
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/zswxy/computer-science-class3-2018/homework/11879 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/zswxy/computer-science-class3-2018/homework/11879 |
| 这个作业的目标 | 学会使用Gitee并且统计编程 |
| 学号 | 20188479 |
| 其他参考文献 | 《构建之法》 |
Gitee地址
https://gitee.com/w010616
https://gitee.com/w010616/project-c
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(小时) | 实际耗时(小时) |
|---|---|---|---|
| Planning | 计划 | 5 | 10 |
| • Estimate | • 估计这个任务需要多少时间 | 5 | 10 |
| Development | 开发 | 10 | 17 |
| • Analysis | • 需求分析 (包括学习新技术) | 0.5 | 1 |
| • Design Spec | • 生成设计文档 | 1 | 2 |
| • Design Review | • 设计复审 | 1 | 2 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 1 | 1 |
| • Design | • 具体设计 | 2 | 5 |
| • Coding | • 具体编码 | 3 | 5 |
| • Code Review | • 代码复审 | 0.5 | 0.5 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 1 | 0.5 |
| Reporting | 报告 | 5 | 8 |
| • Test Repor | • 测试报告 | 2 | 3 |
| • Size Measurement | • 计算工作量 | 1 | 2 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 2 | 3 |
| 合计 | 20 | 35 |
解题思路
刚拿到题目时,确实无从下手,在电脑前面踟蹰了好久,眼看时间越来越少,还是决定要努力一把写一写。看了许多参考文献后,我认为文本读写可以用io库 ,读入字符串后用正则表达式或者自己写字符串分割函数或者封装好的分割函数来获取单词,词频统计用HashMap储存,结果排序后输出。程序有两个类,一个是Main.java,另一个是lib.java,Main.java是程序的入口,文件写入和打印函数,以及一个文本编码判断函数,lib.java包含一些函数例如字符数计算,单词个数计算,单词统计等,lib.java中的函数全部为静态,因此不需要实例化lib对象,直接使用类.方法即可调用类中的方法,由于功能模块互相独立,因此每调用一次函数,都要读取一次文件。Main.java调用lib.java中的函数并输入计算出的值。但是Java尝试多次后没能成功,还是决定用C写。尝试用哈希,二叉树或链表做。
实验需要实现的基本需求
1.统计文件的字符数(对应输出第一行)。
2.统计文件的单词总数(对应输出第二行),单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
3.统计文件的有效行数(对应输出第三行):任何包含非空白字符的行,都需要统计。
4.统计文件中各单词的出现次数(对应输出接下来10行),最终只输出频率最高的10个。
代码片段
头文件
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<ctype.h>
#define M 5000
二叉数遍历
while( !feof(in) )
{
char temp_word[26] = {0};
get_word(temp_word,in);
root = insert(root, temp_word);
}
printf("%s ", root->word);
if(root->rchild != NULL && root->rchild->rchild == NULL) printf("%s\n", root->rchild->word );
else printf("%s ", root->rchild->word );
if(root->rchild->rchild != NULL) printf("%s\n", root->rchild->rchild->word);
inorder(root); /*traverse the tree using inorder way 因为是二叉排序树 所以输出就是按照字典序的*/
return 0;
}
对词频结果统计并排序
void mergeSort(wordNode **headnode){
wordNode *pre,*next,*head;
head = *headnode;
void inorder(BTREE T) /*using inorder*/
{
if(T!= NULL)
{
inorder(T->lchild);
if( strlen(T->word) >0 )
printf("%s %d\n", T->word, T->count);
inorder(T->rchild);
}
}
运行过程及截图
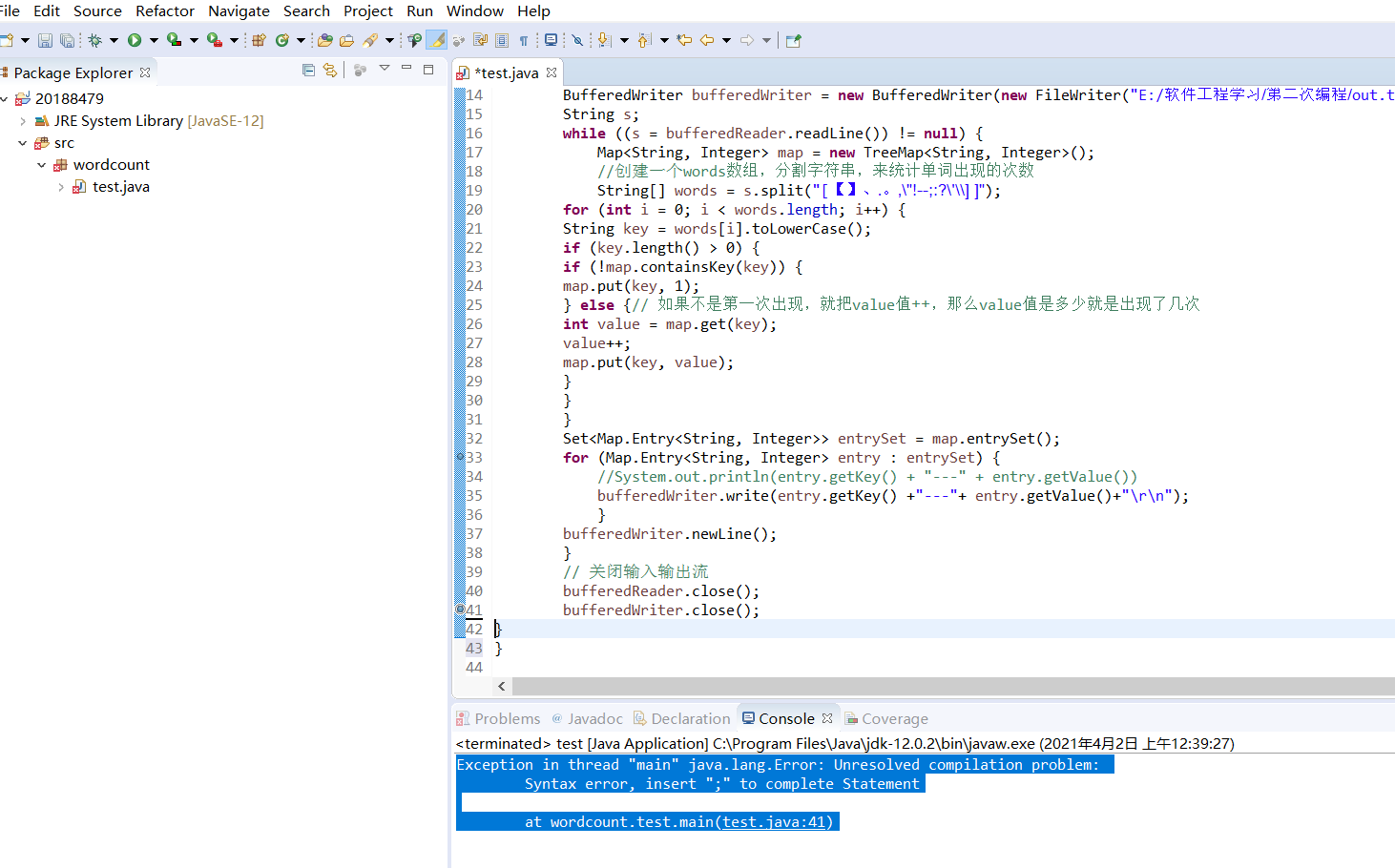

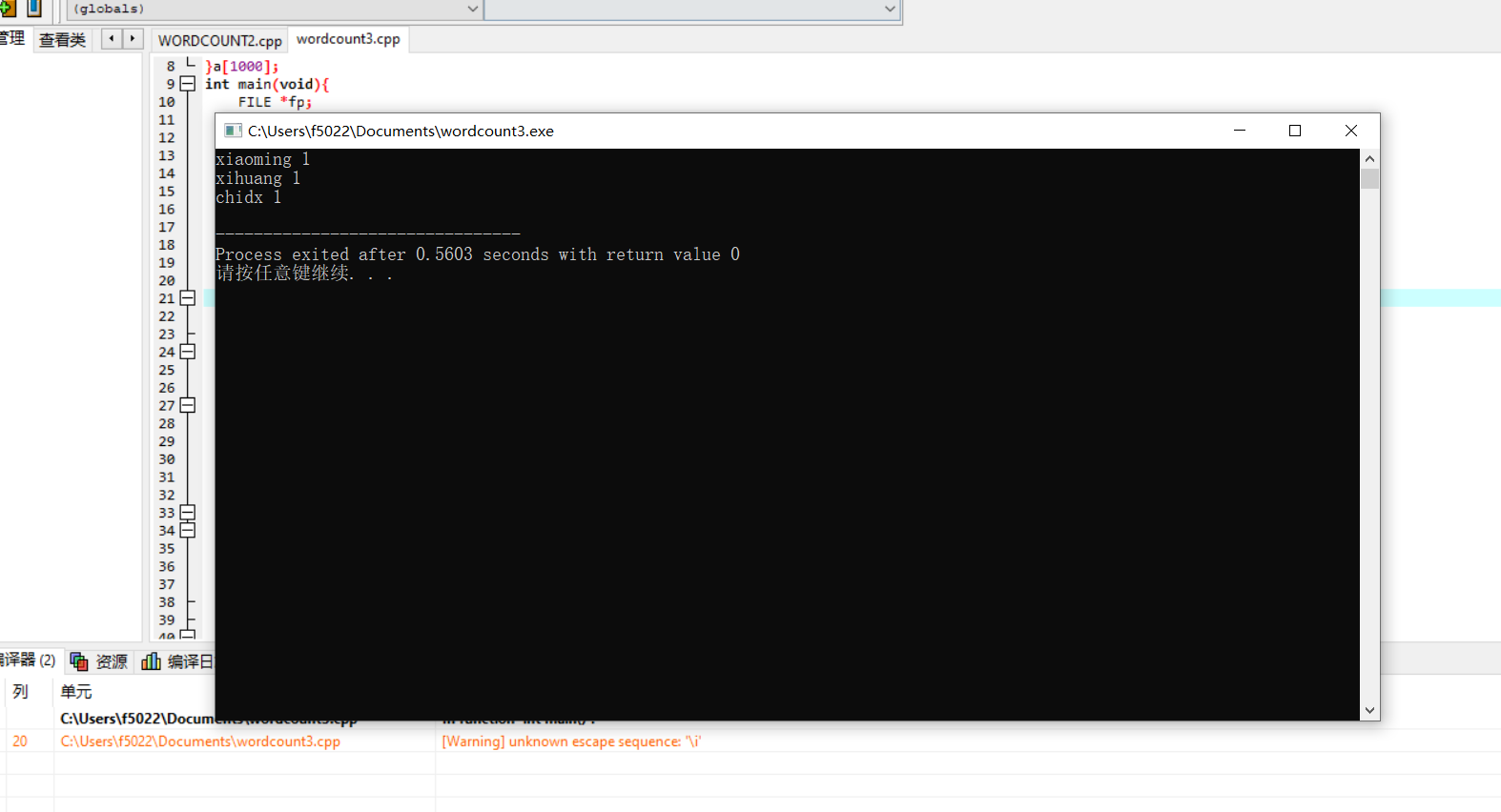

心得
在做作业过程中,深刻意识到自己能力的薄弱和不足,要多多提升自己。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号