redis哨兵
什么是哨兵?
保护redis主从集群,正常运转,当主库挂掉之后,自动的在从库中挑选新的主库,进行同步
redis命令整理
官网地址:http://redisdoc.com/ redis-cli info #查看redis数据库信息 redis-cli info replication #查看redis的复制授权信息 redis-cli info sentinel #查看redis的哨兵信息
创建一个主节点,两个从节点
主节点master的redis-6379.conf
port 6379 daemonize yes logfile "6379.log" dbfilename "dump-6379.rdb" dir "/var/redis/data/"
从节点slave的redis-6380.conf
port 6380 daemonize yes logfile "6380.log" dbfilename "dump-6380.rdb" dir "/var/redis/data/" slaveof 127.0.0.1 6379 // 从属主节点
从节点slave的redis-6381.conf
port 6381 daemonize yes logfile "6380.log" dbfilename "dump-6380.rdb" dir "/var/redis/data/" slaveof 127.0.0.1 6379 // 从属主节点
启动redis主节点
redis-server /etc/redis-6379.conf
测试redis主节点是否通信
redis-cli ping
启动两slave节点
总体redis配置文件如下,6379为master,6380和6381为slave
-rw-r--r-- 1 root root 145 Nov 7 17:44 /etc/redis-6379.conf #这个为主,port是6379 -rw-r--r-- 1 root root 93 Nov 7 17:42 /etc/redis-6380.conf # 这个是从,port6380,并且得加上新的参数slaveof -rw-r--r-- 1 root root 115 Nov 7 17:42 /etc/redis-6381.conf # 这个是从,port6381,并且得加上新的参数slaveof
redis-6380.conf slave配置文件详解,6381端口的配置文件,仅仅和6380端口不一样
port 6380 daemonize yes logfile "6379.log" dbfilename "dump-6379.rdb" dir "/var/redis/data" # Generated by CONFIG REWRITE slaveof 127.0.0.1 6379
启动slave从节点的redis服务
[root@master 192.168.119.10 ~]$redis-server /etc/redis-6380.conf [root@master 192.168.119.10 ~]$redis-server /etc/redis-6381.conf
验证从节点的redis服务
[root@master ~]$redis-cli -p 6380 ping PONG [root@master ~]$redis-cli -p 6381 ping PONG
确定主从关系
在主节点上查看主从通信关系
[root@master ~]# redis-cli -p 6379 info replication # Replication role:master connected_slaves:2 slave0:ip=192.168.119.10,port=6380,state=online,offset=407,lag=0 slave1:ip=192.168.119.10,port=6381,state=online,offset=407,lag=0 master_repl_offset:407 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:2 repl_backlog_histlen:406
在从节点上查看主从关系(6380、6379)
[root@slave 192.168.119.11 ~]$redis-cli -p 6380 info replication # Replication role:slave master_host:192.168.119.10 master_port:6379 master_link_status:up master_last_io_seconds_ago:3 master_sync_in_progress:0 slave_repl_offset:505 slave_priority:100 slave_read_only:1 connected_slaves:0 master_repl_offset:0 repl_backlog_active:0 repl_backlog_size:1048576 repl_backlog_first_byte_offset:0 repl_backlog_histlen:0
此时可以在master上写入数据,在slave上查看数据,此时主从复制配置完成
开始配置Redis Sentinel
实验的环境是单独一台linux,192.168.119.10
[root@master tmp]# ll /etc/redis-* -rw-r--r-- 1 root root 145 Nov 7 17:44 /etc/redis-6379.conf -rw-r--r-- 1 root root 93 Nov 7 17:42 /etc/redis-6380.conf -rw-r--r-- 1 root root 115 Nov 7 17:42 /etc/redis-6381.conf -rw-r--r-- 1 root root 556 Nov 7 17:42 /etc/redis-sentinel-26379.conf -rw-r--r-- 1 root root 556 Nov 7 17:42 /etc/redis-sentinel-26380.conf -rw-r--r-- 1 root root 556 Nov 7 17:42 /etc/redis-sentinel-26381.conf
redis-sentinel-26379.conf配置文件写入如下信息
// Sentinel节点的端口 port 26379 dir /var/redis/data/ logfile "26379.log" // 当前Sentinel节点监控 192.168.119.10:6379 这个主节点 // 2代表判断主节点失败至少需要2个Sentinel节点节点同意 // mymaster是主节点的别名 sentinel monitor mymaster 192.168.119.10 6379 2 //每个Sentinel节点都要定期PING命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过30000毫秒30s且没有回复,则判定不可达 sentinel down-after-milliseconds mymaster 30000 //当Sentinel节点集合对主节点故障判定达成一致时,Sentinel领导者节点会做故障转移操作,选出新的主节点,
原来的从节点会向新的主节点发起复制操作,限制每次向新的主节点发起复制操作的从节点个数为1 sentinel parallel-syncs mymaster 1 //故障转移超时时间为180000毫秒 sentinel failover-timeout mymaster 180000
redis-sentinel-26380.conf和redis-sentinel-26381.conf的配置仅仅差异是port(端口)的不同。
然后启动三个sentinel哨兵
redis-sentinel /etc/redis-sentinel-26379.conf redis-sentinel /etc/redis-sentinel-26380.conf redis-sentinel /etc/redis-sentinel-26381.conf
监控拓扑图
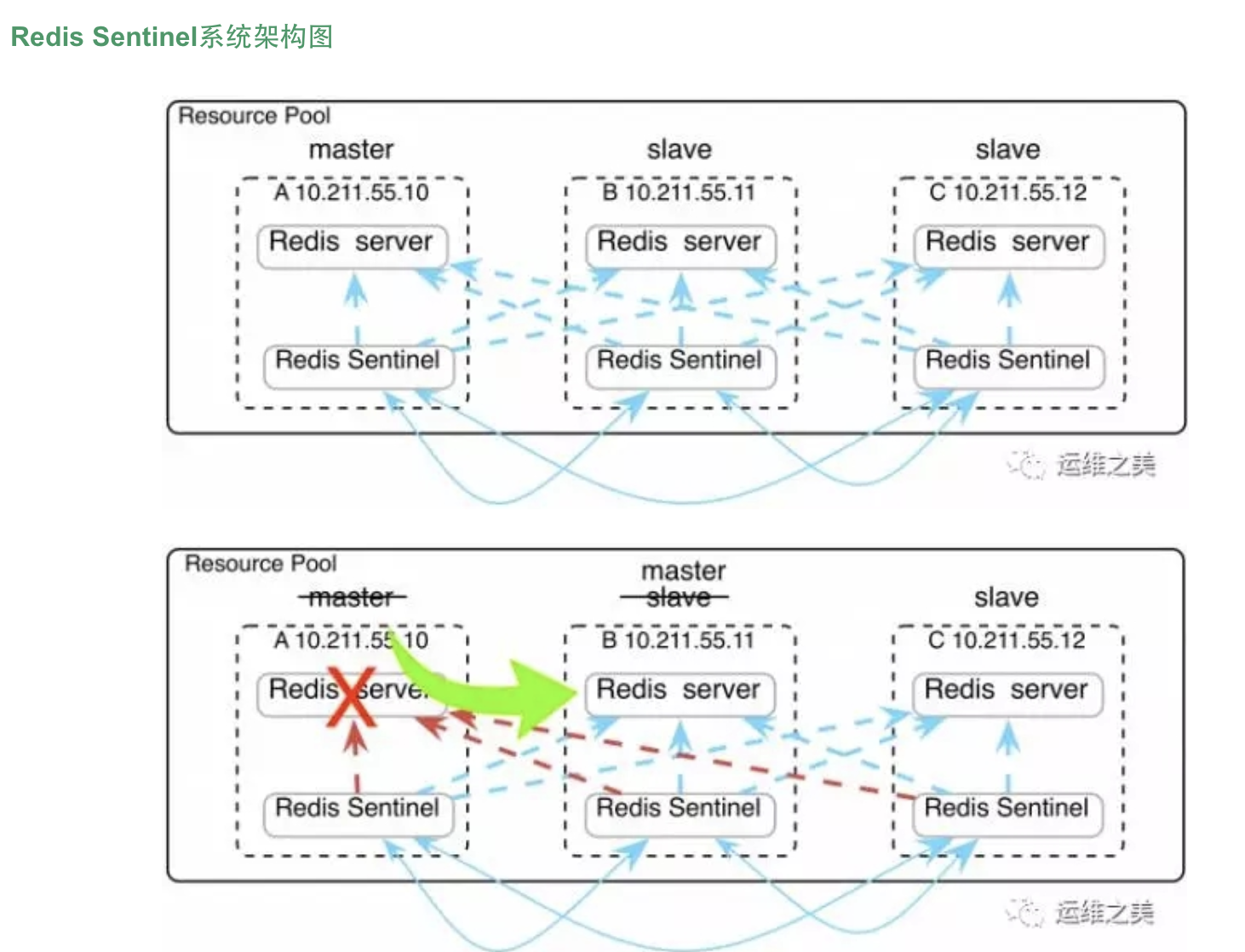
此时查看哨兵是否成功通信
[root@master ~]# redis-cli -p 26379 info sentinel # Sentinel sentinel_masters:1 sentinel_tilt:0 sentinel_running_scripts:0 sentinel_scripts_queue_length:0 sentinel_simulate_failure_flags:0 master0:name=mymaster,status=ok,address=192.168.119.10:6379,slaves=2,sentinels=3
#看到最后一条信息正确即成功了哨兵,哨兵主节点名字叫做mymaster,状态ok,监控地址是192.168.119.10:6379,有两个从节点,3个哨兵
redis高可用故障实验
大致思路
- 杀掉主节点的redis进程6379端口,观察从节点是否会进行新的master选举,进行切换
- 重新恢复旧的“master”节点,查看此时的redis身份
首先查看三个redis的进程状态
ps -ef|grep redis
检查三个节点的复制身份状态
第一个
[root@master tmp]# redis-cli -p 6381 info replication # Replication role:slave master_host:127.0.0.1 master_port:6380
第二个
[root@master tmp]# redis-cli -p 6380 info replication # Replication role:master connected_slaves:2 slave0:ip=127.0.0.1,port=6381,state=online,offset=54386,lag=0 slave1:ip=127.0.0.1,port=6379,state=online,offset=54253,lag=0
第三个
[root@master tmp]# redis-cli -p 6379 info replication # Replication role:slave master_host:127.0.0.1 master_port:6380
此时,干掉master!!!然后等待其他两个节点是否能自动被哨兵sentienl,切换为master节点
ps -ef|grep 6380 #干掉master进程
此时查看两个slave的状态
精髓就是查看一个参数
master_link_down_since_seconds:13
稍等片刻之后,发现slave节点成为master节点!!
[root@master tmp]# redis-cli -p 6379 info replication # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6381,state=online,offset=41814,lag=1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号