


20182322 2019-2020-1 《数据结构与面向对象程序设计》第9周学习总结
教材第16章学习内容总结
本章的内容主要讲树,顾名思义树与队列、栈、列表最大的区别就在于,树是一种非线性结构,其元素是一种层次结构存放。
树: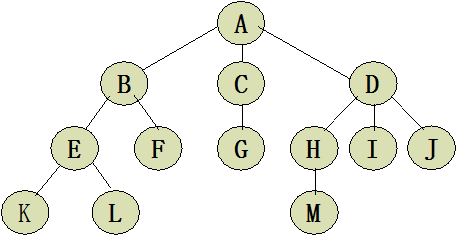
-
用于描述树相关的术语有非常多,除了之前常用的结点(node)还有边(edge)、孩子、兄弟等等,其中我认为比较重要的有:
- 内部节点:非根节点,且至少有一个子结点
- 同胞节点:属于同一节点的子结点
- 叶节点:不包含任何子节点的结点
-
树的分类:可以有非常多的分类方式,但是最重要的标准是任一结点可以具有的最大孩子数目,成为度(order),n元树的定义也是由此定义的
-
树的数组实现:因为数组实现树比较麻烦,所以在树的数组实现中书上同样模拟了链接策略,如图所示。
![]()
![]()
-
树的遍历,
-
前序遍历:从根节点开始访问每一个节点及其孩子。如图:
![]()
-
中序遍历:从根节点开始(注意并不是先访问根节点),中序遍历根节点的左子树,然后是访问根节点,最后中序遍历根节点的右子树。如图:
![]()
-
后序遍历:从左到右先叶子后节点的方式遍历访问左右子树,最后访问根节点。如图:
![]()
-
层序遍历:从树的第一层,也就是根节点开始访问,从上到下逐层遍历,在同一层中,按从左到右的顺序结点逐个访问。如图:
![]()
-




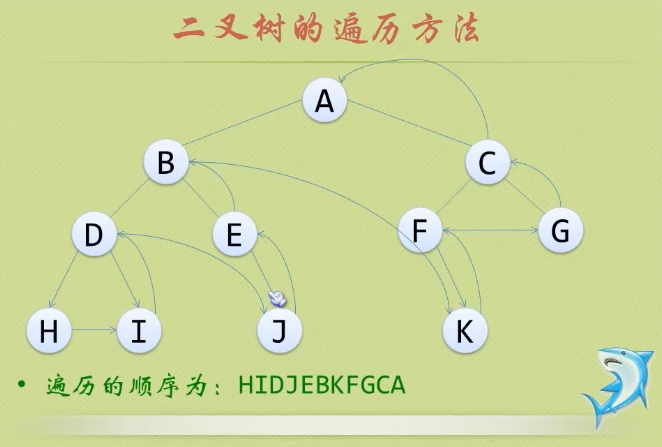
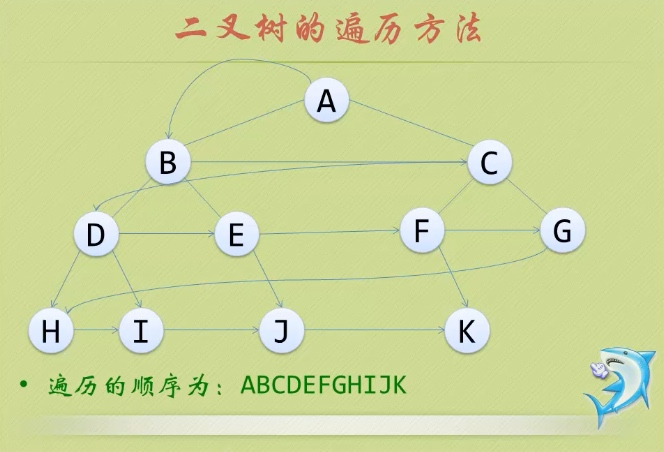
二叉树
(二叉树极其重要,以至于用三级标题来写它,而不是一般的一个点。)二叉树又名二元树,它的每一个结点最多具有两个孩子结点。
二叉树
(二叉树极其重要,以至于用三级标题来写它,而不是一般的一个点。)二叉树又名二元树,它的每一个结点最多具有两个孩子结点。
- 首先我们来看看百度百科的对树的定义:二叉树是一个连通的无环图,并且每一个顶点的度不大于3。有根二叉树还要满足根结点的度不大于2。有了根结点之后,每个顶点定义了唯一的父结点,和最多2个子结点。然而,没有足够的信息来区分左结点和右结点。如果不考虑连通性,允许图中有多个连通分量,这样的结构叫做森林。
- 与之前类似,本次教材也给出了二叉树的ADT
BinaryTreeADT其中的基本方法有:getRoot、isEmpty、size、contains、find、toString和一些迭代器相关的方法。 - 书上提供了两种二叉树的例子:表达式树和决策树。
- 关于二叉树的一些性质,例如,
- 在二叉树的第i层最多有2i-1个节点
- 深度为k的二叉树最多有2k-1个节点
- 对于任何一个二叉树,如果其叶结点个数为n0,度 为2的结点数尾n2,则有:n0=n2+1
- 关于完全二叉树的一些性质,例如,
- 具有n个结点的完全二叉树的高度为:log2n取下整数后+1
- 如果将一个有n个结点的完全二叉树自顶向下,同一层自左向右连续给结点编号1,2,...,n,则对于任意结点i(1<=i<=n),有:
- 若i=1,则该i结点是树根,它无双亲;
- 若2i>n,则编号为i的节点无左孩子,否则它的 左孩子是编号为2*i的结点;
- 若2i+1>n,则编号为i的结点无右孩子,否则右孩子的编号为2*i+1
教材第17章学习内容总结
一、概述
1.二叉查找树
-
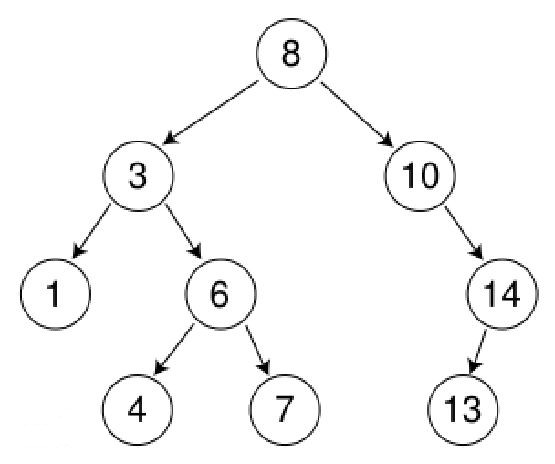
概念:树中的所有结点,其左孩子都小于父结点,父结点小于或等于其右孩子。
-
![]()
-
性质:
- 任意结点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 任意结点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 任意结点的左、右子树也分别为二叉查找树;
没有元素相等的结点。
2.二叉查找树ADT
- 二叉查找树的ADT是上一章中讨论的二叉树的扩展,其中的操作是二叉树中已定义的那些操作的补充。
- 二叉查找树中的操作:
addElement:向树中添加一个元素removeElement:从树中删除一个元素removeAllOccurrences:从树中删除所指定元素的任何存在removeMin:删除树中的最小元素removeMax:删除树中的最大元素findMin:返回树中的最小元素的引用findMax:返回树中的最大元素引用
二、二叉查找树的实现
1.查找
- 二叉查找树的查找方法与二分查找类似,将所要查找的元素与根结点的元素进行比较,如果小于根结点则继续与左孩子对比,大于根结点则继续与右孩子对比,如果相等则返回元素。实现方法有迭代和递归两种。
- 迭代实现
public void find(T element)
{
T result = null;
BinaryTreeNode node = root;
while (node != null)
{
if (element.CompareTo(node.getElement) > 0)
{
node = node.right;
}
else if (element.CompareTo(node.getElement) < 0)
{
node = node.left;
}
else
{
result = node.getElement;
break;
}
}
return result;
}
- 递归实现
public void find(T element)
{
return find(root, element);
}
private void find(BinaryTreeNode root, T element)
{
if (root == null) {
return element;
}
int comparable = element.CompareTo(root.getElement);
if (comparable > 0){
find(root.right,element);
}
else if (comparable < 0){
find(root.left,element);
}
else {
return root.getElement;
}
}
2.插入
- 进行插入的操作有三种情况:
- 若当前的二叉查找树为空,加入的元素会成为根结点。
- 若所插入结点的元素小于根结点的元素:
- 若根的左孩子为
null,插入结点将会成为新的左孩子。 - 若根的左孩子不为
null,则会继续对左子树进行遍历,遍历的同时进行比较操作。
- 若根的左孩子为
- 若所插入结点的元素大于或等于根结点的元素
- 若根的右孩子为
null,插入结点将会成为新的右孩子。 - 若根的右孩子不为
null,则会继续对右子树进行遍历,遍历的同时进行比较操作。
![]()
- 若根的右孩子为
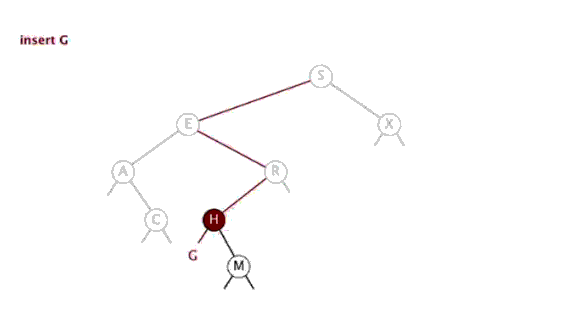
3.删除
- 二叉查找树的删除操作是所有操作中最为复杂的,我们先来考虑一种特殊情况:所删除的元素是树中的最大值或最小值。
(1)特殊情况:所删除元素为树中的最大值或最小值
- 由于二叉查找树的特殊形式,其最小值一般位于树的左子树,最大值位于树的右子树。两者的删除方法是类似的,唯一不同的地方就是“左”和“右”,下面我们以删除最大值为例来说明,删除最小值的情况只要把例子中的“左”和“右”交换一下即可。
- 删除最大值有三种情况:
- 若根结点没有右孩子,那么根结点的元素就为最大元素,原树根的左孩子则会变成新的根结点。
- 若最大值的结点是一个叶子结点,那么直接将其父结点的右孩子的引用设置为null即可。
- 若最大值的结点是一个中间结点,则需要设置其父结点的右孩子的引用为该结点的左孩子。
(2)正常情况
- 正常情况下删除元素也有三种情况,但这三种情况就不是那么简单了。
- 情况一:所删除的为叶子结点
- 这种情况下可以直接删除该结点。不论该结点是根结点还是普通的有父类的叶子结点,都直接将root或父结点与之连接的指针设置为空即可。
- 情况二:所删除的单支结点(即只有左子树或右子树)
- 当删除的结点是根结点时,将
root指针指向被删除结点的单支(左子树或右子树) - 当删除的结点只有左子树时,将所删除结点的父结点的指针指向所删除结点的左孩子。当删除的结点只有右子树时,将所删除结点的父结点的指针指向所删除结点的右孩子。
- 当删除的结点是根结点时,将
- 情况三:所删除的结点既有左子树又有右子树
- 这里需要了解两个概念——前驱结点和后继结点。分别是树中小于它的最大值和大于它的最小值,如果把树结构中的所有节点按顺序排好的话,它的前驱和后继两个结点刚好在它的左右。当一个节点被删除时,为了保证二叉树的结构不被破坏,要让它的前驱结点或者后继结点来代替它的位置,然后将它的前驱结点或者后继结点做同样的删除操作。
- 将当前结点与左子树中最大的元素交换,然后删除当前结点。左子树最大的元素一定是叶子结点,交换后,当前结点即为叶子结点,其删除方式即可参考情况一。还可以将当前结点与右子树中最小的元素交换,然后删除当前结点。
教材学习中的问题和解决过程
- 问题1:如何创建一个泛型方法
- 问题1解决方案:
public <T> T genericMethod(Class<T> tClass)throws InstantiationException ,
IllegalAccessException{
T instance = tClass.newInstance();
return instance;
}
- 问题2:对于红黑树存在的意义问题,为什么要单独设置一个红黑树呢?红黑树可以解决的问题AVL树也同样可以解决。
- 问题2解决方案:这个问题我在网上查找了部分答案,发现为什么需要发明红黑树。
- 最主要就是效率问题,红黑树并不追求“完全平衡”——它只要求部分地达到平衡要求,降低了对旋转的要求,从而提高了性能。
- 当然这也不是没有代价的,红黑树是牺牲了严格的高度平衡的优越条件为代价让红黑树能够以O(log2 n)的时间复杂度进行搜索、插入、删除操作。
- 问题3:在书中说,LinkedBinarySearchTree类提供了两个构造函数,这两个函数都只是引用了其超类(LinkedBinaryTree类),但是好像很少听到超类这个词
- 问题3解决方案:我上网查了下,就暴露了我以前书看的不好的问题了。原来超类就是父类啊。
public class A{//定义类A
}
public class B extends A{//定义类B,继承类A
}
则,类A就是超类或父类,类B叫子类
代码调试中的问题和解决过程
- 问题1:在编写补全二叉树的contains方法时,第一次自己的代码如下
public boolean contains(T targetElement) {
BinaryTreeNode current = root;
BinaryTreeNode temp = root;
boolean contains = false;
if (current == null) {
contains = false;
}
if (current.getElement().equals(targetElement)) {
contains = true;
}
while (current.right != null)
{
if (current.right.getElement().equals(targetElement)) {
contains = true;
} else {
current = current.right;
}
}
while (temp.left != null)
{
if (temp.left.getElement().equals(targetElement))
{
contains = true;
}
else {
temp = temp.left;
}
}
return contains;
}
这导致我测试该方法时只要是在判断非根节点就会出现程序一直运行无法停止的情况。
- 问题1解决方案:仔细回顾了自己的代码,发现问题应该出现在while循环中,发现虽然我在代码中写到了如果查找/未找到到该元素就返回true/false然后返回该循环,没有跳出操作,导致程序一直运行。所以说我分别改为了
if(current.right.getElement().equals(taretElement)) {
contains = true;
break;
}
和
if (temp.left.getElement().equals(targetElement))
{
contains = true;
break;
}
后便解决了该问题。
- 问题2:removeMax、findMax、findMin如何编写?
- removeMax:删除树中的最大元素
- findMax:返回树中最小元素的引用
- findMin:返回树中最大元素的引用
- 问题2解决方案:书中给出了删除最小元素的方法,根据提供的代码以及二叉查找树的了内部结构,最小元素在根结点的左侧查找,那么最大元素则在根结点的右侧查找。具体分析一下删除最小元素,根据二叉查找树的结构可以发现在查找最小元素的时候,如果根结点的左侧没有子结点,那么根结点即为要删除的最小结点,根结点的右侧子节点为新的根结点。如果根结点的左侧有子结点,那么遍历左侧找到最小的结点,但是直接删除给节点是不行的,要考虑到删除的该结点的时候有可能存在其右子结点,这是要把右子结点移到删除结点的位置。所以,删除最大元素,也分两种情况,在根结点的右侧没有子结点,那么根结点即为要删除的最大元素,根结点的左侧元素即为根结点。如果根结点的右侧右子结点,那么遍历右侧找到最大的结点,把该结点的左子结点替代到删除的位置。而查找的方法只需在省略删除结点的子结点替代删除位置的相关代码就行。
- 问题3:在无返回值的条件下语句有return的作用?
- 问题3解决方法:return的使用一直在存在返回值条件下使用,但是从未在无返回值条件下使用。如果return后面不接内容的话,就会结束该方法并不会输出任何内容的。
- (1.)return语句:是指结束该方法,继续执行方法后的语句。
- (2.)break语句:是指在循环中直接退出循环语句(for,while,do-while,foreach),break之后的循环体里面的语句也执行。
- (3.)continue语句:是指在循环中中断该次循环语句(for,while,do-while,foreach),本次循环体中的continue之后语句不执行,直接跳到下次循环。
- 问题4:表达式树的输出为什么总是输出不对?
- 问题4解决方法:书上表达式树的代码在进行树的输出时候,总会输出的稀乱稀乱的一堆,代码也没有爆红。第一次通过单步调试发现,是自己的getHeight()方法的方法体没有写,导致输出的结果总是0。还要自己修改getHeight()...悲惨自行补了相关代码,先判断树是不是空的,不空的话通过书上的代码,进行判断是否是叶结点进行循环遍历,在遍历的过程中进行计数。但是在输出树的情况下就是缺最后一行,通过尝试对一个已知高度的树调用getHeight()方法时,在输出的时候发现会比实际高度少1,所以在计数变量的初始值从0改为1尝试一下,结果就完整了。
-
第一次修改:
![]()
-
第二次修改:
![]()
-
第三次修改:
![]()
-


代码托管
上周考试错题总结
-
It is possible to implement a stack and a queue in such a way that all operations take a constant amount of time.
A .true B .false -
正确答案: A
-
我的答案: B
-
解析: 理想情况。
-
In a circular array-based implementation of a queue, the elements must all be shifted when the dequeue operation is called.
A .true B .false -
正确答案: B
-
你的答案: A
-
解析:基于循环数组的队列实现无需移动元素。
-
In removing an element from a binary search tree, another node must be ___________ to replace the node being removed.
A .duplicated B .demoted C .promoted D .None of the above -
正确答案: C
-
我的答案: B
-
解析:当在二叉查找树上删除一个结点时,后面的结点需要向上移动来补全。当时,以为越靠近根结点说明深度越低,所以是降级了;但是看完答案好像人家的意思是向上补全。题意理解不准确哈哈
结对及互评
评分标准
-
正确使用Markdown语法(加1分):
- 不使用Markdown不加分
- 有语法错误的不加分(链接打不开,表格不对,列表不正确...)
- 排版混乱的不加分
-
模板中的要素齐全(加1分)
- 缺少“教材学习中的问题和解决过程”的不加分
- 缺少“代码调试中的问题和解决过程”的不加分
- 代码托管不能打开的不加分
- 缺少“结对及互评”的不能打开的不加分
- 缺少“上周考试错题总结”的不能加分
- 缺少“进度条”的不能加分
- 缺少“参考资料”的不能加分
-
教材学习中的问题和解决过程, 一个问题加1分
-
代码调试中的问题和解决过程, 一个问题加1分
-
本周有效代码超过300分行的(加2分)
- 一周提交次数少于20次的不加分
-
其他加分:
- 周五前发博客的加1分
- 感想,体会不假大空的加1分
- 排版精美的加一分
- 进度条中记录学习时间与改进情况的加1分
- 有动手写新代码的加1分
- 课后选择题有验证的加1分
- 代码Commit Message规范的加1分
- 错题学习深入的加1分
- 点评认真,能指出博客和代码中的问题的加1分
- 结对学习情况真实可信的加1分
-
扣分:
- 有抄袭的扣至0分
- 代码作弊的扣至0分
- 迟交作业的扣至0分
点评模板:
-
博客中值得学习的或问题:
- 排版工整
- 对问题都深入研究
-
代码中值得学习的或问题:
- 代码有自己的理解
- 代码排列不大美观
-
基于评分标准,我给本博客打分:9分。得分情况如下:
-
正确使用Markdown语法+1.
-
教材学习中的问题和解决过程+2.代码调试中的问题和解决过程+2.
-
感想,体会不假大空+1.
-
错题学习深入+1.
-
点评认真.课后题有验证+1.
-
进度条有记录+1.
点评过的同学博客和代码
- 结对学习情况
其他(感悟、思考等,可选)
- 这次学习内容较多,有好多东西没有理解通透,需要多敲代码来深入学习。
- 还有安卓的操作还不是很熟练,还需要花费大量时间去学习。
- 最近作业量太大了,老师上课讲的东西消化不良,所以还需努力学习。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 10000行 | 30篇 | 400小时 | |
| 第一周 | 59/200 | 2/2 | 20/20 | |
| 第三周 | 292/331 | 2/4 | 20/40 | |
| 第四周 | 677/969 | 2/6 | 20/60 | |
| 第五周 | 661/1265 | 2/8 | 20/80 | |
| 第六周 | 1299 /2554 | 2/10 | 20/100 | |
| 第七周 | 1500/4054 | 2/12 | 20/120 | |
| 第八周 | 2511 / 6565 | 2/14 | 20/140 | |
| 第九周 | 3538/10103 | 2/16 | 20/160 |
-
计划学习时间:20小时
-
实际学习时间:20小时
-
改进情况:学期最后阶段,任务很多,要学会利用缝隙时间来学习。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号