
博客1
作业1:
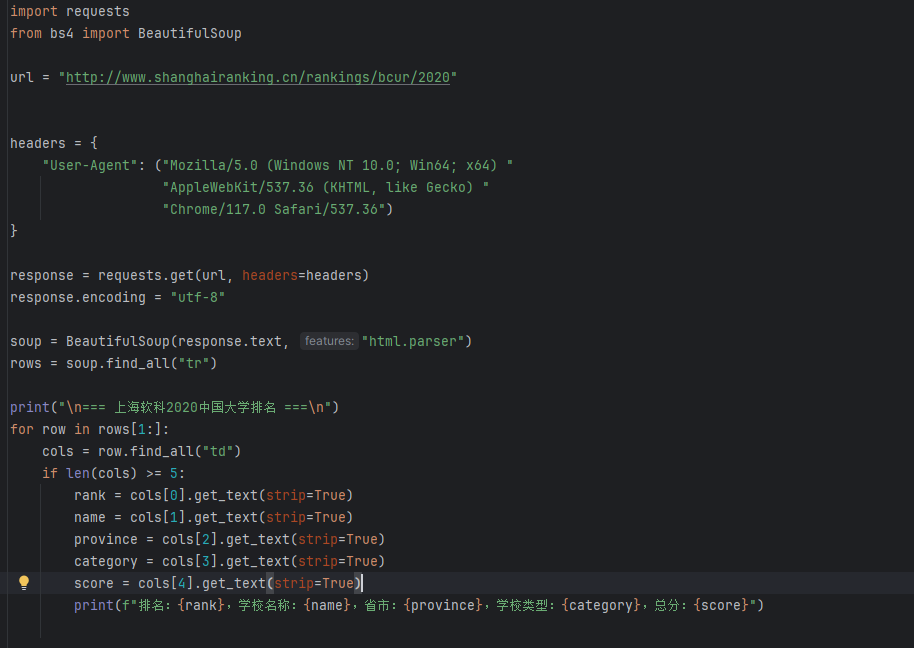
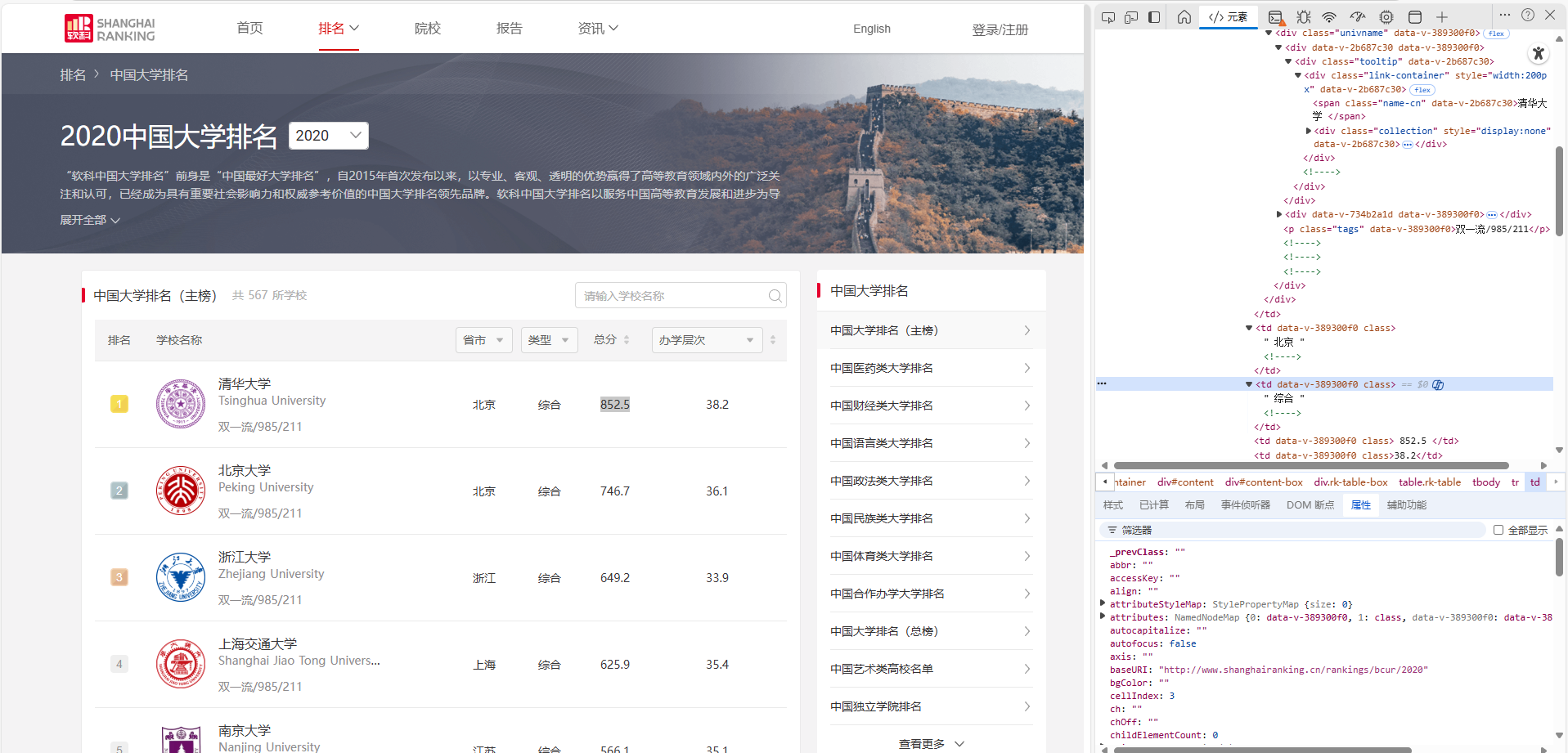
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
完整代码以及运行结果

心得体会:
学会了使用BeautifulSoup的常用方法。
作业2:
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
完整代码以及运行结果



心得体会:
在数据提取阶段,我设计并优化了正则表达式,使其能同时匹配 title 或 alt 属性,从而更准确地获取商品名。同时,对价格部分进行了容错处理,以适应网页结构中可能存在的空格或小数。通过这次实验,我加深了对正则表达式的理解。
作业3:
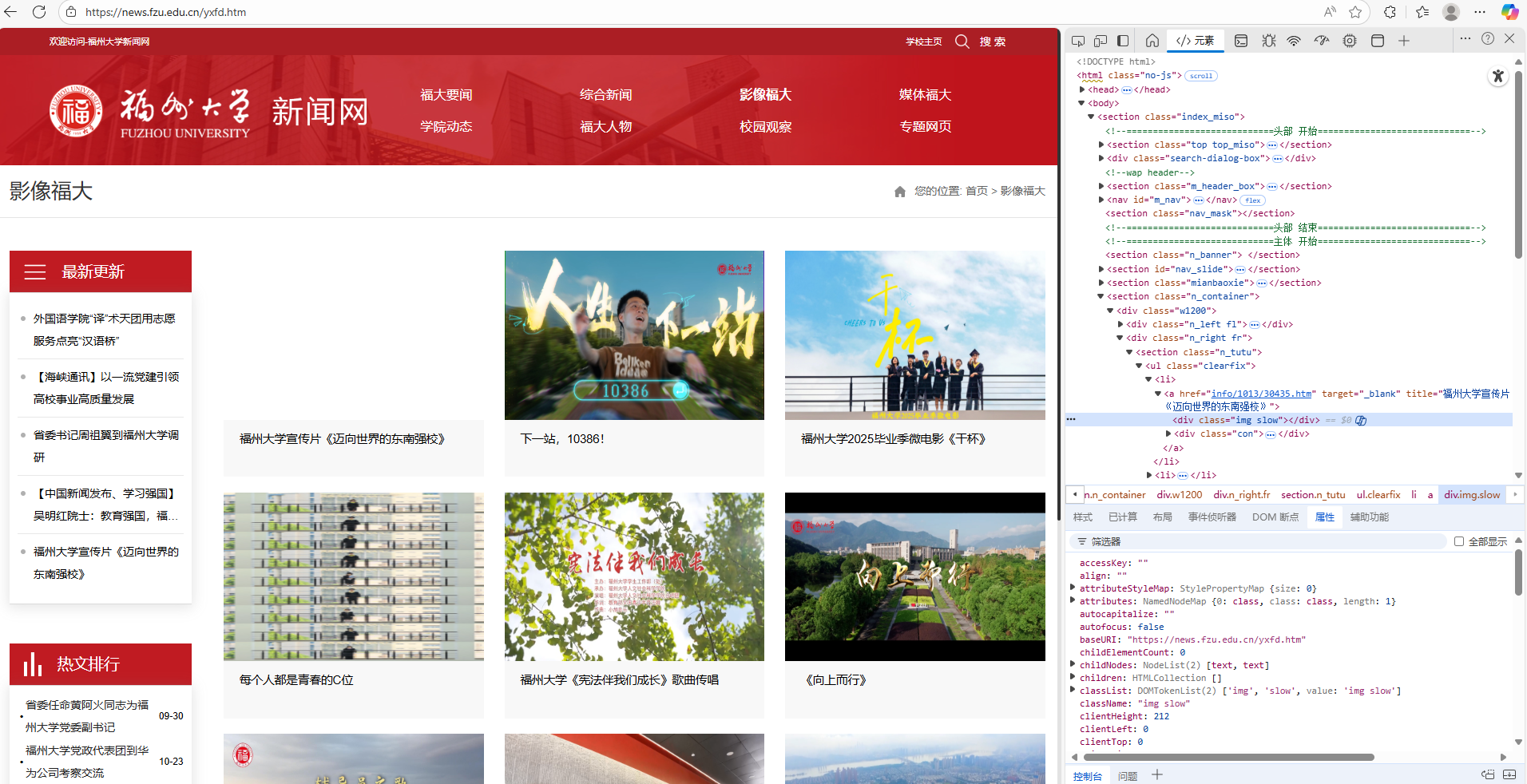
爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
输出信息:将自选网页内的所有JPEG、JPG或PNG格式文件保存在一个文件夹中
完整代码以及运行结果



心得体会:
我主要使用了 urllib.request 来获取网页内容,用正则表达式匹配出所有 .jpg、.jpeg、.png 格式的图片地址,并自动下载到本地文件夹中。通过这次任务我对实际应用正则表达式有了更好的理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号