体时间中 提取出月份的数据 182 if month not in dic_.keys(): 183 dic_[month] = 1 184 else: 185 dic_[month] +=1 186 plt.scatter(dic_.keys(),dic_.values(),alpha=0.8,marker='o') 187 plt.rcParams['font.sans-serif'] = 'simhei' 188 plt.title(title) 189 190 plt.xlabel('月份') 191 plt.xticks(rotation='vertical') 192 plt.ylabel('评价数量') 193 194 plt.savefig(output) 195 #plt.show() 196 197 if __name__=='__main__': 198 filename = '京东商品评论数据.csv' 199 评价_时间_分布散点图(filename, '打分分布散点图(月份)', '打分分布散点图(月份)', []) 200 wordcloud_京东_商品评论(filename, filename + '词云.jpg') 201 词频_京东商品评论_柱状图(filename, 10)
(五)、总结(10 分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号