
py5 编码问题
编码问题
字符编码的发展
ASCII码
ASCII码即为(American Standard Code for Information Interchange)由美国人发明,用于计算机进行字符处理和表示,使用7位(bit)来表示一个字符,总共能够表示128种字符。后来IBM对这套ASCII码进行了扩充,使用8位来表示一个字符,新增了128种字符,这也仅仅是对一些拉丁字母和特殊符号的扩充。
GB2312码
当计算机普及到全世界时,各个国家都针对自己国家的语言制定自己国家的编码规范,我国就提出里一套针对中文的GB2312的编码方式,兼容ASCII码,汉字用两个字节表示,英文和符号用一个字节的ASCII表示。ASCII码最高位为0,当机器度到字节最高位为0的时候,读为ASCII码,GB2312码汉字区的两个字节的最高位都为1
GBK码
GB2312只能编入部分常用汉字,为了把更多的汉字编入进来,针对GB2312进行扩充,就创造出了GBK标准。GBK码用两个字节表示汉字(当高字节首位为1时就表示汉字的开始),一个字节表示英文和符号,兼容ASCII码和GB2312码。其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字。其中GB2312码部分,两个字节的最高位都为1以此判定是GB2312码,GBK码的高字节首位为大于1(弃用扩展ASCII码128-255)。
ANSI
类似我国的编码方案,其他地区和国家也制定了自己的编码方案,如日本的Shift-JIS等等。这些编码方案称为 “DBCS”(Double Byte Charecter Set 双字节字符集)”即是用双字节表示一个字符,也称为ANSI,这里的ANSI代表了不同国家的不同编码方案。在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码。由于ANSI的定义,也引发了一个严重的问题:不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。
UNICODE字符集
为了统一全世界的文字编码,ISO(国际标准化组织)制定了UNICODE字符集(Universal Multiple-Octet Coded Character Set)UNICODE-2码用两个字节编码,UNICODE-4码用四个字节编码。由于ASCII码表示一个字符1个字节,而Unicode需要2,会大量浪费内存,并且个严格意义上说Unicode只是一套标准,为全世界文字给予一个唯一的编码,但是并没有规定在计算机中如何存储,所以根据Unicode标准来制定具体的实施方案就是UTF-8。
UTF-8码
UTF-8是可变长编码根据具体情况用1-4个字节来编码,英文用原本的ASCII码,欧洲语系2个字节,东亚三个字节,其他及特殊字符用4个![Alt text]()

计算机硬盘等存储的是utf-8节省存储空间,计算机内存存储的是Unicode,因此读写的时候会出现编码转换;网络传输一样,网络传输使用utf-8编码节省通信开销,计算机内存中存储的是Unicode,因此读写的时候也会出现编码转换。


如何查看文件编码
将文件用记事本打开,然后另存为界面就能看到
运行程序时各编码间的联系
-
文件编码:文件以何种编码存入硬盘,以何种编码读取出来。
-
系统编码:操作系统是何默认编码,意味着系统软件的默认编码都是操作系统的默认编码。例如简体中文windows默认编码为GBK,繁体中文windows默认编码为Big5码,Linux默认编码为UTF-8。
-
编辑器编码:由于硬盘读写速度太慢编辑器直接与内存交互,在编辑器编写的内容也是存放于内存中的,断电后数据丢失,因而要保存到硬盘上。保存后,从内存中把数据刷到了硬盘上。编辑器,如word,pycharm等,有默认的编码,在此编辑器编写文件会按该编辑器默认编码方式存入硬盘(特殊声明除外)
-
解释器编码:启动解释器第一步相当于先启动了一个编辑器,通过编辑器先将文件读到内存中,然后进行解析。编码方面,以cpython解释器为例,首以解析器的编码去解析文件。
运行程序时各编码间的联系
下面以一个例子来说明程序运行时用到的编码
以python3和简体中文windows环境为例:
-
在pycharm中编写hello.py文件,然后保存(文件以utf-8编码保存在硬盘中)。
# hello.py
s='韦连鑫'
print('hello' + s)
-
关闭后打开,pycharm以utf-8的编辑器默认编码解析硬盘中文件的二进制数据,转成unicode存入内存,以明文的形式显示给我们看。
-
执行,Cpython解释器先调用编辑器以utf-8的编辑器默认编码解码文件bytes数据为unicode,然后翻译成c代码,转化成二进制后调用cpu进行执行。

python版本对编码的影响
python2中的编码
在py2中,有两种字符串类型:str类型和unicode类型。str和unicode分别存的是字节(Bytes)数据和unicode数据。str 和 unicode 都有 encode 和 decode 方法。但是不建议对 str 使用 encode,对 unicode 使用 decode, 这是 Python2 设计上的缺陷。Python3 则进行了优化,str 只有一个 encode 方法将字符串转化为一个字节码,而且 bytes 也只有一个 decode 方法将字节码转化为一个文本字符串。

#_*_coding:gbk_*_
#!/usr/bin/env python
x='林'
# print x.encode('gbk') #报错
print x.decode('gbk') #结果:林
s = " " # 类型是str,它是依操作系统而定的某种编码类型的字符串
s = u" " # 类型是unicode,Unicode编码类型的字符串
python3中的编码
python3把字符串变成了unicode,文件默认编码变成了utf-8,这意味着,只要用python3,无论你的程序是以哪种编码开发的,都不用担心中文问题。
python3除了把字符串的编码改成了unicode, 还把str 和bytes 做了明确区分, str 就是unicode格式的字符,bytes就是单纯二进制,二者通过encode和decode进行转换。
s = '你好' # unicode类型
print(s) # 你好
print(s.encode('gbk')) # b'\xc4\xe3\xba\xc3'
ss = s.encode('gbk') # unicode转换成bytes
print(ss.decode('gbk')) # 你好

Python3 bytes 函数
Python3 内置函数bytes()
描述
bytes 函数返回一个新的 bytes 对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列。它是 bytearray 的不可变版本。
语法
以下是 bytes 的语法:
class bytes([source[, encoding[, errors]]])
>>>a = bytes([1,2,3,4])
>>> a
b'\x01\x02\x03\x04'
>>> type(a)
<class 'bytes'>
>>>
>>> a = bytes('hello','ascii')
>>>
>>> a
b'hello'
>>> type(a)
<class 'bytes'>
>>>
版本对对编码的影响
-
Python2 的 str 和 unicode 都是 basestring 的子类,所以两者可以直接进行拼接操作。而 Python3 中的 bytes 和 str 是两个独立的类型,两者不能进行拼接。
-
Python2 中,普通的,用引号括起来的字符,就是 str,str前面加个字母u的就是unicode;此时str字符串的编码类型,对应着你的 Python 文件本身保存为何种编码有关,最常见的 Windows 平台中,默认用的是 GBK。Python3 中,被单引号或双引号括起来的字符串,就已经是 Unicode 类型的 str 了。
对编码理解的检验
如果你看懂了上面的编码问题,下面这几种情况可以检验是否真正理解
-
cmd下的乱码问题这里有一个hello.py文件
#coding:utf8
print ('hello 张三')
件保存时的编码也为utf8。
问题:为什么在IDE下用2或3执行都没问题,在cmd.exe下3正确,2乱码呢?
答案:我们在win下的终端即cmd.exe去执行,大家注意,cmd.exe本身也一个软件;当我们python2 hello.py时,python2解释器(默认ASCII编码)去按声明的utf8编码文件,而文件又是utf8保存的,所以没问题;问题出在当我们print’苑昊’时,解释器这边正常执行,也不会报错,只是print的内容会传递给cmd.exe用来显示,而在py2里这个内容就是utf8编码的字节数据,可这个软件默认的编码解码方式是GBK,所以cmd.exe用GBK的解码方式去解码utf8自然会乱码。
py3正确的原因是传递给cmd的是unicode数据,cmd.exe可以识别内容,所以显示没问题。
-
open()中的编码问题创建一个hello文本,保存成utf8:
hello world 你好,世界
同目录下创建一个index.py
f=open('hello')
print(f.read())
为什么在linux下,结果正常,在win下却是乱码(py3解释器)?
因为你的win的操作系统安装时是默认的gbk编码,而linux操作系统默认的是utf8编码;
当执行open函数时,调用的是操作系统打开文件,操作系统用默认的gbk编码去解码utf8的文件,自然乱码。
解决办法:
f=open('hello',encoding='utf8')
print(f.read())
如果你的文件保存的是gbk编码,在win 下就不用指定encoding了。
另外,如果你的win上不需要指定给操作系统encoding=’utf8’,那就是你安装时就是默认的utf8编码或者已经通过命令修改成了utf8编码。
注意:open这个函数在py2里和py3中是不同的,py3中有了一个encoding=None参数。
-
文件乱码与运行报错原因以最开始的hello文件为例,新建一个hello.py文件并以gbk编码保存
# hello.py
s='韦连鑫'
print('hello' + s)
在pycharm中打开后如下

由于pacharm默认编码是utf-8,所以在解码文件时把GBK文件以UTF-8读出,所以会显示乱码,此处可以通过pycharm右下角的编码格式更改,成gbk则可正常显示。
当文件运行时,又会报出如下错误

原因是python3解析器默认编码是utf-8,以utf-8解码gbk文件所以会报如下错误
解决方法:
在文件开头加上# encoding=gbk
如此,解释器与编辑器都会以gbk方式来读取和解码文件
总结
-
编码的发展历程大致可概括为ASCII >> GB2312 >> UNICODE >> UTF-8
-
各种编码之间的联系可通过下图理解
-
python版本对字符串编码的影响

注意
- python文件头部声明的编码和pycharm右下角的编码(文件默认编码)意思是文件都是按声明编码存入硬盘的(py2默认为ASCII码py2默认为utf-8),
读文件按文件头部声明(无声明默认为utf-8)读到pycharm,右下角编码方式可以用reload选取读取文件的编码方式(不改变原文件存储的编码),但是右下角的编码明明是存入的编码方式,你这样一改右下角编码方式不就和文件的存储编码方式不一样了么。别急,只要你保存了文件,该文件就又按右下角的编码方式保存到了磁盘,这样读取方式和保存方式就又一样了
- py3会自动将编码转换成UNICODE放入内存,如下。

- py2中有str和UNICODE两种字符串类型,不是UNICODE的都是str
- Python2中默认编码为ASCII码,想写中文就必须在开头加上声明,例如你文件编码是UTF-8,存到内存还是UTF-8,这样在windows中是乱码,因为windows中内码是gbk码,需要用encode和decode
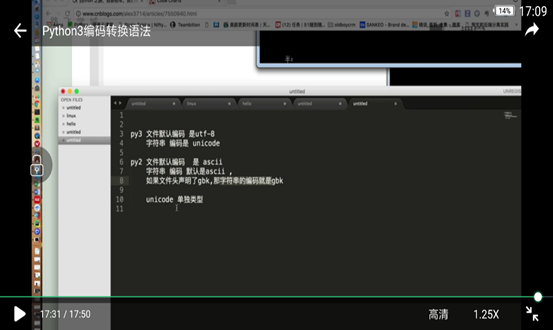

python3默认编码为UNICODE码,会自动转换,不存在这些问题
PY3 除了把字符串的编码改成了unicode, 还把str 和bytes 做了明确区分, str 就是unicode格式的字符, bytes就是单纯二进制啦。



在看实际代码的例子前,我们来聊聊,python3 执行代码的过程
1.解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
2.把代码字符串按照语法规则进行解释,
3.所有的变量字符都会以unicode编码声明

 浙公网安备 33010602011771号
浙公网安备 33010602011771号