groundDino分类训练与微调
前期准备
1.利用lebelme标注工具,生成图片标注信息;
2.将标注的json数据转换成COCO数据格式
3.下图演示只取了其中一部分
annotations = {
"demo1.jpg": [
{"bbox": [1198.3929443359375, 781.3394775390625, 1669.7503662109375, 1207.33740234375], "label": "bear"}
],
"demo2.jpg": [
{"bbox": [800.5625,
510.625,
982.8125,
475.0], "label": "dog"}
],
"demo4.jpg": [
{"bbox": [800.5625,
510.625,
982.8125,
475.0], "label": "dog"}
]
}
一、代码
import os
import cv2
import torch
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
from torchvision import transforms, models
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
import torch.optim as optim
# 设置设备
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {DEVICE}")
# ----------------------------
# 1. 安装和导入 Grounding DINO
# ----------------------------
# 如果没有安装,请先运行:
# !pip install -U groundingdino-py
import GroundingDINO.groundingdino.datasets.transforms as T
from groundingdino.util.utils import clean_state_dict
from GroundingDINO.groundingdino.util.slconfig import SLConfig
from GroundingDINO.groundingdino.models import build_model
from GroundingDINO.groundingdino.util.inference import predict
# 加载 Grounding DINO 模型
# GROUNDING_DINO_CONFIG = "setting/GroundingDINO_SwinT_OGC.py"
# GROUNDING_DINO_CHECKPOINT = "setting/groundingdino_swint_ogc.pth"
GROUNDING_DINO_CONFIG = "GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py"
GROUNDING_DINO_CHECKPOINT = "groundingdino_swint_ogc.pth"
# 下载模型权重(如果还没有)
def load_model(model_config_path, model_checkpoint_path, device):
args = SLConfig.fromfile(model_config_path)
args.device = device
model = build_model(args)
checkpoint = torch.load(model_checkpoint_path, map_location="cpu")
load_res = model.load_state_dict(clean_state_dict(checkpoint["model"]), strict=False)
print(load_res)
_ = model.eval()
return model
if not os.path.exists(GROUNDING_DINO_CHECKPOINT):
print("请先下载 Grounding DINO 权重文件到 weights/ 目录")
print("下载地址: https://github.com/IDEA-Research/GroundingDINO/releases/tag/v0.1.0")
else:
model = load_model(GROUNDING_DINO_CONFIG, GROUNDING_DINO_CHECKPOINT,device=DEVICE)
model = model.to(DEVICE)
# ----------------------------
# 2. 模拟数据和标注
# ----------------------------
# 创建模拟数据(实际使用时替换为你的数据)
IMAGE_DIR = "testDemo/assets/train"
os.makedirs(IMAGE_DIR, exist_ok=True)
# 创建一些示例图像(实际使用时替换为真实图像路径)
# 这里用随机图像演示
annotations = {
"demo2.jpg": [
{"bbox": [800.5625,
510.625,
982.8125,
475.0], "label": "dog"}
],
"demo4.jpg": [
{"bbox": [800.5625,
510.625,
982.8125,
475.0], "label": "dog"}
]
}
# 创建示例图像
# 创建示例图像
classes = ["cat", "dog", "car", "person"]
for img_name, anns in annotations.items():
# 创建随机图像
img = np.random.randint(100, 200, (400, 400, 3), dtype=np.uint8)
label = anns[0]["label"]
# 获取并验证bbox
bbox = anns[0]["bbox"]
x1, y1, x2, y2 = map(int, bbox) # 转换为整数
# 确保坐标正确(左上角 < 右下角)
x_min, x_max = min(x1, x2), max(x1, x2)
y_min, y_max = min(y1, y2), max(y1, y2)
# 限制坐标在图像范围内
x_min = max(0, x_min)
y_min = max(0, y_min)
x_max = min(400, x_max) # 图像宽度
y_max = min(400, y_max) # 图像高度
# 设置颜色
color = (0, 255, 0) if label == "cat" else \
(255, 0, 0) if label == "dog" else \
(0, 0, 255) if label == "car" else (255, 255, 0)
# 绘制矩形
cv2.rectangle(img, (x_min, y_min), (x_max, y_max), color, 3)
# 添加文字(位置要确保在图像内)
text_x = max(10, x_min)
text_y = max(30, y_min)
cv2.putText(img, label, (text_x, text_y),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
cv2.imwrite(os.path.join(IMAGE_DIR, img_name), img)
print("创建了示例图像")
def load_image(image_path):
# load image
image_pil = Image.open(image_path).convert("RGB") # load image
transform = T.Compose(
[
T.RandomResize([800], max_size=1333),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]
)
image, _ = transform(image_pil, None) # 3, h, w
return image_pil, image
# ----------------------------
# 3. 使用 Grounding DINO 提取特征/生成伪标签
# ----------------------------
def extract_features_with_grounding_dino(image_path, text_prompt):
"""
使用 Grounding DINO 提取图像特征或生成伪标签
"""
try:
# 1. 加载图像
image = Image.open(image_path).convert("RGB")
image_np = np.array(image) # [H, W, C], dtype=uint8
image_bgr = cv2.cvtColor(image_np, cv2.COLOR_RGB2BGR) # 转为 BGR
# 2. 转换为 torch.Tensor 并预处理
# 归一化到 [0, 1],转换为 float32
image_float = image_bgr.astype(np.float32) / 255.0
# 转换为 PyTorch 格式 [C, H, W]
image_tensor = torch.from_numpy(image_float).permute(2, 0, 1) # [C, H, W]
# 确保在正确的设备上(predict 内部也会处理,但提前移动更安全)
image_tensor = image_tensor.to(DEVICE)
# 预测
boxes, logits, phrases = predict(
model=model,
image=image_tensor,
caption=text_prompt,
box_threshold=0.25,
text_threshold=0.25,
device=DEVICE
)
# 4. 处理输出:logits 是 tensor,需要转为 numpy 进行后续处理
if isinstance(logits, torch.Tensor):
logits = logits.cpu().numpy() # 转为 numpy 数组
# 5. 提取特征:使用每个类别的最高置信度
class_names = [c.strip() for c in text_prompt.lower().split(".") if c.strip()]
class_scores = {cls: 0.0 for cls in class_names}
for phrase, logit in zip(phrases, logits):
phrase_lower = phrase.lower()
for cls in class_names:
if cls in phrase_lower:
class_scores[cls] = max(class_scores[cls], logit)
features = [class_scores[cls] for cls in class_names]
return np.array(features) # 返回 numpy array
except Exception as e:
print(f"Feature extraction failed for {image_path}: {e}")
import traceback
traceback.print_exc()
# 返回安全的默认值
class_names = [c.strip() for c in text_prompt.lower().split(".") if c.strip()]
return np.zeros(len(class_names))
# ----------------------------
# 4. 构建自定义数据集
# ----------------------------
class GroundingDinoClassificationDataset(Dataset):
def __init__(self, annotations, image_dir, text_prompt):
self.annotations = annotations
self.image_dir = image_dir
self.text_prompt = text_prompt
self.image_names = list(annotations.keys())
self.classes = [c.strip() for c in text_prompt.lower().split(".") if c.strip()]
print(f"Dataset classes: {self.classes}")
def __len__(self):
return len(self.image_names)
def __getitem__(self, idx):
try:
img_name = self.image_names[idx]
image_path = os.path.join(self.image_dir, img_name)
# 验证文件存在
if not os.path.exists(image_path):
print(f"File not found: {image_path}")
# 返回默认值
return torch.zeros(len(self.classes)), torch.zeros(len(self.classes))
# 提取特征
features = extract_features_with_grounding_dino(image_path, self.text_prompt)
# 创建标签
label = torch.zeros(len(self.classes))
if img_name in self.annotations:
for obj in self.annotations[img_name]:
if "label" in obj and obj["label"] in self.classes:
class_idx = self.classes.index(obj["label"])
label[class_idx] = 1.0
return torch.FloatTensor(features), label
except Exception as e:
print(f"Error processing {idx}: {e}")
# 返回安全的默认值
return torch.zeros(len(self.classes)), torch.zeros(len(self.classes))
# ----------------------------
# 5. 创建数据集和数据加载器
# ----------------------------
TEXT_PROMPT = "cat . dog . car . person"
dataset = GroundingDinoClassificationDataset(annotations, IMAGE_DIR, TEXT_PROMPT)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
print(f"数据集大小: {len(dataset)}")
print(f"类别: {dataset.classes}")
# ----------------------------
# 6. 构建分类模型
# ----------------------------
class SimpleClassifier(nn.Module):
def __init__(self, input_dim, num_classes):
super().__init__()
self.classifier = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(128, 64),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(64, num_classes)
)
def forward(self, x):
return self.classifier(x)
# 初始化模型
input_dim = len(dataset.classes) # 使用每个类别的置信度作为输入特征
num_classes = len(dataset.classes)
classifier = SimpleClassifier(input_dim, num_classes).to(DEVICE)
# ----------------------------
# 7. 训练模型
# ----------------------------
LEARNING_RATE = 1e-3
EPOCHS = 50
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.AdamW(classifier.parameters(), lr=LEARNING_RATE)
# 训练循环
classifier.train()
print("开始训练...")
for epoch in range(EPOCHS):
total_loss = 0
correct = 0
total = 0
for features, labels in dataloader:
features = features.to(DEVICE)
labels = labels.to(DEVICE)
optimizer.zero_grad()
outputs = classifier(features)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
# 计算准确率
preds = torch.sigmoid(outputs) > 0.5
targets = labels > 0.5
correct += (preds == targets).all(dim=1).sum().item()
total += labels.size(0)
avg_loss = total_loss / len(dataloader)
accuracy = 100. * correct / total
if epoch % 2 == 0:
print(f"Epoch [{epoch + 1}/{EPOCHS}], Loss: {avg_loss:.4f}, Accuracy: {accuracy:.2f}%")
print("训练完成!")
# ----------------------------
# 8. 测试和预测
# ----------------------------
def predict_image(image_path, classifier, text_prompt):
"""
对单张图像进行预测
"""
classifier.eval()
with torch.no_grad():
# 提取特征
features = extract_features_with_grounding_dino(image_path, text_prompt)
features = torch.FloatTensor(features).unsqueeze(0).to(DEVICE)
# 预测
outputs = classifier(features)
probs = torch.sigmoid(outputs).cpu().numpy()[0]
return probs
# 测试所有图像
print("\n🔍 测试结果:")
for img_name in annotations.keys():
image_path = os.path.join(IMAGE_DIR, img_name)
probs = predict_image(image_path, classifier, TEXT_PROMPT)
print(f"\n{img_name}:")
for i, cls in enumerate(dataset.classes):
print(f" {cls}: {probs[i]:.3f}")
二、微调实践
2.1学习率 LEARNING_RATE
✅ 学习率太大(如 1e-1):步子太大,可能“跨过”最优解,导致训练不稳定或发散。
✅ 学习率太小(如 1e-6):步子太小,收敛很慢,训练时间很长。
✅ 学习率适中(如 1e-4):通常是一个不错的起点,适合很多任务。
LEARNING_RATE = 1e-3 # 等于 0.001
LEARNING_RATE = 1e-4 # 等于 0.0001
常见学习率参考
| 任务类型 | 推荐学习率 |
|---|---|
| 训练小型网络(从头训练) | 1e-2 ~ 1e-3 |
| 微调预训练模型 | 1e-4 ~ 1e-5 |
| Adam 优化器常用值 | 1e-4 |
| 学习率调度(如 Cosine) | 初始设为 1e-4,逐渐减小 |
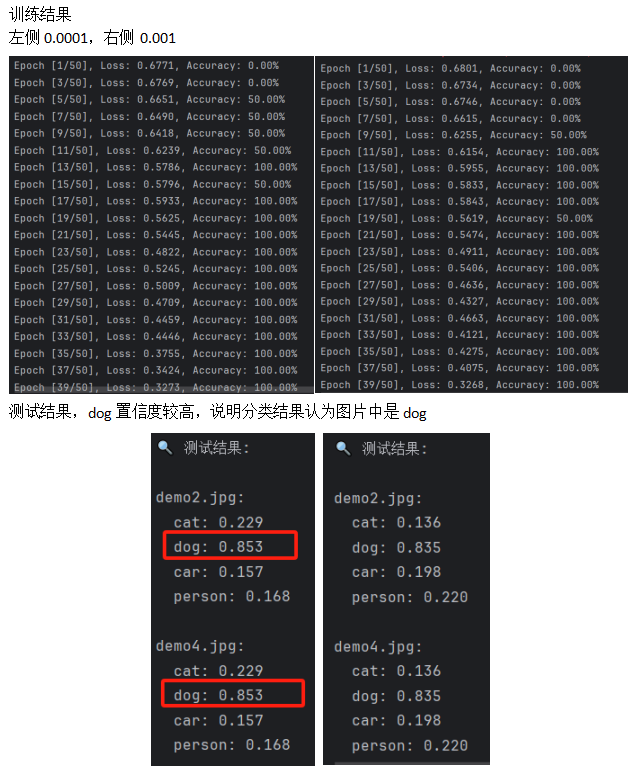
2.2批次 Batch Size
影响梯度估计的质量和内存消耗。较大的批次大小有助于稳定梯度估计,但也需要更多的显存。
建议尝试:
不同的批次大小(如 2、4、8、16、32),找到一个平衡点。
本次测试:批次为2,内存越消耗1.44G,16G内存占用从原58%增长到67%
2.3权重衰减 Weight Decay
用于正则化,防止过拟合。通常值:1e-4 到 1e-5。
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE, weight_decay=1e-4)
2.4过拟合
理想情况:像学生理解数学原理后能解各种变型题(泛化能力强)
过拟合:像学生死记硬背特定题目答案,遇到新题就束手无策(只会复现训练数据)
常见症状
性能指标对比:
- 训练准确率 >> 测试准确率(差距大)
- 训练损失 << 测试损失
模型行为特征:
- 权重值异常大或异常小
- 对输入微小变化反应过度敏感
- 决策边界过于复杂(如分类问题中出现"碎块状"边界)
主要成因
模型方面:
- 模型复杂度过高(参数太多)
- 训练时间过长(过度优化)
数据方面:
- 训练数据量不足
- 数据多样性不够
- 噪声/异常值过多
训练过程:
- 不恰当的正则化
- 验证策略不完善

 浙公网安备 33010602011771号
浙公网安备 33010602011771号