BUAA_OO_Unit1 单元总结
第一次作业

可以发现在第一次的作业中,各个类之间并没有什么联系,每个类所进行的功能也并不独立与明确。这次作业中更多的体现出了一种面向过程的编程思维,导致第二次作业的重构任务很重。
1.2 架构分析
第一次作业需要实现的功能为解析输入的表达式,进行恰当的结构建模,从而完成单变量多项式的括号展开。总体来说,我个人认为作业的构建步骤分为以下几步:解析->存储->运算->(化简合并)->输出结果。
-
解析部分:解析步骤的主要作用,是将输入的表达式分解成为表达式、项、因子三个层次,同时注意到因子层次中可能会存在表达式层次的递归调用。
-
存储部分:建构存储时,我并没有按照解析时分成三个层次,而是建立了Expr类和Term类来进行解析结果与运算结果的存放。这是因为在第一次作业中,最基本的因子类型只有自变量x和常数因子(表达式因子可以递归解析掉),为了方便之后的化简合并,我将两种因子进行了如下的形式统一:
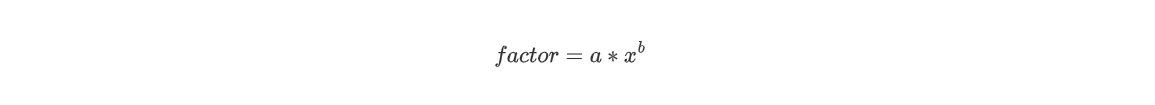
而考虑到项层面,我们有:
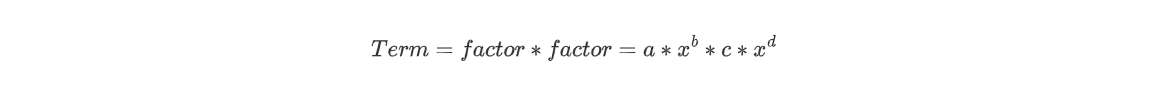
我们不难发现Term的存储结构与factor是相同的,因此笔者将二者合并存储,简化了类结构的复杂性(但是也发现这样的构造并不是很方便之后的迭代)。Term类中含有两个属性,分别为index和exponential,代表着项的系数与指数。
在Expr类中,我建立了一个HashMap<Integer, Term>用来存储表达式所包含的项。HashMap中的key值用来表示该项中x的指数,存储的好处是在合并同类项时能够进行快速的合并,无需再加入新的比较方法。
-
运算部分:本次作业中涉及的运算有加、减、乘、乘方四种类型。其中最为重要的是实现加法与乘法,减法与乘方运算只需加入一点细节修改即可。由于第一次的表达式复杂度不高,我并没有专门为计算建立单独的类(这是一个非常不好的设计,导致在第二次作业中进行了较大规模的重构),而是在parser类中建立了相应方法。基本的思路就是遍历Expr对象的terms,加法进行系数相加,乘法进行系数相乘。
-
合并化简:第一次作业的合并化简较为简单,就是指数相同的项进行系数相加,因此我将运算与合并操作同时进行。
-
结果输出:在Expr、Term两个类中均进行了toString方法的重写,在Expr对象中遍历其Terms,调用存储的Term对象的toString方法,Expr只需维护项之间的加减符号。Term中的toString较为臃肿,为了化简进行了多种情况的特判,如系数为0、指数为0、指数为1、系数为1等等情况。
1.3复杂度分析
-
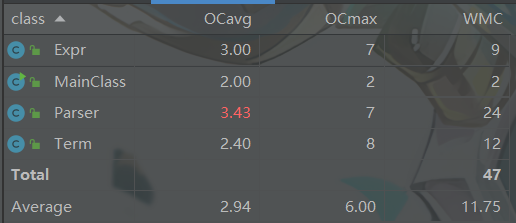
类复杂度
![]()
可以看到,由于第一次作业整体功能尚不复杂,大部分类的复杂度并不高。而Parser类复杂度较高的原因是我将计算与分析功能耦合在了一起,导致Parser类承担了过多的功能。
-
方法复杂度
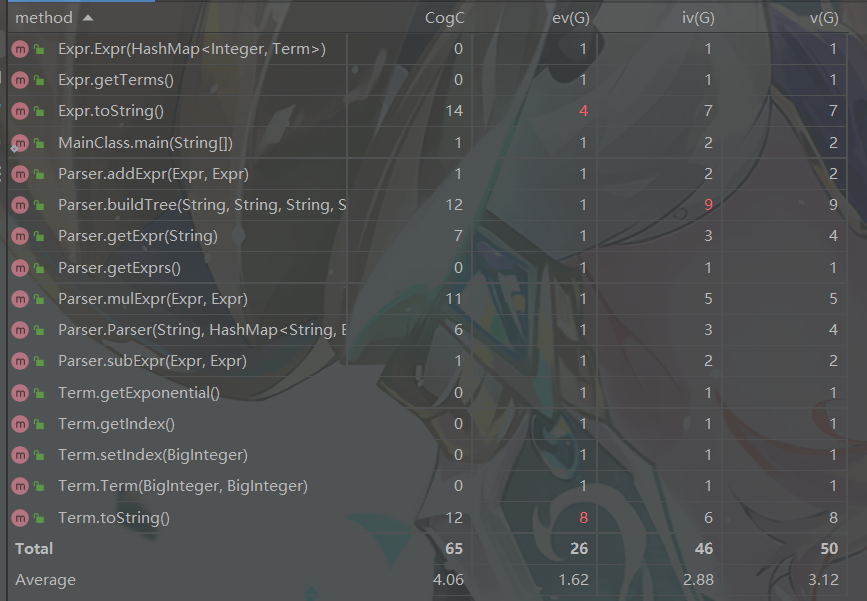
方法复杂度方面整体维持在正常水平,复杂度稍高的方法主要是Expr类与Term类的toString方法,这是因为在输出时我进行了较多的情况判断(这个问题在之后的作业中也并没有较好的解决)
1.4Bug分析
第一次互测中,我所在的房间没有成功的hack。我所采用的主要测试策略为随机数据+边界数据的双重测试,但是各位同学作业的健壮性都很高,并没有发现很明显的bug。
第二次作业
2.1UML图
-
analyze包:

-
expr包:
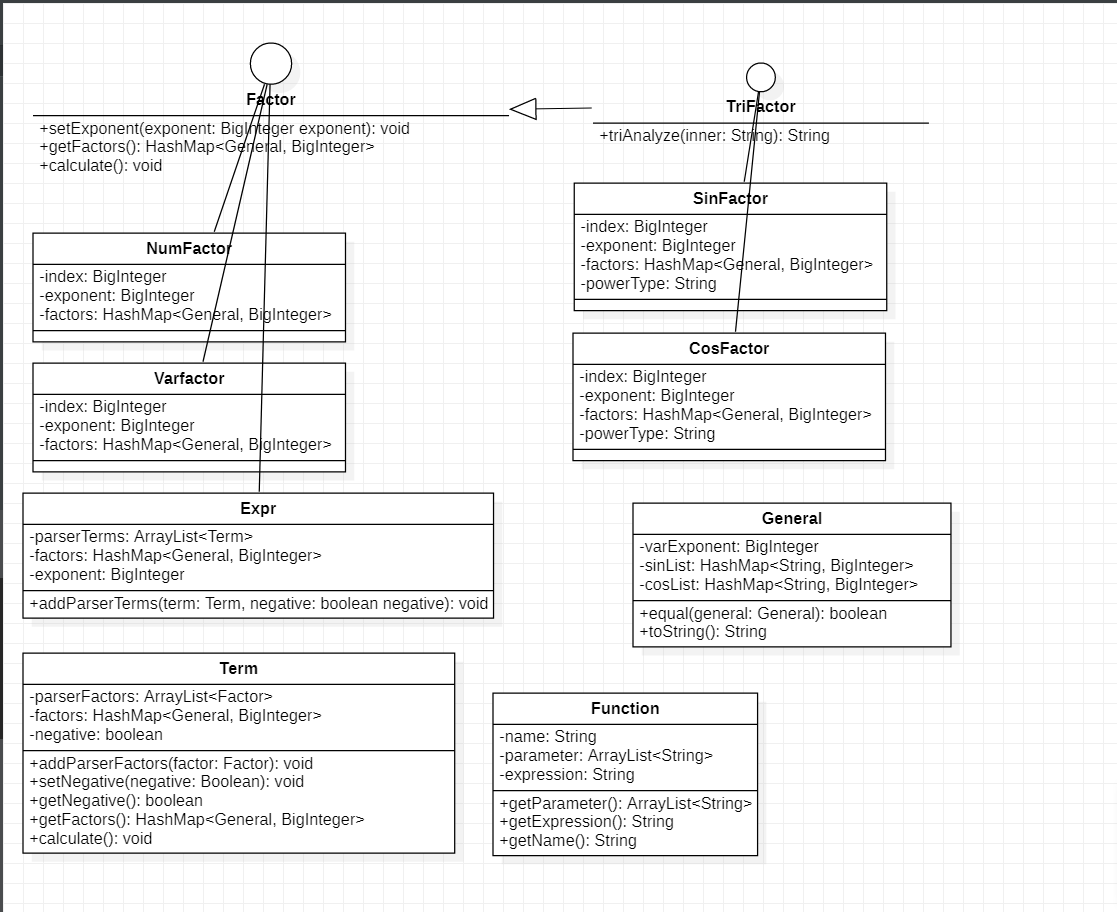
2.2架构分析
第二次作业在第一次作业的基础之上加入了三角函数、自定义函数与求和函数。从迭代的角度来考虑,第二次作业相较于第一次作业有很大的变化,因此我进行了大规模的重构。也我个人认为,从整体结构的建模来说,在因子层面,我们需要引入存储结构来考虑三角函数因子的存在。因为三角函数因子在数学意义上无法与之前的自变量x合并,因此可以认为sin、cos、x分别是我们项中三个独立的维度,即对于每一个项,可以以如下的通项形式表达:
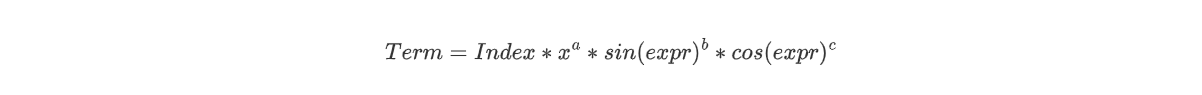
为此我单独建立了一个通项类——General,包含了3个属性,分别是自变量x的指数varExponential和用来存储sin(expr)与cos(expr)的sinList与cosList。这两个list均是采取的HashMap结构存储,以String作为key值,代表着三角函数中具体存放的表达式形式;value值对应的则是该三角函数项的指数。
从解析层面来说,在第一次作业的基础上加入了自定义函数与求和函数的解析。因为考虑到第三次作业中可能存在的进一步函数调用迭代,我将解析的方法换成了递归下降的解析模式。整体来说就是一种Expr->Term->Factor的基础解析步骤,同时在解析Factor时可能会碰到嵌套的表达式因子,此时再次递归调用解析模式即可。我所设计的factor接口与实现了该接口的类均是做解析存储步骤,因为这里与第一次作业没太大差别,在此不再赘述。
第二次作业中解析的主要难度就是自定义函数的处理。对于函数的解析,我一开始考虑的是进行暴力的字符串替换。但在经过思考和同学讨论后,我认为该种方法具有很大的产生bug风险,且并不符合面向对象编程的设计思想。最终我采用的是建立一个FuncAnalyze类,单独用来分析表达式中出现的函数。在Parser对象对初始表达式进行解析时,如果遇到了自定义函数的解析,则会创建FuncAnalyze对象,此时向该对象传入一个HashMap,其中记录了数据输入时的函数解析结果,FuncAnalyze类则会利用传入的解析结果,自己新建一个Parser对象解析函数表达式,同时完成对应的变量替换。
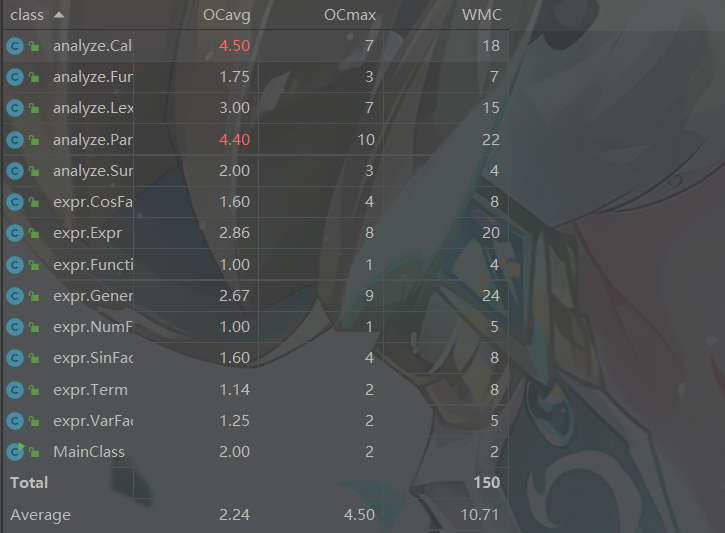
2.3 复杂度分析
-
类复杂度
![]()
就类的复杂度来说,可以看见analyze包中的Parser类与Calculate类复杂度较高,这也体现出第二次作业的表达式分析的复杂性。对于Calculate类的复杂度,我认为是我依然将合并功能交给了计算类的缘故,因为引入了三角函数因子的缘故,所以在判断同类项时的难度大大增加,我整体的思路为依据通项的维度进行独立的判断,即分别比较x的指数、sin表达式与cos表达式的一致性。而因为sin与cos表达式的存储模式较为复杂,重写后的equal方法也比较臃肿;而在合并时又需要利用双遍历对每一项进行逐一比较,导致了Calculate类的复杂性。
-
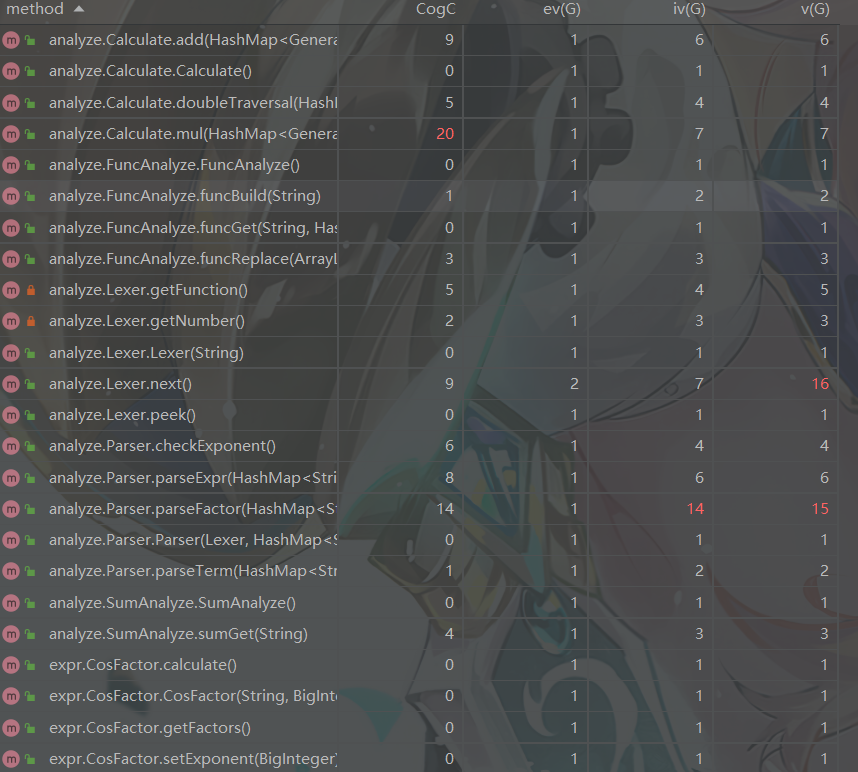
方法复杂度
![]()
![]()
![]()
方法复杂度方面与上次作业相同,第一个问题就是合并问题,已在类复杂度问题中陈述;另一个是toString中为了输出化简时许多情况的特判。
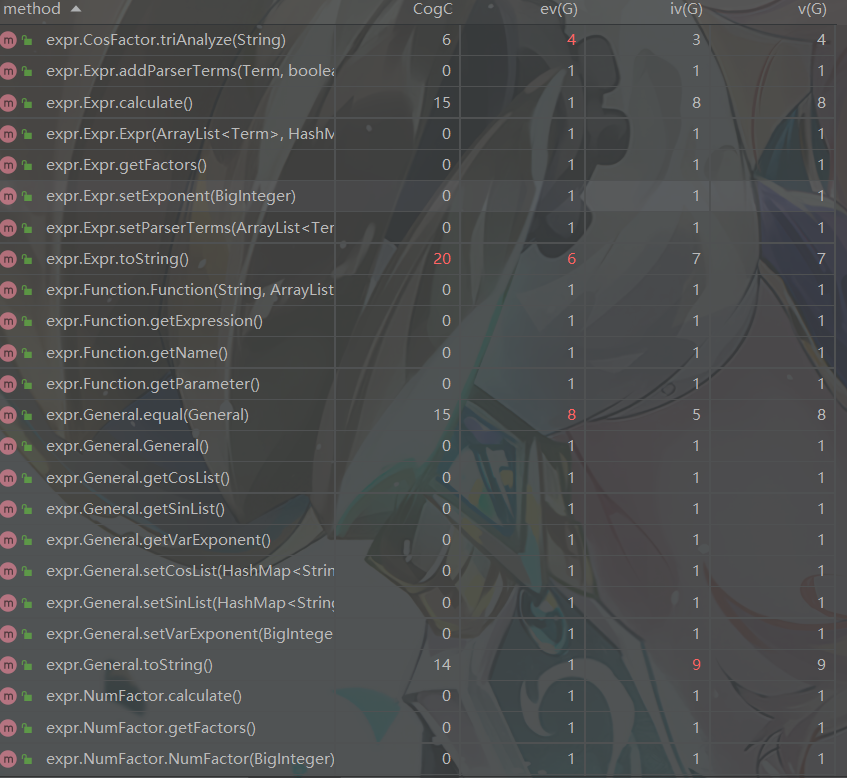
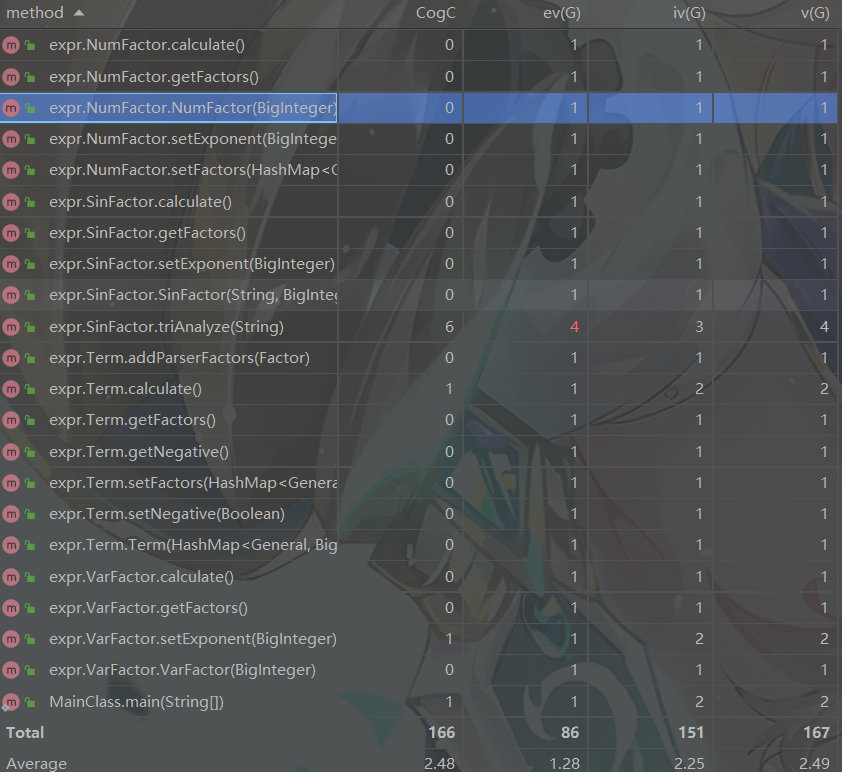
第三次作业
3.1 架构分析
因为第三次作业相比第二次作业来说,放宽了函数调用的限制,但是对于整体结构建模来说并没有很大的改变。所以在设计思路上来说,我在第二次的基础上只是对于三角函数因子的存储进行了修改,将key值由String类型变成的通项类型,从而形成一种递归的存储形式。
3.2 BUG分析
这个BUG分析是将第二次作业与第三次作业的BUG分析合并写的,因为第二次作业在初稿完成时,产生了很多的bug,花费了我很长的时间去修复。但是在第三次debug时我发现仍然有较为严重的bug存在,后来经过仔细检查吗,我发现是从第二次开始就有的一种设计思路上的错误,故放在一起进行阐述。
主要的bug数据是形如sin(1) + sin(2)+ sin(3)时的合并问题,我的程序一开始会将其合并成3sin(1)。一开始我以为是我在合并同类项时忘记考虑常数类型的特判。后来仔细思考后,我发现是我设计思路上的问题:我重写equals方法,目的是为了合并同类项时能够有效判断出能够合并的同类项,这种合并是针对的加法合并模式,因此我自然不会去判断通项中系数的相等性,这也就导致对于常数或者类似1*x这种特殊的表达式,当其不含有三角函数属性时,我会进行合并的误判!除此之外,我们不妨再来考虑一下乘法中的合并模式,乘法的形式为:
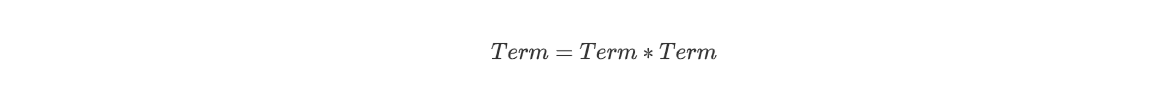
其中:
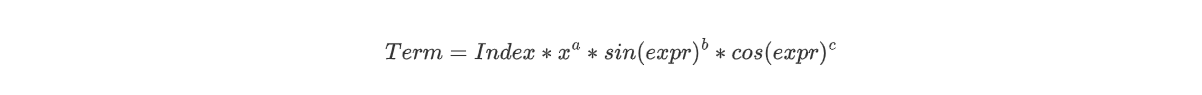
此时我们需要进行的操作是index相乘、不同的a相加,而对于sin项与cos项,我们则是只有在expr全等时才进行合并。我们发现此时对于合并的要求又少了一步——即不再需要x的指数的相等性!所以针对加法与乘法时的合并要求也并不相同。而在我初始的equals方法中,我并没有考虑到这么多的问题,而是进行了粗略的比较。为了修复这个bug,我便将equals方法拆解成分步进行,对于不同的地方,只需要equals执行不同的步骤即可。
测试策略
对于互测中发现他人bug的策略,我均采取的是随机数据+特殊数据的测试方法。其中随机数据采取随机数据生成器来进行生成,这种方式有一些不好的地方是生成的数据不一定符合互测中需要的代价要求。因此我也会进行一些特殊数据的测试,主要的构造方式就是将各种函数进行组合、测试存储类型的边界数据以及根据自身已经出现过的bug来构造类似数据试错。
架构设计体验
-
架构成型
其实第一单元的三次作业来说对于我来说还是挺有挑战性的。因为第一次接触到面向对象编程的思想,第一次作业时明显运用的还不熟练,导致第二次的作业进行了大量的重构工作。在此过程中,我们还进行了实验课与研讨课的学习,我也从中了解到了很多架构的建造模式。在三次作业中,我认为其实是第二次作业的难度最大,因为引入了三角函数与自定义函数其实是在因子层面与解析层面均加入了新的结构。但是站在第一次作业的基础上,其实我们能够有一种统一的思路去处理新的问题,新的架构的构建需要改变的是过去结构的具体方法、具体属性,但是各个类之间的关系应该整体是不会发生大变动的。
总之我的架构成型过程其实并没有很多迭代的元素,大部分时间都重构掉了。但是我认为架构的迭代不光是代码结构的迭代,也是我们思考与解决这个问题的迭代。
-
心得体会

 浙公网安备 33010602011771号
浙公网安备 33010602011771号