
Python爬虫——批量爬取douyin视频,下载到本地
概要
针对批量爬取douyin视频分为两期进行讲解,本期(第一期)内容是讲解如何在上批量下载视频,如何快速的搭建环境,修改参数,让小伙伴们边看边学,半个小时内就可以轻松将douyin视频批量进行下载。第二期内容主要是对代码进行详解,对爬虫感兴趣的小伙伴可以深入了解一下。
代码完整版及结果展示
废话不多说 直接放完整版代码,如果有小伙伴不想去研究的太深,直接拿走用就OK,参照下面我所讲解到所需要更换的参数进行修改,就可以批量下载各种各样的douyin视频啦
# coding:utf-8 import requests from datetime import datetime #===================== ###################### 需修改url 主页地址F12获取具体URL值 ###################### 0 ###################### 需修改headers中 Referer ###################### 需修改headers中 Cookie ###################### 需修改headers中 User-Agent #===================== #===================== #===================== # py获取当前时间 #import time #print( time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) ) #import datetime #print( datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f') ) #===================== #===================== #===================== url = 'httl' headers = { 'Cookie':'UIFI', 'Referer':'https', 'User-Agent':'Mozil6' } res = requests.get(url, headers=headers) aweme_list = res.json().get("aweme_list") for aweme in aweme_list: title = aweme.get("desc") current_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f') print( current_time ,' ',title," "," ======= 下载中!!!!!!!!!!!!!!!!!!!!!!!!!") url = aweme.get("video").get("play_addr").get("url_list")[-1] res = requests.get(url) with open(f"./{title}.mp4", "wb") as f: f.write(res.content) print(f"{title}下载成功!") print(f" !") print(f" !") print(f" !") print(f"GAME------下载结束!")
在这里要提醒大家一下,如果在爬取时间较长的视频时,尽量在网速比较快的情况下进行爬取
具体操作流程
1、代码环境搭建
2、代码简单介绍
为了能够快速的让大家掌握,并且调整参数,下面我将分成4步,快速的为大家进行介绍
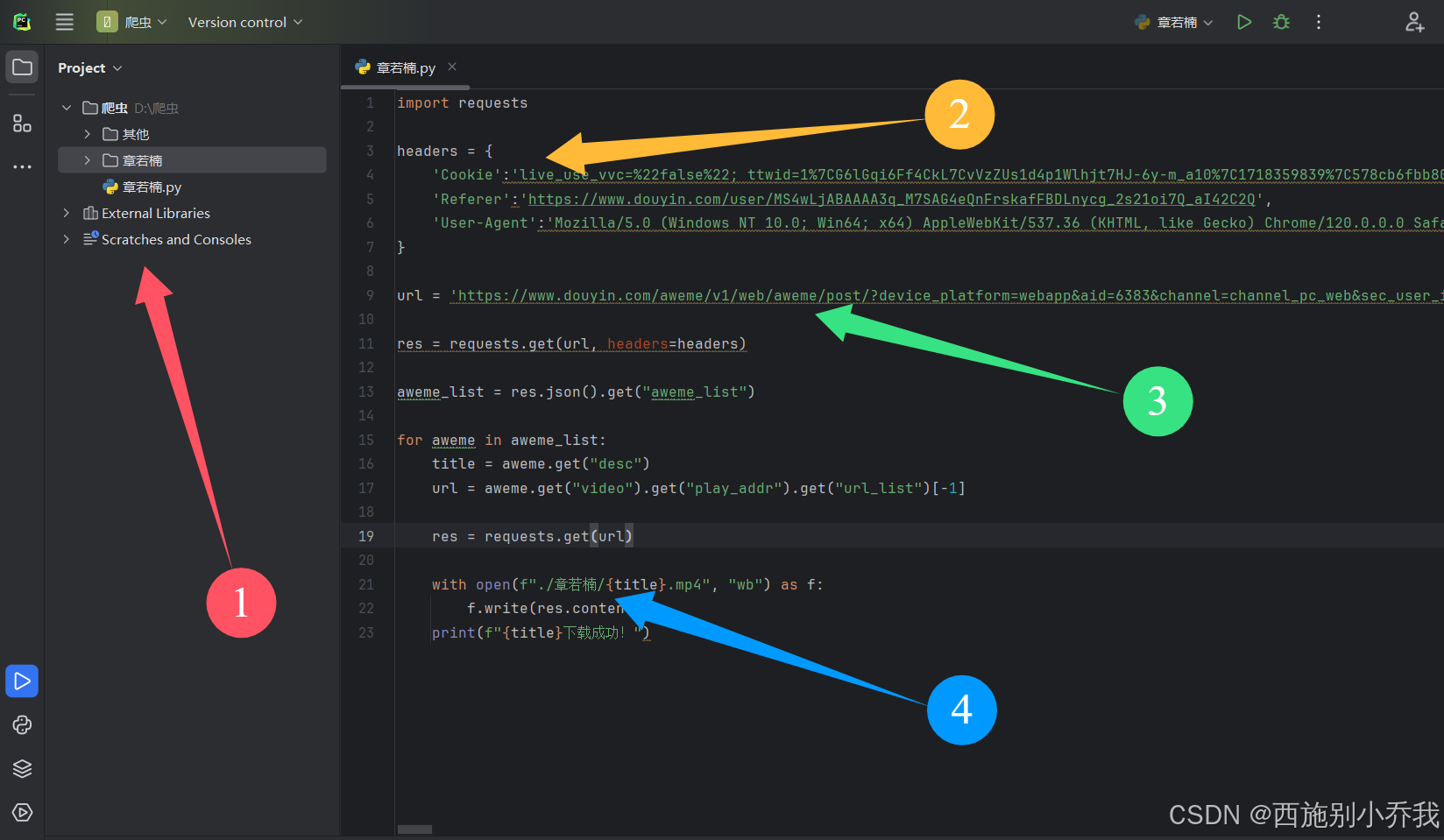
2.1、文件的创建
第一步要在刚建立的文件夹下,创建一个Python文件,这个文件是用来存放代码的,同时在这个文件下创建一个新的文件夹,这个文件夹是用来存放下载视频的(在这里要注意一下,这个文件名称要和第四步的名称一样)
2.2、标头参数
大家可以看到这个标头下,有三个头,分别是Cookie、Referer和User-Agent。
这里就用大白话为大家说明一下这三个的作用。这三个标头大家可以理解为,当我们要回家,打开一扇门时,需要一把钥匙,这样才能够正常的进入到房间内,进行一系列的活动
在这里三个标头就是一把钥匙,当我们想要请求服务器的时候,就需要用一把钥匙来证明我们的身份,当我们的身份合法时,就可以获取里面的内容了
2.3、请求地址
这个地址就是我们需要访问的网址
2.4、文件夹名称
大家在这里要注意的是,要和第一步创建存放视频的文件夹保持一致,否则会保存失败
3、修改参数
在修改参数这一步,大家将2、代码简单介绍的第2步和第3步代码中的参数修改为自己所要爬取视频的参数就OK啦 为了方便大家快速的应用,依旧是使用图片让大家更加清晰的了解参数所在的位置
在你想要爬取的页面鼠标右键,点击检查
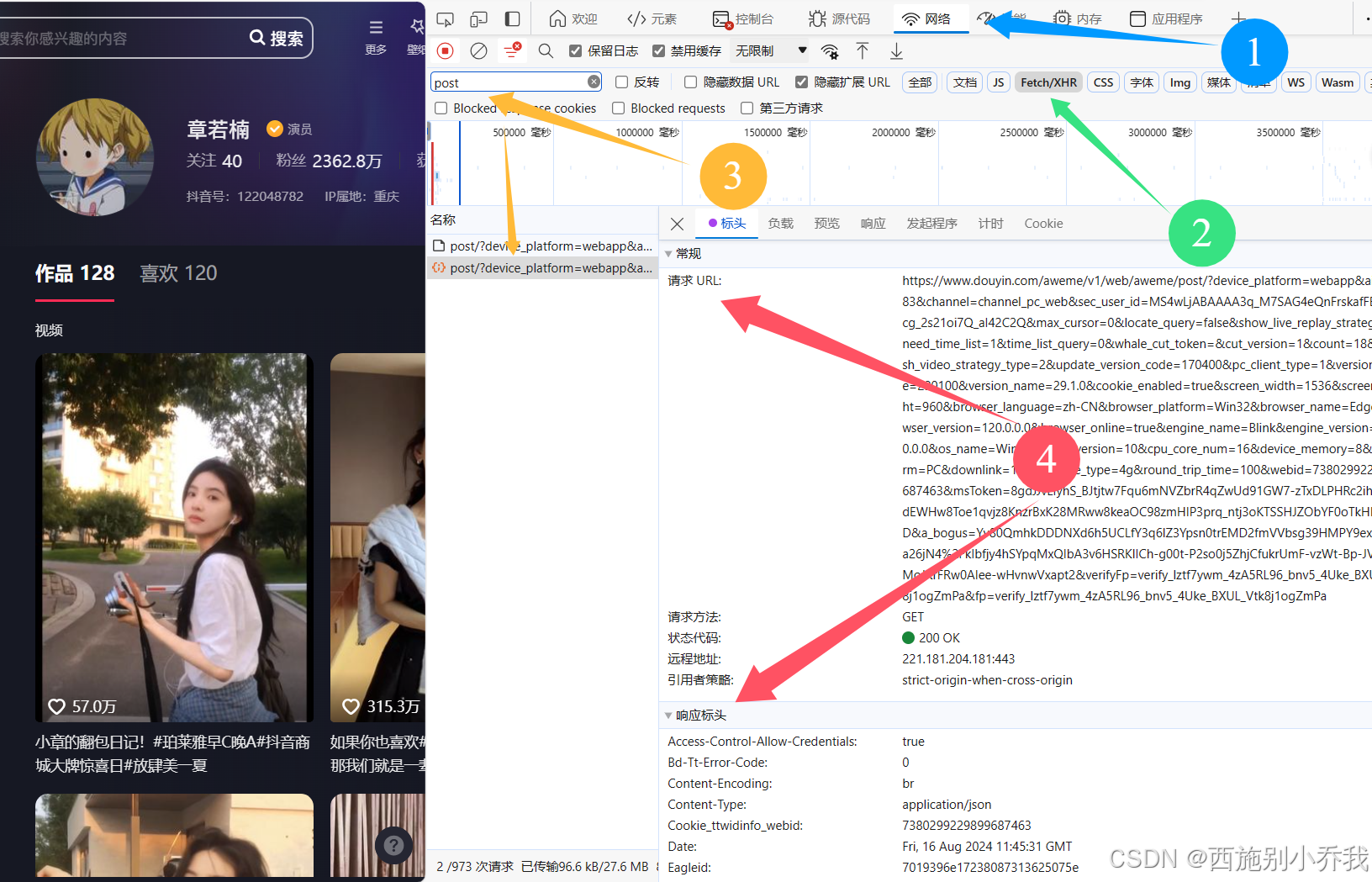
1、点击顺序
在点击检查后,依次点击网络>Fetch/XHR>输入post,对post请求进行筛选,然后点击下方的post,就可以看到右方的一对数据
2、标头调参
右侧分别有标头、负载、预览、响应等等,目前我们只需用到标头中的参数对代码中的内容进行修改 首先可以看到请求URL,将URL全部复制下来,粘贴到代码中响应的位置
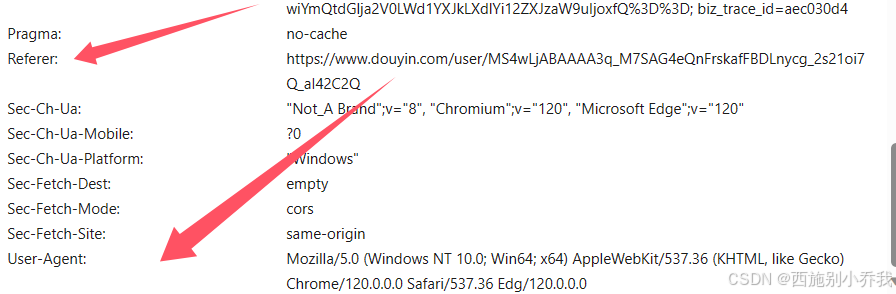
然后在请求URL下面这个模块中就是响应标头,滑动鼠标找到请求标头,对应着(代码简单介绍中的第二步),这三个标头都可以依次找到,然后进行复制粘贴,替换参数。
爬取数据
到这一步小伙伴们就可以在代码中点击右键,运行代码就可以批量下载视频啦
————————————————
原文链接:https://blog.csdn.net/YCH0309/article/details/141268110

 浙公网安备 33010602011771号
浙公网安备 33010602011771号