pipeline和baseline是什么?
昨天和刚来项目的机器学习小白解释了一边什么baseline 和pipeline,今天在这里总结一下什么是baseline和pipeline。
1.pipeline
1.1 从管道符到pipeline
先从在linux的管道符讲起,
find ./ | grep wqbin | sort
inux体系下的各种命令工具的处理,可以使用管道符作为传递,这是一种良好的接口规范,工具的功能有公共的接口规范,就像流水线一样,一步接着一步。
而我们只需改动每个参数就可以获取我们想要的结果。该过程就被称之管道机制。
一个基础的 机器学习的Pipeline 主要包含了下述 5 个步骤:
- 数据读取 - 数据预处理 - 创建模型 - 评估模型结果 - 模型调参
上5个步骤可以抽象为一个包括多个步骤的流水线式工作,从数据收集开始至输出我们需要的最终结果。
因此,对以上多个步骤、进行抽象建模,简化为流水线式工作流程则存在着可行性,流水线式机器学习比单个步骤独立建模更加高效、易用。
管道机制在机器学习算法中得以应用的根源在于,参数集在新数据集(比如测试集)上的重复使用。
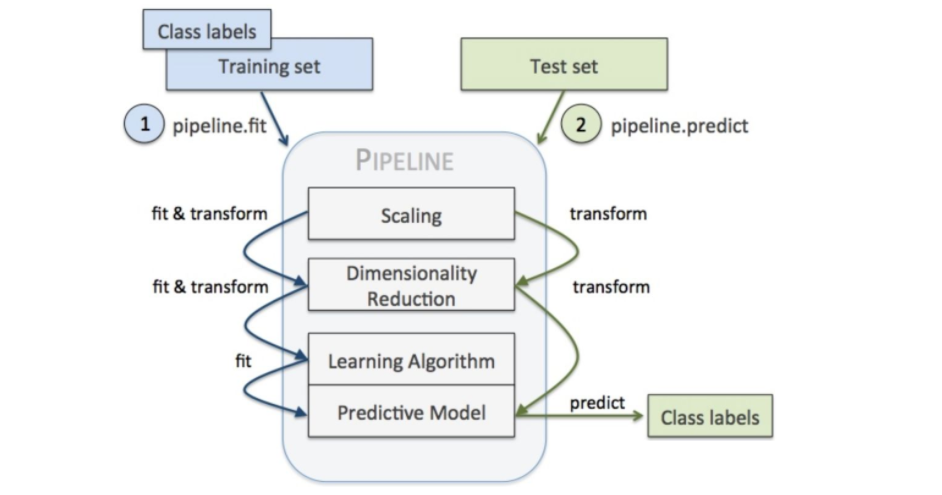
1.2sklearn中pipeline为例
sklearn也遵循pipeline机制,并封装到 sklearn.pipline命名空间下面
pipeline.FeatureUnion(transformer_list[, …]) Concatenates results of multiple transformer objects. pipeline.Pipeline(steps[, memory]) Pipeline of transforms with a final estimator. pipeline.make_pipeline(*steps, **kwargs) Construct a Pipeline from the given estimators. pipeline.make_union(*transformers, **kwargs) Construct a FeatureUnion from the given trans
PIPELINE
sklearn中把机器学习处理过程抽象为estimator,其中estimator都有fit方法,表示数据进行初始化or训练。estimator有2种:
1、特征变换(transformer)
可以理解为特征工程,即:特征标准化、特征正则化、特征离散化、特征平滑、onehot编码等。该类型统一由一个transform方法,用于fit数据之后,输入新的数据,进行特征变换。
2、预测器(predictor)
即各种模型,所有模型fit进行训练之后,都要经过测试集进行predict所有,有一个predict的公共方法。
上面的抽象的好处即可实现机器学习的pipeline,显然特征变换是可能并行的,通过FeatureUnion实现。特征变换在训练集、测试集之间都需要统一,所以pipeline可以达到模块化的目的。举个NLP处理的例子:
# 生成训练数据、测试数据 X_train, X_test, y_train, y_test = train_test_split(X, y) # pipeline定义 pipeline = Pipeline([ ('vect', CountVectorizer()), ('tfidf', TfidfTransformer()), ('clf', RandomForestClassifier()) ]) # train classifier pipeline.fit(X_train, y_train) # predict on test data y_pred = pipeline.predict(X_test)
FEATUREUNION
上面看到特征变换往往需要并行化处理,即FeatureUnion所实现的功能。
pipeline = Pipeline([ ('features', FeatureUnion([ ('text_pipeline', Pipeline([ ('vect', CountVectorizer(tokenizer=tokenize)), ('tfidf', TfidfTransformer()) ])), ('findName', FineNameExtractor()) ])) ('clf', RandomForestClassifier()) ])
pipeline还可以嵌套pipeline,整个机器学习处理流程就像流水工人一样。
上面自定义了一个pipeline处理对象FineNameExtractor,该对象是transformer,自定义一个transformer是很简单的,创建一个对象,继承自BaseEstimator, TransformerMixin即可,
代码如下:
from sklearn.base import BaseEstimator, TransformerMixin class FineNameExtractor(BaseEstimator, TransformerMixin): def find_name(self, text): return True def fit(self, X, y=None): return self def transform(self, X): X_tagged = pd.Series(X).apply(self.find_name) return pd.DataFrame(X_tagged)
执行一个PIPELINE,加上自动调参就可以了,sklearn的调参通过GridSearchCV实现=》pipeline+gridsearch。
GridSearchCV实际上也有fit、predict方法,所以,训练与预测高效抽象的,代码很简洁。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号