20200917-3 白名单
作业要求 https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11207
作业0(5分)
修改create.cpp文件,改成由命令行参数确定生成的数据的数据量。修改readme.md的对应部分。(要求贴出修改之后的代码和read.md。)
#include <iostream>
#include <stdlib.h>
#include <time.h>
using namespace std;
int main(int argc, char* argv[])
{
srand((unsigned)time(NULL));
int num = atoi(argv[1]); //把命令行参数中文件名后的第一个字符串转化为整数
for (int i = 0; i < num; i++);
{
cout << rand() << "\n";
}
cout << endl;
return 0;
}

你看了一下代码,又说道:“老杨,你这结果倒是能对……但是”。你觉得代码的执行效率会比较低。但是你想引导他独立完成修改,你说:“我认为你应该profile一下你的代码,找到代码最慢的地方。”
profile?还好老杨看过《构建之法》,那本书中提到过效能分析。不过老杨不明白为啥要进行效能分析,但毕竟是在面试也不好把太多疑义说出来。所以只好照做。
作业1.
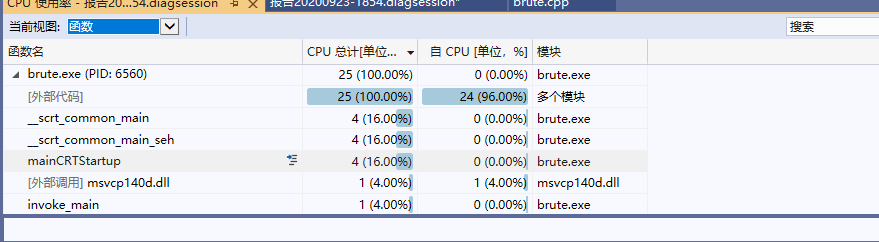
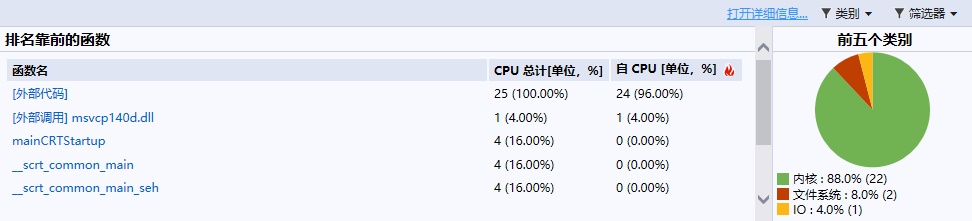
作业2
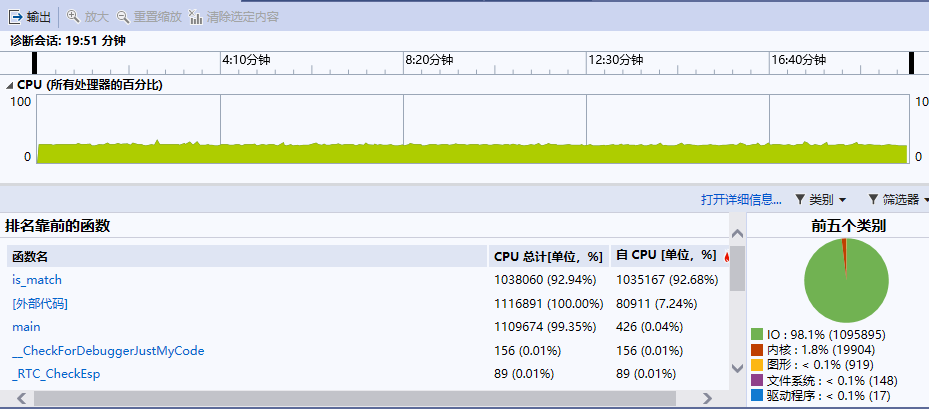
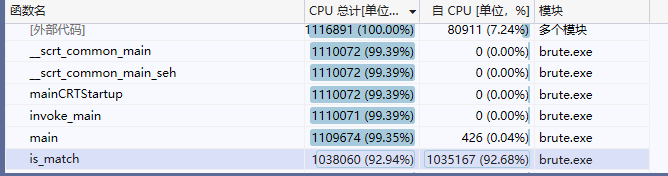
明显可以看出is_match函数耗时
作业三
bool is_match(int t, int w[], int w_length)
{ //修改成折半查找
int low, high, mid;
low = 0;
high = w_length - 1;
while(low<=high)
{
mid=(low+high)/2;
if (w[mid]==t)
return false;
else if(w[mid]>t)
high = mid - 1;
else if(w[mid]<t)
low = mid + 1;
}
return true;
}
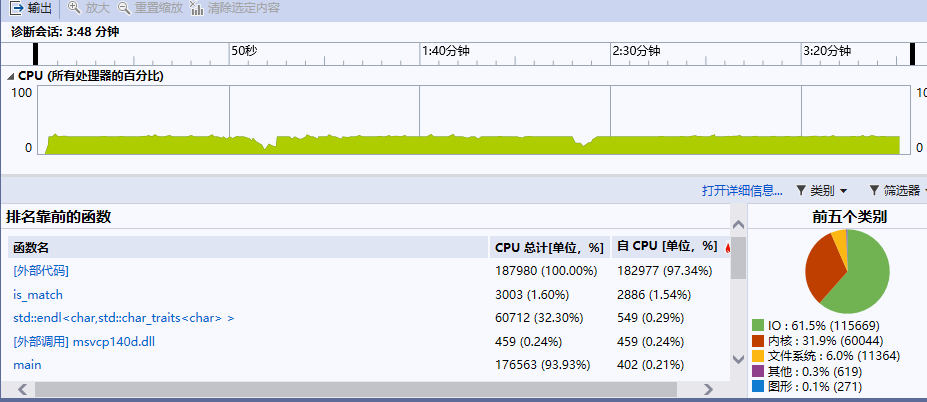
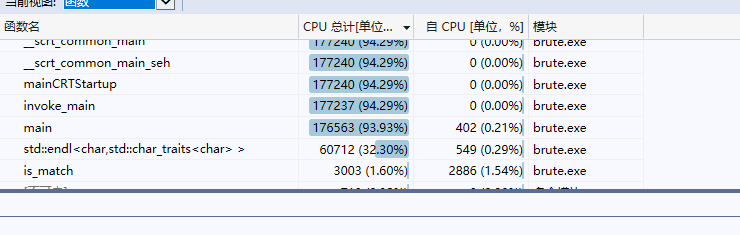
代码 https://e.coding.net/wowcy/brute/btute.git
作业四
is_match函数cpu占比 |
运行时间 | |
| 修改前 | 92.94% | 19分51秒 |
| 修改后 | 1.60% | 3分48秒 |
可以明显看出使用折半查找后is_match函数cpu占比减少,程序运行时间也缩小很多。
作业五
我觉得老杨的在每个.cpp文件开头都写上注释,标记上名字还是很值得我学习的。
我认为老杨的readme不是特别详细,比如
7 执行“create >q”生成文件q;
8 编译brute.cpp文件;
9 执行“brute -w q < whitelist > output”
在执行第九条之前应该将生成的q文件和whitelist放进和brute.cpp同一个目录下
这个地方让我费了好长时间。
不积跬步无以至千里,不积小流无以成江海。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号