awk之基础学习
样例数据:
joho.wang Male 30 021-11111111111111111
lucy.yang Female 25 021-22222222222222
jack.chen Male 35 021-33333333333333
lily.gong Female 20 021-44444444444444
1、awk认为文件都是结构化的,也就是说都是由单词和各种空白字符组成的,“空白字符”包括空格,Tab,以及连续的t空格和Tab等。
每个非空白的部分叫做域,从左到右一次是第一个域、第二个域,等等。$1,$2分别用于表示域,$0则表示全部域。
所有操作以此文件为例:
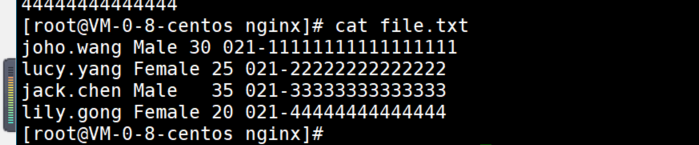
分析:
joho.wang Male 30 021-11111111111111111
拿第一行来说,默认以空白字符为分隔,joho.wang 为被分隔出来的第一个数据,所以为$1,同理,Male、30、021-11111111111111111分别为$2、$3、$4。
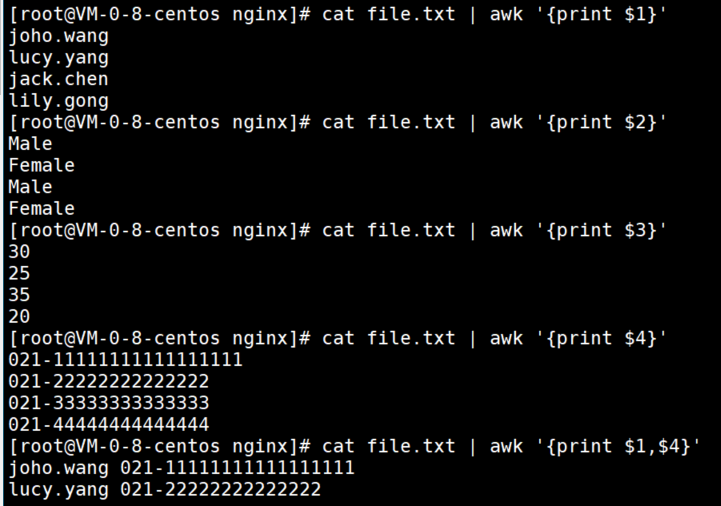
2、默认为“空白字符分隔”,当然我们在实际使用中,也可以指定字符分隔。使用-F进行指定。例如cat file.txt | awk -F . '{print $1}'
所有操作以此文件为例:


3、内部变量NF,可以计算分隔以后的元素个数,也就是分隔了几个元素。
所有操作以此文件为例:
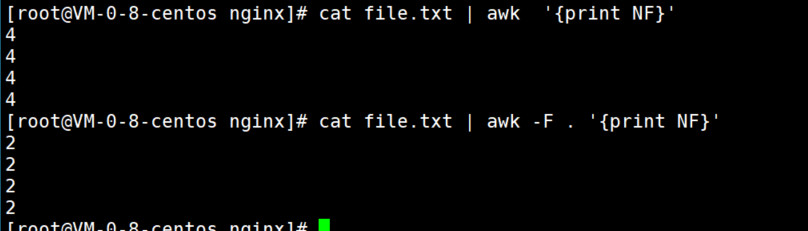
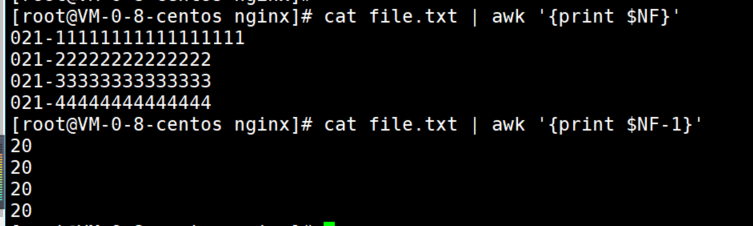
4、打印固定列。$F表示每一行的最后一列,倒是第二行可以用$F-1,以此类推。
所有操作以此文件为例:
5、截取字符串。substr截取字符串。用法:substr(指定域,第一个开始字符的位置,第二个结束的位置)。
所有操作以此文件为例:


6、打印文件的指定行。使用“NR==行数“打印,不存在(超过)的行,不显示结果。

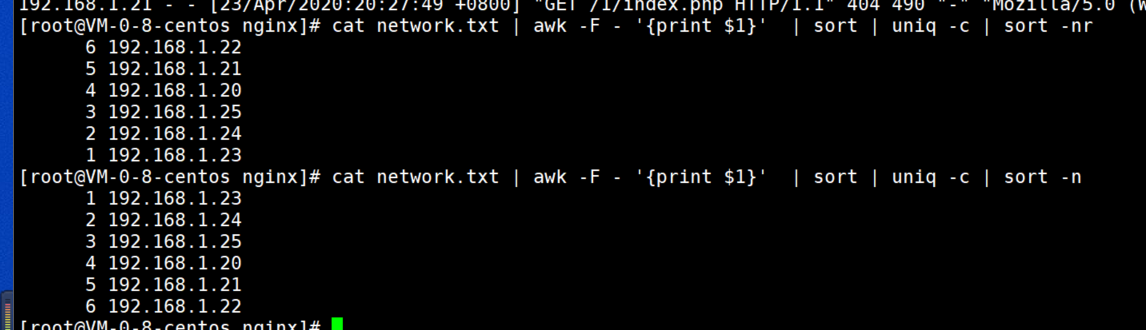
7.对统计的到的相关数据,进行次数从多到少排序,并且显示出现的次数。
cat network.txt | awk -F - '{print $1}' | sort | uniq -c | sort -nr
sort 排序
uniq -c 去重统计数量
sort -n 根据数量排序 (正序) -nr(倒序)
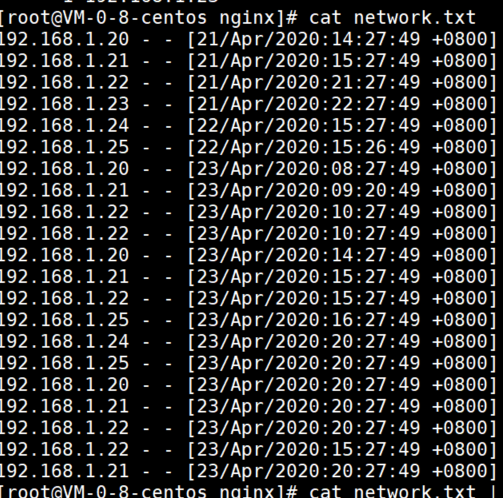
进阶:获取23号的ip访问的次数,并且统计的数据前面不允许有空格
cat network.txt | grep 23/Apr/2020 | awk -F '-' '{print $1}' | sort | uniq -c | sort -nr | awk -F ' ' '{print $1" "$2}'

8、统计文件的行数
awk 'END{print NR}' nowcoder.txt
9、awk列求和
awk '{a+=$6}END{print a}' nowcoder.txt
10、统计文件内相同字符串的个数
xargs -n1 过滤,-n ,排列多少个文字符串为一行
cat nowcoder.txt | xargs -n1 | sort | uniq -c | sort | awk '{print $2,$1}'


 浙公网安备 33010602011771号
浙公网安备 33010602011771号