

网站爬取-案例四:知乎抓取(COOKIE登录抓取个人中心)(第一卷)
有很多网站是需要先登录,才可以浏览的,所以我们这个案例主要讲解如何以登陆的方式抓取这类的页面
第一:http本身是一种无状态的协议
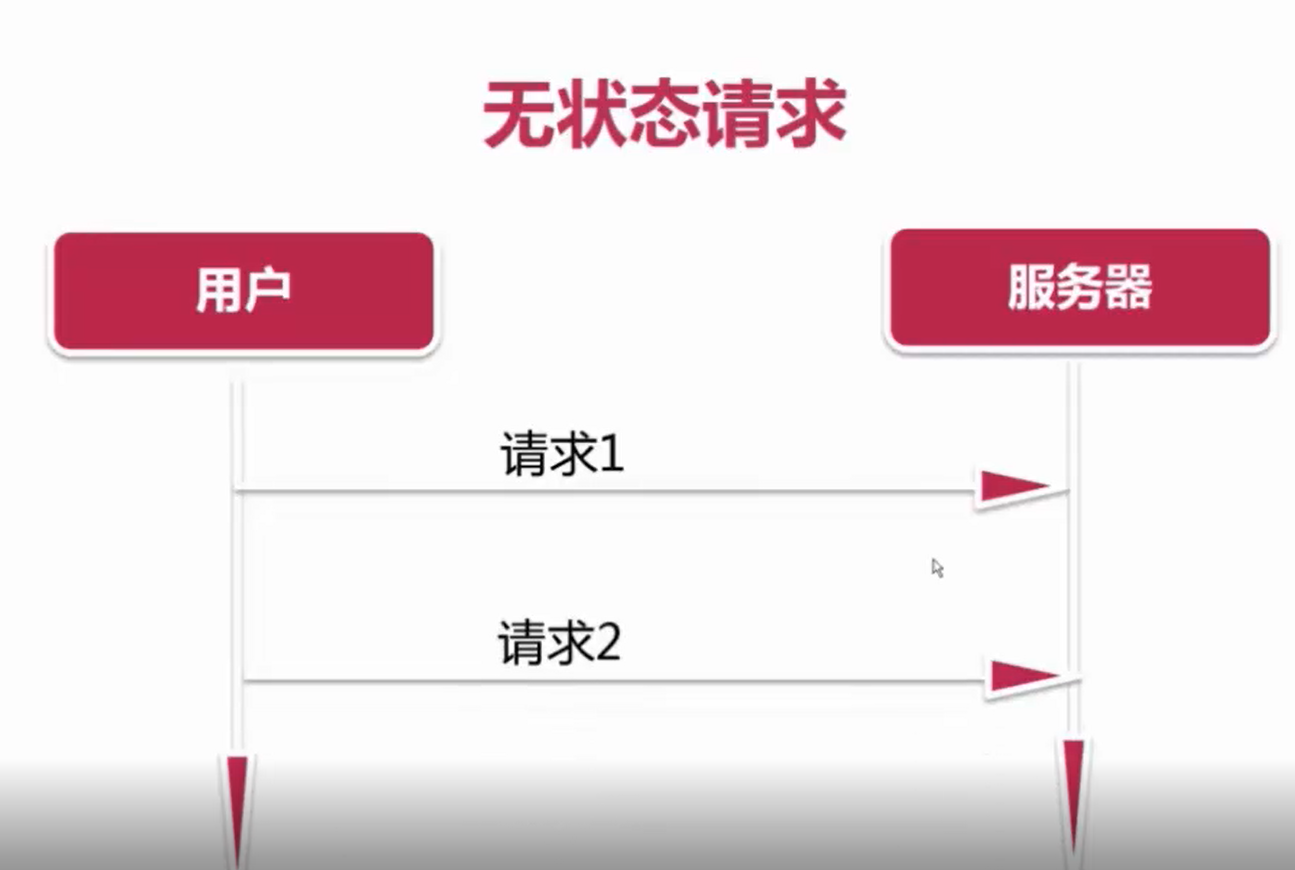
这样两个请求没有任何关系,像淘宝这样的网站需要记录用户的每次请求,来看看有状态的请求
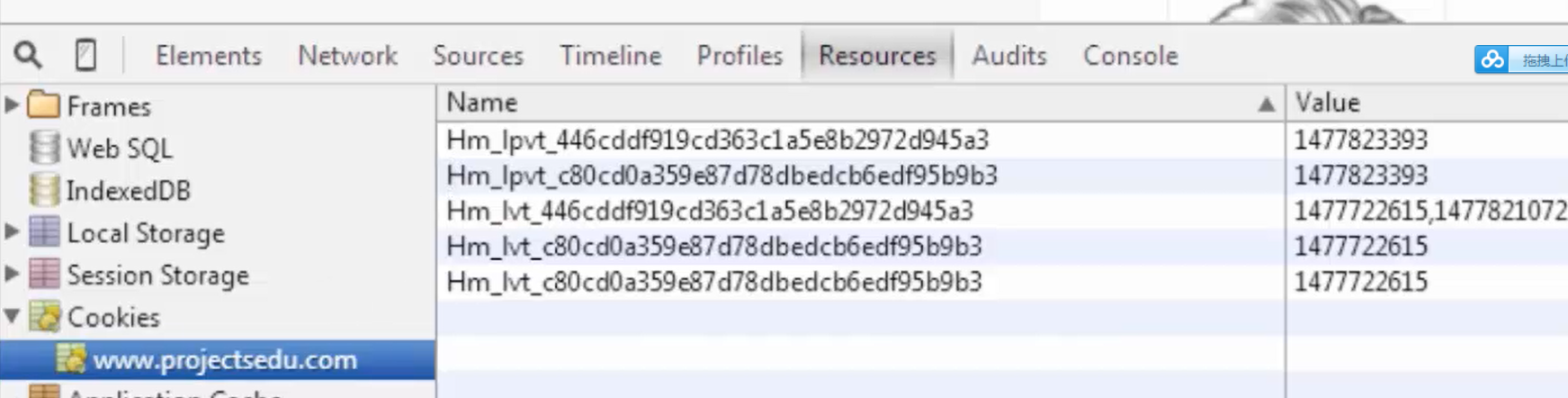
 看一下COOKIE本地存储
看一下COOKIE本地存储
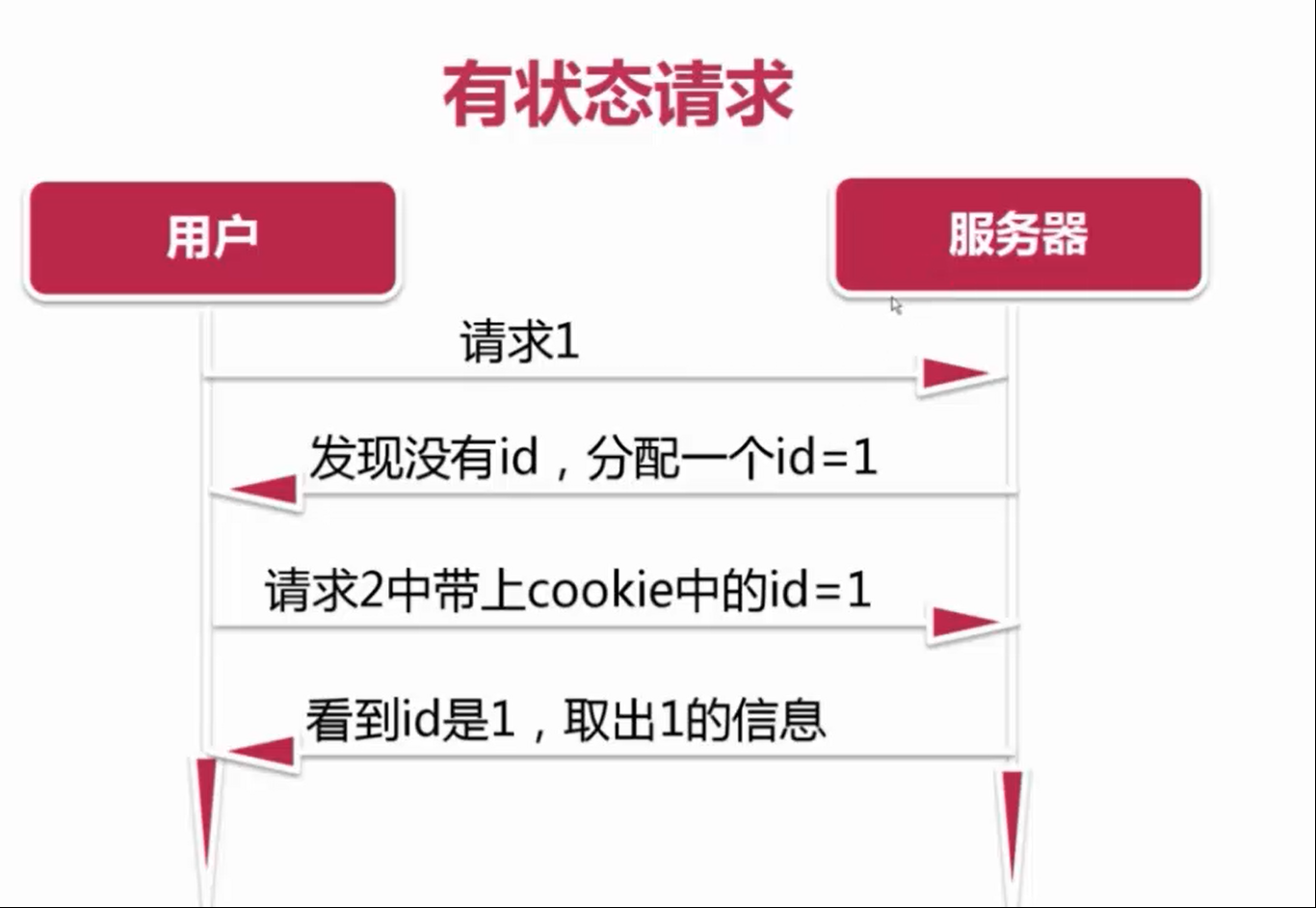
用户名密码可以存到本地,所以安全性不高,这样就出现了SESSION机制,根据用户名和密码生成SESSIONID,根据SESSIONID请求取出用户要的内容
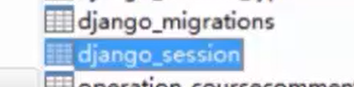
登陆时产生,退出时清空 看下登陆时
![]()
三个字段为ID,加密字段,失效日期,看下登录后的控制台

说到这里我们不得说一说浏览器请求的几种状态:
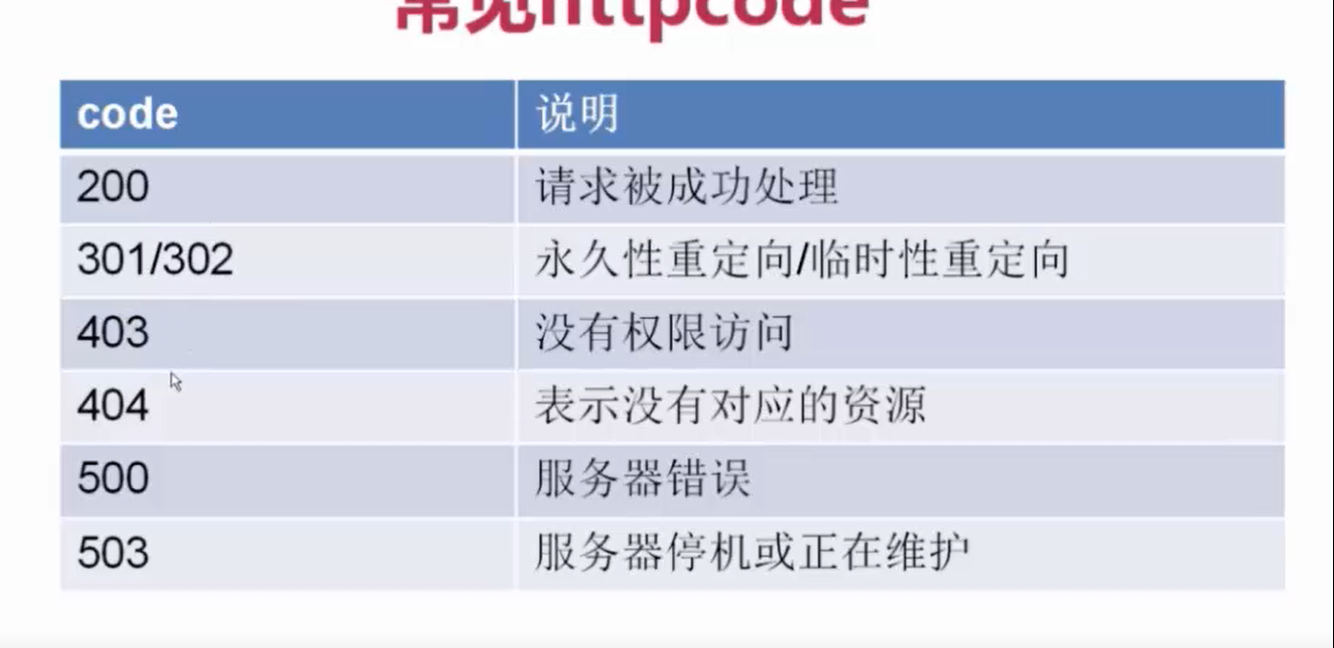 这些状态要分析完成之后才可以模拟登陆先来看下知乎这个目标网站
这些状态要分析完成之后才可以模拟登陆先来看下知乎这个目标网站
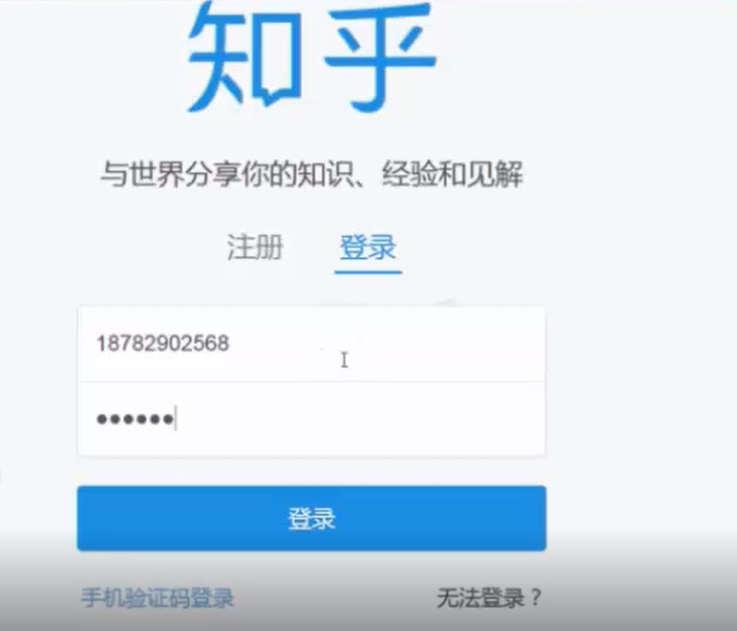
我先用别人的试用用户名和密码做个实验:登陆是爬取知乎的第一步

 浙公网安备 33010602011771号
浙公网安备 33010602011771号