
1.配置独立操作
独立操作默认情况下,Hadoop被配置为以非分布式模式作为单个java进程运行,这个对调式很有用;
下面的实例复制要用作输入的未打包conf目录,然后查找并显示给定正则表达式的每个匹配项。输出被写入给定的输出目录;
1.1 创建一个文件夹名为input
mkdir input //在hadoop的bin目录下创建一个input文件夹
1.2 将Hadoop的XML配置文件复制到input
cp etc/hadoop/*.xml input

1.3 执行share目录下的MapReduce程序(执行)
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar grep input output 'dfs[a-z.]+'
1.4 查看输出结果
cat output/*

2.WordCount案例
2.1 在hadoop目录下创建一个文件夹名为wcinput
mkdir wcinput
2.2 在wcinput文件夹里创建一个wc.input文件并编译
cd wcinput
touch wc.input
vim wc.input
编译内容如下:
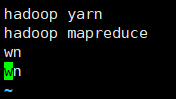
2.3 返回/opt/module/hadoop 目录下
2.4 执行程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar wordcount wcinput wcoutput
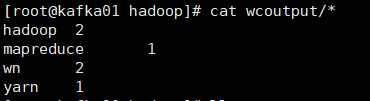
2.5 查看结果
cat wcoutput/*
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号