


数据采集与融合技术作业一
数据采集与融合技术作业一
网络爬虫实践
作业①:爬取大学排名信息
代码实现
import requests
from bs4 import BeautifulSoup
# 确保URL是正确的
target_url = "http://www.shanghairanking.cn/rankings/bcur/2020"
try:
response = requests.get(target_url)
response.raise_for_status() # 检查请求是否成功
html_content = response.content
soup = BeautifulSoup(html_content, 'html.parser')
ranking_table = soup.find('table')
# 设置列宽,确保对齐
print(f"{'排名':<5}{'学校名称':<50}{'省市':<15}{'学校类型':<20}{'总分':<10}")
table_rows = ranking_table.find_all('tr')
for row in table_rows[1:]:
columns = row.find_all('td')
if columns:
ranking = columns[0].get_text(strip=True)
school = columns[1].get_text(strip=True)
location = columns[2].get_text(strip=True)
university_type = columns[3].get_text(strip=True)
score = columns[4].get_text(strip=True)
# 打印信息,使用格式化字符串对齐列
print(f"{ranking:<5}{school:<50}{location:<15}{university_type:<20}{score:<10}")
except requests.RequestException as e:
print(f"请求网页时遇到问题:{e}")
except Exception as e:
print(f"解析网页时遇到问题:{e}")
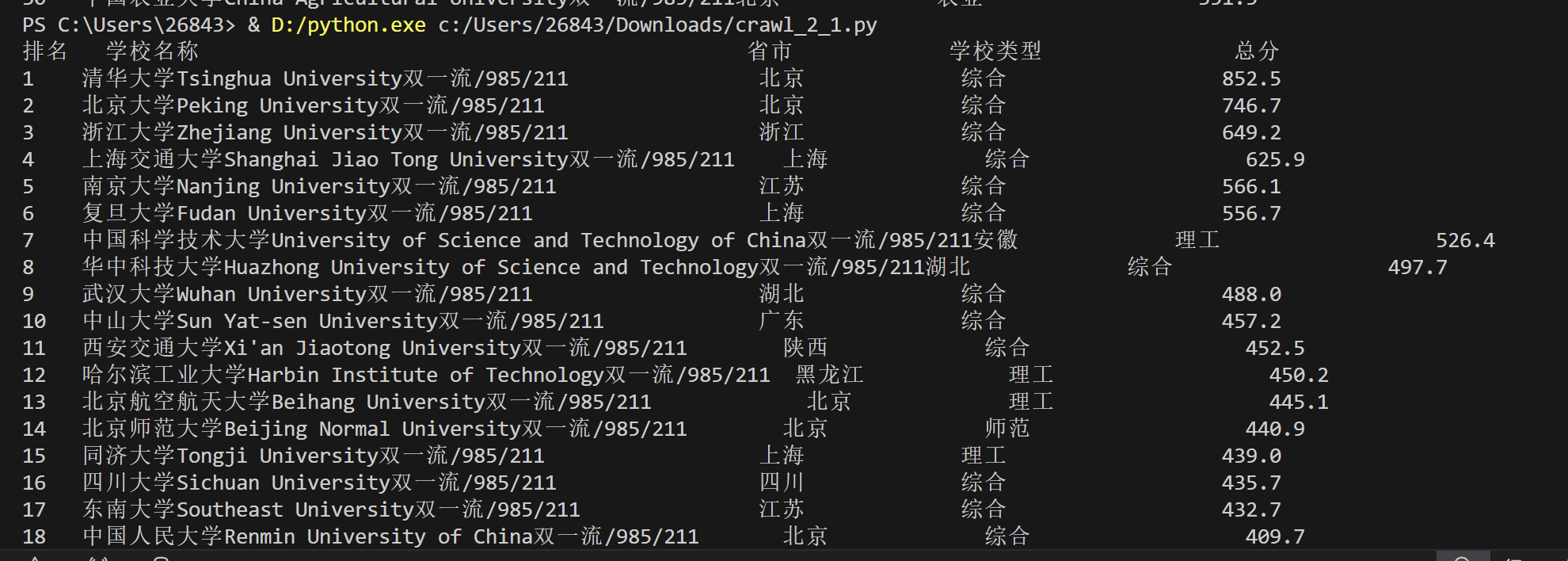
心得体会:
在完成作业①的过程中,我学习了如何使用requests库来发送HTTP请求,并使用BeautifulSoup来解析HTML文档。这个过程中,我了解到了网页结构的重要性,以及如何根据网页的结构来提取所需的数据。
作业②:爬取商城商品信息
代码实现
import urllib.request
from bs4 import BeautifulSoup
import chardet
# 我获取HTML文本内容
def getHTMLText(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
try:
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req).read() # 发送请求并读取响应数据
encoding = chardet.detect(data)['encoding'] # 使用chardet库检测网页编码
data = data.decode(encoding, 'ignore') # 解码网页内容
return data
except Exception as err:
print("Error:", err)
return None
# 解析页面内容
def parsePage(data):
uinfo = []
soup = BeautifulSoup(data, 'html.parser')
items = soup.find_all('li', class_=lambda x: x and x.startswith('line'))
for i, item in enumerate(items):
price = item.find('p', class_='price').span.get_text(strip=True)
name = item.find('p', class_='name').a.text
uinfo.append([i + 1, price, name])
return uinfo
# 打印商品列表
def printGoodsList(uinfo):
tplt = "{:<10} {:<10} {:<20}"
print(tplt.format("序号", "价格", "商品名称"))
for i in uinfo:
print(tplt.format(i[0], i[1], i[2]))
def main():
url = 'http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input'
data = getHTMLText(url)
if data:
uinfo = parsePage(data)
printGoodsList(uinfo)
if __name__ == '__main__':
main()

心得体会:
在完成作业②的过程中,我学习了如何使用正则表达式来提取商品价格。这个过程中,我了解到了正则表达式的强大功能,以及如何在实际的网页数据中应用它们。
作业③:爬取网页中的图片
代码实现
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
def fetch_page_content(url):
"""获取网页内容"""
try:
response = requests.get(url)
response.raise_for_status() # 确保请求成功
response.encoding = 'utf-8'
return response.text
except requests.RequestException as e:
print(f"请求网页时遇到问题:{e}")
return None
def parse_images_from_html(html_content, base_url):
"""从HTML内容中解析图片链接"""
soup = BeautifulSoup(html_content, 'html.parser')
img_tags = soup.find_all('img')
img_urls = [urljoin(base_url, img.get('src')) for img in img_tags if img.get('src')]
return [img_url for img_url in img_urls if img_url.lower().endswith(('.jpg', '.jpeg'))]
def download_images(img_urls, folder_name):
"""下载图片并保存到指定文件夹"""
if not os.path.exists(folder_name):
os.makedirs(folder_name)
for img_url in img_urls:
try:
img_response = requests.get(img_url)
img_response.raise_for_status() # 确保请求成功
img_name = os.path.join(folder_name, img_url.split('/')[-1])
with open(img_name, 'wb') as f:
f.write(img_response.content)
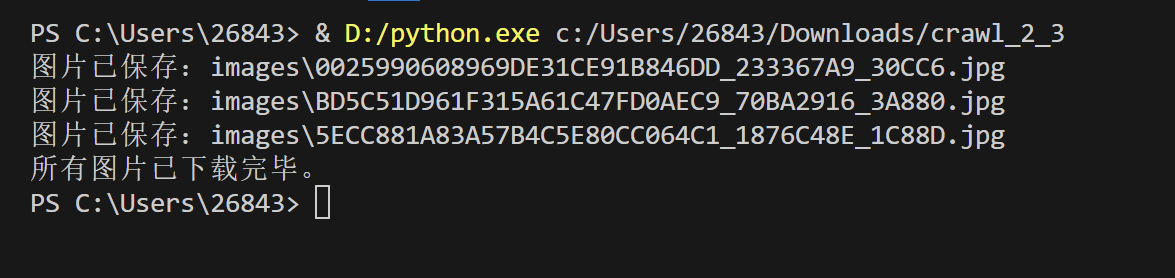
print(f'图片已保存:{img_name}')
except requests.RequestException as e:
print(f"下载图片时遇到问题:{e}")
def main():
url = 'https://news.fzu.edu.cn/yxfd.htm'
folder_name = 'images'
html_content = fetch_page_content(url)
if html_content:
img_urls = parse_images_from_html(html_content, url)
download_images(img_urls, folder_name)
print('所有图片已下载完毕。')
if __name__ == '__main__':
main()
心得体会:
在完成作业③的过程中,我学习了如何使用urllib.parse来处理URL,以及如何使用requests库来下载文件。这个过程中,我了解到了网络请求中的一些细节,比如如何处理URL拼接和文件保存。




 浙公网安备 33010602011771号
浙公网安备 33010602011771号