关于intern的一切
一、intern与字符串比较
前置知识
字符串常量池
在Java语言中有8种基本数据类型和一种比较特殊的类型String。这些类型为了使它们在运行过程中速度更快、更节省内存,都提供了一种常量池的概念。
常量池就类似一个Java系统级别提供的缓存。8种基本数据类型的常量池都是系统协调的,String类型的常量池比较特殊,它的主要使用方法有两种:
• 直接使用双引号声明出来的String对象会直接存储在常量池中。
• 如果不是用双引号声明的String对象,可以使用String提供的intern()方法。
Java 6及以前,字符串常量池存放在方法区的永久代。Java 7及以后将字符串常量池的位置调整到Java堆内。
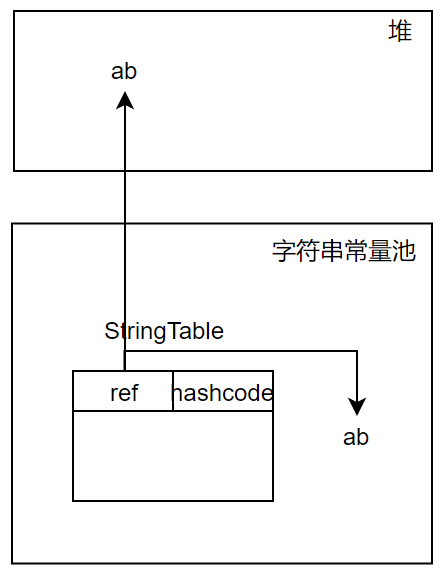
字符串常量池除了有专门的内存区域存储字符串外,还提供了一个StringTable,主要用于快速检索字符串常量池中是否包含某个字符串,它的结构类似于HashTable,每个元素都是key-value结构,里面保存了字符串的引用。注意:这里说StringTable的每条记录中保存了字符串的引用,但没说这个引用指向的是池中的字符串还是堆中的字符串,实际上两者皆有可能!——这点非常重要,是判断intern()返回的引用与字符串比较结果的关键,详情见下文分解。
intern与字符串比较
注:1.为方便描述,下文中的“字符串常量池”简称“池”;2.对于语句“String s = new String("ab");”,虽然变量名s与new String("ab")对象在内存中的引用并非一回事,但为方便描述,下文中的类似描述“引用x”均为代指字符串对象在内存中的引用。
intern()返回字符串对象在池(StringTable)中的引用,在java文档中这样介绍这个方法:
当调用intern方法时,如果池中已经包含一个字符串,该字符串与equals(object)方法确定的string对象相等,则返回池中的字符串。否则,将此字符串对象添加到池中,并返回对此字符串对象的引用。(When the intern method is invoked, if the pool already contains a string equal to this String object as determined by the equals(Object) method, then the string from the pool is returned. Otherwise, this String object is added to the pool and a reference to this String object is returned.)
注意:该文档中对intern方法的描述实际上是不准确的(或者说是过时的),前半句没啥问题,返回池中的字符串就是返回这个字符串的引用;后半句有问题,因为调用intern方法,将字符串添加到池中,这仅仅是在jdk6及以前版本JVM才会干的事情,对于这点下文有具体说明。
intern()返回的引用与字符串比较,关键是看intern()返回的引用指向哪里的字符串,而看引用指向哪里首先要看在调用intern()前字符串在哪里,据此可分为两种情况:
• 如果字符串在池中(可能只在池中,也可能既在池中也在堆中),那么intern()返回的引用一定指向池中的字符串;
• 如果字符串仅在堆中,那么依据jdk版本会有不同结果:在jdk6及以前版本,intern()返回的引用指向池中的字符串,在jdk7及以后版本,intern()返回的引用指向堆中的字符串。
这里拿字符串ab调用intern()举例,如果在调用intern()前,字符串ab在池中(可能只在池中,也可能既在池中也在堆中),那么intern()返回的引用一定指向池中的ab;如果ab只在堆中,则在不同的jdk环境下有不同的结果:如果是jdk6及以前版本,intern()返回的引用指向池中的ab,如果是jdk7及以后的版本,intern()返回的引用指向堆中的ab。如下示意图:

注意:对于上面示意图中的第2种情况,这里我所说的字符串仅在堆中,指的是“调用intern()前”,实际上在jdk6下,当调用intern()时,JVM会从堆中复制一份字符串ab到池中,因此intern()返回的引用会指向池中的ab(更多详情见下文)。
下面拿代码来说明以上两种情况。
1.字符串ab在池中,这种情况又包含了ab仅在池中,又包含了ab既在池中也在堆中两种情形:
1.1.字符串ab仅在池中
正如本文的“前置知识”中所讲的那样,通过String s1 = "ab";的方式创建字符串对象,字符串ab就仅存在池中。
分析代码1(结合图示1):执行语句1时会将字符串“ab”存入池中,并在StringTable中创建一行记录,其中的引用指向池中的字符串“ab”。执行语句2时,通过StringTable检索(通过hashcode)发现字符串“ab”已经在池中,返回StringTable中的引用即可。引用s1与s2为同一引用,均指向池中的字符串“ab”,故相等。执行语句3的s1.intern()时,与执行语句2流程一致,也是直接返回StringTable中的引用即可。引用s1与s1.intern()返回的引用也是同一引用,所以比较结果也是true。综上所述,引用s1、s2与s1.intern()返回的引用均为同一引用。
代码1
@Test
void t1(){
String s1 = "ab"; // 语句1
String s2 = "ab"; // 语句2
System.out.println(s1 == s2); // true
System.out.println(s1 == s1.intern()); // 语句3 true
System.out.println(s2 == s1.intern()); // true
}
图示1
例外:如下面变量s4的赋值形式,字符串相加时若包含变量,JVM编译器在编译期间不会把相加后的结果字符串作为一个字符串常量存入常量池表,这样自然在类加载后的内存分配时不会将结果字符串分配到池中,而是在运行期间通过执行StringBuilder的append及toString方法创建一个新的结果字符串对象,并存入堆中。
@Test
void t1_例外(){
String s1 = "ab";
String s2 = "a";
String s3 = "b";
String s4 = s2 + s3; // 字符串相加若包含变量,创建的字符串将处于堆中
System.out.println(s1 == s4); // false
System.out.println(s1 == s4.intern()); // true
}
1.2.字符串ab既在池中也在堆中
通过String s = new String("ab");的方式创建字符串对象,则字符串ab既在池中也在堆中。
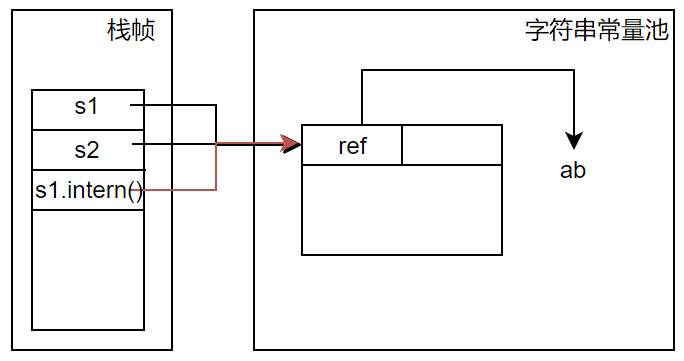
分析代码2(结合图示2):执行语句1时,将在堆中创建字符串对象“ab”,引用s1指向该字符串对象,且会在池中存入字符串“ab”。执行语句2时,将在堆中再次创建字符串对象“ab”,引用s2指向该字符串对象,由于池中已经存在字符串“ab”,所以这次不会在池中重复地存入该字符串了。引用s1与s2指向堆中2个不同的字符串对象“ab”,比较结果为false。执行语句3中的s1.intern()时,发现池中虽已包含字符串“ab”,但在StringTable中并未包含其记录,则在StringTable中新增一条记录,且这条记录中的引用指向的就是池中的字符串“ab”,最后返回这个引用。引用s1与s1.intern(),前者指向堆中字符串“ab”,后者返回的引用指向池中的字符串“ab”,比较结果为false。
代码2
@Test
void t2(){
String s1 = new String("ab"); // 语句1
String s2 = new String("ab"); // 语句2
System.out.println(s1 == s2); // false
System.out.println(s1 == s1.intern()); // 语句3 false
}
图示2
小结测试
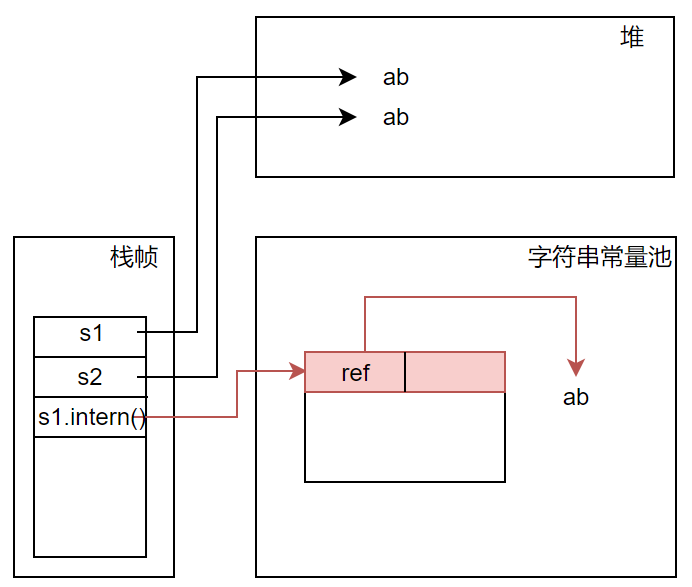
现在进行一个测试,内容很简单,s1是池中的引用,指向池中的字符串,引用s2指向堆中的字符串对象,比较为false。s2.intern()也是返回池中的引用,指向的也是池中的字符串,和s1比较为true。
@Test
void t12(){
String s1 = "ab";
String s2 = new String("ab");
System.out.println(s1 == s2); // false
System.out.println(s1 == s2.intern()); // true
}
2.字符串ab仅在堆中
如果字符串“ab”不在池中而仅在堆中,那么调用intern()依据jdk版本不同会产生不同的行为,这也导致了在这种情况下,intern()返回的引用与字符串进行比较,在不同的jdk环境下有不同的比较结果。
什么情况下会出现字符串“ab”不在池中而仅在堆中呢?这种情况出现在有字符串对象或字符串变量相加的语句中。如下代码3中的语句1,与“代码2中的语句1”不同,JVM编译器在编译期不会将相加的结果放入常量池表,相应地在内存分配时自然也不会将结果放入池中,而是在运行期间通过StringBuilder的append和toString方法创建一个新的结果字符串对象,并存入堆中。语句1中的字符串对象“a”、“b”、“ab”都只会被分配到堆中。
分析代码3(结合图示3):
执行语句2的s1.intern()时,依据jdk环境不同分两种情况:
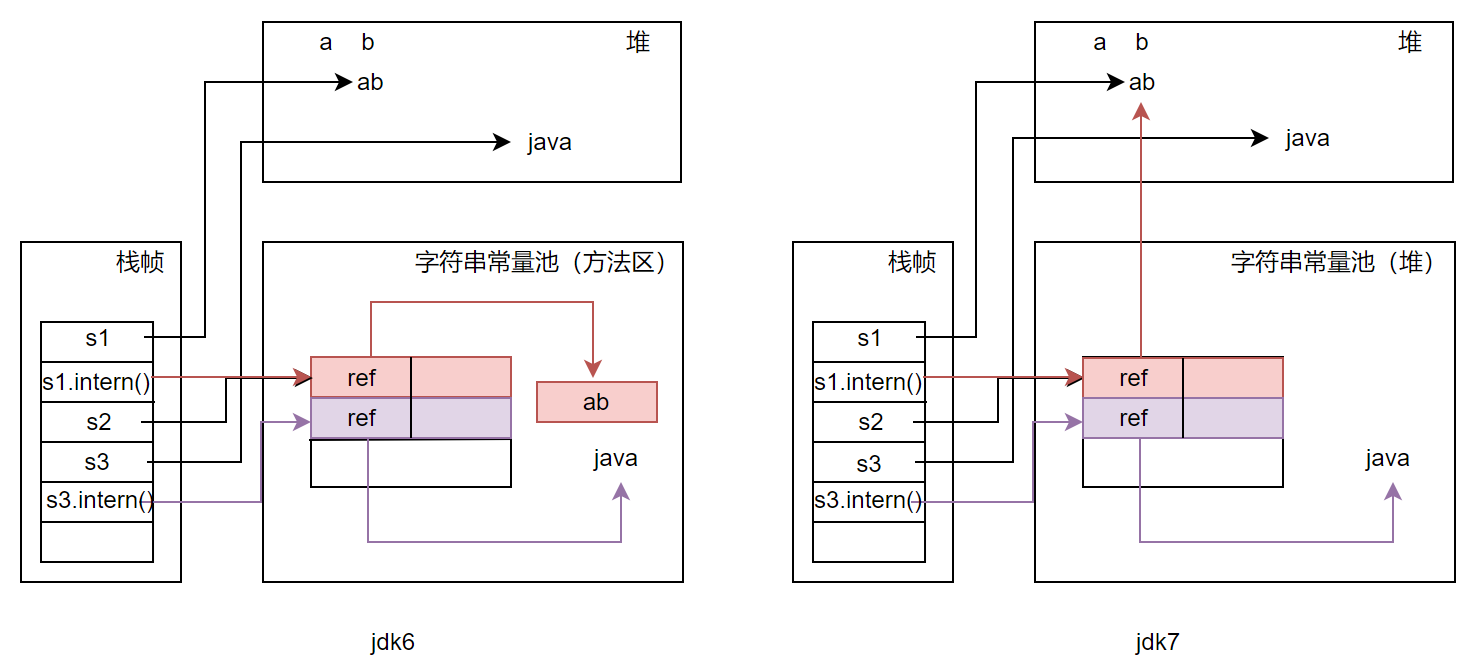
• 如果是jdk6,池在方法区的永久代中(虽然说彼时方法区在物理上仍属于堆,但从逻辑上的内存分配内容而言,俨然是2个概念)。发现字符串“ab不在池中,因此先将它复制到池中,并在StringTable中新增一条指向池中的记录。引用s1指向堆中的字符串对象“ab”,s1.intern()返回的引用指向池中的字符串“ab”,两者比较为false;
• 自jdk7开始,池“搬家”至堆中。发现字符串“ab”不在池中,不会再把字符串复制到池中,而只是在StringTable中新增一条记录,这条记录中的引用就是字符串对象“ab”在堆中的引用。s1.intern()返回的引用与引用s1为同一个,两者比较为true。
执行语句3时,在jdk6环境下,发现StringTable中已包含字符串对象“ab”的引用,直接返回该引用。引用s1指向的字符串在堆中,s2指向的字符串在池中,s1与s2为不同引用,故不等;在jdk7环境下,同样的发现StringTable中已包含字符串对象“ab”的引用,也是直接返回该引用,但是该引用就是堆中的字符串对象“ab”的引用s1,s2和s1为同一引用,故相等。这里顺便总结下(语句4),在jdk7环境下,引用s1、s1.intern()、s2为同一引用,三者相等,在jdk6环境下,s1.intern()与s2相等。
对于语句5有点特殊,因为“java”作为关键字在池创建后就被“优先安排”到池中了,执行语句6中的s3.intern()时,会在StringTable中新增一条记录,该记录中的引用指向池中的字符串“java”。因为引用s3指向堆中的字符串对象“java”,s3.intern()返回的引用指向池中的字符串“java”,两者比较结果自是false。经笔者测试,不仅是“java”,还有更多的关键字也在这“优先安排”的名单中,它们包含但不限于:boolean,byte,char,default,double,float,int,long,null,short,true,void,false。
注意:
1.经测代码3中的语句1替换成以下变句,测试结果是一样的:
变句1:String s1 = new StringBuilder("a").append("b").toString();
变句2:String s1 = new String("a") + "b";
变句3:String b = "b"; String s1 = new String("a") + b;
变句4:String a = "a"; String b = "b"; String s1 = a + b;
2.一个细节需注意,比较字面量与比较这个字面量的引用其实是一样的,如s1 == "ab"跟s1 == s2的比较结果是一样的,因为比较字面量,返回的也是其在池中的引用。
注:本文测试的jdk6的具体版本为:jdk1.6.0_45,jdk7的具体版本为:jdk1.7.0_79(另外笔者在jdk8中测试结果与jdk7一致,jdk8测试具体版本为:1.8.0_112)
代码3
@Test
void t3(){
String s1 = new String("a") + new String("b"); // 语句1
System.out.println(s1 == s1.intern()); // 语句2 false(6) true(7)
String s2 = "ab"; // 语句3
System.out.println(s1 == s2); // false(6) true(7)
System.out.println(s1.intern() == s2); // 语句4 true(6) true(7) jdk7:s1 == s1.intern() == s2; jdk6:s1.intern() == s2
String s3 = new String("ja") + new String("va"); // 语句5
System.out.println(s3 == s3.intern()); // 语句6 false(6) false(7)
}
图示3
二、intern的应用
理解intern的目的不仅是应付面试题,更在于在实际开发过程中应用。先了解一下intern的优缺点。
intern的优缺点
优点
• 提升比较效率。
• 在创建大量的重复字符串的场景中,有效减少内存消耗。
缺点
• 执行intern本身需要一定的时间成本,降低代码效率。
先看下优点1。如下代码,通过debug可知:使用intern(语句2),在进行 equals 比较时,如果两个对象是同一个的话,在 “==” 比较时就能得出结果,所以可以提高 equals 比较的效率。
@Test
void t_equals(){
String s1 = new String("ab");
String s2 = new String("ab");
System.out.println(s1.equals(s2)); // 语句1
System.out.println(s1.intern().equals(s2.intern())); // 语句2 intern好处之一:提高比较效率
}
执行语句1
执行语句2
下面再看下优点2及缺点。下面进行测试,此次测试用于检测intern能否有效节省内存及其执行效率。如下测试代码,在运行前设置JVM参数:-Xmx2g -Xms2g -Xmn1500M。(注意:因为此JVM参数设置的足够大,因此即使对于本测试代码创建了1千万个字符串对象(不使用intern的情况下),也不会发生OMM。经笔者测试,如把JVM参数设置为:-Xms128m -Xmx1024m -Xmn600m -XX:+HeapDumpOnOutOfMemoryError,因为新生代只有600m,则会发生OOM,期间因为垃圾回收会造成长时间的卡顿)
public class intern {
// 字符串数组的⻓度
static final int MAX = 1000 * 10000;
// 字符串数组
static final String[] arr = new String[MAX];
public static void main(String[] args) throws Exception {
// 随机数数组
Integer[] DB_DATA = new Integer[10];
// 随机数对象
Random random = new Random(10 * 10000);
// 产⽣10个随机数,放⼊DB_DATA数组中保存
for (int i = 0; i < DB_DATA.length; i++) {
DB_DATA[i] = random.nextInt();
}
long t = System.currentTimeMillis();
// 存储1000*10000个字符串对象
for (int i = 0; i < MAX; i++) {
arr[i] = new String(String.valueOf(DB_DATA[i %
DB_DATA.length])); // 语句1
}
System.out.println((System.currentTimeMillis() - t) +
"ms");
System.gc();
// TimeUnit.SECONDS.sleep(30);
}
}
获取堆转储文件说明:此次测试用的是jmap命令获取堆转储文件,用mat软件进行分析。由于执行测试类速度很快,为了在测试类执行期间获取pid,所以在测试代码最后一句(System.gc();)后面再加一句TimeUnit.SECONDS.sleep(30);(注意:在测消耗时间时不要加这句,在获取堆转储文件时加上这句),以利用这个睡眠时间获取堆转储文件。以下是获取堆转储文件示例:
执行测试代码,然后立即在cmd上输入:jps -l,查看测试类pid为17096。

然后立即在cmd上输入:jmap -dump:format=b,file=D:/Test/intern2/intern.bin 17096,即可创建堆转储文件(注意:这2个步骤需在测试类执行完毕前操作好)。最后用mat打开堆转储文件即可进行分析。

• 不使用intern测试:
即语句1不含intern(),直接测试即可。
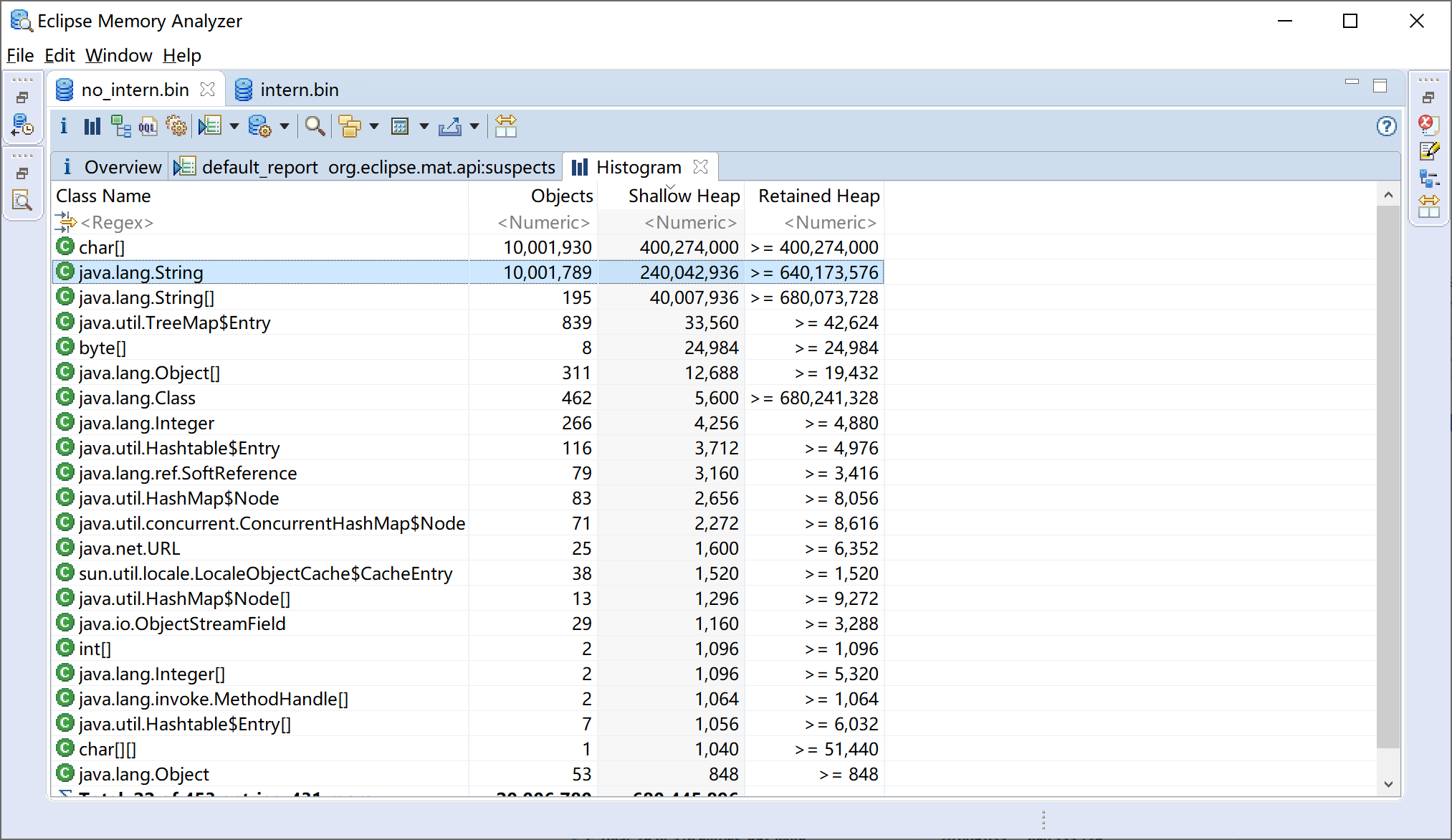
mat分析结果:从结果上看,不使用intern共创建10001789个字符串对象,共占用约610m(640173576/1024/1024,注:640173576的单位为字节),消耗时间:655ms
• 使用intern测试:
先在语句1上增加intern方法,即:arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length])).intern();,然后进行测试。
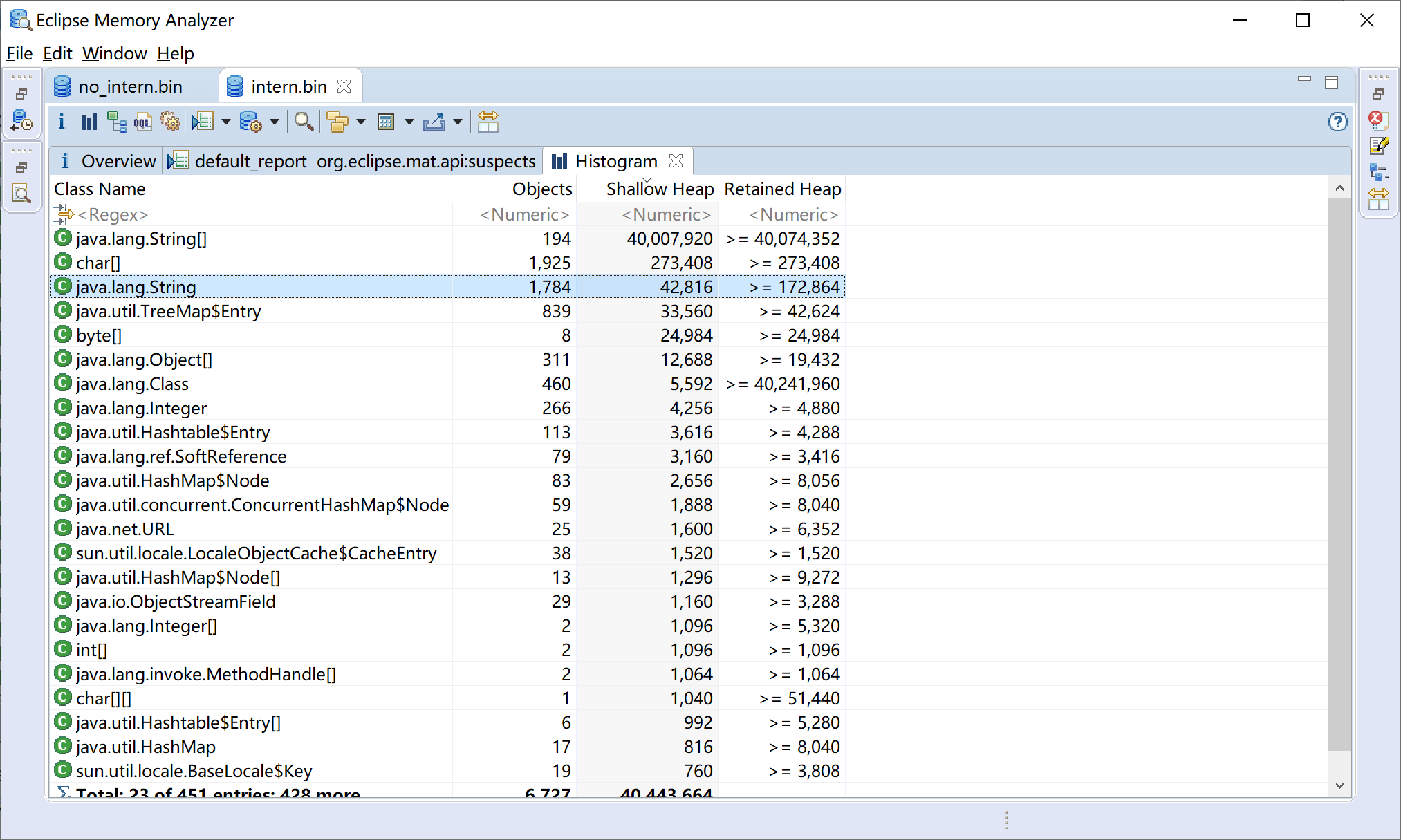
mat分析结果:从结果上看,使用intern创建了1784个字符串对象,共占用约168kb(172864/1024),消耗时间:1518ms
测试结果:基于本测试案例,会创建大量的重复字符串,使用intern一方面大量节省了内存,另一方面却又降低了代码效率。
intern节省内存的原理:intern方法本身不能减少JVM去创建对象,而是通过消除引用,促进垃圾回收来实现内存优化的。如代码String s1 = new String("ab"); String s2 = new String("ab");与代码:String s1 = new String("ab").intern(); String s2 = new String("ab").intern();在创建对象数量上其实是一样的,都创建了2个对象,都占用了2块堆内存空间。但是,由于前者的引用s1、s2直接指向堆中的2个字符串对象,所以在这2个引用消失前,垃圾回收器是不会回收这2个对象的;而后者引用s1、s2指向的是池中的引用,所以堆中的2个对象是没有引用指向它们的,它们会很快被回收。
intern的应用
根据测试结果可知,当某一场景中创建了大量重复字符串,为了节省内存和避免OOM,就可以考虑使用intern进行优化。
对于与业务逻辑相关的字符串,可以很容易的通过mat分析工具,找到它们并查看它们是否占据了大量的内存;对于其他字符串,可以通过mat的 “Merge shortest Path to GC Root” 选项来找到它们被存储的位置。
参考文章:《使用string的intern优缺点》、《深入理解Java虚拟机》第三版 2.4.3 方法区和运行时常量池溢出

 浙公网安备 33010602011771号
浙公网安备 33010602011771号