Zookeeper+Hadoop完全分布式HA部署
1. 环境准备
1.1. 服务器规划
|
名称 |
IP |
|
hadoop1 |
192.168.10.51/16 |
|
hadoop2 |
192.168.10.52/16 |
|
hadoop3 |
192.168.10.53/16 |
1.2. 节点部署规划
|
Hadoop1 |
Hadoop2 |
Hadoop3 |
备注 |
|
NameNode |
NameNode |
|
|
|
resourcemanager |
resourcemanager |
|
yarn-site.xml,这里配哪一台,哪一台启动ResourceManager |
|
|
NodeManager |
NodeManager |
DataNode、NodeManager决定于: 当namenode跑的时候,会通过配置文件开始扫描slaves文件,slaves文件有谁,谁启动dataNode.
|
|
ZKFC |
ZKFC |
|
|
|
|
DataNode |
DataNode |
|
|
journalnode |
journalnode |
journalnode |
|
|
zookeeper |
zookeeper |
zookeeper |
|
1.3. 目录规划
|
序号 |
目录 |
路径 |
|
1 |
所有软件目录 |
/home/hadoop/app/ |
|
2 |
所有数据和日志目录 |
/home/hadoop/data/ |
2. 集群基础环境准备
2.1. 修改主机名(群集)
|
[root@localhost ~]# for i in `seq 1 3`;do echo HOSTNAME=hadoop$i > 192.168.10.5$:/etc/sysconfig/network;done [root@localhost .ssh]# for i in `seq 2 3`;do sshpass -p zq@123 ssh -o StrictHostKeychecking=no root@192.168.10.5$i reboot;done |
2.2. 修改hosts(群集)
|
[root@localhost ~]# for i in `seq 1 3 `;do echo 192.168.10.5$i hadoop$i >> /etc/hosts;done [root@localhost ~]# for i in `seq 2 3`;do scp /etc/hosts 192.168.10.5$i:/etc/hosts;done |
2.3. 用户创建(单机)
[root@localhost ~]# useradd -m hadoop -s /bin/bash
[root@localhost ~]# passwd hadoop
Changing password for user hadoop.
New password:
BAD PASSWORD: The password is shorter than 8 characters
Retype new password:
passwd: all authentication tokens updated successfully.
|
2.4. hadoop用户创建(群集)
|
[root@hadoop1 ~]#for i in `seq 2 3`;do ssh hadoop$i useradd -m hadoop -s /bin/bash;done |
2.5. hadoop用户修改密码(群集)
|
[root@hadoop1 ~]# for i in `seq 2 3`;do ssh hadoop$i 'echo hadoop|passwd --stdin hadoop';done |
2.6. 为hadoop增加管理员权限
|
|
2.7. root用户配置ssh免密登陆
2.7.1. hadoop1-hadoop3机器
|
[root@localhost ~]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: 7f:45:11:68:e0:5d:27:0b:37:b1:db:b7:2d:e0:7e:ef root@localhost.localdomain The key's randomart image is: +--[ RSA 2048]----+ | ....Oo.| | . .o+ B | | ... + | | . o | | S . o o| | . . o +| | . o ...| | o .. | | .. oE| +-----------------+ |
2.7.2. hadoop1机器
|
cat id_rsa.pub >> authorized_keys |
2.7.3. hadoop2-3机器
|
[root@hadoop2 .ssh]# ssh-copy-id -i hadoop1 [root@hadoop3 .ssh]# ssh-copy-id -i hadoop1 |
2.7.4. hadoop1机器
|
[root@hadoop1 .ssh]# chmod 600 authorized_keys [root@hadoop1 .ssh]# for i in `seq 2 3`;do scp authorized_keys 192.168.10.5$i:/root/.ssh/authorized_keys ;done |
2.8. hadoop用户配置ssh免密登陆
2.8.1. hadoop1-hadoop3机器
|
[hadoop@hadoop1 .ssh]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa. Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub. The key fingerprint is: b2:72:3a:58:a5:22:a6:f7:cd:44:2f:9f:1e:d3:07:d2 hadoop@hadoop1 The key's randomart image is: +--[ RSA 2048]----+ | | | | | | | . . | | oo S E | |... o. + o . | |o. +. = + . . | |. o .B o + . | | . .o.o.+ | +-----------------+ |
2.8.2. hadoop1机器
|
[hadoop@hadoop1 .ssh]cat .ssh/id_rsa.pub >> authorized_keys |
2.8.3. hadoop2-3机器
|
[hadoop@hadoop2 .ssh]ssh-copy-id -i hadoop1 [hadoop@hadoop3 .ssh]ssh-copy-id -i hadoop1 |
2.8.4. hadoop1机器
|
[hadoop@hadoop1 .ssh]chmod 600 authorized_keys [hadoop@hadoop2 .ssh]for i in `seq 2 3`;do scp authorized_keys hadoop$i:/home/hadoop/.ssh/authorized_keys |
注意权限问题:
Chmod 600 .ssh/authorized_keys
Chmod 700 .ssh
2.9. java环境配置
2.9.1. hadoop1机器
|
[root@hadoop1 soft]# ./javainstall.sh [root@hadoop1 soft]# for i in `seq 2 3`;do scp /soft/jdk-* hadoop$i:/soft/ ;done [root@hadoop1 soft]# for i in `seq 2 3`;do scp /soft/java* hadoop$i:/soft/ ;done [root@hadoop1 soft]# for i in `seq 2 3`;do ssh hadoop$i sh /soft/javainstall.sh ;done [root@hadoop1 soft]#for i in `seq 2 3`;do ssh hadoop$i ‘source /etc/profile’ ;done |
[root@hadoop1 local]# for i in `seq 2 3`;do ssh hadoop$i 'export BASH_ENV=/etc/profile' ;done
[root@hadoop1 local]# for i in `seq 2 3`;do ssh hadoop$i java -version;done
3. zookeeper安装
3.1. 创建安装目录
|
[hadoop@hadoop1 ~]$ for i in `seq 1 3`;do ssh hadoop$i 'mkdir -p /home/hadoop/app';done [hadoop@hadoop1 ~]$ for i in `seq 1 3`;do ssh hadoop$i 'mkdir -p /home/hadoop/data';done |
3.2. Hadoop1机器配置
|
[hadoop@hadoop1 ~]$tar -zxvf /soft/zookeeper-3.4.10.tar.gz -C /home/hadoop/app/zookeeper [hadoop@hadoop1 ~]$cd /home/hadoop/app/zookeeper/conf/ [hadoop@hadoop1 ~]$mv zoo_sample.cfg zoo.cfg [hadoop@hadoop1 ~]$cat zoo.cfg WARNING! The remote SSH server rejected X11 forwarding request. Last login: Tue Mar 26 01:47:38 2019 from 192.168.0.71 [hadoop@hadoop1 ~]$ cd /home/hadoop/app/zookeeper/conf/ [hadoop@hadoop1 conf]$ cat zoo.cfg # The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/home/hadoop/app/zookeeper/zkdata dataLogDir=/home/hadoop/app/zookeeper/zkdatalog # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients #maxClientCnxns=60 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # # http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 #server.服务编号=主机名称:Zookeeper不同节点之间同步和通信的端口:选举端口(选举leader) server.1=hadoop1:2888:3888 server.2=hadoop2:2888:3888 server.3=hadoop3:2888:3888 |
3.3. 将Zookeeper安装目录拷贝到其他节点上面
|
[hadoop@hadoop1 ~]$for i in `seq 2 3`;do scp -r zookeeper hadoop$i:/home/hadoop/app/;done |
3.4. 在所有节点创建目录
|
[hadoop@hadoop1 ~]$for i in `seq 2 3`;do ssh hadoop$i 'mkdir -p /home/hadoop/app/zookeeper/zkdata';done [hadoop@hadoop1 ~]$ for i in `seq 2 3`;do ssh hadoop$i 'mkdir -p /home/hadoop/app/zookeeper/zkdatalog';done [hadoop@hadoop1 ~]$for i in `seq 2 3`;do ssh hadoop$i 'touch /home/hadoop/app/zookeeper/zkdata/myid';done |
3.5. 在所有节点修改myid, 然后分别在hadoop1\hadoop2\hadoop3上面,进入zkdata目录下,创建文件myid,里面的内容分别填充为:1、2、3、
|
[hadoop@hadoop1 ~]$cd /home/hadoop/app/zookeeper/zkdata [hadoop@hadoop1 ~]echo 1 > myid |
3.6. 在所有节点配置Zookeeper环境变量
|
[hadoop@hadoop1]cat /etc/profile export JAVA_HOME=/usr/local/java/jdk1.8.0_181 export ZOOKEEPER_HOME=/home/hadoop/app/zookeeper export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$ZOOKEEPER_HOME/bin:$PATH |
3.7. 在所有节点启动zookeeper
|
[hadoop@hadoop1 ~]$ cd /home/hadoop/app/zookeeper/bin/ [hadoop@hadoop1 bin]$ pwd /home/hadoop/app/zookeeper/bin [hadoop@hadoop1 bin]$ ll total 172 -rwxr-xr-x 1 hadoop hadoop 232 Mar 23 2017 README.txt -rwxr-xr-x 1 hadoop hadoop 1937 Mar 23 2017 zkCleanup.sh -rwxr-xr-x 1 hadoop hadoop 1056 Mar 23 2017 zkCli.cmd -rwxr-xr-x 1 hadoop hadoop 1534 Mar 23 2017 zkCli.sh -rwxr-xr-x 1 hadoop hadoop 1628 Mar 23 2017 zkEnv.cmd -rwxr-xr-x 1 hadoop hadoop 2696 Mar 23 2017 zkEnv.sh -rwxr-xr-x 1 hadoop hadoop 1089 Mar 23 2017 zkServer.cmd -rwxr-xr-x 1 hadoop hadoop 6773 Mar 23 2017 zkServer.sh -rw-rw-r-- 1 hadoop hadoop 138648 Mar 26 02:57 zookeeper.out [hadoop@hadoop1 bin]$ ./zkServer.sh start [hadoop@hadoop1 bin]$ ./zkServer.sh status ###查看状态 |
3.8. 查看状态报错解决
|
[hadoop@hadoop1 bin]$ ./zkServer.sh status ZooKeeper JMX enabled by default Usingconfig: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg Error contacting service. It is probably not running. |
以上错误可以查看日志 zookeeper.out(哪个目录执行启动命令则.out就生成在哪个目录下)
通常是由于防火墙没有关闭导致
以root用户登陆查看防火墙状态并关闭防火墙
|
[root@hadoop1 ~]# systemctl status firewalld.service ● firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled) Active: active (running) since Mon 2019-03-25 02:13:01 EDT; 24h ago Main PID: 727 (firewalld) CGroup: /system.slice/firewalld.service └─727 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid
Mar 25 02:12:59 localhost.localdomain systemd[1]: Starting firewalld - dynamic firewall daemon... Mar 25 02:13:01 localhost.localdomain systemd[1]: Started firewalld - dynamic firewall daemon. [root@hadoop1 ~]# [root@hadoop1 ~]# systemctl stop firewalld.service [root@hadoop1 ~]# systemctl disable firewalld.service Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service. Removed symlink /etc/systemd/system/basic.target.wants/firewalld.service. |
3.9. 验证状态
|
[hadoop@hadoop1 bin]$ ./zkServer.sh status ZooKeeper JMX enabled by default Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg Mode: follower
[hadoop@hadoop2 ~]$ zkServer.sh status ZooKeeper JMX enabled by default Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg Mode: leader
[hadoop@hadoop3 ~]$ zkServer.sh status ZooKeeper JMX enabled by default Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg Mode: follower |
4. hadoop安装
4.1. 解压安装程序-hadoop1
|
[hadoop@hadoop1 soft]$ tar -zxvf hadoop-2.6.4.tar.gz -C /home/hadoop/app/hadoop |
4.2. 解压安装程序-hadoop1-修改配置文件
进入目录/home/hadoop/app/hadoop/etc/hadoop
|
[hadoop@hadoop1 hadoop]$ pwd /home/hadoop/app/hadoop/etc/hadoop [hadoop@hadoop1 hadoop]$ ll total 152 -rw-r--r-- 1 hadoop hadoop 4436 Mar 7 2016 capacity-scheduler.xml -rw-r--r-- 1 hadoop hadoop 1335 Mar 7 2016 configuration.xsl -rw-r--r-- 1 hadoop hadoop 318 Mar 7 2016 container-executor.cfg -rw-r--r-- 1 hadoop hadoop 774 Mar 7 2016 core-site.xml -rw-r--r-- 1 hadoop hadoop 3670 Mar 7 2016 hadoop-env.cmd -rw-r--r-- 1 hadoop hadoop 4224 Mar 7 2016 hadoop-env.sh -rw-r--r-- 1 hadoop hadoop 2598 Mar 7 2016 hadoop-metrics2.properties -rw-r--r-- 1 hadoop hadoop 2490 Mar 7 2016 hadoop-metrics.properties -rw-r--r-- 1 hadoop hadoop 9683 Mar 7 2016 hadoop-policy.xml -rw-r--r-- 1 hadoop hadoop 775 Mar 7 2016 hdfs-site.xml -rw-r--r-- 1 hadoop hadoop 1449 Mar 7 2016 httpfs-env.sh -rw-r--r-- 1 hadoop hadoop 1657 Mar 7 2016 httpfs-log4j.properties -rw-r--r-- 1 hadoop hadoop 21 Mar 7 2016 httpfs-signature.secret -rw-r--r-- 1 hadoop hadoop 620 Mar 7 2016 httpfs-site.xml -rw-r--r-- 1 hadoop hadoop 3523 Mar 7 2016 kms-acls.xml -rw-r--r-- 1 hadoop hadoop 1325 Mar 7 2016 kms-env.sh -rw-r--r-- 1 hadoop hadoop 1631 Mar 7 2016 kms-log4j.properties -rw-r--r-- 1 hadoop hadoop 5511 Mar 7 2016 kms-site.xml -rw-r--r-- 1 hadoop hadoop 11291 Mar 7 2016 log4j.properties -rw-r--r-- 1 hadoop hadoop 938 Mar 7 2016 mapred-env.cmd -rw-r--r-- 1 hadoop hadoop 1383 Mar 7 2016 mapred-env.sh -rw-r--r-- 1 hadoop hadoop 4113 Mar 7 2016 mapred-queues.xml.template -rw-r--r-- 1 hadoop hadoop 758 Mar 7 2016 mapred-site.xml.template -rw-r--r-- 1 hadoop hadoop 10 Mar 7 2016 slaves -rw-r--r-- 1 hadoop hadoop 2316 Mar 7 2016 ssl-client.xml.example -rw-r--r-- 1 hadoop hadoop 2268 Mar 7 2016 ssl-server.xml.example -rw-r--r-- 1 hadoop hadoop 2237 Mar 7 2016 yarn-env.cmd -rw-r--r-- 1 hadoop hadoop 4567 Mar 7 2016 yarn-env.sh -rw-r--r-- 1 hadoop hadoop 690 Mar 7 2016 yarn-site.xml |
4.2.1. 修改HDFS配置文件
4.2.1.1. 配置hadoop-env.sh
主要配置JAVA_HOME可以不配置,在hadoop-env.sh和mapred-env.sh还有yarn-env.sh中写上你的jdk路径(有可能这条属性被注释掉了,记得解开,把前面的#去掉就可以了)
|
|
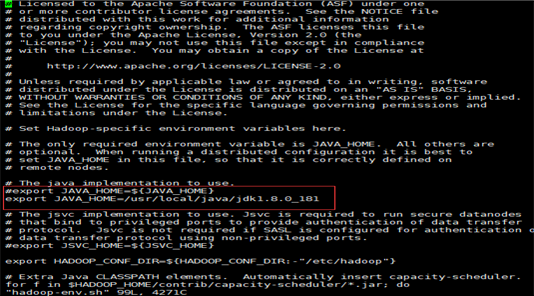
4.2.1.2. 配置core-site.xml
|
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. -->
<!-- Put site-specific property overrides in this file. -->
<configuration> <property> <name>fs.defaultFS</name> <!--把两个NameNode的地址组装成一个集群cluster1 -->
--> <value>hdfs://cluster1</value> </property> < 这里的值指的是默认的HDFS路径 ,在哪一台配,namenode就在哪一台启动> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/data/tmp</value> </property> < hadoop的临时目录,如果需要配置多个目录,需要逗号隔开,data目录需要我们自己创建> <!-指定ZKFC故障自动切换转移---> <property> <name>ha.zookeeper.quorum</name> <value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value> </property> < 配置Zookeeper 管理HDFS> </configuration> ~ ~ |
4.2.1.3. 配置hdfs-site.xml
|
[hadoop@hadoop1 hadoop]$ cat hdfs-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. -->
<!-- Put site-specific property overrides in this file. -->
<configuration> <property> <name>dfs.replication</name> <value>3</value> </property> < 数据块副本数为3> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> < 权限默认配置为false>
<property> <name>dfs.nameservices</name> <value>cluster1</value> </property> < 命名空间,它的值与fs.defaultFS的值要对应,namenode高可用之后有两个namenode,cluster1是对外提供的统一入口>
<property> <name>dfs.ha.namenodes.cluster1</name> <value>hadoop1,hadoop2</value> </property> < 指定 nameService 是 cluster1 时的nameNode有哪些,这里的值也是逻辑名称,名字随便起,相互不重复即可> <!-- hadoop1的RPC通信地址,hadoop1所在地址 --> <property> <name>dfs.namenode.rpc-address.cluster1.hadoop1</name> <value>hadoop1:9000</value> </property> <!-- hadoop1的http通信地址,外部访问地址 --> <property> <name>dfs.namenode.http-address.cluster1.hadoop1</name> <value>hadoop1:50070</value> </property> <!-- hadoop2的RPC通信地址,hadoop2所在地址 --> <property> <name>dfs.namenode.rpc-address.cluster1.hadoop2</name> <value>hadoop2:9000</value> </property> <!-- hadoop2的http通信地址,外部访问地址 --> <property> <name>dfs.namenode.http-address.cluster1.hadoop2</name> <value>hadoop2:50070</value> </property> <!-- 指定NameNode的元数据在JournalNode日志上的存放位置(一般和zookeeper部署在一起) --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/cluster1</value> </property> <!-- 指定JournalNode集群在对nameNode的目录进行共享时,JournalNode自己在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hadoop/data/journaldata</value> </property> <!--客户端通过代理访问namenode,访问文件系统,HDFS 客户端与Active 节点通信的Java 类,使用其确定Active 节点是否活跃,指定 cluster1 出故障时,哪个实现类负责执行故障切换 --> <property> <name>dfs.client.failover.proxy.provider.cluster1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--这是配置自动切换的方法,有多种使用方法,具体可以看官网,这个参数的值可以有多种,可以是shell(/bin/true),也可以是 <value>sshfence</value> 的远程登录杀死的方法,这个脚本do nothing 返回0 --> <property> <name>dfs.ha.fencing.methods</name> <value>shell(/bin/true)</value> </property> <!-- 这个是使用sshfence隔离机制时才需要配置ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <!-- 配置sshfence隔离机制超时时间,这个属性同上,如果你是用脚本的方法切换,这个应该是可以不配置的 --> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>10000</value> </property> < 脑裂默认配置> <!-- 这个是开启自动故障转移,如果你没有自动故障转移,这个可以先不配,可以先注释掉 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration> |
4.2.1.4. 配置slave
DataNode、NodeManager决定于:slaves文件。(默认localhost,删掉即可)
谁跑dataNode,slaves文件写谁。当namenode跑的时候,会通过配置文件开始扫描slaves文件,slaves文件有谁,谁启动dataNode.当启动yarn时,会通过扫描配置文件开始扫描slaves文件,slaves文件有谁,谁启动NodeManager
|
[hadoop@hadoop1 hadoop]$ cat slaves hadoop2 hadoop3 |
4.2.2. 修改yarn配置文件
4.2.2.1. 配置mapred-site.xml
[hadoop@hadoop1 hadoop]$ mv mapred-site.xml.template mapred-site.xml
|
[hadoop@hadoop1 hadoop]$ cat mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. -->
<!-- Put site-specific property overrides in this file. -->
<configuration> <!-- 指定mr运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> |
4.2.2.2. 配置yarn-site.xml
|
[hadoop@hadoop1 hadoop]$ cat yarn-site.xml <?xml version="1.0"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <configuration>
<!-- Site specific YARN configuration properties --> <!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--启用resourcemanager ha--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--声明两台resourcemanager的地址--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>rmCluster</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>hadoop1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>hadoop2</value> </property> <!--指定zookeeper集群的地址--> <property> <name>yarn.resourcemanager.zk-address</name> <value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value> </property> <!--启用自动恢复--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--指定resourcemanager的状态信息存储在zookeeper集群--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> </configuration> |
4.2.3. 分发hadoop文件到所有节点
[hadoop@hadoop1 hadoop]$ for i in `seq 2 3`;do scp -r /home/hadoop/app/hadoop hadoop$i:/home/hadoop/app/;done
4.2.4. 修改hadoop环境变量
切换到root用户执行hadoop1
|
[root@hadoop1 ~]# cat /etc/profile # /etc/profile
# System wide environment and startup programs, for login setup # Functions and aliases go in /etc/bashrc
# It's NOT a good idea to change this file unless you know what you # are doing. It's much better to create a custom.sh shell script in # /etc/profile.d/ to make custom changes to your environment, as this # will prevent the need for merging in future updates.
pathmunge () { case ":${PATH}:" in *:"$1":*) ;; *) if [ "$2" = "after" ] ; then PATH=$PATH:$1 else PATH=$1:$PATH fi esac }
if [ -x /usr/bin/id ]; then if [ -z "$EUID" ]; then # ksh workaround EUID=`id -u` UID=`id -ru` fi USER="`id -un`" LOGNAME=$USER MAIL="/var/spool/mail/$USER" fi
# Path manipulation if [ "$EUID" = "0" ]; then pathmunge /usr/sbin pathmunge /usr/local/sbin else pathmunge /usr/local/sbin after pathmunge /usr/sbin after fi
HOSTNAME=`/usr/bin/hostname 2>/dev/null` HISTSIZE=1000 if [ "$HISTCONTROL" = "ignorespace" ] ; then export HISTCONTROL=ignoreboth else export HISTCONTROL=ignoredups fi
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL
# By default, we want umask to get set. This sets it for login shell # Current threshold for system reserved uid/gids is 200 # You could check uidgid reservation validity in # /usr/share/doc/setup-*/uidgid file if [ $UID -gt 199 ] && [ "`id -gn`" = "`id -un`" ]; then umask 002 else umask 022 fi
for i in /etc/profile.d/*.sh ; do if [ -r "$i" ]; then if [ "${-#*i}" != "$-" ]; then . "$i" else . "$i" >/dev/null fi fi done
unset i unset -f pathmunge export JAVA_HOME=/usr/local/java/jdk1.8.0_181 export ZOOKEEPER_HOME=/home/hadoop/app/zookeeper export HADOOP_HOME=/home/hadoop/app/hadoop export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$PATH |
[root@hadoop1 ~]# for i in `seq 2 3`;do scp /etc/profile hadoop$i:/etc/profile;done
Hadoop1-3 source /etc/profile
5. 启动集群
前提条件:
修改JAVA环境变量:
mapred-env.sh
yarn-env.sh
hadoop-env.sh
export JAVA_HOME /usr/local/java/jdk1.8.0_181
5.1. 启动zookeeper
[hadoop@hadoop1 ~]$ zkServer.sh start
[hadoop@hadoop2 ~]$ zkServer.sh start
[hadoop@hadoop3 ~]$ zkServer.sh start
检查状态
[hadoop@hadoop1 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[hadoop@hadoop2 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Mode: leader
[hadoop@hadoop3 ~]$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[hadoop@hadoop1 ~]$ jps
QuorumPeerMain(存在)
[hadoop@hadoop2 ~]$ jps
QuorumPeerMain(存在)
[hadoop@hadoop3 ~]$ jps
QuorumPeerMain(存在)
5.2. 启动journalnode服务
启动Journalnode是为了创建namenode元数据存放目录
[hadoop@hadoop1 ~]$ hadoop-daemon.sh start journalnode
[hadoop@hadoop2 ~]$ hadoop-daemon.sh start journalnode
[hadoop@hadoop3 ~]$ hadoop-daemon.sh start journalnode
结确认
Jps 三个节点都存在JournalNode进程
主namenode data目录下创建目录成功

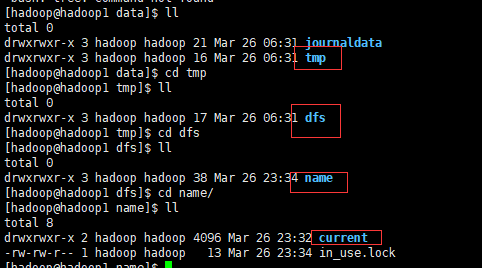
5.3. 格式化主Namenode
在主namenode节点执行
[hadoop@hadoop1 ~]$hdfs namenode –format
结果确认:存在以下目录
5.4. 启动主Namenode
[hadoop@hadoop1 ~]$ hadoop-daemon.sh start namenode
Jps查看存在namenode
5.5. 同步主Namenode(hadoop1)的信息到备namenode(hadoop2)上面
在namenode(hadoop2)上面执行命令同步
[hadoop@hadoop2 ~]$hdfs namenode –bootstrapStandby
结果确认:data目录下存在以下目录文件
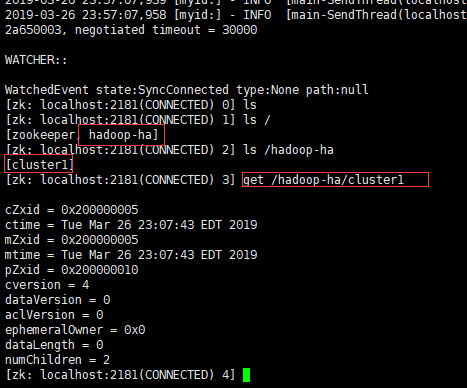
5.6. 只在主NameNode上格式化zkfc,创建znode节点
[hadoop@hadoop1 ~]$ hdfs zkfc –formatZK
结果存在zkCli.sh
5.7. 停掉主namenode和所有的journalnode进程
[hadoop@hadoop1 ~]$hadoop-daemon.sh stop namenode
[hadoop@hadoop1 ~]$ hadoop-daemon.sh stop journalnode
[hadoop@hadoop2 ~]$ hadoop-daemon.sh stop journalnode
[hadoop@hadoop3 ~]$ hadoop-daemon.sh stop journalnode
jps检查只存在zookeeper
5.8. 启动hdfs
[hadoop@hadoop1 ~]$start-dfs.sh
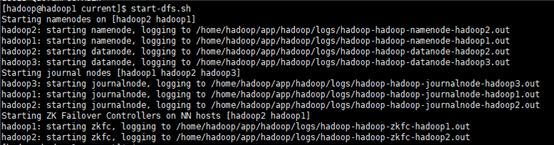
Jps检查进程
5.9. 问题处理
重新格式化后jps检查其余都正常只是没有datanode
在对应的hadoop2-hadoop3的log下面查看报错:

问题分析:
datanode的clusterID 和 namenode的clusterID 不匹配
查看namenode节点上的cluserID
路径:
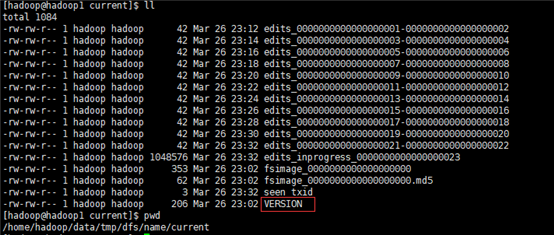
Cat VERSION
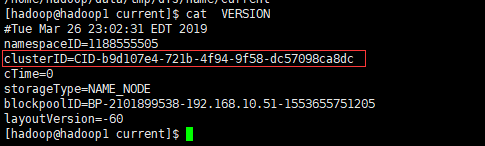
所有dataNode的clusterID查看路径

将NAMENODE的CLUSTERID复制覆盖DATANODE的CLUSTERID
启动正常
6. 启动yarn集群
6.1. 在主namenode节点上启动yarn集群
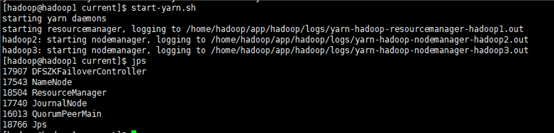
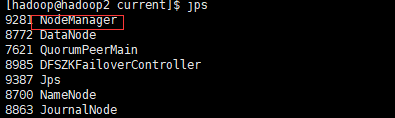
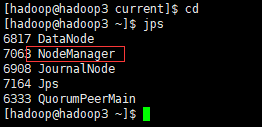
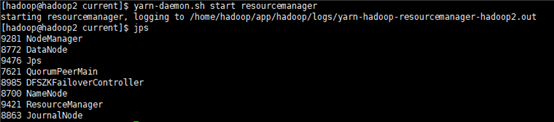
6.2. 在备节点上手动启动resourceMabager
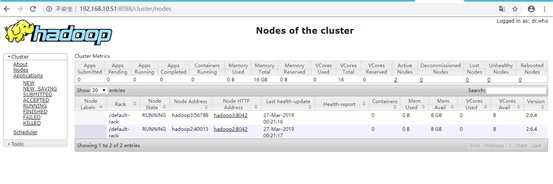
6.3. 访问yarn
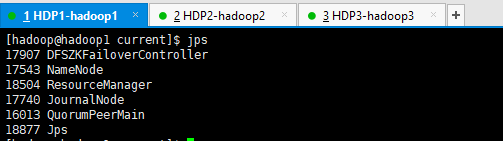
6.4. 集群角色分布情况
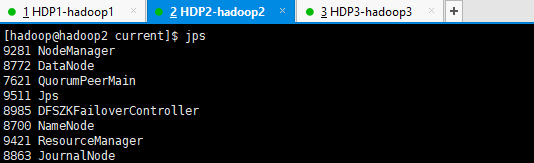
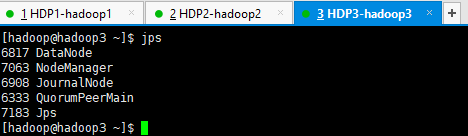

 浙公网安备 33010602011771号
浙公网安备 33010602011771号