

【video-text retrieval论文阅读】Align and Prompt: Video-and-Language Pre-training with Entity Prompts
 CVPR2022
CVPR2022
代码地址:https://github.com/salesforce/ALPRO
这个论文还有一部分是视频问答的结果,但是我不主要研究那个方面,就没有放上来。主要放了视频-文本检索的部分
针对问题
(1)单一模态之间的相互对齐问题(视频和文本)
(2)传统的视频处理中选择目标检测,浪费资源
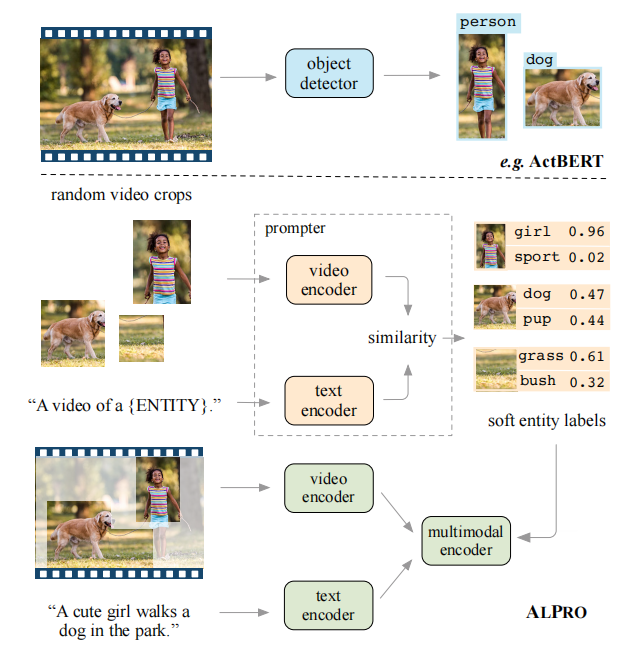
添加prompter的意义:(1)生成伪样本,增加对照(2)检测主要目标物体,节省资源
主要构成
该模型由一个视频-语义预训练模型和一个prompter组成。prompter用来产生软实体标签,帮助监督视频-语义模型的预训练。每个模态(预训练部分+prompter)都有一个视频编码器和文本编码器。此外在预训练部分有一个额外的多模态编码器,用以捕获两个模态之间的交互。
视觉编码器:12层的TimeSformer224抽取视频特征。分patch展平进入线性层+位置embedding+在时间和空间维度分别引入了sel-attention机制。在时间维度加入一个时间融合层来将帧特征聚合到视频特征中。最终获得了一串视觉特征{Vcls,V1,V2,...,VK}。
文本编码器:6层transformer,给定Nt个token的文本输入,将输出一个特征序列{Tcls,T1,T2,...,TK}。其中同样添加了位置信息。
多模态编码:6层transformer建模视频和文本特征之间的交互,来源于之前两个编码器的输出。选择直接连接视频和文本特征并输入多模态编码模型中。模型输出为{Ecls,E1,...,Env+nt},为了便于标注,放弃了视频[CLS]令牌的多模式嵌入,因为它不用于预训练损失。
预训练部分
在四个模型上对ALPRO预训练任务进行训练,包括MLM(masked language modeling)/VTM(video-text matching)/VTC( video-text contrastive loss)/PEM( prompting entity modeling loss)
后两者是用来加强视频和文本之间的跨模态对齐的。其中VTC着重捕获instance-level的对齐,而PEM着重局部视频区域预文本实体描述的对齐。
VTC:现存的预训练模型使用点积或依靠transformer模型中的模块得到跨模态交互信息。以上都受制于两种模态信息的语义信息不同。VTC将两种模态信息输入到相同的语义空间,再进行相似度的计算。如下:
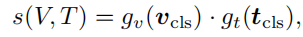
其中两个函数都是线性映射,旨在将cls-embedding转换到一个相同的正则低维空间。
计算两种损失函数并取平均值作为VTC损失函数。
PEM:改进了模型捕获局部区域信息、增强视频区域和文本实体之间的跨模态对齐的能力。
这一部分需要一个prompter模块生成伪软标签。然后,在给定伪标签作为目标的情况下,要求预训练模型预测视频裁剪中的实体类别。
(*软标签和硬标签的不同:
[1]硬编码的类别标签向量是二值的,如,一个类别标签是正类别,其他类别标签为负类别.
[2]软编码的类别标签中,正类别具有最大的概率;其他类别也具有非常小的概率.)
prompter列表中有M个文本promp。每个文本提示是模板的实例化,完成预训练后,它将计算针对每一个文本的cls-embedding。
为了产生实体标签,给定一个视频输入,我们首先获得一个随机的视频片段和通过prompter得到视频的cls-embedding。之后计算针对该视频片段的一个实体伪标签q与视频cls-embedding之间对应的softmax正则相似度。之后使用交叉熵函数计算损失值。
总体预训练
MLM(masked language modeling):使用视频和剩下的文本预测出被打码的部分
实验结果
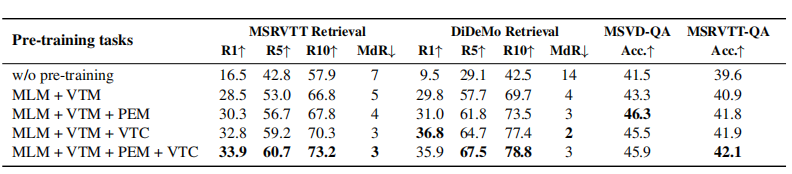
依次添加预训练任务,观察模型最终运行时得到的后端任务结果

提示器生成的伪标签示例(括号中的分数)。突出显示的区域被输入提示器。我们的方法生成了一系列常见的实体类别,这些类别通常不被对象检测器覆盖,例如塔、顶峰、瑜伽。此外,实体标签并不总是出现在文本描述中,作为语料库级监督的来源。左下角:不包含实体的随机裁剪。提示器由此产生具有低相似度的伪标签。在预训练期间,如果伪标签的最可能实体的分数小于0.2,则丢弃伪标签。对:从同一视频中为不同作物生成的标签。
调参过程
在后端任务中,ALPRO模型输入为视频帧,允许端到端的视频框架微调。
对每个视频随机采样N帧,在检索任务中N=8,而在问答任务中N=16。
把所有视频重新设置成224*224大小的。
为了对检索进行微调,我们在预训练期间重用视频文本匹配头,并优化VTC和VTM损失之和。我们在推理过程中从VTM头的输出中获得相似性分数。
实验结果
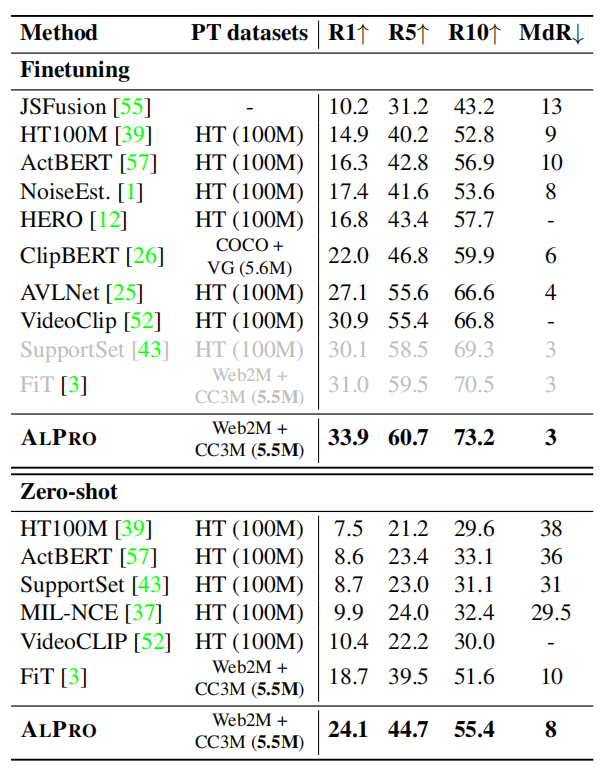
MSRVTT数据集上的微调结果和零样本结果(1k-B)
与MSRVTT上具有微调和零镜头设置的现有文本到视频检索方法的比较。我们使用7k培训视频遵循公共分区。方法使用9k的训练视频进行灰显。两个分区协议共享相同的1k测试视频。R@k表示k次检索努力的召回率(%);MdR表示检索视频的中值排名。预训练数据集包括HowTo100M(HT)[39]、MS-COCO(COCO)[31]、视觉基因组(VG)[22]、WebVid2M(Web2M)[3]和概念字幕(CC3M)[46]。
消融实验
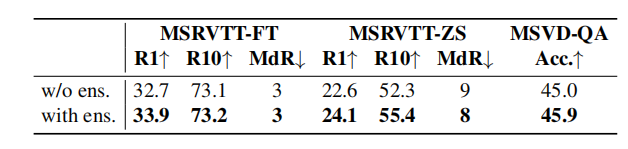
prompter的设计和构成。
我们注意到使用多个模板设计和集成提示非常重要。在没有太多工程工作的情况下,我们使用了一组初步的提示模板,例如“一个{实体}的视频”、视频输入的”一个{实体}的镜头和“一个{实体}的照片”作为图像输入。我们总共为视频和图像输入设计了12个模板。我们通过对同一实体实例化的提示的t-class嵌入进行平均来构建集成。上表中显示了即时集成的效果。尽管我们的工程努力最小(我们仅使用一组模板进行了实验),但即时集成证明了其在生成高质量伪标签方面的重要性。我们未来的工作是探索更及时的工程策略。
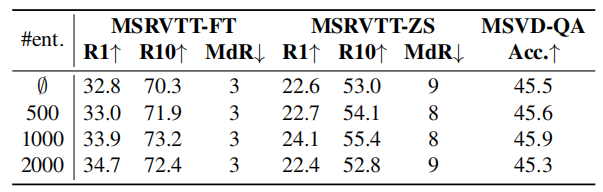
PEM实体数量的影响。我们报告了使用微调(FT)和零镜头(ZS)设置的MSVD-QA和MSRVTT文本视频检索的结果。第一行对应于用MLM+VTM+VTC(即,不使用PEM)训练的模型。
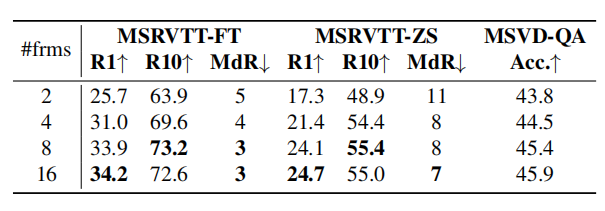
帧数对MSRVTT文本视频检索和MSVD-QA的影响。更多的帧通常导致更好的性能,8-16帧在度量和计算开销之间实现了良好的折衷。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号