会员
周边
新闻
博问
闪存
赞助商
YouClaw
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
wsilj
博客园
首页
新随笔
联系
订阅
管理
爬虫基础总结1
html
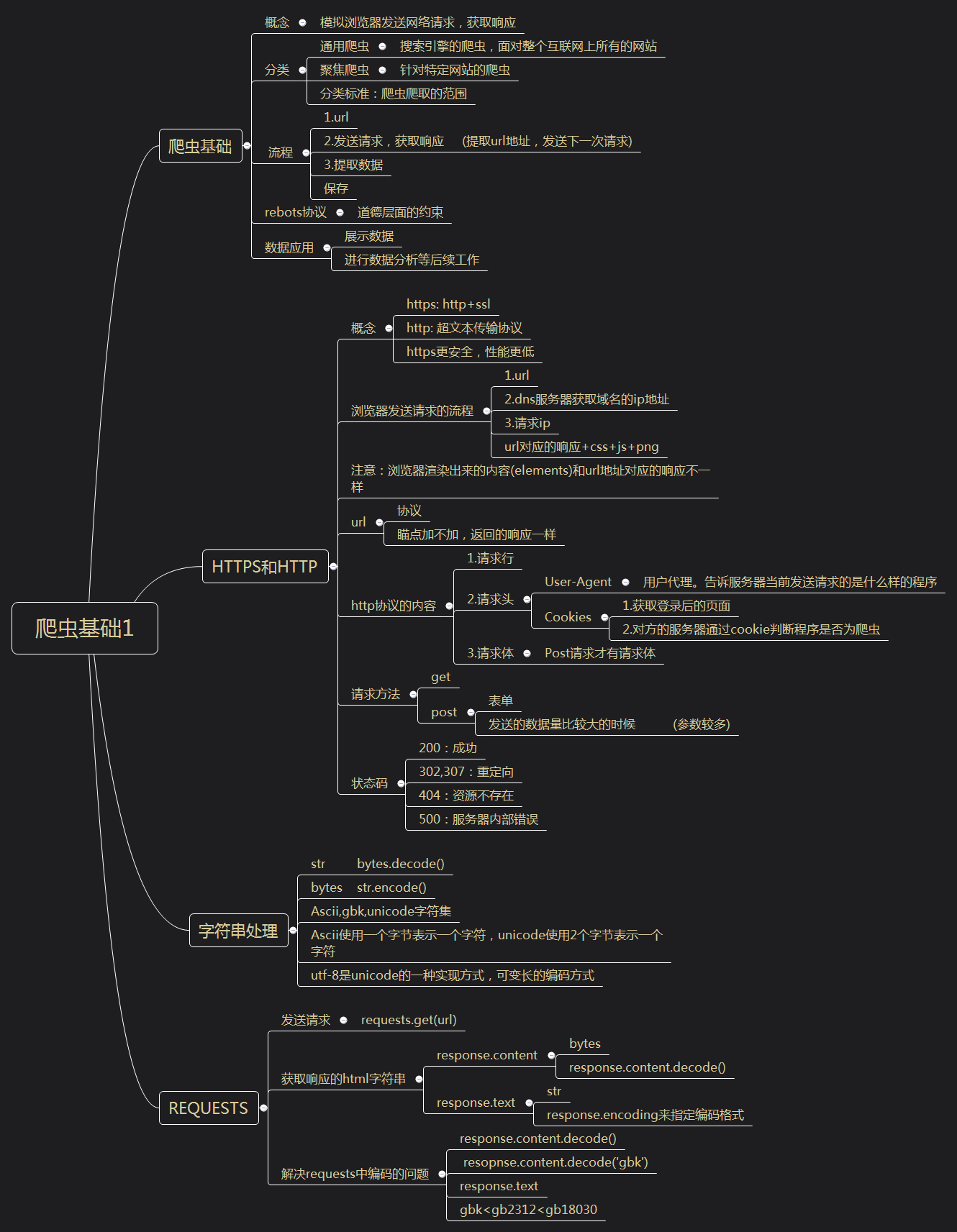
爬虫基础
概念
模拟浏览器发送网络请求,获取响应
分类
通用爬虫
搜索引擎的爬虫,面对整个互联网上所有的网站
聚焦爬虫
针对特定网站的爬虫
分类标准:爬虫爬取的范围
流程
1.url
2.发送请求,获取响应 (提取url地址,发送下一次请求)
3.提取数据
保存
rebots协议
道德层面的约束
数据应用
展示数据
进行数据分析等后续工作
HTTPS和HTTP
概念
https: http+ssl
http: 超文本传输协议
https更安全,性能更低
浏览器发送请求的流程
1.url
2.dns服务器获取域名的ip地址
3.请求ip
url对应的响应+css+js+png
注意:浏览器渲染出来的内容(elements)和url地址对应的响应不一样
url
协议
瞄点加不加,返回的响应一样
http协议的内容
1.请求行
2.请求头
User-Agent
用户代理。告诉服务器当前发送请求的是什么样的程序
Cookies
1.获取登录后的页面
2.对方的服务器通过cookie判断程序是否为爬虫
3.请求体
Post请求才有请求体
请求方法
get
post
表单
发送的数据量比较大的时候 (参数较多)
状态码
200:成功
302,307:重定向
404:资源不存在
500:服务器内部错误
字符串处理
str bytes.decode()
bytes str.encode()
Ascii,gbk,unicode字符集
Ascii使用一个字节表示一个字符,unicode使用2个字节表示一个字符
utf-8是unicode的一种实现方式,可变长的编码方式
requests
发送请求
requests.get(url)
获取响应的html字符串
response.content
bytes
response.content.decode()
response.text
str
response.encoding来指定编码格式
解决requests中编码的问题
response.content.decode()
resopnse.content.decode('gbk')
response.text
gbk<gb2312<gb18030
posted @
2020-04-20 00:25
wsilj
阅读(
162
) 评论(
0
)
收藏
举报
刷新页面
返回顶部
公告

 浙公网安备 33010602011771号
浙公网安备 33010602011771号