

Hive day1内容理解
Hive(数据仓库建模工具之一)
简介:
Hive本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据存储,说白了hive可以理解为一个将SQL转换为MapReduce的任务的工具,甚至更近一步说hive就是一个MapReduce客户端。
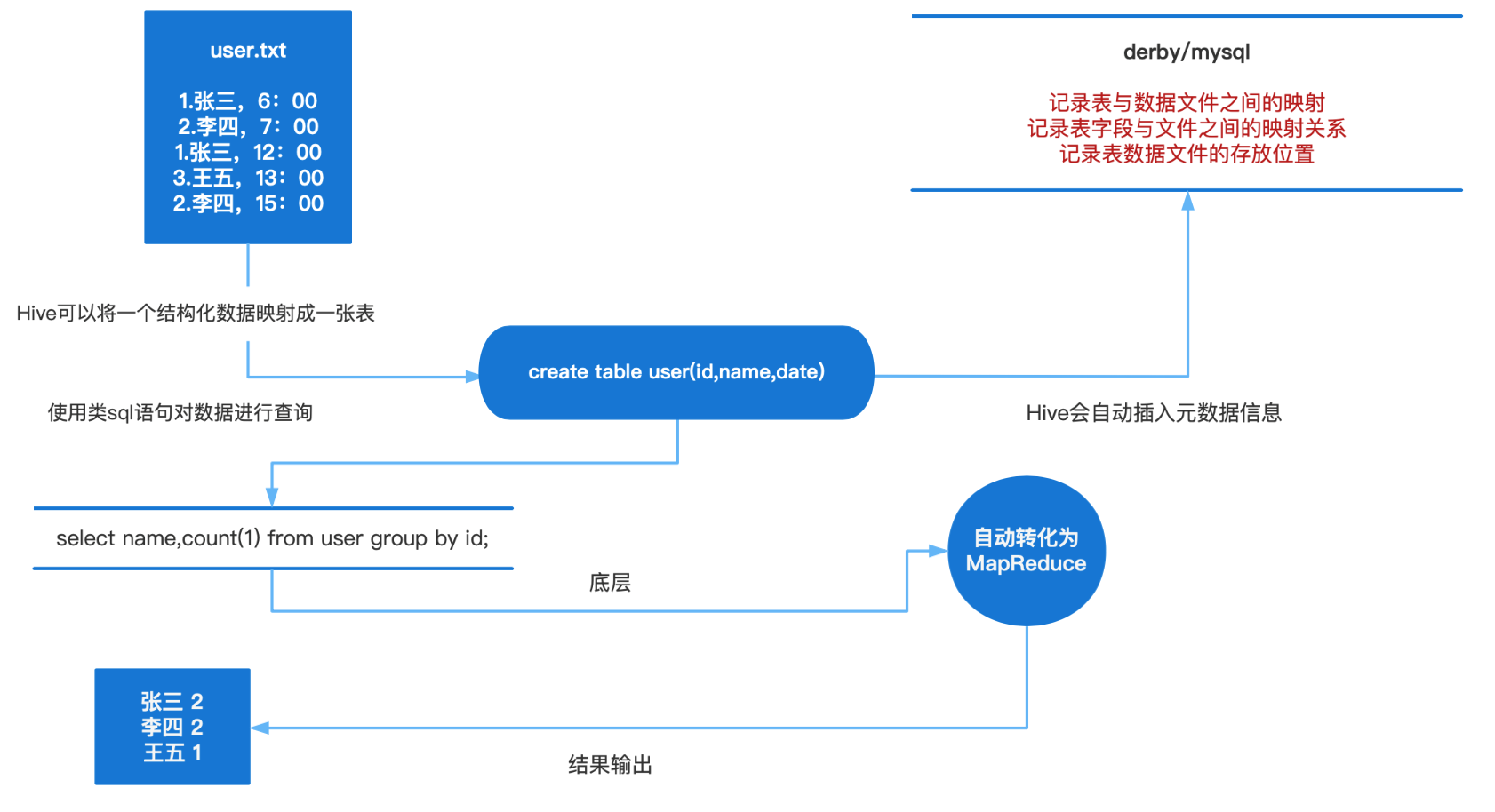
思考:计算文件user.txt中张三出现几次,使用mapreduce怎么写,然后再比照下图的hive实现过程
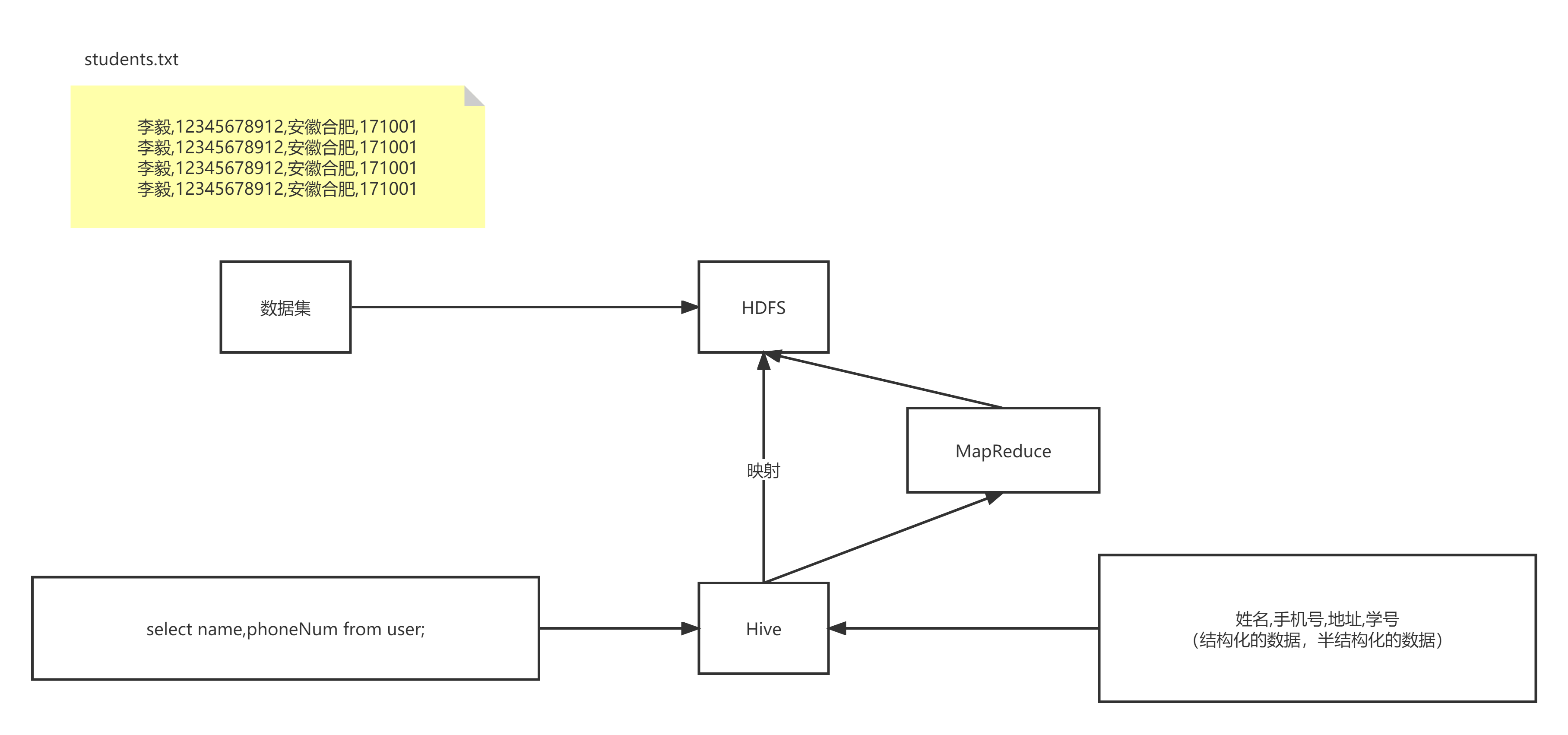
mapreduce是不会主动输出到文件保存的,是直接返回给客户端的;需要手动保存
数据库:
关系数据库本质上是一个二元关系,说的简单一些,就是一个二维表格,对普通人来说,最简单的理解就是一个Excel表格。这种数据库类型,具有结构化程度高,独立性强,冗余度低等等优点,一下子就促进了计算机的发展。
操作型数据库和分析型数据库
随着关系数据库理论的提出,诞生了一系列经典的RDBMS,如Oracle,MySQL,SQL Server等。这些RDBMS被成功推向市场,并为社会信息化的发展做出的重大贡献。然而随着数据库使用范围的不断扩大,它被逐步划分为两大基本类型:
操作型数据库
主要用于业务支撑。一个公司往往会使用并维护若干个操作型数据库,这些数据库保存着公司的日常操作数据,比如商品购买、酒店预订、学生成绩录入等;
分析型数据库
主要用于历史数据分析。这类数据库作为公司的单独数据存储,负责利用历史数据对公司各主题域进行统计分析;
不能构造一个同样适用于操作和分析的统一数据库,因为他们两个会抢资源,而且它们有太多不同
操作型数据库和分析型数据库的区别:
- 而对于分析型数据库来说,因为汇总数据比较稳定不会发生改变,而且其计算量也比较大(因为时间跨度大),因此它的汇总数据可考虑事先计算好,以避免重复计算。
数据仓库概述
数据仓库之父比尔·恩门,1991年提出
数据仓库就是为了解决数据库不能解决的问题而提出的。
OLTP和OLAP
OLTP(OnLine Transaction Processing 联机事务处理)
OLAP(Online Analysis Processing 联机分析处理)
这个东西又是上面发明关系型数据库的科德发明的。OLAP略有复杂,但这里我举一个简单的例子,大家就很容易理解了。 比如说,沃尔玛超市的数据库里有很多张表格,记录着各个商品的交易记录。超市里销售一种运动饮料,我们不妨称之为红牛。数据库中有一张表A,记录了红牛在一年的各个月份的销售额;
还有一张表B,记录了红牛每个月在美国各个州的销售额:;甚至还有一张表C,记录了这家饮料公司在每个州对红牛饮料的宣传资金投入;甚至后来沃尔玛又从国家气象局拿到了美国各个州的一年365天每天的天气表D。
好,最后问题来了,请根据以上数据分析红牛在宣传资金不超过三百万的情况下,什么季节,什么天气,美国哪个州最好卖?
凭借我们的经验,可能会得出,夏季的晴天,在美国的佛罗里达,最好卖,而且宣传资金投入越高销售额应该也会高。可能这样的结论是正确的,但决策者想要看到的是确凿的数据结论,而不是“可能”这样的字眼。 科学是不相信直觉的,如果我们人工进行手动分析,会发现这个要考虑的维度实在太多了,根本无法下手,何况这才四五个维度,要是更多了怎么办?
OLAP就是为了解决这样的问题诞生的,但糟糕的是,传统数据库是无法满足OLAP所需要的数据信息的。
数据仓库概念
概述
数据库的大规模应用,使得信息行业的数据爆炸式的增长,为了研究数据之间的关系,挖掘数据隐藏的价值,人们越来越多的需要使用OLAP来为决策者进行分析,探究一些深层次的关系和信息。但很显然,不同的数据库之间根本做不到数据共享,就算同一家数据库公司,数据库之间的集成也存在非常大的挑战(最主要的问题是庞大的数据如何有效合并、存储)。
1988年,为解决企业的数据集成问题,IBM的两位研究员(Barry Devlin和Paul Murphy)创造性地提出了一个新的术语:数据仓库(Data Warehouse)。看到这里读者朋友们可能要问了,然后呢?然后…然后就没然后了。就在这个创世纪的术语诞生了之后,IBM就哑火了,只是将这个名词作为市场宣传的花哨概念,并没有在技术领域有什么实质性的研究和突破。
对于数据仓库的概念我们可以从两个层次予以理解:
首先,数据仓库用于支持决策,面向分析型数据处理,它不同于企业现有的操作型数据库; 其次,数据仓库是对多个异构的数据源有效集成,集成后按照主题进行了重组,并包含历史数据,而且存放在数据仓库中的数据一般不再修改。
我们可以不用管这个定义,简单的理解,其实就是我们为了进行OLAP,把分布在各个散落独立的数据库孤岛整合在了一个数据结构里面,称之为数据仓库。
这个数据仓库在技术上是怎么建立的读者朋友们并不需要关心,但是我们要知道,原来各个数据孤岛中的数据,可能会在物理位置(比如沃尔玛在各个州可能都有自己的数据中心)、存储格式(比如月份是数值类型,但但天气可能是字符类型)、商业平台(不同数据库可能用的是Oracle数据库,有的是微软SQL Server数据库)、编写的语言(Java或者Scale等)等等各个方面完全不同,数据仓库要做的工作就是将他们按照所需要的格式提取出来,再进行必要的转换(统一数据格式)、清洗(去掉无效或者不需要的数据)等,最后装载进数据仓库(我们所说的ETL工具就是用来干这个的)。这样,拿我们上面红牛的例子来说,所有的信息就统一放在了数据仓库中了。
自从数据仓库出现之后,信息产业就开始从以关系型数据库为基础的运营式系统慢慢向决策支持系统发展。这个决策支持系统,其实就是我们现在说的商务智能(Business Intelligence)即BI。
可以这么说,数据仓库为OLAP解决了数据来源问题,数据仓库和OLAP互相促进发展,进一步驱动了商务智能的成熟,但真正将商务智能赋予“智能”的,正是我们现在热谈的下一代技术:数据挖掘
数据仓库特点(重点)
面向主题特性是数据仓库和操作型数据库的根本区别。
集成性是指数据仓库会将不同源数据库中的数据汇总到一起;
数据仓库内的信息并不只是反映企业当前的状态,而是记录了从过去某一时点到当前各个阶段的信息。通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
数据仓库的趋势

数据仓库的发展
从公司业务出发,是分析的宏观领域,比如供应商主题、商品主题、客户主题和仓库主题
2)为多维数据分析服务
数据报表;数据立方体,上卷、下钻、切片、旋转等分析功能。
3)反范式数据模型

数据仓库架构

ODS里面建很多表,但是数据是存放实际上在hdfs上的
DWD数据明细层,构建事实表和维度表(星型模型和雪花模型)
DWS指标明细层 指标出来后可以使用机器学习
ADS数据集市层(数据应用层)
上面四个每个都可以看做为一个库
hive包含在整个数据仓库中
数据仓库是数据中台的一小部分,数据源和检验数据等都是在数据中台中
Hive基于HDFS存储数据,基于mapreduce计算,源数据存放在mysql中
什么是Hive?(面试题)
hive理解
2、Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop的yarn上的执行。
3、Hive的表其实就是HDFS的目录,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
4、Hive相当于hadoop的客户端工具,部署时不一定放在集群管理节点中,可以放在某个节点上。
可以将Hive理解为一个:将 SQL 转换为 MapReduce 任务的工具
![]()
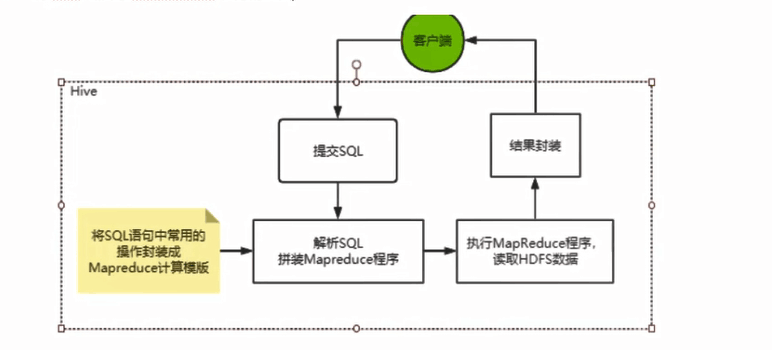
所以Hive不存储数据,自己也没有任何计算功能,只是相当于类SQL语句与Hadoop文件之间的一个解释器。他本质上只是一个对HDFS上的文件进行索引与计算的工具。他需要依赖Hadoop的Yarn来进行资源分配,也需要Hadoop的MapReduce来提供计算支持。后面我们就会知道,hive在进行数据计算时,不仅可以用MapReduce来支持,也可以集合其他更灵活,更高效的大数据计算框架(比如spark Spark SQL)
为什么使用Hive?
如果直接使用hadoop的话,人员学习成本太高,项目要求周期太短,MapReduce实现复杂查询逻辑开发难度太大。如果使用hive的话,可以操作接口采用类SQL语法,提高开发能力,免去了写MapReduce,减少开发人员学习成本,功能扩展很方便(比如:开窗函数)。
Hive的特点:
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务
2、延伸性
Hive支持自定义函数,用户可以根据自己的需求来实现自己的函数
3、容错
Hive的优缺点:
优点:
2、避免了去写MapReduce,减少开发人员的学习成本
3、Hive的延迟性比较高,因此Hive常用于数据分析,适用于对实时性要求不高的场合
4、Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高。(不断地开关JVM虚拟机)
5、Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点:
(1)迭代式算法无法表达 (反复调用,mr之间独立,只有一个map一个reduce,反复开关)
(2)数据挖掘方面不擅长
2、Hive 的效率比较低
(1)Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
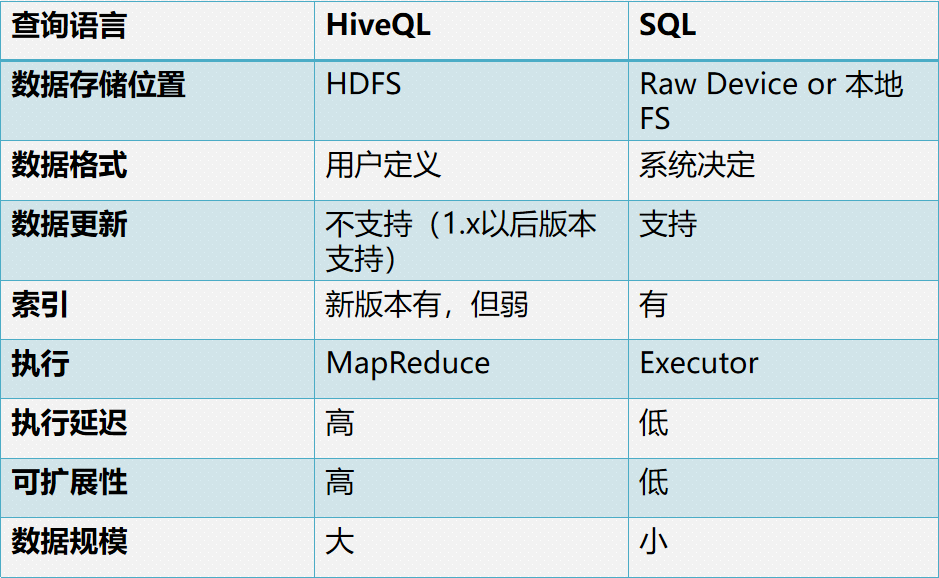
hive和传统数据库对比
Hive应用场景
日志分析:大部分互联网公司使用hive进行日志分析,如百度、淘宝等。
统计一个网站一个时间段内的pv,uv,SKU,SPU
多维度数据分析
海量结构化数据离线分析
构建数据仓库
PV(Page View)访问量, 即页面浏览量或点击量,衡量网站用户访问的网页数量;在一定统计周期内用户每打开或刷新一个页面就记录1次,多次打开或刷新同一页面则浏览量累计。 UV(Unique Visitor)独立访客,统计1天内访问某站点的用户数(以cookie为依据);访问网站的一台电脑客户端为一个访客。可以理解成访问某网站的电脑的数量。
网站判断来访电脑的身份是通过来访电脑的cookies实现的。如果更换了IP后但不清除cookies,再访问相同网站,该网站的统计中UV数是不变的。如果用户不保存cookies访问、清除了cookies或者更换设备访问,
计数会加1。00:00-24:00内相同的客户端多次访问只计为1个访客。
SPU全称Standard Product Unit (标准化产品单元)。译为:最小包装单元;SPU可以直接认为是很多个产品打包组成的一个新物品,有更多的新特性和更多的形态。
SKU不同于SPU,它可以认为就是一个很简单的物品。而这些个简单的物品打包组合就是SPU,比如,现在有5个iPhone(SKU),如果5个为一个生产最小单位,那么这5个iPhone就是组合打包产品(SPU)
Hive架构
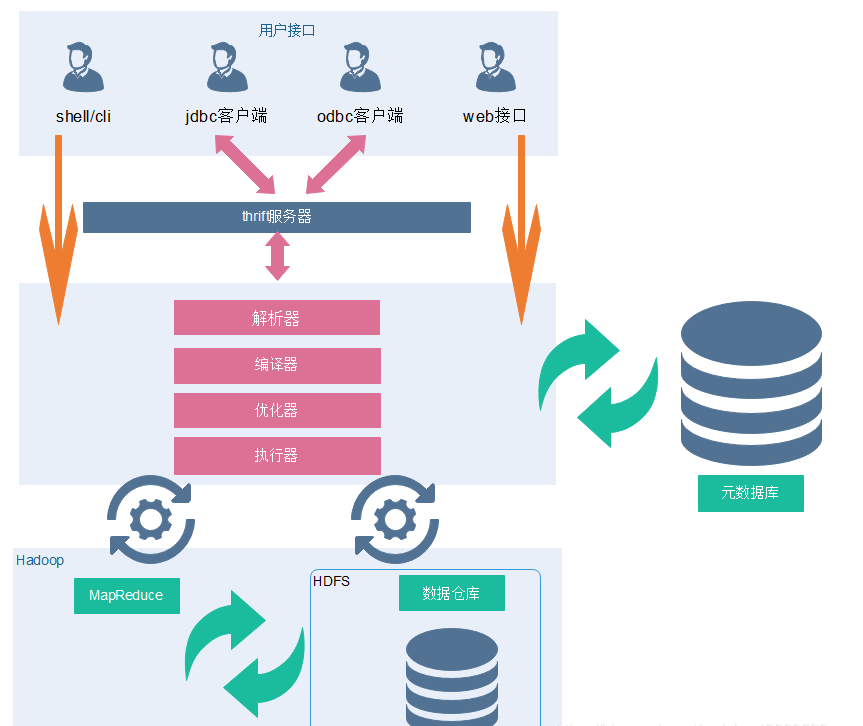
Hive允许client连接的方式有三个CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问 hive)。JDBC访问时中间件Thrift软件框架,跨语言服务开发。DDL DQL DML,整体仿写一套SQL语句。
1)client–需要下载安装包
2)JDBC/ODBC 也可以连接到Hive 现在主流都在倡导第二种 HiveServer2/beeline 做基于用户名和密码安全的一个校验
3)Web Gui hive给我们提供了一套简单的web页面 我们可以通过这套web页面访问hive 做的太简陋了
元数据包括表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是 外部表)、表的数据所在目录等。
一般需要借助于其他的数据载体(数据库)
主要用于存放数据库的建表语句等信息
推荐使用Mysql数据库存放数据
连接数据库需要提供:uri username password driver
3 Driver(面试题:sql语句是如何转化成MR任务的?)
元数据存储在数据库中,默认存在自带的derby数据库(单用户局限性)中,推荐使用Mysql进行存储。
1) 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完 成,比如ANTLR;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
3) 优化器(Query Optimizer):对逻辑执行计划进行优化。(重复的,不必要的语句优化)
4 数据处理
Hive的数据存储在HDFS中,计算由MapReduce完成。HDFS和MapReduce是源码级别上的整合,两者结合最佳。解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号