
hash一致算法原理
hash一致算法原理
hash一致算法被用于memcached的集群,memcached的集群主要有hash与一致性hash。下面分别解释这两种算法的原理。
hash集群算法。
由于memcached的集群方式是每个节点存储的内容都不一样,所以在集群时要用个算法来选择存储和读时在哪台服务器。这就是hash算法,这个算法比较简单,跟haspmap的算法一样,余数分散(就是hashcode%服务器个数来决定放在哪台服务器) 。这种算法的问题:在服务器个数变更了,大部分数据就会丢掉。因为服务器个数变更后,余数变了。所以要缓存重组,数据量大的话代价太大。
一致性hash
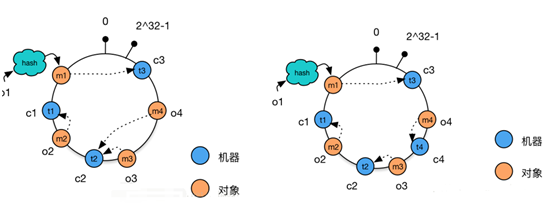
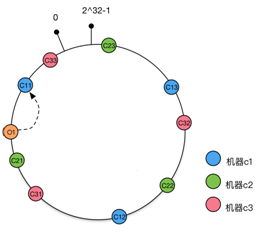
如何解决缓存重组。,数据的hashcode与所属服务器虚拟节点关联起来放到一个顺时针大环中。服务器与数据的hashcode都放在这个大环中,重点:服务器节点与数据节点的关系是怎样的呢?数据的hashcode最接近的一个服务器节点hashcode就是这个数据节点的服务器。所以读与写数据都是找最接近的服务器节点。 在物理服务器个数变更时,不需要全部缓存重组。因为这个环是有序的,所以删除点节,只会影响到这个节点上的数据,其他的不用调整。添加新节点时,就是将顺时针最靠近的那个节点的部分最靠近新节点的数据点的数据往新节点迁移就行了。
添加虚拟节点
仅仅使用真实的节点来形成环的结构可能会导致数据的倾斜,为了解决这种数据不对称的现象,可以在原理缓存的机器的基础上,增加相应的虚拟节点,这样数据就会均匀的打散到其他节点中。
这个时候客户端进行数据存取的时候找的就是虚拟节点,而不是真实的物理节点服务器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号