SAS初学者笔记---003---利用数据步读取数据--INPUT语句的用法
@
在学习过程中,作者发现关于使用数据步读取数据这一问题主要涉及三大内容,也可以说是三个语句,分别是:
- CARDS,指从CARDS语句后指定的数据阵列中读取数据,其中需要使用INPUT语句在数据阵列中读取数据并输出到数据集。需要注意的是INPUT语句在程序内部的运行机制,如其循环读取的本质和在数据步中的运行顺序,以及如何利用行保持符 @ 、DO循环、OUTPUT等语句生成需要的数据集。DATALINES与CARDS同义。
- INFILE,指从程序外部文件中读取数据。此处要点在于INFILE语句的诸多选项对目标数据集的适配,如EXPANTABS等语句
- SET,指从sas软件记录的逻辑库中读取数据,也可以用INPUT代替。时常会遇到的使用场景是在原有的大型数据集中截取某些对象以及变量,并计算生成新的变量,以此组合成一个新的数据集。
此外,在导入的过程中需要叠加使用对于变量和对象的增删、合并、计算等语句,以做到用原始数据为蓝本,合成出我们想要的数据集。废话不多说,现在开始介绍以上三大内容。
从数据阵列中读取数据——使用INPUT语句
input语句读取数据阵列时的运行逻辑
如前文所讲到的,sas的数据步通常会创建三个项目,其中之一就是input buffer,这个项目的作用是暂时存储cards后的数据的。当整块sas数据步运行时,cards后的数据并不会像其他语句一样依次等待被执行(事实上它在这之前就被执行了),而是独立出来一片区域,供INPUT语句随时读取。
数据步的程序开始执行时,每个语句都将依次执行,当遇到input语句时,数据步便根据INPUT语句所指示的变量向input buffer 中读取相应的变量值,并默认将其输入到数据集中。
形象一点,我们把一行一行的数据阵列看做是一个个在排队就医的病人,input语句的执行就好比向病人询问病史,数据步其余的语句就好像是执行各种各样的检查,经过组合与推断以完善这一病人的信息,最后将所有的数据输入到数据集中,病人的每一个信息都被抽象化成了一个个的变量。
举个例子: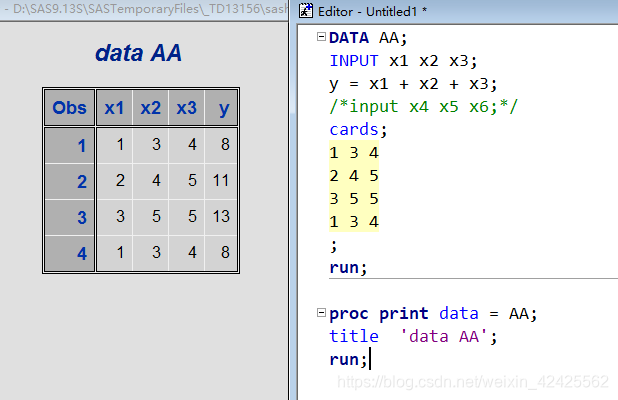
如上程序所示,程序执行的内容依次为:
1. 建立名称为AA的数据集
2. 将cards内的数据提取到input缓冲池中
3. input语句读取第一行的数据,读取到 x1 x2 x3这三个变量,并将变量写入第一个对象中
4. 根据 x1 x2 x3 这三个变量,生成y变量
5. 反复对每一行数据执行 3,4 步骤,直到缓冲池内数据全部被执行
以上步骤对数据步的执行逻辑进行了一个简单的介绍,事实上在项目中所书写的数据步远比以上代码复杂,但数据步本身的逻辑都是一致的。
INPUT的自由格式输入
自由格式输入是新人最早开始接受的数据输入方法,很好理解,举个例子:
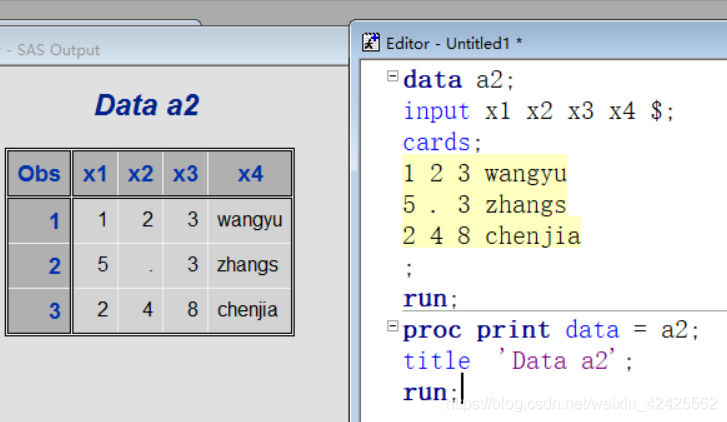
这一段代码中的INPUT语句后指示了4个变量名,其中$符号的作用是提示符号前的变量性质为字符串类型,否则INPUT语句默认以数值型(严格来说应该是浮点型)来读取数据。若遇到不符合规则的情况,读出的数据就会是缺失值,在数据集内用.表示。
简单来说INPUT的自由格式输入有以下特点:
INPUT语句按照变量顺序逐行读取数据阵列中的变量- 数据阵列(
CARDS后的数据)中的每一个数据都需要用空格符号隔开 - 在变量后放置
$符号, 以指示数据为字符串类型 - 当数据读取遇到空值或读取规则不符时 , 数据读取为空值, 在数据集中用
.表示 - 每个变量默认的最大读取长度是8. 每个中文字符占两个长度. 可以在程序中添加代码, 如:
LENGTH [VARIABLE] $ [NUMBER]
** 问题来了, 如果 INPUT后 指示的变量数少于/多于实际上数据阵列中的数据列数会发生什么 **
分析一下 , 懒得分析, 直接上程序 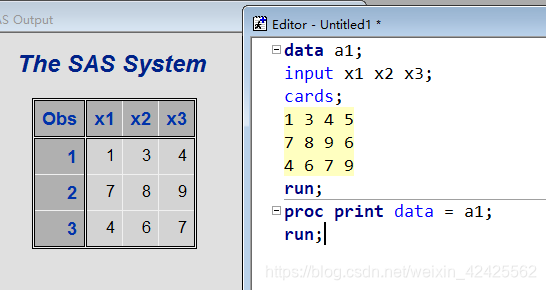

以上分别展示了指示变量数多于/少于数据阵列中数据列数的情况, 关于少于的情况比较好理解, 我就不多说了.
接下来着重讲述一下多于的情况:
INPUT语句在遇到变量不足的情况时会自动换行继续读取, 但是如果换行后依旧无法读取完毕时, 便会结束读取,直接跳出循环.
INPUT的列方式输入
常见于读取排列整齐的数据,如身份证号,程序日志等
使用起来很简单,举例如下:

可见,使用时只需要在变量后加上$ [start -end ]
行保持符的应用
在理解行保持符前,需要明白以下内容:
CARDS数据内部存在一种称为数据指针的东西 , 它的存在指示INPUT语句的起始读取位置INPUT语句在完整的读取变量后都会将待读取指针放到下一行- 某一行未能满足
INPUT一次完整的变量读取时,INPUT就会顺序读取下一行的数据直到读满此次的变量为止 - 在一轮程序结束后,程序会自动的将读取指针换行 , 以备下一轮的
INPUT语句读取数据
接下来介绍行保持符,如: @ , @@
简要介绍一下:
@的意义在于一段数据步中有两个INPUT语句时,在第一个INPUT语句末尾放置此保持符,便会使此次的变量读取不会换行,后一次的INPUT语句接着上一句INPUT语句读取结束后的位置进行读取, 当用在程序最后一个INPUT语句时,不起作用@@的意义在于用在程序的最后一个INPUT语句中 , 表示每轮程序运行后不换行,下一轮程序执行时,INPUT语句接着上一轮数据最后一个INPUT后读取数据
枯燥的概念让人难以理解,理解它的正确方式就是举个例子,如下:
![在这里插入图片描述]()
上述代码中未添加行保持符,程序在每次执行INPUT语句后进行了换行,结果就是读取了数据阵列中第一列的数据.
![hang bao chi fu 001]()
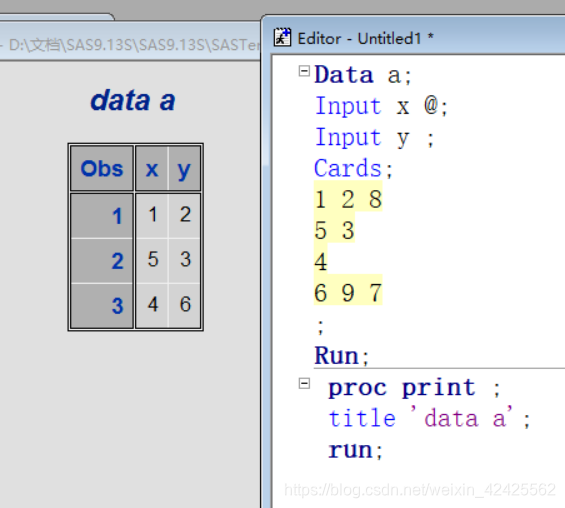
上述代码中, 第一个INPUT语句后添加了@, 于是读取的结果就变成了读取每一行前两个数据, 当数据读取到第三行4时,因为此行不满足程序读取完所有变量的要求, 于是第二个INPUT语句接着读取了下一行的首位数据.
![hang bao chi fu 002]()
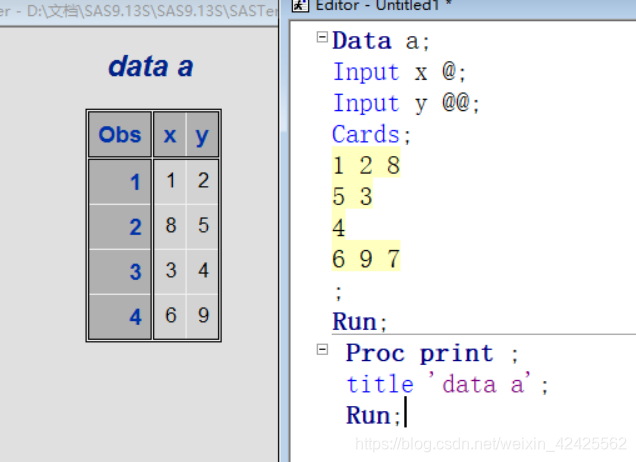
此段代码的两段INPUT都添加了行保持符, 此种代码达到的效果是两个INPUT语句接连读取数据阵列中的所有数据, 且读取时不进行换行. 当读取到最后一个数据时, 此时只满足第一个INPUT语句的读取, 而没有数据让第二个INPUT语句进行读取, 此时程序便停止了读取, 可以看到数据内部仍有最后一个数据没被读取.
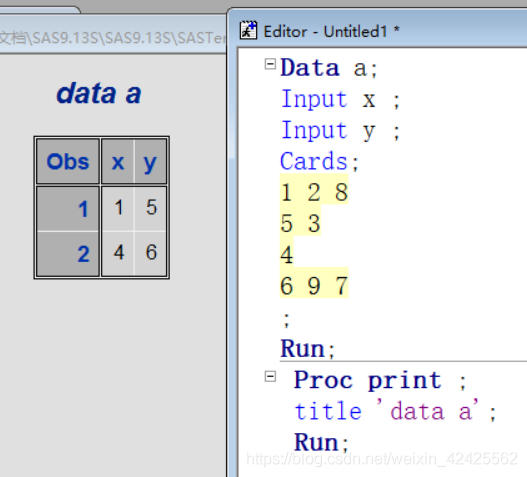
由于数据步读取数据的内容过多,接下来有关INFILE、SET语句以及其他知识点的内容放到下一博文阐述,这一篇文章就到这了,谢谢
时隔三月,我又把这一系列捡了起来,放心这一次绝对不会鸽,我发誓!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号