数据结构与算法简记--B+树
B+树
争哥的课程都会我们解决问题的思路和过程比结果更重要
此节就以这样的思路来分析MYSQL的索引底层数据结构B+树是如何一步一步演化的
- 解决问题的前提是定义清楚问题
对一些模糊的需求进行假设,来限定要解决的问题的范围:
分析mysql数据库的需求
- 功能性需求
假定只有以下两个需求:
-
- 根据某个值查找数据,比如 select * from user where id=1234;
- 根据区间值来查找某些数据,比如 select * from user where id > 1234 and id < 2345。
- 非功能性需求
安全、性能、用户体验,着重考虑性能需求
性能需求中着重考虑执行效率和存储空间,即时间复杂度和空间复杂度
- 尝试用学过的数据结构解决这个问题
- 散列表:查询性能很好:O(1),不支持按区间查询
- 平衡二叉查找树:查询:O(logn),依然不能解决按区间查询
- 跳表:查询,增,删效率都很好:O(logn),跳表结构:多层索引,底层数据使用链表串联,查询区间,可先查到起始数据,再在链表中顺序遍历直到找到结束数据,满足需求,实际B+树的结构跟跳表就很像。
- 改造二叉查找树来解决这个问题
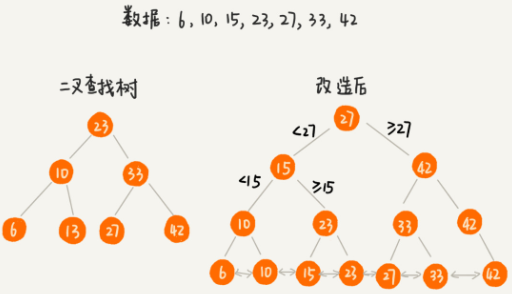
- 用跳表的思想改造二叉树,少量数据时,已可满足需求
![]()
-
数据规模比较大时,如给一亿个数据构建二叉查找树索引,那索引中会包含大约 1 亿个节点,每个节点假设占用 16 个字节,那就需要大约 1GB 的内存空间,如表多,索引也多,内存就无法满足需求了。
这时使用空间换时间的思路,可将索引存储在磁盘中。
然而磁盘的性能跟内存比相差上万倍,影响磁盘性能的主要瓶颈在于磁盘io操作,减少磁盘IO操作可提高性能,意味着要一次读取尽可能多的节点。
如果把二叉树存储在磁盘中,那每次节点的读取都对应一次磁盘IO操作,树的高度代表一次查询的磁盘IO次数,要降低磁盘IO,就是要降低树的高度。
可使用多叉树代替二叉树
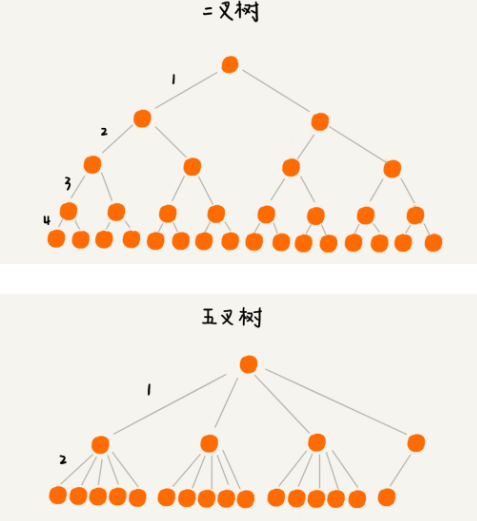
如果将 m 叉树实现 B+ 树索引,用代码实现出来,(假设我们给 int 类型的数据库字段添加索引,所以代码中的 keywords 是 int 类型的):
-
/** * 这是B+树非叶子节点的定义。 * * 假设keywords=[3, 5, 8, 10] * 4个键值将数据分为5个区间:(-INF,3), [3,5), [5,8), [8,10), [10,INF) * 5个区间分别对应:children[0]...children[4] * * m值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小: * PAGE_SIZE = (m-1)*4[keywordss大小]+m*8[children大小] */ public class BPlusTreeNode { public static int m = 5; // 5叉树 public int[] keywords = new int[m-1]; // 键值,用来划分数据区间 public BPlusTreeNode[] children = new BPlusTreeNode[m];//保存子节点指针 } /** * 这是B+树中叶子节点的定义。 * * B+树中的叶子节点跟内部结点是不一样的, * 叶子节点存储的是值,而非区间。 * 这个定义里,每个叶子节点存储3个数据行的键值及地址信息。 * * k值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小: * PAGE_SIZE = k*4[keyw..大小]+k*8[dataAd..大小]+8[prev大小]+8[next大小] */ public class BPlusTreeLeafNode { public static int k = 3; public int[] keywords = new int[k]; // 数据的键值 public long[] dataAddress = new long[k]; // 数据地址 public BPlusTreeLeafNode prev; // 这个结点在链表中的前驱结点 public BPlusTreeLeafNode next; // 这个结点在链表中的后继结点 }
m的大小并不是越大越好,在选择 m 大小的时候,要尽量让每个节点的大小等于一个页的大小(getconf PAGE_SIZE)。读取一个节点,只需要一次磁盘 IO 操作。
数据库的索引对增删数据的影响
插入数据和删除数据时要维护索引树的平衡,维护平衡主要维护的是节点子节点个数不超过m,
插入数据会使子节点个数超过m:分裂出一个父节点,会有级联反应直至根节点。
删除数据会使子节点个数过小:设置阈值m/2,小于则与相邻的兄弟节点合并,合并后如果超过m,则按插入规则再分裂。
B+树的特点总结
- 每个节点中子节点的个数不能超过 m,也不能小于 m/2;
- 根节点的子节点个数可以不超过 m/2,这是一个例外;
- m 叉树只存储索引,并不真正存储数据,这个有点儿类似跳表;
- 通过链表将叶子节点串联在一起,这样可以方便按区间查找;
- 一般情况,根节点会被存储在内存中,其他节点存储在磁盘中。
B树,B-树
B树就是B-树,跟B+树主要有以下区别
- B+ 树中的节点不存储数据,只是索引,而 B 树中的节点存储数据;
- B 树中的叶子节点并不需要链表来串联。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号