
C++整理笔记02(代码源件可私信)
9.数组@[TOC]
数组就是一个集合,里面存放了相同类型的数据元素
每个数据元素都是相同的数据类型;由连续的内存位置组成的。
(1)一维数组
①定义的三种方式:
数据类型 数组名{数组长度};
数据类型 数组名[数组长度] = {值1,值2…….};
数据类型 数组名[ ] = {值1,值2…….};
【注】数组元素的下标是从0开始索引的。
【注】数组名的命名规范与变量名命名规范一致,不要和变量重名。
【注】对于第二种定义方式来说,如果在初始化数据时没有全部填写,会用0来填补剩余的数据:

【注】定义数组的时候,必须有初始长度
②一维数组名称的用途
sizeof(arr) //可以统计整个数组在内存中的长度(即整个数组占用内存空间的大小);
cout<<arr<<endl; //可以获取数组在内存中的首地址。
【注】地址表示分为十六进制和十进制:

【注】数组名是常量,不可以进行赋值操作。
【注】若要在一个数组中找出最大值,思路:访问数组中的每个元素,如果这个元素比我认定的最大值要大,则更新最大值。

【注】表示数组起始下标和末尾下标:

③冒泡排序(参考代码见“指针”的[注])
对数组内的元素进行排序:
a.比较相邻的元素,如果第一个比第二个大,就交换他们两个。
b.对每一对相邻元素做同样的工作,执行完毕后,找到第一个最大值。
c.重复以上的步骤,每次比较次数-1,知道不需要比较。
【注】排序的总轮数 = 元素个数 - 1;
【注】每轮对比次数 = 元素个数 - 排序轮数 - 1
(2)二维数组
二维数组就是在一维数组上,多加一个维度。
①定义的四种方式:
数据类型 数组名[ 行数 ][ 列数 ];
数据类型 数组名[ 行数 ][ 列数 ] = { { 数据1,数据2 } , { 数据3,数据4 } };
数据类型 数组名[ 行数 ][ 列数 ] = { 数据1,数据2,数据3,数据4 };
数据类型 数组名[ ][ 列数 ] = { 数据1,数据2,数据3,数据4 };
【注】第二种更加直观,可以提高代码的可读性:


【注】打印时可使用嵌套的for循环进行打印:

②二维数组数组名
查看二维数组所占内存空间;获取二维数组首地址。

【注】因为arr[0][0]是一个数(元素),所以要看它的地址的话要在前面加一个取址符&。
10.函数10.函数@[TOC]
将一段经常使用的代码封装起来,减少重复代码。
一个较大的程序,一般分为若干个程序块,每个模块实现特定的功能。
(1)函数的定义
分为5个步骤:
①返回值类型:一个函数可以返回一个值
②函数名:给函数起个名称
③参数列表:使用该函数时,传入的数据
④函数体语句:函数内需要执行的语句
⑤return表达式:和返回值类型挂钩,函数执行完后,返回相应的数据
语法如下:

(2)函数的调用
使用定义好的函数
语法:函数名(参数)

【注】函数定义里小括号内称为形参,函数调用时传入的参数称为实参。
(3)值传递
指的是函数调用时实参将数值传给形参。
值传递时,如果形参发生,并不会影响实参。
【注】 
【注】返回值不需要时可以不写return;或者只写个return,后面不加东西。
(4)常见的函数样式
①无参无返;
②有参无返;
③无参有返;
④有参有返。
(5)函数的声明
告诉编译器函数名称以及如何调用函数。函数的实际主体可以单独定义。
【注】函数的声明可以有多次,但是函数的定义只能有一次。
(6)函数的分文件编写
让代码结构更加清晰。
函数分文件编写一般有四个步骤:
①创建后缀名为.h的头文件
②创建后缀名为.cpp的源文件
③在头文件中写函数的声明
④在源文件中写函数的定义
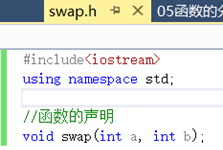
【注】要注意在创建的头文件中写上框架。
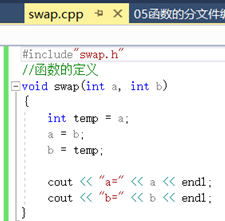
【注】在创建的源文件中要加上include“swap.h”
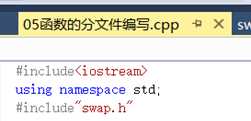
【注】在原本的原文件中加上include“swap.h”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号