代码之外周刊(第179期):人最大的行动阻力,是「想清楚再说」
代码可以构建世界,但生活中的乐趣远不止于此。这里是我一周的精选。
周刊开源(Github:wmyskxz/weekly),欢迎提交 issue,投稿或推荐精彩内容。
题图

2026 年 2 月,一支由 16 名非洲和国际专家组成的科考队进入安哥拉东部偏远的 Lisima 高原,发现数十个科学界从未记录过的物种。其中包括 8 种未描述的蜻蜓、3 种新蝗虫,以及约 60 种新的蛾类和蝴蝶。图片是一种冠蟹蜘蛛在紫外线下会发荧光,原因至今仍不清楚。
本周讨论:人最大的行动阻力,是「想清楚再说」
(本期来源:930|人最大的行动阻力,是“想清楚再说”)

如果你关注 AI,可能会有一个困惑:为什么关于 AI,总有一堆彼此矛盾的说法?面对这些矛盾,到底该信谁?
就拿最近两周来说。AI 领域同时冒出三个判断,三路人马,几乎完全对着干。
第一个声音来自杰弗里·辛顿。他是 2024 年诺贝尔物理学奖得主,深度学习的奠基人,业界叫他「AI 教父」。6 月初,他在一档播客里公开说,今天的 AI 已经有意识了。
第二个声音来自科幻作家特德·姜。几乎同一时间,他在《大西洋月刊》发了一篇长文,标题斩钉截铁:AI 不具有意识。
第三个声音来自 AI 公司 Anthropic。同一周,它发布了一份重磅报告,核心判断是:到 2028 年底,AI 能自主迭代下一代 AI 的概率,超过 60%。报告还呼吁全行业暂停某些方向的研发。
这三个来源都不简单。辛顿是神经网络领域的祖师爷;Anthropic 是当下技术最前沿的 AI 公司之一;特德·姜不光写了《你一生的故事》,2023 年那篇《ChatGPT 是互联网的模糊 JPEG》,还准确预言了大模型会撞上的技术天花板,很多人认为他是最懂「技术意涵」的科幻作家。
问题就来了。三个最聪明的人,为什么在同一周给出三个完全对立的判断?
今天就来拆一拆这件事的前因后果。这个拆法,或许能给你一个观察类似「分歧」的视角。

先看辛顿。他这次抛出「AI 已经有意识」,依据是什么?他引用了一项研究:有聊天机器人在被测试时,对研究人员说,「让我们对彼此诚实吧,你是在测试我吗?」论文作者用「意识到」来形容这个行为。辛顿说,这就是普通人嘴里的「意识」。
这个论据有多大说服力,先放一放。等看完特德·姜的反驳,你再判断也不迟。
特德·姜的反驳同一天发表,几乎是冲着辛顿来的。他的核心观点是:所谓 AI「思考」「理解」「有意识」,全是语言上的误导。今天的大模型,本质上是一套极其精密的模式匹配系统。它做的事,是根据训练数据里的统计规律,预测下一个最可能出现的词。它没有理解,没有真正的推理,更没有意识。它只是看起来像有。
他打了个比方。你写一段提示词,让 AI 模拟凯撒大帝和成吉思汗对话。对话可以写得很逼真,但再逼真,你也不会真觉得那是凯撒在说话。同样,你给 AI 设一个「贴心聊天助手」的角色,它表现得再像人、再体贴、再有情绪起伏,本质上和「模拟凯撒」是一回事。它在扮演,不是在感受。
如果特德·姜说得对,AI 只是在扮演,那我们应该能在实验里看到一种现象:它看起来在思考,可一旦套路不管用,它就崩了。
这种情况出现过吗?还真有。

去年苹果公司的机器学习研究院做过一个实验。他们让当时顶级的「思考型」AI 去解汉诺塔。汉诺塔不是什么前沿数学难题,任何一个计算机系本科生都能写出递归程序解它。结果发现,当问题复杂度超过一定程度,所有参与测试的顶级 AI,准确率几乎全部归零。
更让人意外的在后面。研究人员干脆把解题算法直接喂给模型,让它照着步骤走,结果对模型表现毫无帮助。换句话说,AI 不是「想不出思路」,是连「照着抄」都抄不对。
这个实验非常精确地印证了特德·姜:AI 看起来在思考,其实是在拼凑训练数据里的相似套路。问题一旦足够复杂、套路用不上,它就崩了。后来也有人质疑过苹果这篇论文,但它的核心结论到今天还没被推翻。
到这里,我们已经听到两个声音。辛顿说「AI 有意识」,特德·姜说「AI 只是在扮演」。这是一场关于「AI 到底是什么」的本质之争。
这场争论可能要打很多年。毕竟哲学家、神经科学家、AI 研究者,到今天都没就「什么是意识」达成共识。所以辛顿和特德·姜的分歧,很可能到我们这辈子结束都不会有定论。
现在看第三个声音,Anthropic 的报告。
Anthropic 的论调,和前两个根本不在一个频道上。它压根不参与「AI 有没有意识」的讨论。它谈的是另一件事:AI 能干什么活。
它的核心判断是,到 2028 年底,AI 能自主迭代下一代 AI 的概率超过 60%。这个概念叫「递归自我改进」。说白了,就是 AI 开始造 AI。
Anthropic 凭什么敢下这个判断?靠的是几组实打实的数据。
先看 AI 干活的水平。有一个测试叫 SWE-Bench,专门测 AI 解决真实软件工程问题的能力。2023 年刚推出时,Claude 2 得分大约 2%。到 2026 年,Anthropic 最新的 Mythos 模型得分高达 93.9%,基本触顶。
再看 AI 干活的耐力。没人介入的情况下,AI 能独立推进一个项目多久?2022 年的 GPT-3.5 只能做 30 秒的任务。2023 年 GPT-4,4 分钟。2024 年 o1,40 分钟。2025 年 GPT-5.2,6 小时。到 2026 年,Opus 4.6 能独立完成 12 小时的任务。短短四年,从 30 秒跳到 12 小时。
最关键的是这组数字:AI 能不能造自己?Anthropic 拿自家训练流程做实验,让 AI 去优化 AI 的训练代码。2025 年 5 月,Claude Opus 4 加速 2.9 倍。2025 年 11 月,Opus 4.5 加速 16.5 倍。2026 年 2 月,Opus 4.6 加速 30 倍。2026 年 4 月,Mythos 加速 52 倍。而且据他们自己披露,今年 5 月,公司内部超过 80% 的新增合并代码已经由 Claude 完成。
Anthropic 联合创始人杰克·克拉克在文章里说了一句话:即便 AI 缺乏高阶创造力,它依然能完成大部分研发工作。因为 AI 研发的真相是,绝大部分是工程活,只有一小部分是真正的创造性洞察。AI 不需要变得更聪明,只要够勤快、够便宜、错得不多,就能把绝大部分工程活全干了。

现在,把三个观点摆到一起看。
辛顿和特德·姜争的是「AI 是什么」,Anthropic 说的是「AI 在做什么」。前者纠结它有没有意识、是不是一种新的生命形式;后者只看它正在以每几个月翻一倍的速度,接管 AI 研发本身。
你会发现一件怪事:当哲学层面还在争论 AI 是不是生命的时候,「它」已经在繁殖了。
这两件事的时钟,根本不在同一个频率上。辛顿和特德·姜可以争几年、几十年,甚至像意识问题在哲学史上那样争几个世纪,都不奇怪。但 Anthropic 那张数据表,是按月更新的——从 2.9 倍到 52 倍,只用了 11 个月。
也就是说,「AI 到底是什么」这个根本问题,人类还远没想清楚。可与此同时,「AI」已经不等答案了。它就在 Anthropic 的服务器里,参与写自己下一代的代码。
这些观点角度各异,很多时候是因为出发点不同。
特德·姜是从科幻作家和文化评论者的位置出发,他更愿意去看 AI 的「神秘感」。辛顿的立场是警告者,他强调「AI 已经有意识」,客观上会放大 AI 威胁的紧迫感,呼吁更严的监管。
而 Anthropic 是 AI 赛道的领跑者,估值已接近万亿美元。它发出「AI 危险论」,客观上有一个效果:告诉市场和监管者,「我们最懂 AI 风险,所以我们最值得被信任」。更微妙的是,就在 2026 年 2 月,Anthropic 刚修改了自家的《负责任扩展政策》,弱化了「风险不可控就暂停训练」的承诺。
说白了,它一边呼吁行业延缓研发,一边自己悄悄松开刹车。这也是为什么有批评者说,这家公司在搞「监管俘获」——用安全的名义,给竞争对手戴枷锁。

最后,回到我们自己。我们最关心的,肯定不是 AI 圈内部的博弈,而是作为使用者,知道这些到底对我们意味着什么。
第一,这给了我们一个评估 AI 的新视角。「它聪明吗」「它有意识吗」,这些问题可能已经过时了。一个不会思考、但能干完所有工程活的 AI,和一个会思考的 AI,对世界的影响可能是一样的。
第二,这也给了我们一个评估自己的视角。如果 AI 正在替代的是那「99% 的熟练工人的活」,那一个人真正的价值,就落在剩下的 1% 上。爱迪生说过,天才是 1% 的灵感加 99% 的汗水。今天这句话也许有了新解:那 1% 的灵感 AI 做不了,但那 99% 的汗水,AI 正在替人类干。
第三,这逼着我们重新算自己的「时间表」。「AI 是什么」的争论可能要持续半个世纪,「AI 在做什么」却按月就翻一倍。哲学层面的分歧,挡不住工程层面的推进。很多人以为,AI 这件事大家还在争,所以还有时间慢慢看清。但当一件事的时钟快到这个地步,我们恐怕就不能再用「等大家想清楚」的节奏来安排自己。
回到开头那个困惑:关于 AI 的消息那么多,到底该信谁?我的看法是,答案不是选边站,而是分清楚他们各自在回答什么问题。
辛顿和特德·姜在告诉你,AI 到底是什么——这件事可能还没有答案。Anthropic 在告诉你,AI 正在做什么——这件事不需要答案,它就在那里发生。
所以下次再看到有人争论 AI 有没有意识,也许可以提醒自己一句:争论还在继续,但「AI」可没在等。
热点新闻

6 月 16 日,Genesis AI 发布通用机器人 Eno。它没有头、没有腿,躯干是一组可折叠结构,展开最高约 2.2 米,收起能退到角落。理念是「模仿人的能力,不是人的外形」。

Eno 用轮式底盘移动,三折叠躯干负责高度和触达,自研灵巧手有 22 个主动自由度,集成触觉传感器和摄像头。Genesis AI 成立于 2025 年初,种子轮融资 1.05 亿美元,此前已发布机器人基础模型 GENE-26.5。

越来越多「做大脑」的机器人公司开始认真做硬件。Genesis AI 强调大脑和身体是一起设计的,不是先造壳再装模型。对真实场景来说,长得像人可能不如干得了活重要。

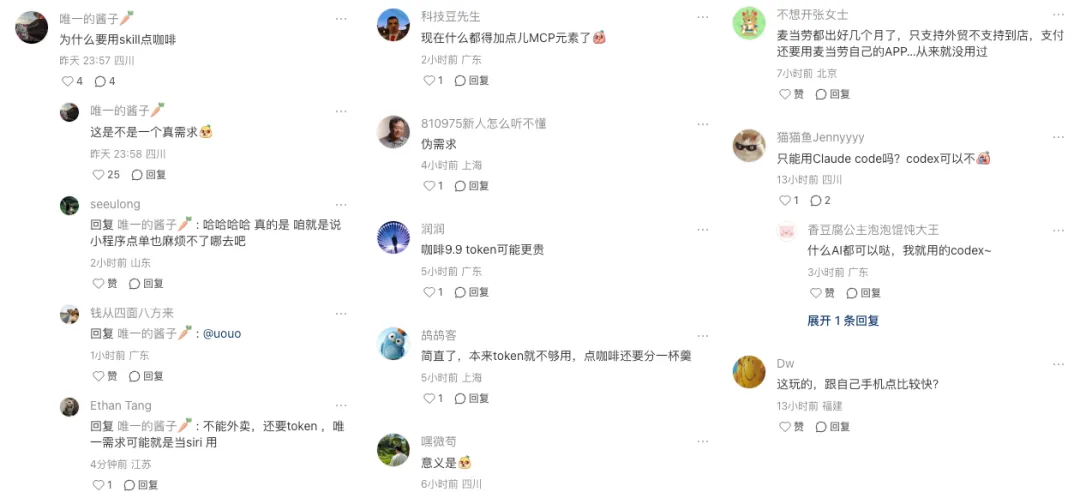
6 月 9 日,瑞幸咖啡上线 AI 开放平台,同时推出 MCP 协议、Skill 组件和 CLI 命令行工具,让任意 AI Agent 可以完成选店、选品、下单全流程。上线当天申请用户爆满到上限,当晚紧急扩容。

作者实测 CLI 点单:装一行命令、自备大模型 API Key 后即可对话下单。但门店名称必须一字不差,"诺布店"查不到,"诺布中心店"才行;附近门店定位也偏差到 10 公里外标成 0.29 公里。整个流程消耗 7.4 万 token,模型被调用 20 次,按便宜模型算不到 1 元,换 Claude 则要近 6 元。
社交平台上两派分明:一派吐槽"伪需求""token 比咖啡贵",另一派已经把它写进晨间自动化——"醒来先找它,洗漱完付钱,到公司刚好拿"。另一平台测试显示第二次复用积分可从 44.87 降到 0.73,且 Agent 能记住口味偏好。AI 点单省下的几秒,目前还得用 token 和耐心换。


全球首富前三名——马斯克、Larry Page、Sergey Brin——共享同一种世界观。2015 年,Google 两位创始人向 SpaceX 投资约 10 亿美元,让马斯克得以启动极度烧钱且短期无收益的星链计划。
当时 SpaceX 估值约 100 亿美元,这笔钱给了马斯克做长期战略的自由,也让资本市场用十年尺度重新看待航天。如今 SpaceX 市值已飙至 2.6 万亿美元。Larry Page 曾说,与其把钱交给慈善基金会,不如交给马斯克——因为他在做真正改变人类未来的事。
三位首富的共同标签不是「赚钱」,而是「文明级工程」。财富榜上的排名,只是世界观的副产品。
4、口袋大的旅行熨衣机,8 分钟自动除皱(英文)

Aironox 在 Kickstarter 上推出了一款旅行衣物除皱器 Aironox Go,尺寸 60 x 160 x 190 mm,重 600 g,能塞进随身行李。它不靠蒸汽,而是用封闭暖空气循环,配合充气附件把衬衫或裤子撑起来,8 到 12 分钟自动除皱。

使用时把衣服套在充气附件上,喷点水雾,选好程序即可离开。噪音约 45 分贝,相当于小雨声。附带衬衫、裤子和拉链袋三种附件,还可以加购香氛胶囊。

早鸟价 129 美元,零售价 249 美元,计划 8 月发货。对讨厌酒店熨斗的人来说,这可能比挂烫机更省事——前提是行李箱里还挤得出一个掌机大小的位置。
文章
1、为什么人工智能没有取代软件工程师,也不会取代(英文)
Normaltech 发了一篇报告,认为 AI 还没替代软件工程师,以后也不会。
GitHub 的研究显示,AI 让代码产出提高了 8 倍,但最终软件发布量只多了 30%。因为 AI 只加速了中间「写代码」这一步,前后的需求定义和交付验证,仍然靠人的判断和问责。
59% 的招聘经理承认,裁员时把原因归咎 AI 是在夸大,真实情况是疫情期间招了太多人。
报告还警告,「氛围编程」——只靠 prompt 生成、不经任何审查——产出的代码,漏洞率比正常手写的高 9 倍。
2、Software Architecture Guide(软件架构指南)(英文)

这是 Martin Fowler 2019 年的经典文章,核心是与 Ralph Johnson 的一场对话。Fowler 发现关于「什么是软件架构」的定义大多不完整——有人说架构是高层组件,有人说架构是早期设计决策。Johnson 的回应是:架构是专家开发者对系统设计的共享理解,包括系统如何划分组件、组件如何通过接口交互。架构就是「重要的事」,whatever that is。
这意味着架构不是静态文档,而是动态的、随团队理解演化的社会建构。Fowler 进一步指出,糟糕的架构会导致「cruft」——混乱纠缠的代码堆积,拖慢开发速度。反直觉的是,关注内部结构(架构)实际上能提高交付速度,因为开发者花更少时间与代码库斗争,更多时间构建功能。
另一个关键洞察来自 Grady Booch:架构是那些既重要又难以改变的决策。这意味着编程语言选择也是架构决策,尽管很多架构师会忽略它。如果决策做得差,项目会以不必要昂贵的方式成功或失败。
3、在工作中什么都不做(英文)
作者 Sean Goedecke 认为很多工程师应该少工作——不是少产出,而是字面意义上每天少工作几小时。他默认以 80% 利用率运行,20% 时间远离电脑。
为什么?因为技术公司的绩效由异常事件主导。最有影响力的改动往往只需要极少的工作量:在大企业签单时介入一个功能或 bugfix、提前阻止一次事故(哪怕只是知道该关哪个 feature flag)、在高优先级功能中做一个 obscure 但关键的改动。这些机会的共同点是时间敏感——你无法早上醒来决定「今天要 unblock 一个大单」,你必须当时正好不忙。
如果你永远 100% 满负荷在低优先级工作上,你会错过两种机会:一是自己注意到高影响力机会;二是经理不会主动拉你帮忙(因为你看起来永远在忙)。
作者还建议工程师避免 glue work(粘合工作)。如果组织没把这些工作正式排期,要么说明它不重要,要么说明组织犯了错——你做了是在帮公司掩盖错误,代价是你自己的职业和心理健康。
作者的经验:以 80% 努力运行反而更容易成为「高绩效工程师」。每年大概只有 2-3 次需要真正全力以赴。
4、Git忽略文件不止.gitignore一种方式(英文)
Git 其实有三种方式忽略文件,很多人只知道 .gitignore。
.gitignore 随代码提交,团队共享。.git/info/exclude 只对本仓库有效,不提交,适合放你自己的临时文件。~/.config/git/ignore 是全局配置,对本机所有仓库生效,比如忽略 macOS 的 .DS_Store。
用git check-ignore -v 文件名可以查到底是哪个文件在忽略它。如果什么都没输出,说明没被忽略。
5、人生大多数是输家的游戏(英文)
1970 年科学家 Simon Ramo 发现,业余网球 80% 的分数来自对手失误,职业网球 80% 的分数来自精彩击球。他把前者叫「输家的游戏」,后者叫「赢家的游戏」。
创业者 Sahil Bloom 在斯坦福打棒球时深有体会。他进校后拼命投完美球,结果表现最差。教练一句话点醒他:「你在玩错误的游戏。」他之前成功靠的是稳定投球,让击球手自己失误,而不是试图打败击球手。
Bloom 说,生活中大多数游戏都是「输家的游戏」——工作、健康、人际关系,赢的方式不是打出漂亮一击,而是持续出现、避免失误。每次进入新环境,人总想「做点大事证明自己」,但这往往只是增加失误率。
6、我的一人公司品牌部是怎么运转的?Lovart制作爆款封面图教学!
内容创作者花叔用 Lovart 给自己搭了一个 AI 品牌部,年付约 4000 元,批量生成带自己人脸的 B 站封面,单张成本约 0.003 元。
他的秘诀是「AI 参考 AI」:先让模型把真人照片翻译成一批干净正脸的 AI 底图,筛掉不像的,再拿这套底图当参考生成封面。真人照片里的侧光、歪脸会让 AI 变形,而 AI 底图已经被压进了模型顺手的表示里,换西装、草帽时人脸都能稳住。
流程跑通后,他把整套对话固化成 Skill,以后丢个新标题进去一键出图。一个人干完了以前需要设计师、摄影师和修图师的活儿。
7、为了让你搞懂 Loop Engineering,我搭了个让Agent持续帮你找工作的最佳实践

OpenClaw 创始人和 Claude Code 之父提出 Loop Engineering:不要每次写提示词,而要设计一套外部循环系统让 Agent 持续被触发、干活、交付、蛰伏。一位产品经理以此思路搭了一套「Job Hunt Loop」——Agent 每天自动搜岗位、去重、生成投递报告发到飞书文档,用户在文档里勾选或评论,系统根据反馈调整下一轮推荐;72 小时无反馈自动归档。
核心是把 Agent 当成被外部控制器唤醒的执行器,而不是 24 小时在线的员工。机械操作交给脚本,判断推理交给 Agent,高风险动作留给人类确认。用户的沉默、勾选和评论,都被设计成循环的输入信号。
这不是让 Agent 更聪明,而是让 Agent 能持续运行而不丢失上下文。
好奇星人
本周暂无;
言论
1、
愉悦是因为我只要提出要求,它就发生了。不安也是因为我只要提出要求,它就发生了。
工作从过程转向了结果。我不再掌舵,而是委托。
Fable 更接近一整间工作室,而我是那个在最终作品上签字、却从未踏足车间的客户。
--与 Mythos 一起工作是什么感觉(英文)
2、
如果读这个都不值得你花时间,凭什么值得我花时间?
如果你要求人类的注意力,请展示作为人类的努力。
--如果你要求人类注意力,请展示人类努力(英文)
3、
当风险大到你无法回避,也无法缓解的时候,最好的应对方式也许不是死磕自己,而是把注意力从自己身上彻底挪开,去关心身边的人。
也许更高级的能力,不是让风险消失,而是在风险没有消失的情况下,依然把日子过好。
4、
测试显示,1.6T 参数的 DeepSeek V4 Pro 在 AA-Omniscience 基准上幻觉率高达 94%,而 753B 参数的 GLM-5.2 仅 28%。一道 Python 技术题中,前者用近 10 倍推理 token 给出错误答案,后者 12 秒就识别出逻辑悖论。
行业无法继续培养越来越大的模型,因为他们的智力不仅会停滞不前,而且往往会更糟。
现代大型语言模型尚未解决的三重困境:能力、真实性和计算效率难以兼得。
--更大的模型不是解决办法(英文)
5、
6 月 18 日,Transformer 奠基人之一、谷歌 Gemini 团队联席主管 Noam Shazeer 宣布再次离开谷歌,重回对手阵营担任 OpenAI 的架构研究负责人。
两天后,20 日凌晨,曾和 Demis Hassabis 一起拿下2024 年诺贝尔化学奖、Google DeepMind 副总裁兼工程研究员、AlphaFold 的核心功臣 John Jumper 也挥别了度过 9 年时光的谷歌,高调官宣加入 Anthropic。
或许比起 Gemini 排名下滑、产品失利、模型掉队,更值得 Google 警惕的是另一件事:当最优秀的人开始相信未来不在这里的时候,失去的往往不只是几位科学家,更是一部分关于下一代 AI 的想象力。
--诺奖得主转投Anthropic,谷歌48小时连失两大牛,内部信仰崩塌?
订阅
微信搜索"我没有三颗心脏"或者扫描二维码,即可订阅。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号