
python 爬虫-1
买了本书在自学,我也不知道自己能学到什么地步,反正不用这个找工作,纯属爱好,有可能之后就会放弃 233333333....
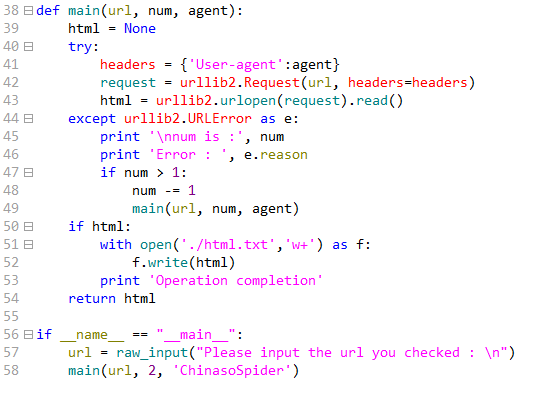
先来一个特别简单点的:将百度搜索主页 扒下来,并保存到一个文件里面
first_crawling.py
执行结果:
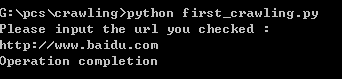
当前目录下的文件html.txt 就是扒下来的百度首页


买了本书在自学,我也不知道自己能学到什么地步,反正不用这个找工作,纯属爱好,有可能之后就会放弃 233333333....
先来一个特别简单点的:将百度搜索主页 扒下来,并保存到一个文件里面
first_crawling.py
执行结果:
当前目录下的文件html.txt 就是扒下来的百度首页

 浙公网安备 33010602011771号
浙公网安备 33010602011771号