
笔记-机器学习-1
笔记-机器学习-1
1. 什么是机器学习
机器学习是一类算法的总称,这些算法企图从大量历史数据中挖掘出其中隐含的规律,并用于预测或者分类,更具体的说,机器学习可以看作是寻找一个函数,输入是样本数据,输出是期望的结果,只是这个函数过于复杂,以至于不太方便形式化表达。需要注意的是,机器学习的目标是使学到的函数很好地适用于“新样本”,而不仅仅是在训练样本上表现很好。学到的函数适用于新样本的能力,称为泛化(Generalization)能力。
个人理解:
软件程序实际上就是抽象化数据,找出规律,根据输入给出一个输出。
现在的问题是有一些数据之间的关系是模糊的,无法直观描述,也不容易找不到规律。
有人尝试通过穷举/模拟/猜来找出一个“最优”的描述/算法,如果这个算法的结果基本上满足要求,就认为它是一个合格的算法了。
下面把这种描述/算法统称为函数。
1.1. 学习步骤
通常学习一个好的函数,分为以下三步:
1、选择一个合适的模型,这通常需要依据实际问题而定,针对不同的问题和任务需要选取恰当的模型,模型就是一组函数的集合。
2、判断一个函数的好坏,这需要确定一个衡量标准,也就是我们通常说的损失函数(Loss Function),损失函数的确定也需要依据具体问题而定,如回归问题一般采用欧式距离,分类问题一般采用交叉熵代价函数。
3、找出“最好”的函数,如何从众多函数中最快的找出“最好”的那一个,这一步是最大的难点,做到又快又准往往不是一件容易的事情。常用的方法有梯度下降算法,最小二乘法等和其他一些技巧(tricks)。
4、学习得到“最好”的函数后,需要在新样本上进行测试,只有在新样本上表现很好,才算是一个“好”的函数。
1.2. 机器学习路线图
机器学习是一个庞大的家族体系,涉及众多算法,任务和学习理论,下图是机器学习的学习路线图。
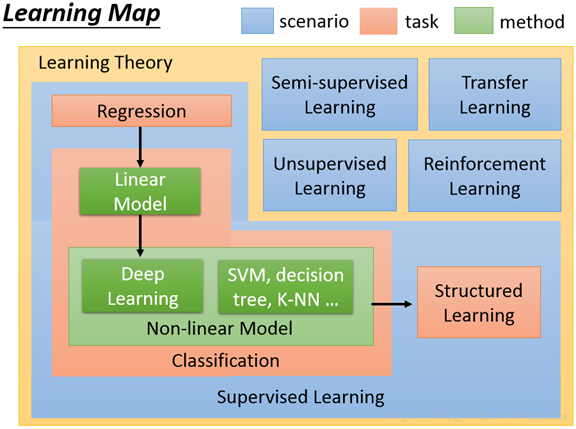
图中蓝色代表不同的学习理论,橙色代表任务,绿色代表方法。
1、按任务类型分,机器学习模型可以分为回归模型、分类模型和结构化学习模型。回归模型又叫预测模型,输出是一个不能枚举的数值;分类模型又分为二分类模型和多分类模型,常见的二分类问题有垃圾邮件过滤,常见的多分类问题有文档自动归类;结构化学习模型的输出不再是一个固定长度的值,如图片语义分析,输出是图片的文字描述。
2、从方法的角度分,可以分为线性模型和非线性模型,线性模型较为简单,但作用不可忽视,线性模型是非线性模型的基础,很多非线性模型都是在线性模型的基础上变换而来的。非线性模型又可以分为传统机器学习模型,如SVM,KNN,决策树等,和深度学习模型。
3、按照学习理论分,机器学习模型可以分为有监督学习,半监督学习,无监督学习,迁移学习和强化学习。当训练样本带有标签时是有监督学习;训练样本部分有标签,部分无标签时是半监督学习;训练样本全部无标签时是无监督学习。迁移学习就是就是把已经训练好的模型参数迁移到新的模型上以帮助新模型训练。强化学习是一个学习最优策略(policy),可以让本体(agent)在特定环境(environment)中,根据当前状态(state),做出行动(action),从而获得最大回报(reward)。强化学习和有监督学习最大的不同是,每次的决定没有对与错,而是希望获得最多的累计奖励。
2. 机器学习理论
一般分为监督式学习,无监督式学习,半监督式学习三种。
2.1. 监督式学习supervised learning
在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。监督式学习的常见应用场景如分类问题和回归问题。常见算法有逻辑回归(Logistic Regression)和反向传递神经网络(Back Propagation Neural Network)
监督式学习的流程
- 获取带属性值的样本,假设m个训练样本{(x1,y1),(x2,y2)……(xm, ym)};
- 对样本进行预处理,过滤其中的杂质,保留有用信息,称之为特征提取;
- 通过算法习得样本特征到样本标签之间的假设函数;
- 根据假设函数进行预测。
监督学习算法:
分类问题classification,是指通过训练数据学习一个从观测样本到离散的标签的映射,分类问题是一个监督学习问题。
典型的问题有:垃圾邮件的分类spam classification,训练样本是邮件中的文本,标签是每个邮件是否是垃圾邮件{-1,+1}(-1为垃圾邮件,反之不然)
另一个安案例是点击率预测click-through rate prediction,训练样本是用户、广告和广告主的信息,标签是是否被点击{-1,+1}
回归问题regression指通过训练数据学习一个从观测样本到连续的标签的映射,在回归问题中的标签是一系列连续的值。
典型的回归问题有,股票价格的预测,房屋价格的预测
2.2. 无监督式学习unsupervised learning
在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。常见的应用场景包括关联规则的学习以及聚类等。常见算法包括Apriori算法以及k-Means算法。
无监督学习流程:
聚类算法是无监督学习算法中最典型的一种学习算法。聚类算法利用样本的特征,将具有相似特征的样本划分到同一个类别中,而不关心这个类别具体是什么。
下面是一个案例:
只关心其特征
2.3. 半监督式学习 semi-supervised learning
在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。如图论推理算法(Graph Inference)或者拉普拉斯支持向量机(Laplacian SVM.)等。
3. 机器学习算法
有点晕,有空再写。
一些关键词
- 二项分布:二项分布就是重复n次独立的伯努利试验。在每次试验中只有两种可能的结果,而且两种结果发生与否互相对立,并且相互独立,与其它各次试验结果无关,事件发生与否的概率在每一次独立试验中都保持不变,则这一系列试验总称为n重伯努利实验,当试验次数为1时,二项分布服从0-1分布。
- 伯努利试验(Bernoulli experiment)是在同样的条件下重复地、相互独立地进行的一种随机试验,其特点是该随机试验只有两种可能结果:发生或者不发生。我们假设该项试验独立重复地进行了n次,那么就称这一系列重复独立的随机试验为n重伯努利试验,或称为伯努利概型。单个伯努利试验是没有多大意义的,然而,当我们反复进行伯努利试验,去观察这些试验有多少是成功的,多少是失败的,事情就变得有意义了,这些累计记录包含了很多潜在的非常有用的信息。
4. 总结
机器学习总体上来说就是:信息-关联-数学公式描述-程序实现描述-运行-结果
对机器学习有了一个基础的了解,更深入的需要一定的统计学和数学功底。
5. 参考文档
https://blog.csdn.net/hohaizx/article/details/80584307
https://www.cnblogs.com/nxld/p/6059509.html
https://blog.csdn.net/BaiHuaXiu123/article/details/69488610

 浙公网安备 33010602011771号
浙公网安备 33010602011771号