

博客5docx
|
这个项目属于哪个课程 |
2025数据采集与融合技术 |
|
组名、项目简介 |
组名:基米大哈气 项目背景:针对B站视频评论信息量大、内容杂乱的问题,提供智能化的筛选与分类方案,帮助用户快速了解视频评论风向。 项目目标:开发一个支持评论爬取、智能分类、违禁词管理及可视化分析的综合系统,实现对评论内容的精准筛选与多维度展示。 技术路线:前端采用 React + React Router 实现组件化开发;后端使用 Flask + MySQL 管理数据与接口;核心算法基于本地部署的 Qwen2.5 大模型,并应用 LoRA 微调与4位量化技术优化性能;系统最终部署于 华为云平台。| |
|
团队成员学号 |
102302113(王光诚) 102302115(方朴) 102302119(庄靖轩) 102302120(刘熠黄) 102302121(许友钿) 102302122(许志安) 102302123(许洋) 102302147(傅乐宜) |
|
这个项目目标 |
1.智能分类:结合视频类型(如游戏、二次元),将评论自动归类为正常、争论、广告、@某人、无意义五大类。 2.数据可视化:** 提供评论统计、分类分布、高频词云及评论变化曲线图,直观展示数据特征。 3. 违禁词管理:支持实时增删查改违禁词库,保障过滤机制的高效性。 4. 自动化爬取:用户只需输入B站链接,系统即可自动抓取评论并进行智能处理,爬取过程中支持播放背景音乐。 |
|
其他参考文献 |
[1]Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebr´on, and SumitSanghai. GQA: Training generalized multi-query Transformer models from multi-head checkpoints. InEMNLP, pp. 4895–4901. Association for Computational Linguistics, 2023. |
|
码云链接(由于git上上传不了大于1GB的文件,所以我们将所有源码都放到了github上,小组成员间底代码不分开) |
项目代码(GitHub): https://github.com/liuliuliuliu617-maker/-/tree/master |
姓名:许洋 学号:102302123
工作重点:编写前端代码,设计交互页面
- 登录界面设计
蓝粉色渐变的登录界面,可以注册,可以直接登录
二、首页设计
系统支持一键抓取视频评论数据,并通过智能算法对评论内容进行自动分类与统计分析,涵盖正常评论、争议言论、广告信息、@他人及无意义评论等多种类型。首页以数据概览为核心,集中展示评论数量分布、整体舆情概况及高频关键词,帮助用户快速把握评论区整体氛围与关注焦点。同时,评论列表支持按类别筛选与查看,便于用户进行精细化分析与管理。系统界面简洁清晰,操作流程流畅,适用于舆情分析、内容运营及数据分析等多种应用场景,为用户提供可靠、高效的评论分析支持。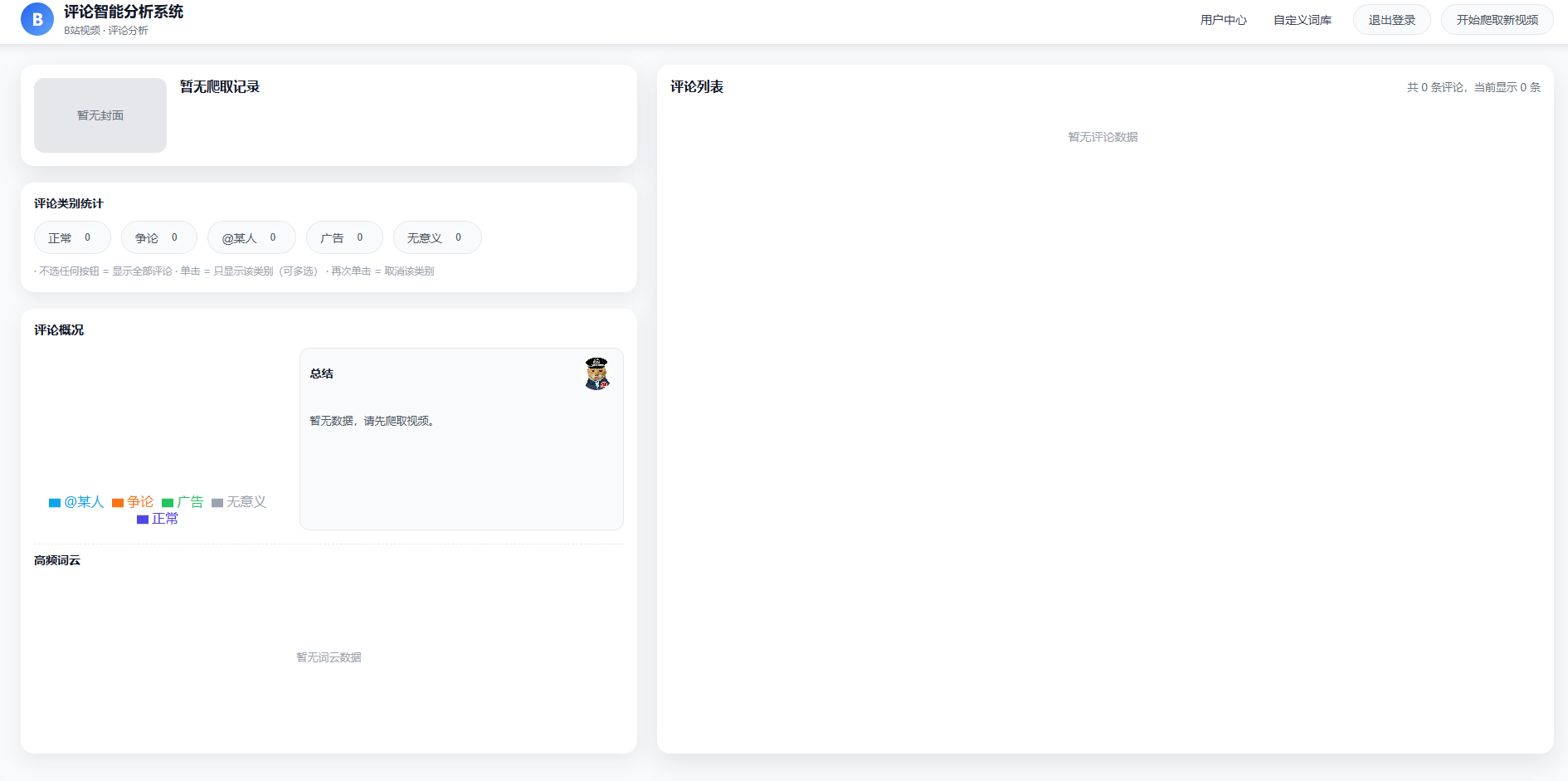
三、爬取页面设计
本页面用于对 B 站视频评论进行快速爬取与智能分析。用户只需输入目标视频链接并选择对应领域,即可一键启动评论抓取流程。系统将自动获取视频下的评论数据,并在后台完成清洗、分类与分析处理,为后续的评论统计、舆情概览和关键词分析提供数据支持。首次爬取可能需要一定时间,请耐心等待。该功能适用于评论区舆情研究、内容分析及课程实验等多种场景,操作简单高效。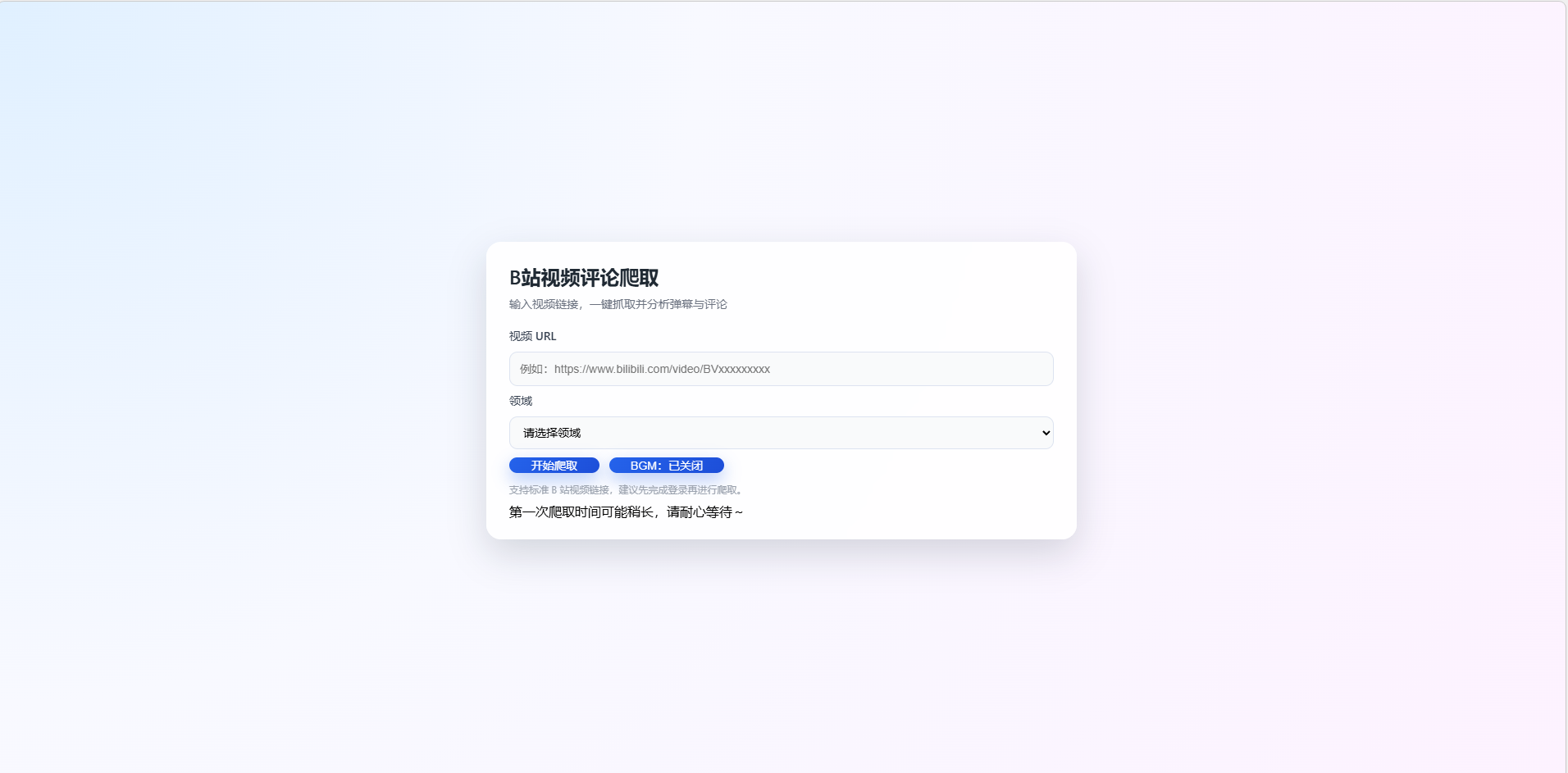
四、用户中心页面设置
用户中心用于集中管理与查看已爬取的视频评论数据,是系统的数据汇总与分析入口。本页面以可视化方式展示历史爬取记录,包括不同视频的评论总量变化趋势及各类评论占比情况,帮助用户直观了解不同视频评论区的活跃度与舆情结构。同时,下方以卡片形式列出已分析的视频信息,支持快速跳转查看对应的评论详情。通过用户中心,用户可以高效回顾爬取历史、对比多视频评论特征,为后续的数据分析与研究提供有力支持。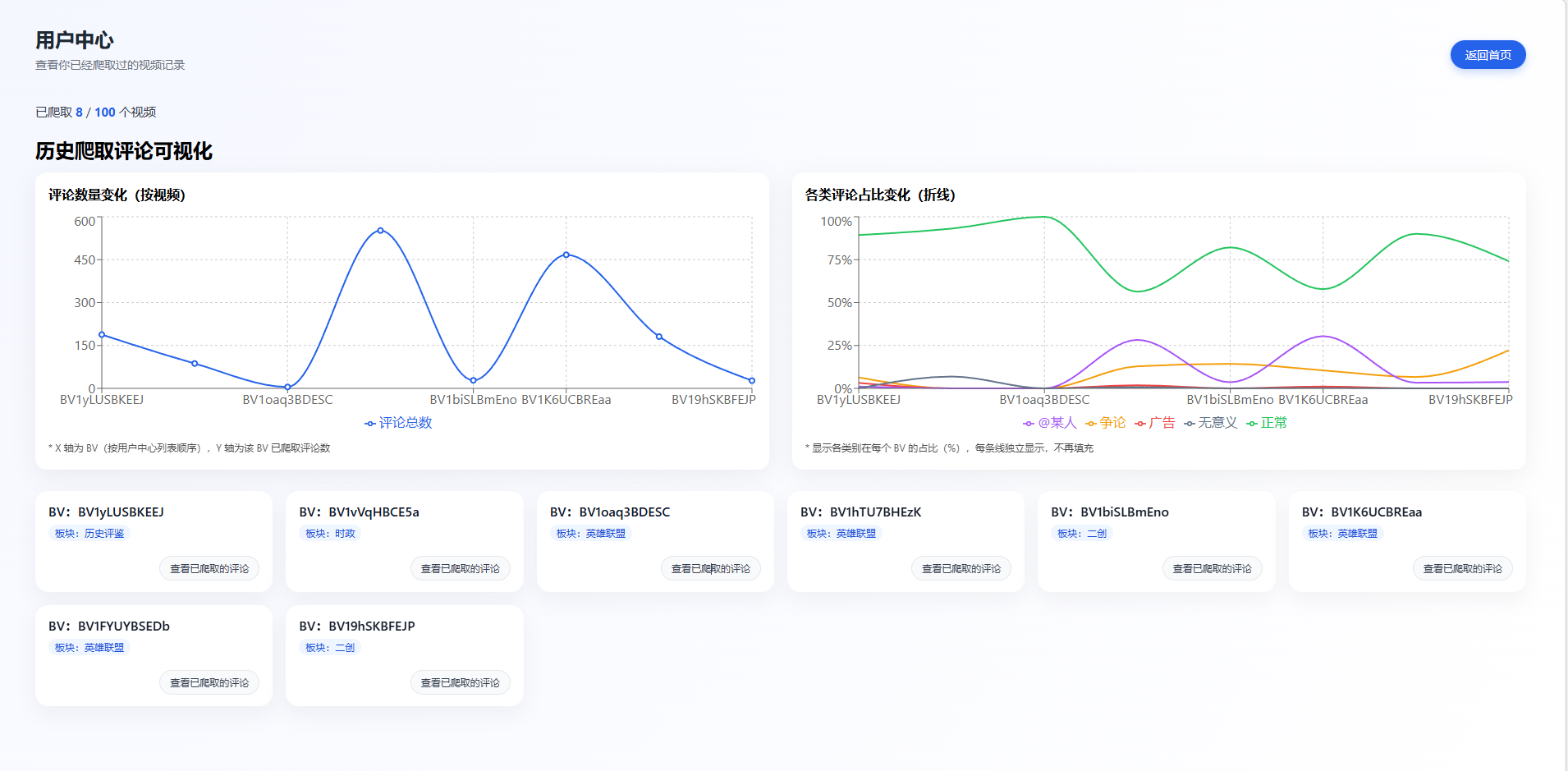
五、自定义词库界面设计
自定义词库用于对评论分类规则进行个性化配置,是提升评论分析准确性的关键功能。用户可根据不同视频领域,针对各类评论自定义关键词,当评论内容匹配到相关词语时,系统将优先按所设置的类别进行判定与归类。通过灵活维护关键词库,可有效增强对广告、争议言论及特定话题评论的识别能力,使分析结果更加贴合实际应用需求。该功能适用于舆情分析优化、规则调整及实验对比等场景,支持关键词的新增与删除,操作简单直观。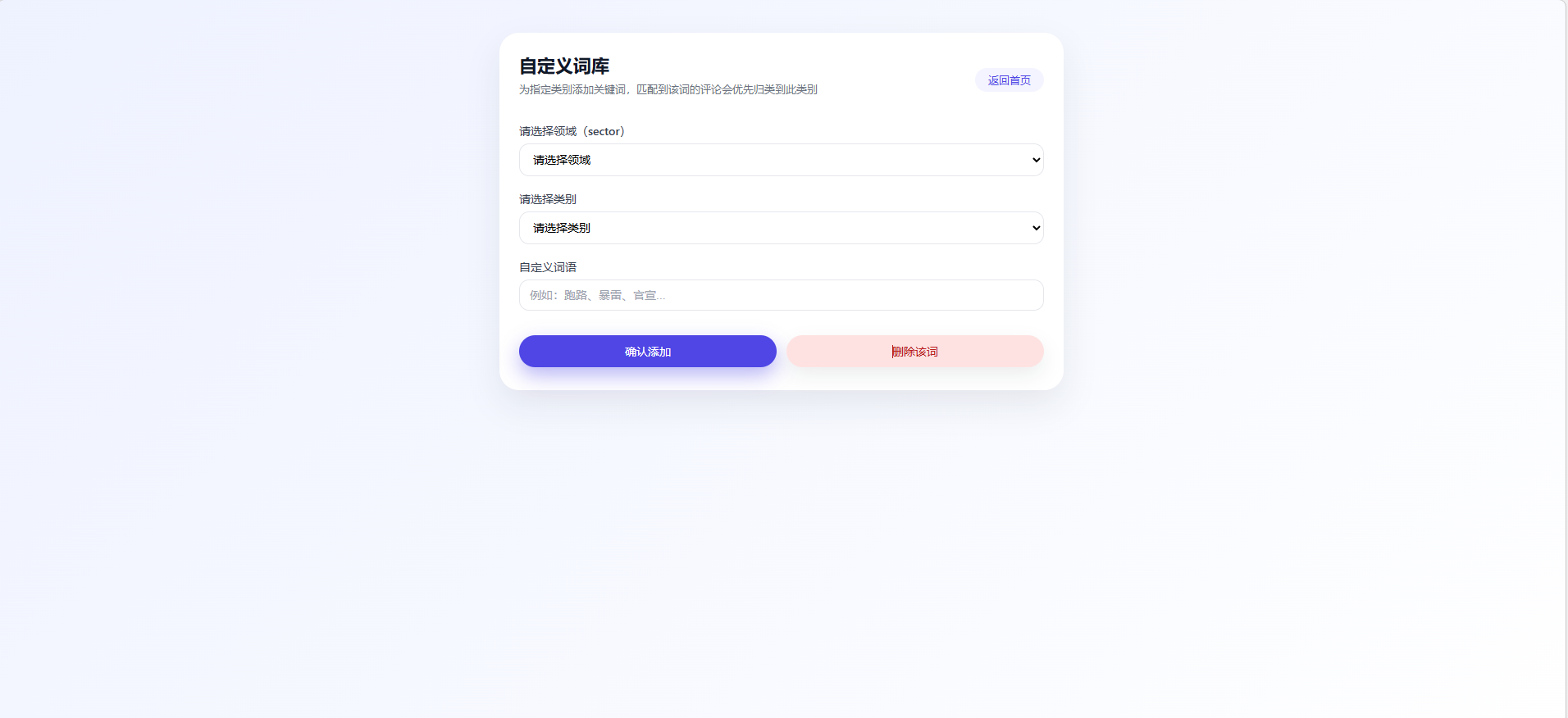

 浙公网安备 33010602011771号
浙公网安备 33010602011771号