会员
周边
新闻
博问
闪存
赞助商
YouClaw
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
wsilj
博客园
首页
新随笔
联系
订阅
管理
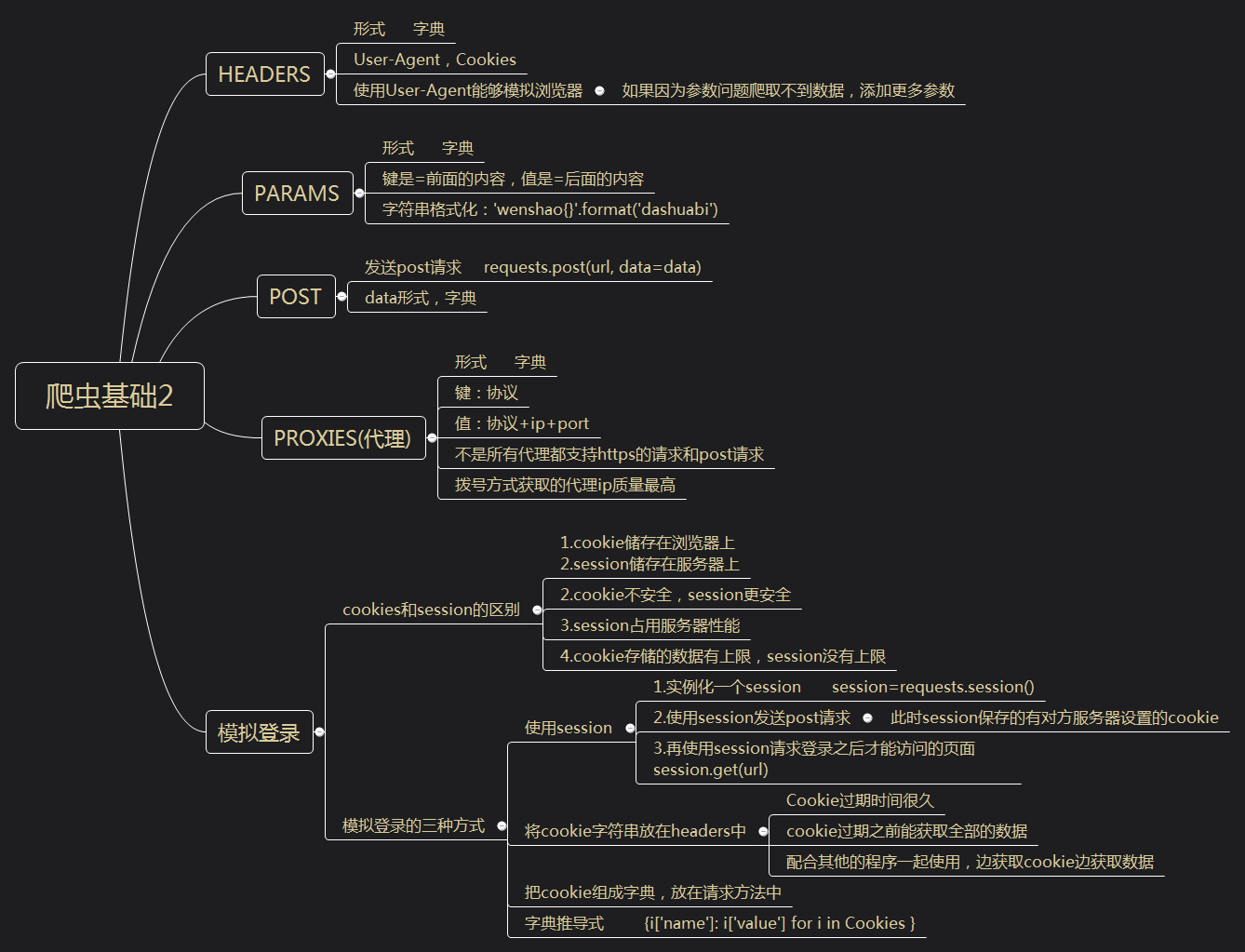
爬虫基础总结2
headers
形式 字典
User-Agent,Cookies
使用User-Agent能够模拟浏览器
如果因为参数问题爬取不到数据,添加更多参数
params
形式 字典
键是=前面的内容,值是=后面的内容
字符串格式化:'wenshao{}'.format('dashuabi')
post
发送post请求 requests.post(url, data=data)
data形式,字典
proxies(代理)
形式 字典
键:协议
值:协议+ip+port
不是所有代理都支持https的请求和post请求
拨号方式获取的代理ip质量最高
模拟登录
cookies和session的区别
1.cookie储存在浏览器上 2.session储存在服务器上
2.cookie不安全,session更安全
3.session占用服务器性能
4.cookie存储的数据有上限,session没有上限
模拟登录的三种方式
使用session
1.实例化一个session session=requests.session()
2.使用session发送post请求
此时session保存的有对方服务器设置的cookie
3.再使用session请求登录之后才能访问的页面 session.get(url)
将cookie字符串放在headers中
Cookie过期时间很久
cookie过期之前能获取全部的数据
配合其他的程序一起使用,边获取cookie边获取数据
把cookie组成字典,放在请求方法中
字典推导式 {i['name']: i['value'] for i in Cookies }
posted @
2020-04-20 10:13
wsilj
阅读(
98
) 评论(
0
)
收藏
举报
刷新页面
返回顶部
公告

 浙公网安备 33010602011771号
浙公网安备 33010602011771号