
博客2
作业1:
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
完整代码以及运行结果
from bs4 import BeautifulSoup from bs4 import UnicodeDammit import urllib.request import sqlite3 class WeatherDB: def openDB(self): self.con = sqlite3.connect("weathers.db") self.cursor = self.con.cursor() try: self.cursor.execute( """CREATE TABLE weathers ( wCity TEXT, wDate TEXT, wWeather TEXT, wTemp TEXT, CONSTRAINT pk_weather PRIMARY KEY (wCity, wDate) )""" ) print(" 数据表 weathers 已创建") except sqlite3.OperationalError: print(" 数据表已存在,清空旧数据...") self.cursor.execute("DELETE FROM weathers") def insert(self, city, date, weather, temp): try: self.cursor.execute( "INSERT OR REPLACE INTO weathers (wCity, wDate, wWeather, wTemp) VALUES (?, ?, ?, ?)", (city, date, weather, temp), ) except Exception as err: print("插入数据出错:", err) def show(self): self.cursor.execute("SELECT * FROM weathers") rows = self.cursor.fetchall() print("\n=== 数据库内容预览 ===") print("%-8s%-10s%-20s%-10s" % ("city", "date", "weather", "temp")) for row in rows: print("%-8s%-10s%-20s%-10s" % (row[0], row[1], row[2], row[3])) def closeDB(self): self.con.commit() self.con.close() print("\n 数据已保存并关闭数据库连接。") class WeatherForecast: def __init__(self): self.headers = { "User-Agent": ( "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/107.0 Safari/537.36" ) } # 城市编码 self.cityCode = { "北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601", } def forecastCity(self, city): if city not in self.cityCode: print(f" 未找到城市编码:{city}") return url = f"http://www.weather.com.cn/weather/{self.cityCode[city]}.shtml" print(f"正在爬取 {city} ({url})...") try: req = urllib.request.Request(url, headers=self.headers) data = urllib.request.urlopen(req, timeout=10).read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data, "lxml") lis = soup.select("ul[class='t clearfix'] li") for li in lis: try: date = li.select("h1")[0].text.strip() weather = li.select('p[class="wea"]')[0].text.strip() # 有的温度没有span标签,做防错处理 try: high_temp = li.select('p[class="tem"] span')[0].text.strip() except: high_temp = "" low_temp = li.select('p[class="tem"] i')[0].text.strip() temp = (high_temp + "/" + low_temp).replace("//", "/") print(f"{city} | {date} | {weather} | {temp}") self.db.insert(city, date, weather, temp) except Exception as e: print(f"解析错误({city}):", e) except Exception as e: print(f"请求错误({city}):", e) def process(self, cities): self.db = WeatherDB() self.db.openDB() for city in cities: self.forecastCity(city) self.db.show() self.db.closeDB() # 主程序入口 if __name__ == "__main__": ws = WeatherForecast() ws.process(["北京", "上海", "广州", "深圳"]) print("\n 爬取与保存完成!")
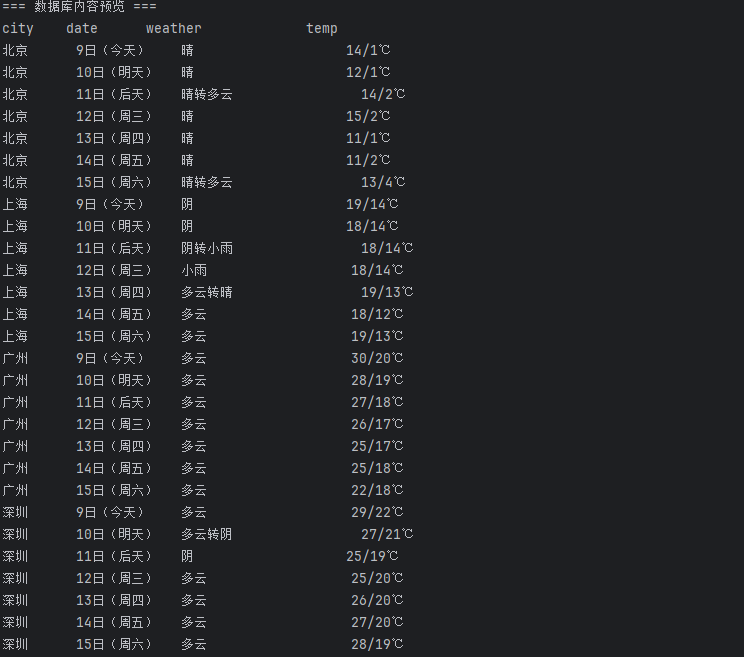
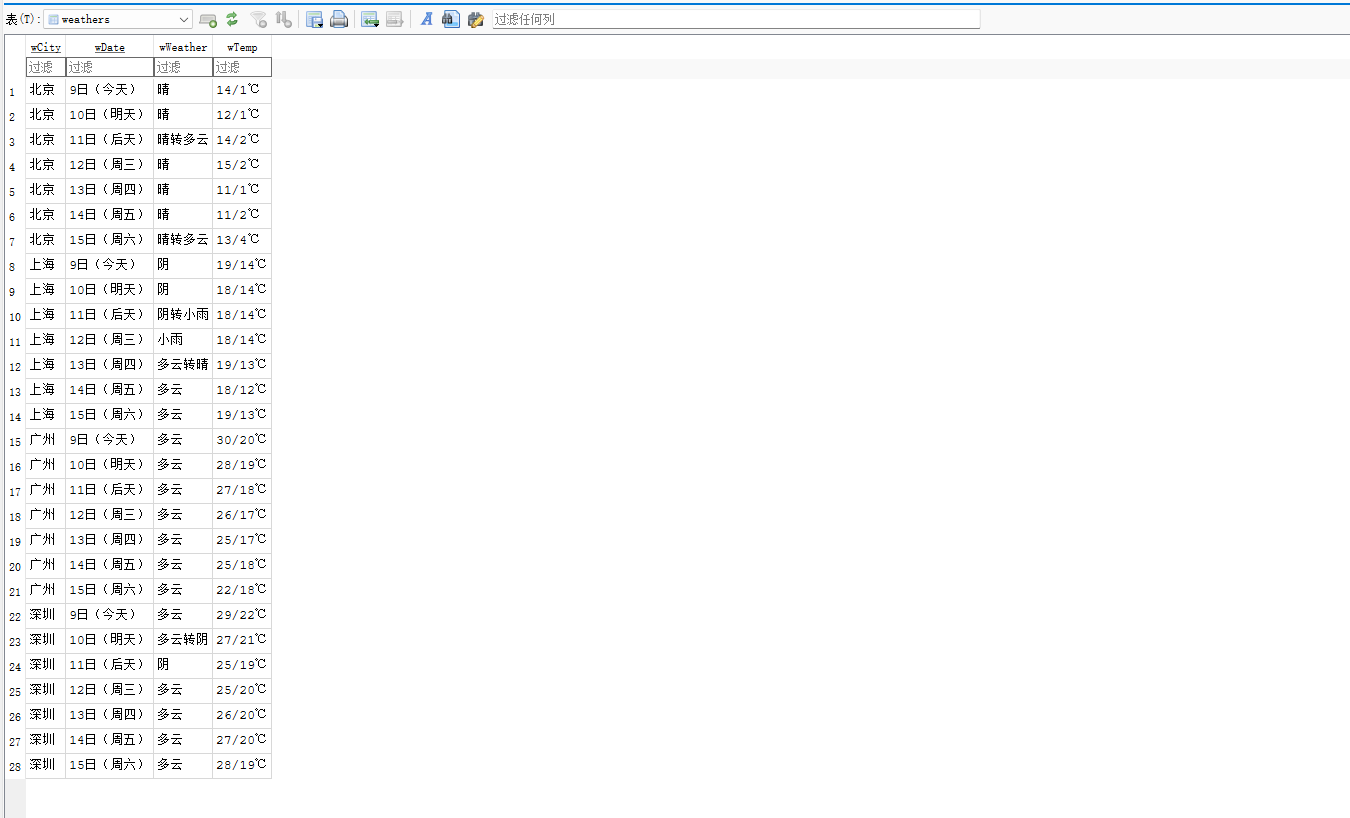
心得体会:
学会了使用BeautifulSoup的常用方法。
作业2:
–要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
完整代码以及运行结果
import requests import pandas as pd import time import sqlite3 import ast headers = { "User-Agent": ( "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/122.0.0.0 Safari/537.36" ) } base_url = ( "https://vip.stock.finance.sina.com.cn/quotes_service/api/json_v2.php/" "Market_Center.getHQNodeData?page={}&num=40&sort=symbol&asc=1&node=hs_a&symbol=&_s_r_a=page" ) all_data = [] for page in range(1, 11): url = base_url.format(page) print(f"正在爬取第 {page} 页: {url}") try: res = requests.get(url, headers=headers, timeout=10) res.encoding = "utf-8" text = res.text.strip() # 新浪返回的是伪JSON格式,用 ast.literal_eval 解析 data_list = ast.literal_eval(text) all_data.extend(data_list) time.sleep(1) except Exception as e: print(f" 第 {page} 页爬取失败: {e}") continue df = pd.DataFrame(all_data) columns_map = { "symbol": "股票代码", "code": "代码(数字)", "name": "名称", "trade": "最新价", "pricechange": "涨跌额", "changepercent": "涨跌幅(%)", "buy": "买入价", "sell": "卖出价", "open": "开盘价", "high": "最高价", "low": "最低价", "settlement": "昨收", "volume": "成交量(股)", "amount": "成交额(元)", "mktcap": "总市值", "nmc": "流通市值", "turnoverratio": "换手率(%)" } for col in columns_map.keys(): if col not in df.columns: df[col] = None df = df[list(columns_map.keys())].rename(columns=columns_map) print("\n 数据示例:") print(df.head()) # 存入 SQLite 数据库 conn = sqlite3.connect("zuoye2-2.db") table_name = "sina_hs_a" # 如果表已存在则替换 df.to_sql(table_name, conn, if_exists="replace", index=False) conn.close() print(f"\n 数据已成功保存至数据库 zuoye2-2.db 表 {table_name}")
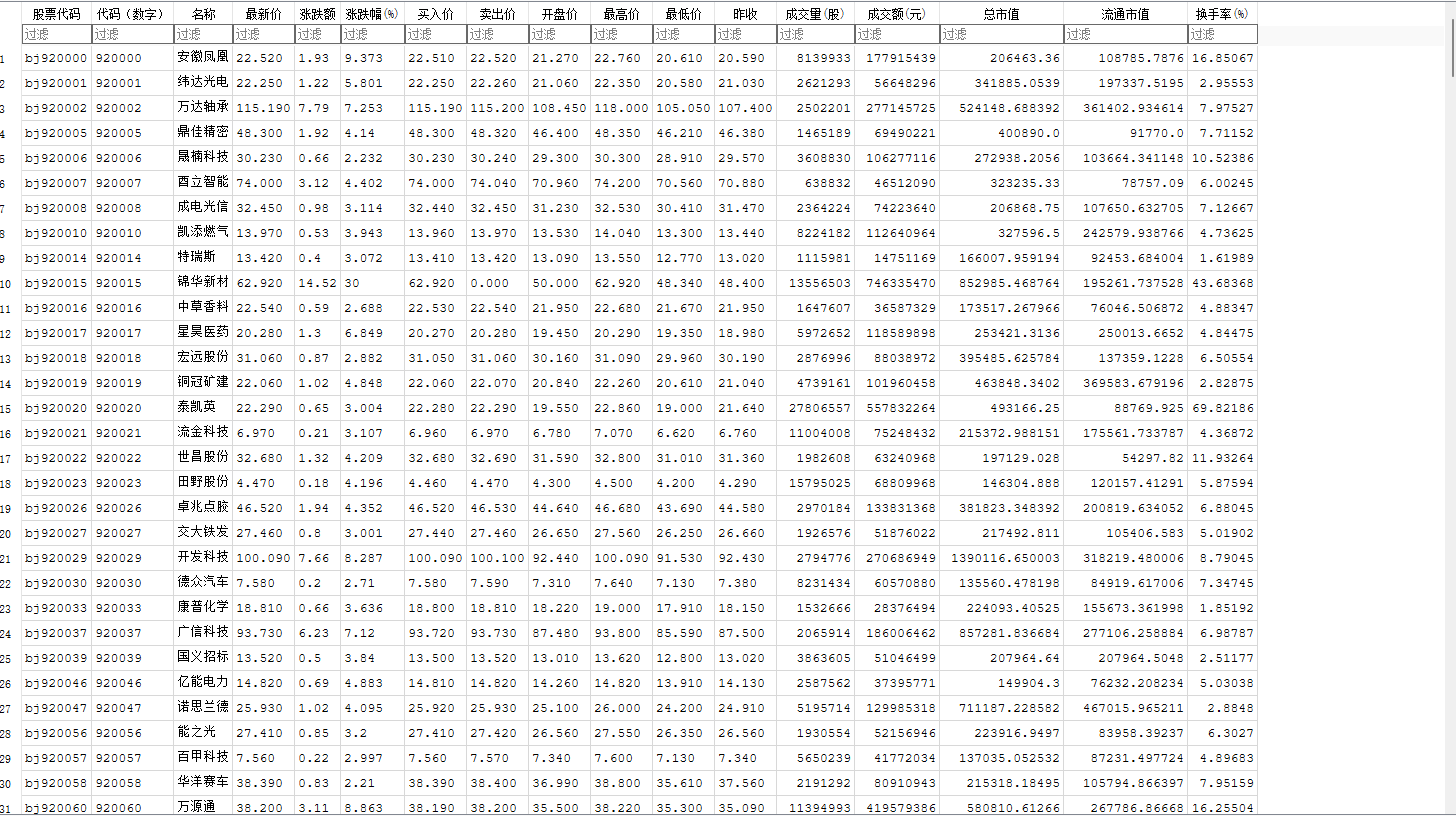
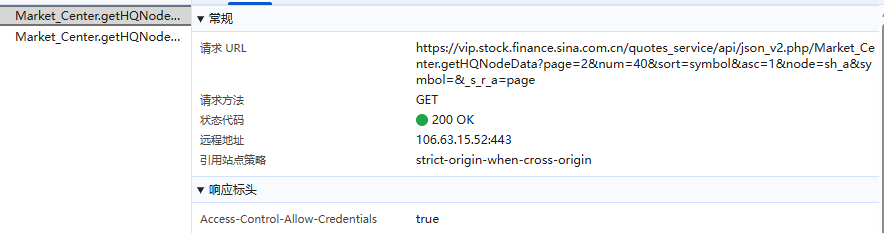
通过抓包发现其翻页有page这个参数决定。
心得体会:
学会了使用抓包的方式抓去url来爬取数据。
作业3:
–要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
抓取过程的gif图:
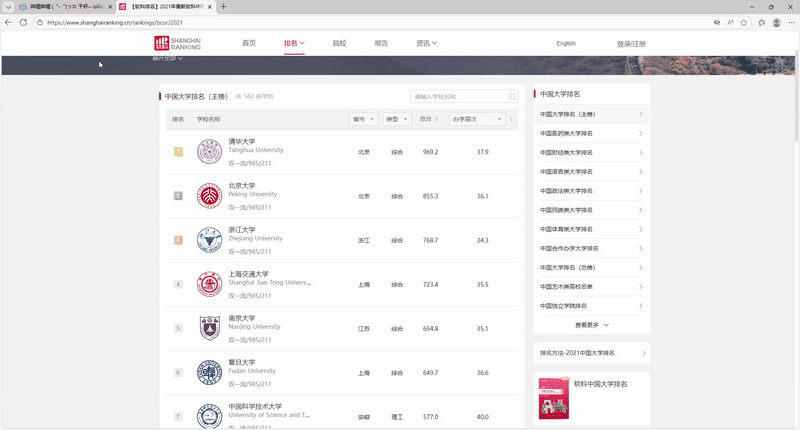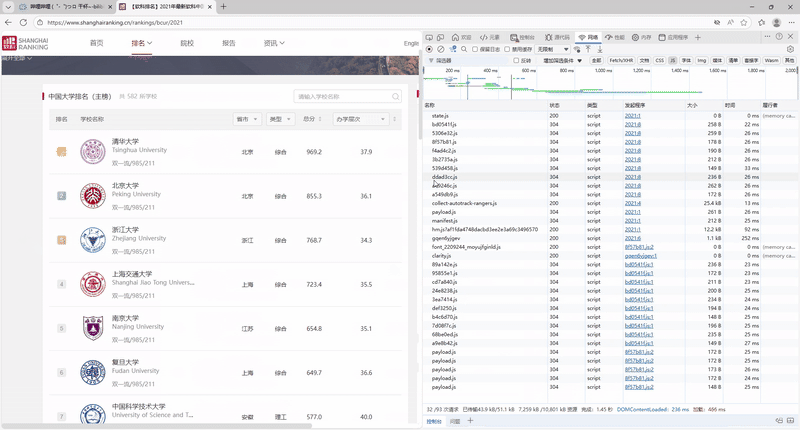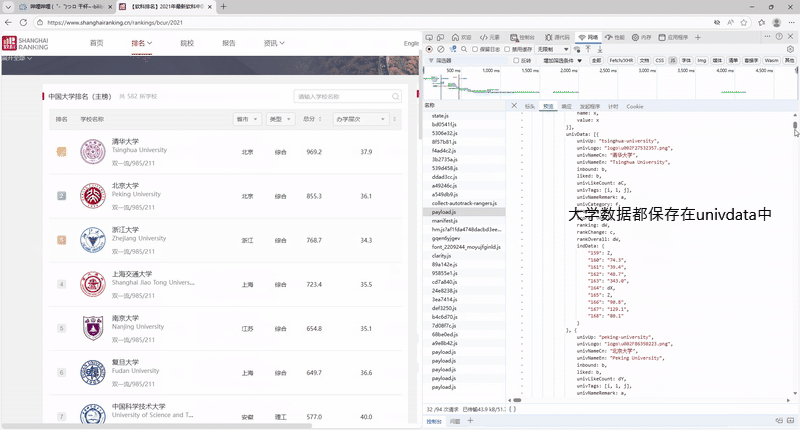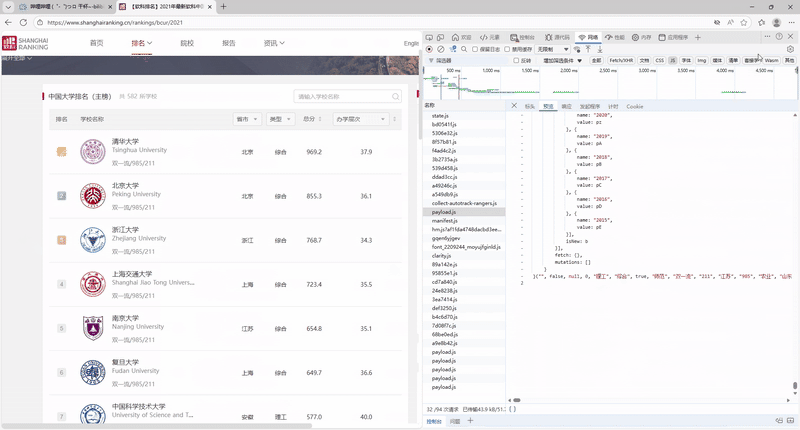
完整代码以及运行结果
import requests import json import sqlite3 import os # === 配置 === URL = "https://www.shanghairanking.cn/api/pub/v1/bcur?bcur_type=11&year=2021" HEADERS = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)", "Referer": "https://www.shanghairanking.cn/", "Accept": "application/json, text/plain, */*" } JSON_FILE = "university_rankings.json" DB_FILE = "rankings.db" # === 获取 JSON 数据 === def fetch_json(): print("正在获取大学排名数据...") response = requests.get(URL, headers=HEADERS, timeout=10) response.raise_for_status() data = response.json() print(" 数据获取成功!") return data # === 保存 JSON 到本地 === def save_json(data): with open(JSON_FILE, "w", encoding="utf-8") as f: json.dump(data, f, ensure_ascii=False, indent=4) print(f"JSON 已保存到 {JSON_FILE}") # === 解析 JSON 数据 === def parse_universities(data): raw_data = data.get("data") if raw_data is None: raise RuntimeError(" JSON 格式异常:未找到 data 字段") if isinstance(raw_data, str): try: raw_data = json.loads(raw_data) except json.JSONDecodeError: raise RuntimeError(" 无法解析 data 字符串为 JSON") if isinstance(raw_data, dict) and "rankings" in raw_data: raw_data = raw_data["rankings"] if not isinstance(raw_data, list): raise RuntimeError(f" 解析后的 data 不是列表,而是 {type(raw_data)}") universities = [] for item in raw_data: if not isinstance(item, dict): continue name_cn = item.get("univNameCn") or "未知" name_en = item.get("univNameEn") or "" rank = item.get("rank") or item.get("ranking") score = item.get("score") province = item.get("province") or "未知" category = item.get("univCategory") or "未知" region = item.get("region") or "" tags = item.get("univTags") if isinstance(tags, list): tags = ", ".join(tags) elif tags is None: tags = "" universities.append((name_cn, name_en, rank, score, province, category, region, tags)) print(f" 共解析到 {len(universities)} 所大学。") return universities # === 保存到 SQLite 数据库 === def save_to_db(universities): conn = sqlite3.connect(DB_FILE) cur = conn.cursor() cur.execute(""" CREATE TABLE IF NOT EXISTS university_rankings ( id INTEGER PRIMARY KEY AUTOINCREMENT, name_cn TEXT, name_en TEXT, rank INTEGER, score REAL, province TEXT, category TEXT, region TEXT, tags TEXT ) """) cur.executemany(""" INSERT INTO university_rankings (name_cn, name_en, rank, score, province, category, region, tags) VALUES (?, ?, ?, ?, ?, ?, ?, ?) """, universities) conn.commit() conn.close() print(f" 数据已成功保存到 {DB_FILE} 数据库") def main(): data = fetch_json() save_json(data) universities = parse_universities(data) save_to_db(universities) if __name__ == "__main__": main()
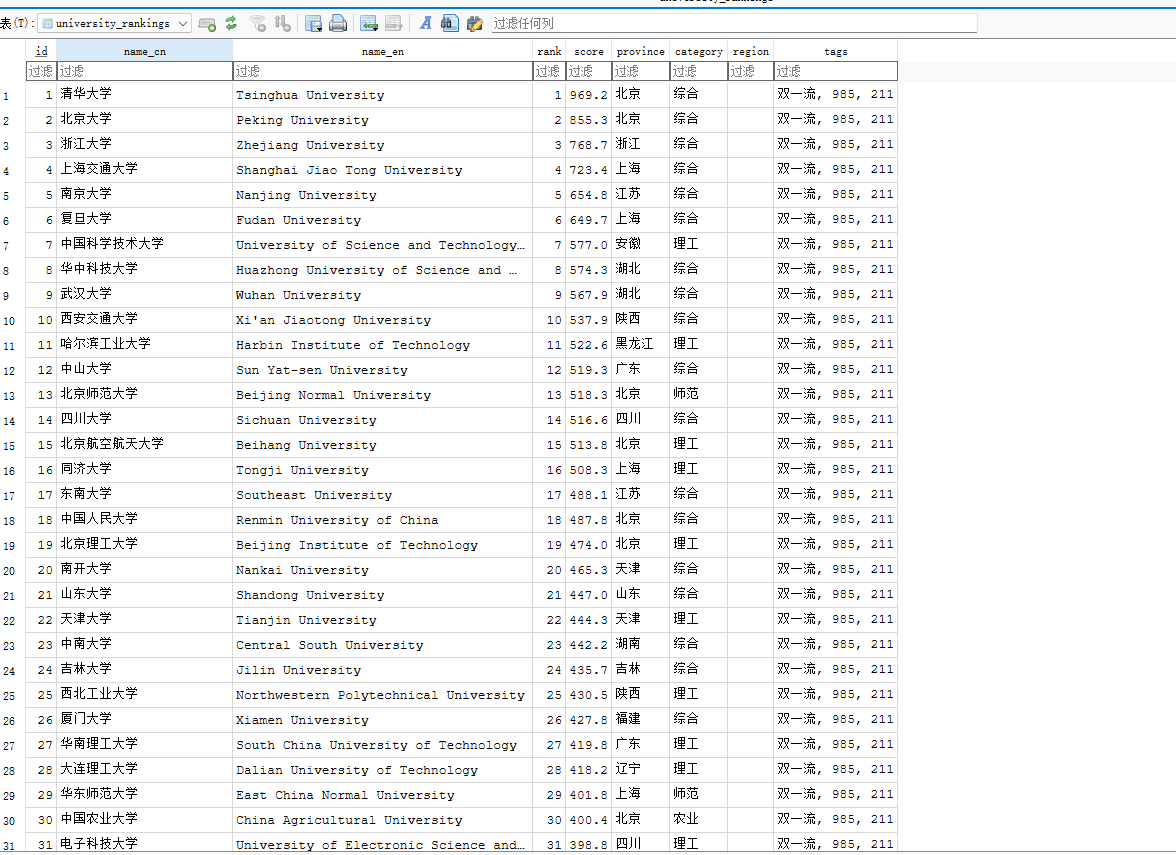
心得体会:
这个任务的抓包我是通过将抓到的json保存到本地再进行解析,通过这次任务我又对抓包的理解更深了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号