浅谈CC攻击原理与防范
概念
CC攻击的原理就是攻击者控制某些主机不停地发大量数据包给对方服务器造成服务器资源耗尽,一直到宕机崩溃。CC主要是用来攻击页面的,每个人都有这样的体验:当一个网页访问的
人数特别多的时候,打开网页就慢了, CC就是模拟多个用户(多少线程就是多少用户)不停地进行访问那些需要大量数据操作(就是需要大量CPU时间)的页面,造成服务器资源的浪费,
CPU长时间处于100%, 永远都有处理不完的连接直至就网络拥塞,正常的访问被中止。
攻击方式
通常发起 CC 攻击是使用专门的攻击工具,同时模拟成多个用户,向目标网站发起多个请求,一般这些软件为了防止地址被屏蔽,还内置通过代理攻击的功能。可以通过多个代理服务器对
目标发起攻击,使封 IP 的防御方式变的失效。
防御思路
我们抛开购买的软件来防护 下面主要从程序角度来做防护。
某人使用过某某网站卫士来预防攻击他的评价:
从界面上看,似乎是防止了大量的CC攻击,但登录网站后发现,流量依旧异常,攻击还是依旧,看起来这个网站卫士的效果并没有达到。
从原理上看,基本上所有的防火墙都会检测并发的TCP/IP连接数目,超过一定数目一定频率就会被认为是Connection-Flood。但如果IP的数量足够大,使得单个IP的连接数较少,
那么防火墙未必能阻止CC攻击。
启用了某某网站卫士之后,反而更容易被CC攻击,因为这个网站卫士并不能过滤掉CC攻击,攻击的IP经过其加速后,更换成为这个网站卫士的IP,在网站服务器端显示的IP都是相同的,
导致服务器端无法过滤这些IP。
因为 CC 攻击通过工具软件发起,而普通用户通过浏览器访问,这就是区别。我们只有想到办法对这二者作出正确的判断,屏蔽来自机器的流量攻击就没问题了。
思路一:
普通浏览器发起请求时,除了要访问的地址以外, Http 头中还会带有 Referer , UserAgent 等多项信息。遇到攻击时可以通过访问日志查看访问信息,看攻击的流量是否有明显特征,
比如固定的 Referer 或 UserAgent ,如果能找到特征,就可以直接屏蔽掉了。
HTTP_Referer 名词解释 看单词知道大概意思是 http的访问来源
HTTP Referer是header的一部分,当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器我是从哪个页面连接过来的。
UserAgent 名词解释
HTTP_USER_AGENT是用来检查浏览页面的访问者在用什么操作系统(包括版本号)浏览器(包括版本号)和用户个人偏好的代码。
UserAgent 标准格式是 : 浏览器标识 (操作系统标识; 加密等级标识; 浏览器语言) 渲染引擎标识 版本信息(但是不同的浏览器的格式是不同的,大体都包括这些内容)
下图就是 浏览器的 HTTP_Referer 和 HTTP_USER_AGENT

大家明白了的吧 如果这两个有固定的特征就可以直接用程序屏蔽了)
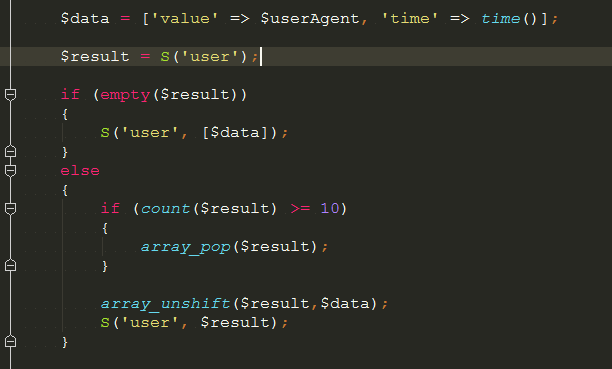
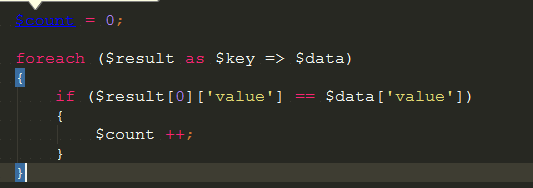
这里用useragent做了一个判断逻辑是这样的
缓存最近访问的二十条记录, 如果到了二十条就开始做对比,如果这二十条的user-agent 一样就把这个user-agent 给封了,
如果不一样就继续回到0 开始, 为了避免网站一个人访问的情况下误杀,加上一个时间判断效果最好 比如 三秒内。
上代码
然后对比
计算时间差

我这里是根据实际情况判断的 (考虑到白名单, 黑名单, ip断等场景需要)

好了 userAgent 防御大概就说这么多。
思路二:
上面也说了用userAgent可以根据情况来屏蔽, 但是这个玩意还是可以伪造的(ps: 虽然 比较困难),如果伪造了我们就要像其它办法了;我们知道一般的
攻击软件一般来说功能都比较简单,只有固定的发包功能,是不支持完成的http协议的 而浏览器会完整的支持 Http 协议,我们可以利用这一点来进行一下防御。
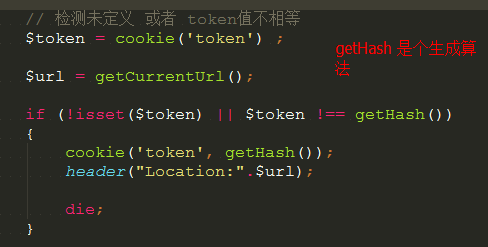
用户初次访问的时候我们定义个规则 token(ps:这个应该是有唯一key 生成的),保存在 COOKIE 中作为 Token ,用户必须要带有正确的 Token 才可以访问后端服务。当用户第一次访问时,会
检测到用户的 COOKIE 里面并没有这个 Token ,则返回一个 302 重定向跳转,目标地址为当前页面,同时在返回的 Http 头中加入 ,对 COOKIE 进行设置,使用户带有这个 Token 。
客户端如果是一个正常的浏览器,那么就会支持 HTTP 头中的 SET COOKIE 和 302 重定向指令,将带上正确的 Token 再次访问页面,这时候后台检测到正确的 Token ,就会放行,
这之后用户的 Http 请求都会带有这个 Token ,所以并不会受到阻拦。客户端如果是 CC 软件,那么一般不会支持这些指令,那么就会一直被拦在最外层,并不会对服务器内部造成压力。
代码:这里主要用php 代码来说明
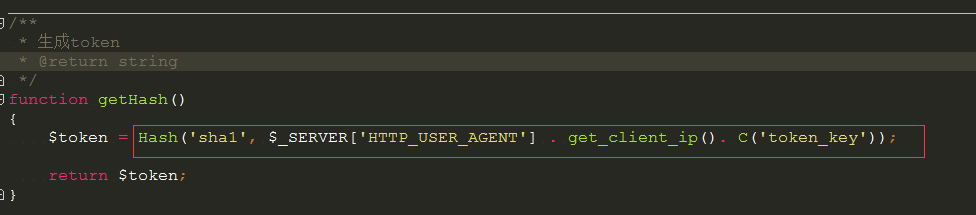
token 生成算法 大致这样 UserAgent + client_ip + key 这样就避免了无法伪造,保证了相同的客户端的 token 的一致性。
对 CC 攻击者来说,在使用固定或者唯一 Token 的情况下,攻击成本是有差别的。
很多攻击软件是可以设置 http 头的,如果使用固定 Token ,攻击者只需要在本机获取一次 Token ,然后设置好 http 头就可以直接发起攻击了,攻击成本低的可以,
但是如果使用可变 Token ,基本市面上所有 CC 软件全都无法使用了 ,我们这个就是可变的token (随 IP 地址变化是为了防止通过一台机器获取 Token 之后,再通过代理服务来进行攻击)
实际上 token 只能挡普通攻击,计算 token 这个事情本身就消耗 CPU 资源,攻击的时候为了省带宽也有只发不收,只要入口带宽没有被塞满,普通 cc 攻击都可以挡住。
但是如果暴力发包,只发不收的攻击来说,带宽都满了,并并不能通过这种方式进行防御。
弊端: 这样的token 对搜索引擎不够友好,这 token 校验第一波挡住的是搜索引擎的爬虫。所以,最好只是在被攻击的时候开启这个功能,平时关闭掉.
其它:
如果你的网站是使用的是Nginx做的反向代理,那么可以利用Nginx原生的limit_req模块来针对请求进行限制,ngx_http_limit_req_module
总结:
综上所述:最好在受到攻击的时候才开启token。
ps: 并没有绝对的防御方式,我们所能做的也就是不断提高攻击者的成本。通过手段把不合法的流量拦住。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号