

作业二:第一次个人编程作业
| 这个作业属于哪个课程 | 软工23级 |
|---|---|
| 这个作业要求在哪里 | 个人项目 |
| 这个作业的目标 | 1、通过系统化流程完成软件开发 2、学会使用性能测试工具和单元测试以优化程序 |
一、PSP表格
| *PSP2.1* | *Personal Software Process Stages* | *预估耗时(分钟)* | *实际耗时(分钟)* |
|---|---|---|---|
| Planning | 计划 | 40 | 40 |
| Estimate | 估计这个任务需要多少时间 | 360 | 470 |
| Development | 开发 | 200 | 175 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 45 |
| Design Spec | 生成设计文档 | 10 | 15 |
| Design Review | 设计复审 | 10 | 5 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 3 | 3 |
| Design | 具体设计 | 20 | 20 |
| Coding | 具体编码 | 70 | 80 |
| Code Review | 代码复审 | 20 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 25 | 30 |
| Reporting | 报告 | 120 | 130 |
| Test Repor | 测试报告 | 30 | 25 |
| Size Measurement | 计算工作量 | 35 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 30 |
| 合计 | 983 | 1118 |
二、模块接口的设计与实现过程
1. 代码组织
-
模块化设计:将程序分为多个模块,每个模块负责一个特定的功能。
-
类和函数:
-
类:可以设计一个 TextSimilarityCalculator 类,封装所有与文本相似度计算相关的功能。
-
函数:将每个功能拆分为独立的函数,如读取文件、预处理文本、计算相似度等。
-
2. 关键函数
-
read_file(file_path):读取文件内容。
-
preprocess_text(text):对文本进行预处理(分词、去除停用词)。
-
calculate_similarity(text1, text2):计算两段文本的余弦相似度。
-
main():主函数,负责处理命令行参数并调用其他函数。
3. 函数关系
-
main() 调用 read_file() 读取文件内容。
-
main() 调用 preprocess_text() 对文本进行预处理。
-
main() 调用 calculate_similarity() 计算相似度。
-
main() 将结果写入输出文件。
4. 流程图
+-------------------+
| main() |
+-------------------+
|
v
+-------------------+
| read_file() |
+-------------------+
|
v
+-------------------+
| preprocess_text() |
+-------------------+
|
v
+-------------------+
|calculate_similarity()|
+-------------------+
|
v
+-------------------+
| write output |
+-------------------+
5. 算法关键
- 文本预处理:使用 jieba 进行中文分词,并去除停用词。
- 向量化:使用 CountVectorizer 将文本转换为词频向量。
- 余弦相似度:计算两个向量的余弦相似度,值越接近 1 表示文本越相似。
6. 独到之处
- 模块化设计:代码结构清晰,易于维护和扩展。
- 高效分词:使用 jieba 进行高效的中文分词。
- 灵活的相似度计算:通过 CountVectorizer 和 cosine_similarity 实现灵活的文本相似度计算。
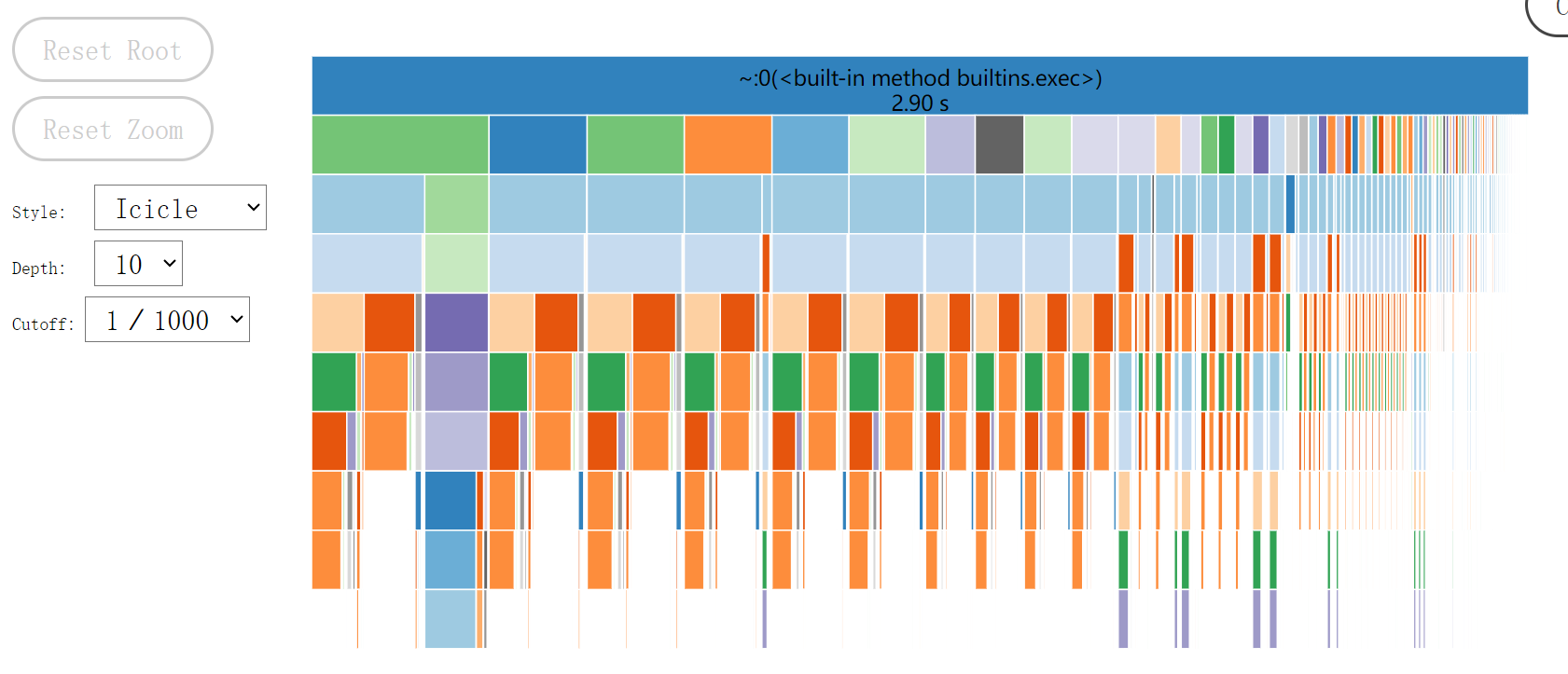
三、改进模块接口部分的性能
四、模块部分单元测试
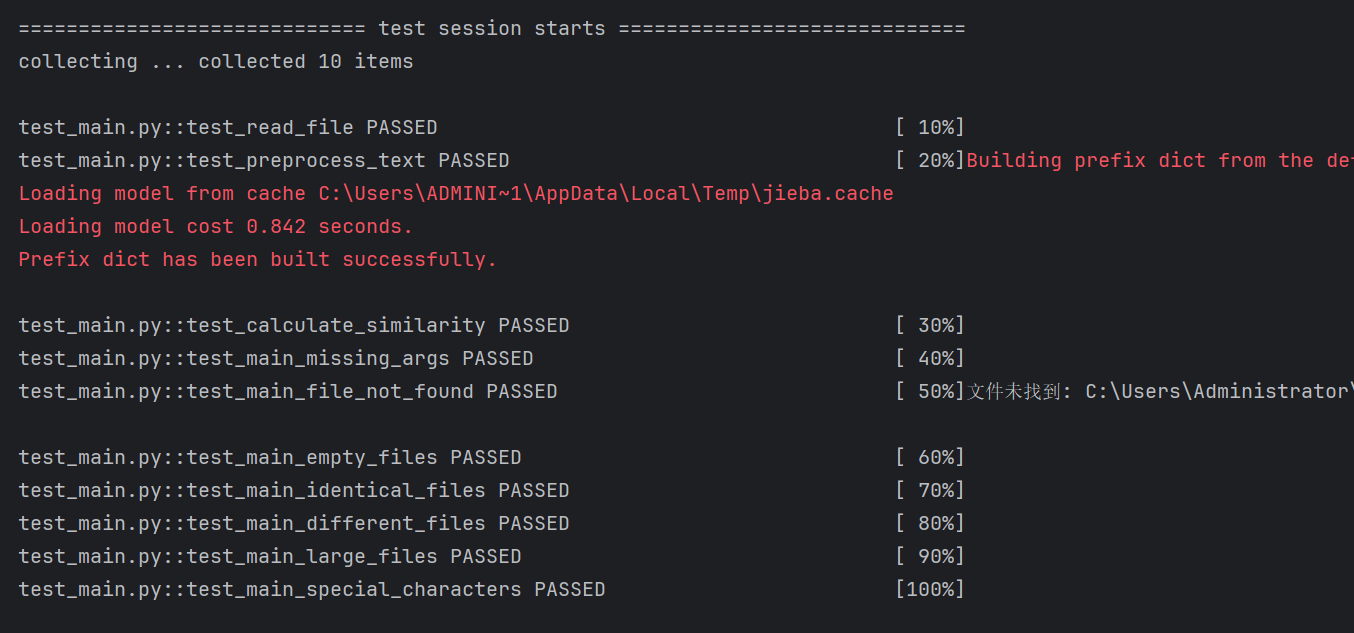
1. test_read_file
def test_read_file(tmpdir):
file_path = tmpdir.join("test_file.txt")
file_path.write("这是一个测试文件。")
content = main.read_file(file_path)
assert content == "这是一个测试文件。"
- 功能:测试 read_file 函数是否能正确读取文件内容。
- 测试数据:创建一个临时文件 test_file.txt,并写入内容 "这是一个测试文件。"。
- 预期结果:read_file 函数应返回文件内容 "这是一个测试文件。"。
2. test_preprocess_text
def test_preprocess_text():
text = "这是一个测试句子"
processed_text = main.preprocess_text(text)
assert processed_text == "这是 测试 句子"
- 功能:测试 preprocess_text 函数是否能正确分词并去除停用词。
- 测试数据:提供一个包含停用词的句子 "这是一个测试句子"。
- 预期结果:preprocess_text 函数应返回分词并去除停用词后的结果 "这是 测试 句子"。
3. test_calculate_similarity
def test_calculate_similarity():
text1 = "这是一个测试句子"
text2 = "这是另一个测试句子"
similarity = main.calculate_similarity(text1, text2)
assert 0 <= similarity <= 1
- 功能:测试 calculate_similarity 函数是否能正确计算两段文本的余弦相似度。
- 测试数据:提供两段相似的文本 "这是一个测试句子" 和 "这是另一个测试句子"。
- 预期结果:calculate_similarity 函数应返回一个介于 0 和 1 之间的相似度值。
4. test_main_missing_args
def test_main_missing_args(capsys):
with pytest.raises(SystemExit):
main.main([])
captured = capsys.readouterr()
assert "Usage: python main.py <original_file> <copied_file> <output_file>" in captured.out
- 功能:测试 main 函数在缺少命令行参数时的情况。
- 测试数据:不提供任何命令行参数。
- 预期结果:main 函数应输出用法信息并退出。
5. test_main_file_not_found
def test_main_file_not_found(tmpdir):
original_file = tmpdir.join("original.txt")
copied_file = tmpdir.join("copied.txt")
output_file = tmpdir.join("output.txt")
with pytest.raises(SystemExit):
main.main([original_file, copied_file, output_file])
- 功能:测试 main 函数在文件不存在时的情况。
- 测试数据:提供不存在的文件路径。
- 预期结果:main 函数应输出文件未找到的错误信息并退出。
6. test_main_empty_files
def test_main_empty_files(tmpdir):
original_file = tmpdir.join("original.txt")
copied_file = tmpdir.join("copied.txt")
output_file = tmpdir.join("output.txt")
original_file.write("")
copied_file.write("")
main.main([original_file, copied_file, output_file])
with open(output_file, 'r', encoding='utf-8') as f:
assert f.read() == "0.00"
- 功能:测试 main 函数在处理空文件时的情况。
- 测试数据:创建两个空文件 original.txt 和 copied.txt。
- 预期结果:main 函数应输出相似度 0.00。
7. test_main_identical_files
def test_main_identical_files(tmpdir):
original_file = tmpdir.join("original.txt")
copied_file = tmpdir.join("copied.txt")
output_file = tmpdir.join("output.txt")
original_file.write("这是一个测试句子")
copied_file.write("这是一个测试句子")
main.main([original_file, copied_file, output_file])
with open(output_file, 'r', encoding='utf-8') as f:
assert f.read() == "1.00"
- 功能:测试 main 函数在处理完全相同文件时的情况。
- 测试数据:创建两个内容相同的文件 original.txt 和 copied.txt,内容为 "这是一个测试句子"。
- 预期结果:main 函数应输出相似度 1.00。
8. test_main_different_files
def test_main_different_files(tmpdir):
original_file = tmpdir.join("original.txt")
copied_file = tmpdir.join("copied.txt")
output_file = tmpdir.join("output.txt")
original_file.write("这是一个测试句子")
copied_file.write("这是另一个测试句子")
main.main([original_file, copied_file, output_file])
with open(output_file, 'r', encoding='utf-8') as f:
similarity = float(f.read())
assert 0 <= similarity < 1
- 功能:测试 main 函数在处理完全不同文件时的情况。
- 测试数据:创建两个内容不同的文件 original.txt 和 copied.txt,内容分别为 "这是一个测试句子" 和 "这是另一个测试句子"。
- 预期结果:main 函数应输出一个介于 0 和 1 之间的相似度值。
9. test_main_large_files
def test_main_large_files(tmpdir):
original_file = tmpdir.join("original.txt")
copied_file = tmpdir.join("copied.txt")
output_file = tmpdir.join("output.txt")
original_file.write("这是一个测试句子。" * 1000)
copied_file.write("这是另一个测试句子。" * 1000)
main.main([original_file, copied_file, output_file])
with open(output_file, 'r', encoding='utf-8') as f:
similarity = float(f.read())
assert 0 <= similarity <= 1
- 功能:测试 main 函数在处理大文件时的情况。
- 测试数据:创建两个大文件 original.txt 和 copied.txt,内容分别为 "这是一个测试句子。" 和 "这是另一个测试句子。" 重复 1000 次。
- 预期结果:main 函数应输出一个介于 0 和 1 之间的相似度值。
10. test_main_special_characters
def test_main_special_characters(tmpdir):
original_file = tmpdir.join("original.txt")
copied_file = tmpdir.join("copied.txt")
output_file = tmpdir.join("output.txt")
original_file.write("这是一个测试句子!@#¥%……&*()")
copied_file.write("这是另一个测试句子!@#¥%……&*()")
main.main([original_file, copied_file, output_file])
with open(output_file, 'r', encoding='utf-8') as f:
similarity = float(f.read())
assert 0 <= similarity <= 1
- 功能:测试 main 函数在处理包含特殊字符的文件时的情况。
- 测试数据:创建两个包含特殊字符的文件 original.txt 和 copied.txt,内容分别为 "这是一个测试句子!@#¥%……&()" 和 "这是另一个测试句子!@#¥%……&()"。
- 预期结果:main 函数应输出一个介于 0 和 1 之间的相似度值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号