弹性线程池的实现
前置知识
并发和并行
CPU单核
CPU多核、多CPU
并发
单核上,多个线程占用不同的CPU时间片,物理上还是串行执行的,但是由于每个线程占用的CPU时间
片非常短(比如10ms),看起来就像是多个线程都在共同执行一样,这样的场景称作并发(concurrent)。
并行
在多核或者多CPU上,多个线程是在真正的同时执行,这样的场景称作并行(parallel)。
多线程一定能优化程序性能吗?
多线程与CPU
多线程与CPU是程序员了解的最多的,我们知道多线的目的之一在于充分利用多核,但这里有个前提就是你要处理的任务真的能拆分成独立的子任务。
举个例子,如果你想对一个数组所有元素的和,那么这个任务就可以拆分成为两个独立的子任务:任务A计算前一半数组元素的和,任务B计算后一半数组元素的和,然后任务A和任务B分别交给两个线程来执行。
如果是在多核系统下这类多线程并行处理将显著提高程序性能,但这种使用多线程充分利用多核带来的性能提升是有上限的。
道理很简单,这就好比盖房子,盖房子算是个不大不小的工程,让一个人来完成也不是不可以,但再来六七个人显然能加快工程速度,但是再来成百上千工人来盖一栋房子可能速度反而会变慢,毕竟资源是有限的(可用的工具等),人一多需要用在协调上的时间就会变多,多线程也是同样的道理,当线程数量超过某个临界点时操作系统就开始忙不过来了(频繁调度切换),我称之为三个和尚没水喝现象。

但如果系统是单核的,那么这种任务拆分则不会有什么效果,因为不管你创建多少线程真正工作的CPU只有一个。
当然也有可能我们根本就不能对任务进行拆分,像计算斐波那契数列这类问题,如果你不能计算出f(n-1)与f(n-2)的解,那么你根本就没有办法计算出当前问题f(n)的解,被拆分的两个任务A和B有前后依赖关系,这时多线程就没有用武之地了。
还有一种可能,就是你的问题规模非常小,如果这个数组是有几百几千个元素,那么这时你使用多线程意义不大,这时使用多线程带来的收益不足以抵消掉多线程带来的性能开销。
多线程与IO
多线程一定能提升程序的IO性能吗?答案显然不是的。
最简单的场景是这样的,你的程序需要从一个速度极慢的网络链接上读写数据,在这种情况下一个线程很可能就足以应付的过来,创建多个线程反而可能对程序性能有损。
相同的情况也会出现在磁盘上,一个线程可能就已经将磁盘打满,这时创建多个线程去读写文件显然不能加快程序的处理速度。
而在服务器端,程序员也使用多线程加快程序处理速度,在这里,一个典型的问题是阻塞式网络IO会导致调用线程被挂起而暂停运行,此时最简单的方法就是创建多个线程,每个线程处理一个请求,但随着请求的增多创建的线程也会越来越多,此时三个和尚没水喝现象开始出现,IO多路复用技术可以很好的解决这一问题。
当然,如果你的场景是IO会阻塞住处理线程,那么此时创建两个线程,一个负责处理数据,一个负责等待IO,那么这显然会提高程序性能。
多线程与内存
内存其实和磁盘一样,也是有读写带宽上限的,但我们的程序一般都不会达到内存读写带宽上限,这并不是瓶颈。
瓶颈在于多线程共享的内存资源(数据)以及多核系统的cache一致性问题。
一般来说,对于多线程共享资源通常需要互斥访问,然而为加快内存读写速度,现代处理器中都有cache系统(L1、L2、L3),每个核心都有自己的cache,这些cache会缓存内存数据,也就是说一份数据可能会同时存在于内存以及各个核心的cache中,这就会带来经典的数据一致性问题:某个核心修改了cache中的数据后需要将其同步给其它核心,这就要求cache系统中必须有能确保一致性的协议,否则程序可能会读取到错误的(过期的)数据。
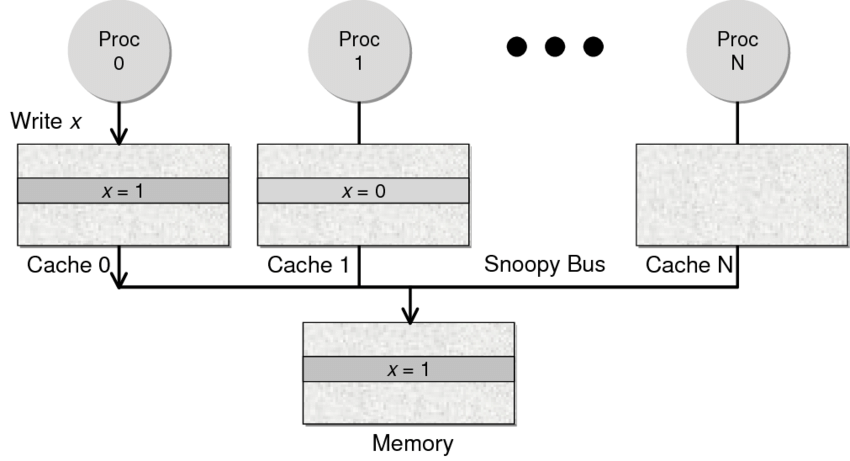

然而这种同步是有性能损耗的,多个线程频繁操作同一个变量可能导致处理器cache系统需要频繁在各个核心之间进行同步,极端情况下多线程程序性能甚至比单线程要差。
因此多线程之间能不共享数据就不要共享,如果一定要共享,那么就尽量将其控制在最小范围,读写频次控制到最少。
线程池
线程的消耗
为了完成任务,创建很多的线程可以吗?线程真的是越多越好?
- 线程的创建和销毁都是非常"重"的操作
- 线程栈本身占用大量内存
- 线程的上下文切换要占用大量时间
- 大量线程同时唤醒会使系统经常出现锯齿状负载或者瞬间负载量很大导致宕机
线程池的优势
- 操作系统上创建线程和销毁线程都是很"重"的操作,耗时耗性能都比较多,那么在服务执行的过程中,如果业务量比较大,实时的去创建线程、执行业务、业务完成后销毁线程,那么会导致系统的实时性能降低,业务的处理能力也会降低。
- 线程池的优势就是(每个池都有自己的优势),在服务进程启动之初,就事先创建好线程池里面的线程,当业务流量到来时需要分配线程,直接从线程池中获取一个空闲线程执行task任务即可,task执行完成后,也不用释放线程,而是把线程归还到线程池中继续给后续的task提供服务。
Fixed模式线程池
线程池里面的线程个数是固定不变的,一般是ThreadPool创建时根据当前机器的CPU核心数量进行指
定。
Cached模式线程池
线程池里面的线程个数是可动态增长的,根据任务的数量动态的增加线程的数量,但是会设置一个线程数量的阈值(线程过多的坏处上面已经讲过了),任务处理完成,如果动态增长的线程空闲了60s还没有处理其它任务,那么关闭线程,保持池中最初数量的线程即可。
// 线程池支持的模式
enum class PoolMode
{
MODE_FIXED, // 固定数量的线程
MODE_CACHED, // 线程数量可动态增长
};
线程同步
线程互斥
- 互斥锁mutex
- atomic原子类型
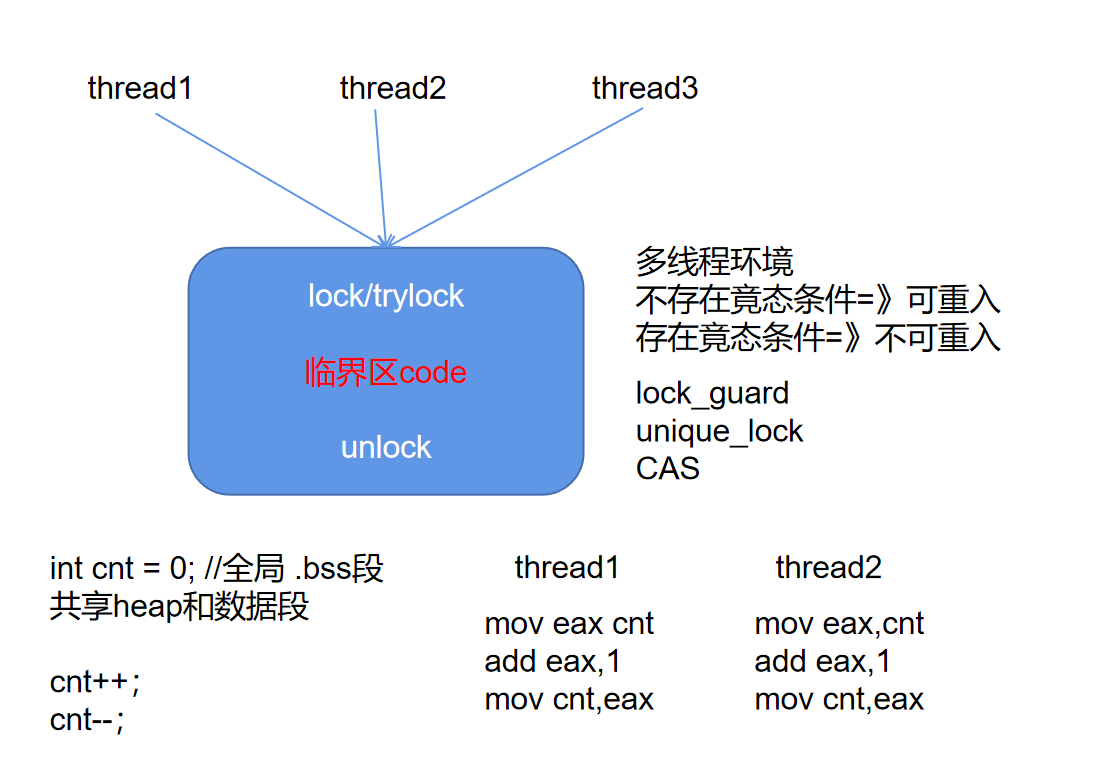
线程通信
- 条件变量 condition_variable
- 信号量 semaphore(C++20)
通过条件变量(mutex+condition_variable)实现一个semaphore类
c++中lock_guard以及unique_lock的区别
- unique_lock可以实现延时锁,即先生成unique_lock对象,然后在有需要的地方调用lock函数,lock_guard在对象创建时就自动进行lock操作了;
- unique_lock可以在需要的地方调用unlock操作,而lock_guard只能在其对象生命周期结束后自动Unlock;
正是由于这两个差异特性,unique_lock可以用于一次性锁多个锁以及用于条件变量的搭配使用,而lock_guard做不到。
线程池的整体概览
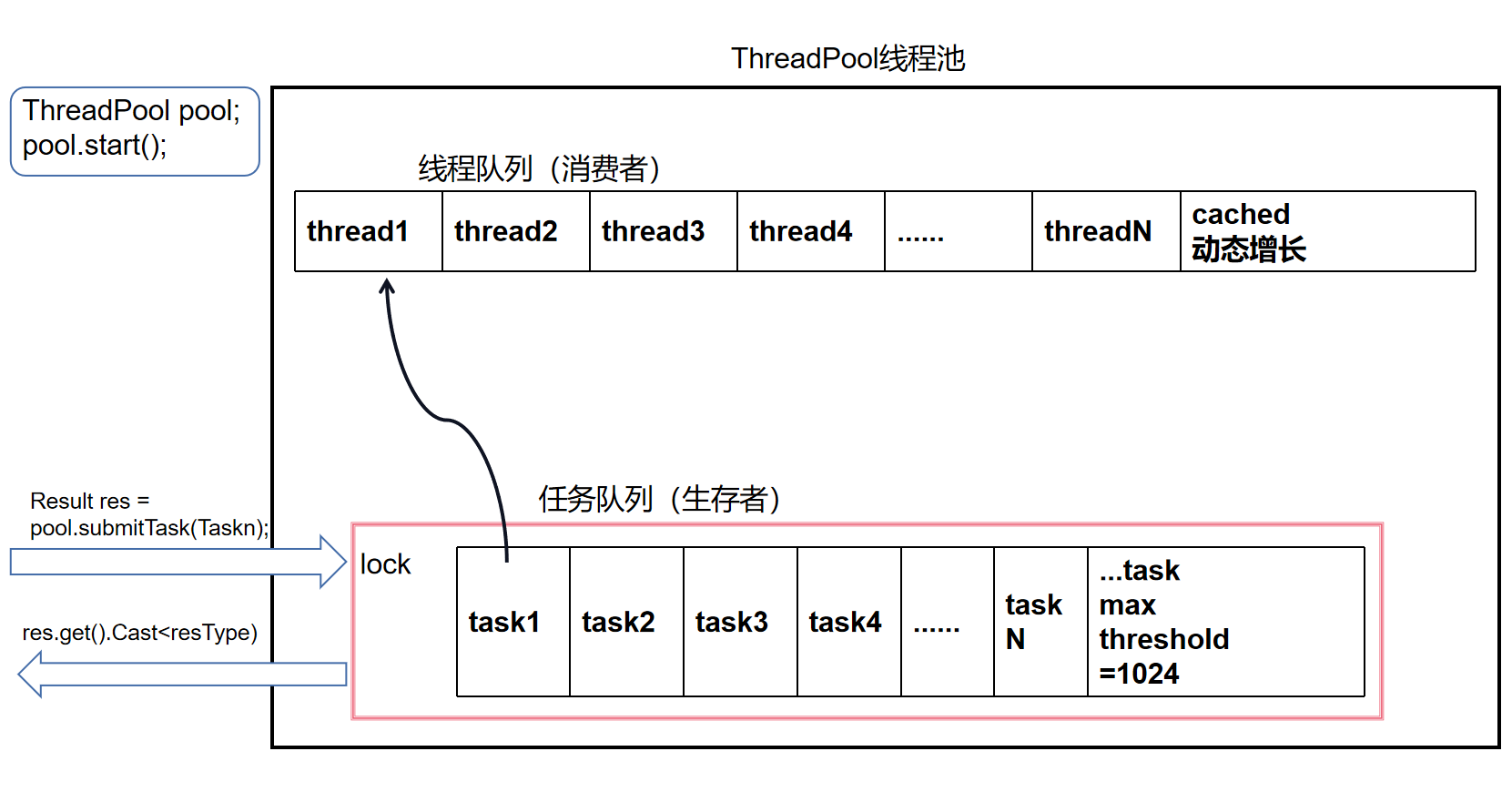
ThreadPool
// 线程池类型
class ThreadPool
{
public:
// 线程池构造
ThreadPool();
// 线程池析构
~ThreadPool();
// 设置线程池的工作模式
void setMode(PoolMode mode);
// 设置task任务队列上线阈值
void setTaskQueMaxThreshHold(int threshhold);
// 设置线程池cached模式下线程阈值
void setThreadSizeThreshHold(int threshhold);
// 给线程池提交任务
Result submitTask(std::shared_ptr<Task> sp);
// 开启线程池
void start(int initThreadSize = std::thread::hardware_concurrency());
ThreadPool(const ThreadPool&) = delete;
ThreadPool& operator=(const ThreadPool&) = delete;
private:
// 定义线程函数
void threadFunc(int threadid);
// 检查pool的运行状态
bool checkRunningState() const;
private:
// std::vector<std::unique_ptr<Thread>> threads_; // 线程列表
std::unordered_map<int, std::unique_ptr<Thread>> threads_; // 线程列表
int initThreadSize_; // 初始的线程数量
int threadSizeThreshHold_; // 线程数量上限阈值
std::atomic_int curThreadSize_; // 记录当前线程池里面线程的总数量
std::atomic_int idleThreadSize_; // 记录空闲线程的数量
std::queue<std::shared_ptr<Task>> taskQue_; // 任务队列
std::atomic_int taskSize_; // 任务的数量
int taskQueMaxThreshHold_; // 任务队列数量上限阈值
std::mutex taskQueMtx_; // 保证任务队列的线程安全
std::condition_variable notFull_; // 表示任务队列不满
std::condition_variable notEmpty_; // 表示任务队列不空
std::condition_variable exitCond_; // 等到线程资源全部回收
PoolMode poolMode_; // 当前线程池的工作模式
std::atomic_bool isPoolRunning_; // 表示当前线程池的启动状态
};
绑定线程函数
在ThreadPool中定义存放线程函数
// 线程池类型
class ThreadPool
{
//略
private:
// 定义线程函数
void threadFunc(int threadid);
};
在线程启动时需要接收定义在ThreadPool的线程函数
// 线程类型
class Thread
{
public:
// 线程函数对象类型
using ThreadFunc = std::function<void(int)>;
// 线程构造
Thread(ThreadFunc func);
// 线程析构
~Thread();
/*...*/
};
// 开启线程池
void ThreadPool::start(int initThreadSize)
{
// 设置线程池的运行状态
isPoolRunning_ = true;
// 记录初始线程个数
initThreadSize_ = initThreadSize;
curThreadSize_ = initThreadSize;
// 创建线程对象
for (int i = 0; i < initThreadSize_; i++)
{
// 创建thread线程对象的时候,把线程函数给到thread线程对象
auto ptr = std::make_unique<Thread>(std::bind(&ThreadPool::threadFunc, this, std::placeholders::_1));
int threadId = ptr->getId();
threads_.emplace(threadId, std::move(ptr));
// threads_.emplace_back(std::move(ptr));
}
// 启动所有线程 std::vector<Thread*> threads_;
for (int i = 0; i < initThreadSize_; i++)
{
threads_[i]->start(); // 需要去执行一个线程函数
idleThreadSize_++; // 记录初始空闲线程的数量
}
}
SubmitTask分配线程执行task
// 给线程池提交任务 用户调用该接口,传入任务对象,生产任务
Result ThreadPool::submitTask(std::shared_ptr<Task> sp)
{
// 获取锁
std::unique_lock<std::mutex> lock(taskQueMtx_);
// 线程的通信 等待任务队列有空余 wait wait_for wait_until
// 用户提交任务,最长不能阻塞超过1s,否则判断提交任务失败,返回
if (!notFull_.wait_for(lock, std::chrono::seconds(1),
[&]()->bool { return taskQue_.size() < (size_t)taskQueMaxThreshHold_; }))
{
// 表示notFull_等待1s,条件依然没有满足
std::cerr << "task queue is full, submit task fail." << std::endl;
// return task->getResult(); // Task Result 线程执行完task,task对象就被析构掉了
return Result(sp, false);
}
// 如果有空余,把任务放入任务队列中
taskQue_.emplace(sp);
taskSize_++;
// 因为新放了任务,任务队列肯定不空了,在notEmpty_上进行通知,赶快分配线程执行任务
notEmpty_.notify_all();
// cached模式 任务处理比较紧急 场景:小而快的任务 需要根据任务数量和空闲线程的数量,判断是否需要创建新的线程出来
if (poolMode_ == PoolMode::MODE_CACHED
&& taskSize_ > idleThreadSize_
&& curThreadSize_ < threadSizeThreshHold_)
{
std::cout << ">>> create new thread..." << std::endl;
// 创建新的线程对象
auto ptr = std::make_unique<Thread>(std::bind(&ThreadPool::threadFunc, this, std::placeholders::_1));
int threadId = ptr->getId();
threads_.emplace(threadId, std::move(ptr));
// 启动线程
threads_[threadId]->start();
// 修改线程个数相关的变量
curThreadSize_++;
idleThreadSize_++;
}
// 返回任务的Result对象
return Result(sp);
// return task->getResult();
}
任务完成获取返回值
用户想要获得任务执行完的返回值:比如多个线程计算不同部分返回后进行加总
- 用户定义一个mytask类,重写task的run()方法
- 将一个mytask对象由线程池submitTask到任务队列
- 线程池提交完task后会产生一个result对象提前开辟好任务返回值的存储空间和准备好将返回值传回给用户的方法(需等待task执行完成才能调用,用信号量同步)
- 将task分配到线程池中空闲的线程执行task->exec()
- task→exec()由对应的result对象的setVal(run())来调用,这样在task的run()完成后result会自动将run()返回的any类移动到result的any_中,等到run()执行完成的信号量资源增加,用户就可以调用result的get()方法获得任务的返回值
void Task::exec()
{
if (result_ != nullptr)
{
result_->setVal(run()); // 这里发生多态调用
}
}
Result res = pool.submitTask(std::make_shared<MyTask>())
Any类的实现原理
any特性在c++17 得到支持,这里我们自己简单实现一个类似的any类
// Any类型:可以接收任意数据的类型
class Any
{
public:
Any() = default;
~Any() = default;
Any(const Any&) = delete;
Any& operator=(const Any&) = delete;
Any(Any&&) = default;
Any& operator=(Any&&) = default;
// 这个构造函数可以让Any类型接收任意其它的数据
template<typename T> // T:int Derive<int>
Any(T data) : base_(std::make_unique<Derive<T>>(data))
{}
// 这个方法能把Any对象里面存储的data数据提取出来
template<typename T>
T cast_()
{
// 我们怎么从base_找到它所指向的Derive对象,从它里面取出data成员变量
// 基类指针 =》 派生类指针 RTTI
Derive<T>* pd = dynamic_cast<Derive<T>*>(base_.get());
if (pd == nullptr)
{
throw "type is unmatch!";
}
return pd->data_;
}
private:
// 基类类型
class Base
{
public:
virtual ~Base() = default;
};
// 派生类类型
template<typename T>
class Derive : public Base
{
public:
Derive(T data) : data_(data)
{}
T data_; // 保存了任意的其它类型
};
private:
// 定义一个基类的指针
std::unique_ptr<Base> base_;
};
实现semaphore类(mutex+condition_variable)
class Semaphore
{
public:
Semaphore(int limit = 0)
:resLimit_(limit)
{}
~Semaphore() = default;
// 获取一个信号量资源
void wait()
{
std::unique_lock<std::mutex> lock(mtx_);
// 等待信号量有资源,没有资源的话,会阻塞当前线程
cond_.wait(lock, [&]()->bool {return resLimit_ > 0; });
resLimit_--;
}
// 增加一个信号量资源
void post()
{
std::unique_lock<std::mutex> lock(mtx_);
resLimit_++;
// linux下condition_variable的析构函数什么也没做
// 导致这里状态已经失效,无故阻塞
cond_.notify_all(); // 等待状态,释放mutex锁 通知条件变量wait的地方,可以起来干活了
}
private:
int resLimit_;
std::mutex mtx_;
std::condition_variable cond_;
};
线程池返回值设计
// 实现接收提交到线程池的task任务执行完成后的返回值类型Result
class Result
{
public:
Result(std::shared_ptr<Task> task, bool isValid = true);
~Result() = default;
// 问题一:setVal方法,获取任务执行完的返回值的
void setVal(Any any);
// 问题二:get方法,用户调用这个方法获取task的返回值
Any get();
private:
Any any_; // 存储任务的返回值
Semaphore sem_; // 线程通信信号量
std::shared_ptr<Task> task_; //指向对应获取返回值的任务对象
std::atomic_bool isValid_; // 返回值是否有效
};
线程池Cached模式的实现
线程池资源回收
死锁问题分析解决
1、在ThreadPool的资源回收,等待线程池所有线程退出时,发生死锁问题,导致进程无法退出
2、在windows平台下运行良好的线程池,在linux平台下运行发生死锁问题,平台运行结果有差异化
分析定位问题:主要通过gdb attach到正在运行的进程,通过info threads,thread tid,bt等命令查看各个线程的调用堆栈信息,结合项目代码,定位到发生死锁的代码片段,分析死锁问题发生的原因,以及最终的解决方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号