渗透测试被动信息搜集工具v0.1
一、简单叭叭几句
趁着培训完的调整期,再填一篇原来挖的坑吧,这个工具很久之前和黄同学 @aHls 就写完了,初衷是想搞个一键信息搜集的工具(其实就是个爬虫),通过这个工具研究了一些反爬机制的绕过,这个工具还有很多可以完善的地方,最近懒懒,我先记下来等一个有缘人逼我改吧。划重点,这个工具现在还不算好用!!!只是记录一下我青涩的代码
先说缺陷和原因
1.爬了shodan 而没爬 fofa 的信息
原因:写的时候没舍得买 fofa 会员,但是现在有会员了!
2.需要几个潮汐指纹账号
原因:听说云悉指纹好用,但是我没邀请码,从前没有现在也没有,等我入职了问问公司有没有吧。用了潮汐之后才发现了亿点点问题,我原来都不知道查询次数过多会弹出验证码,所以这就是我这个工具最不好用的点,需要有几个潮汐指纹账号换着用
3.子域名太少
原因:这里只用了递归搜集子域名的方式,首先检测目标系统主页内包含的子域名,再接着访问主页上探测到的子域名上是否还有符合条件的子域名,递归直到搜集完毕,所以还要和其他工具配合着用,这个思路是我当时逛 github 找到的,但是我忘了参考的哪位师傅,如果有问题,师傅联系我,我马上署名!或者我哪天改改,接着调用大佬的工具?
4.需要安装 ChromeDriver
原因:暂时没想到其他绕过 ajax 的方式
优点
1.省去了频繁访问多个信息搜集工具的步骤,程序自动执行
2.可以批量处理多个目标站的信息搜集并生成报告
3.通过多个第三方平台获取目标的信息,尽可能的减少在目标站留下痕迹
二、流程图和代码
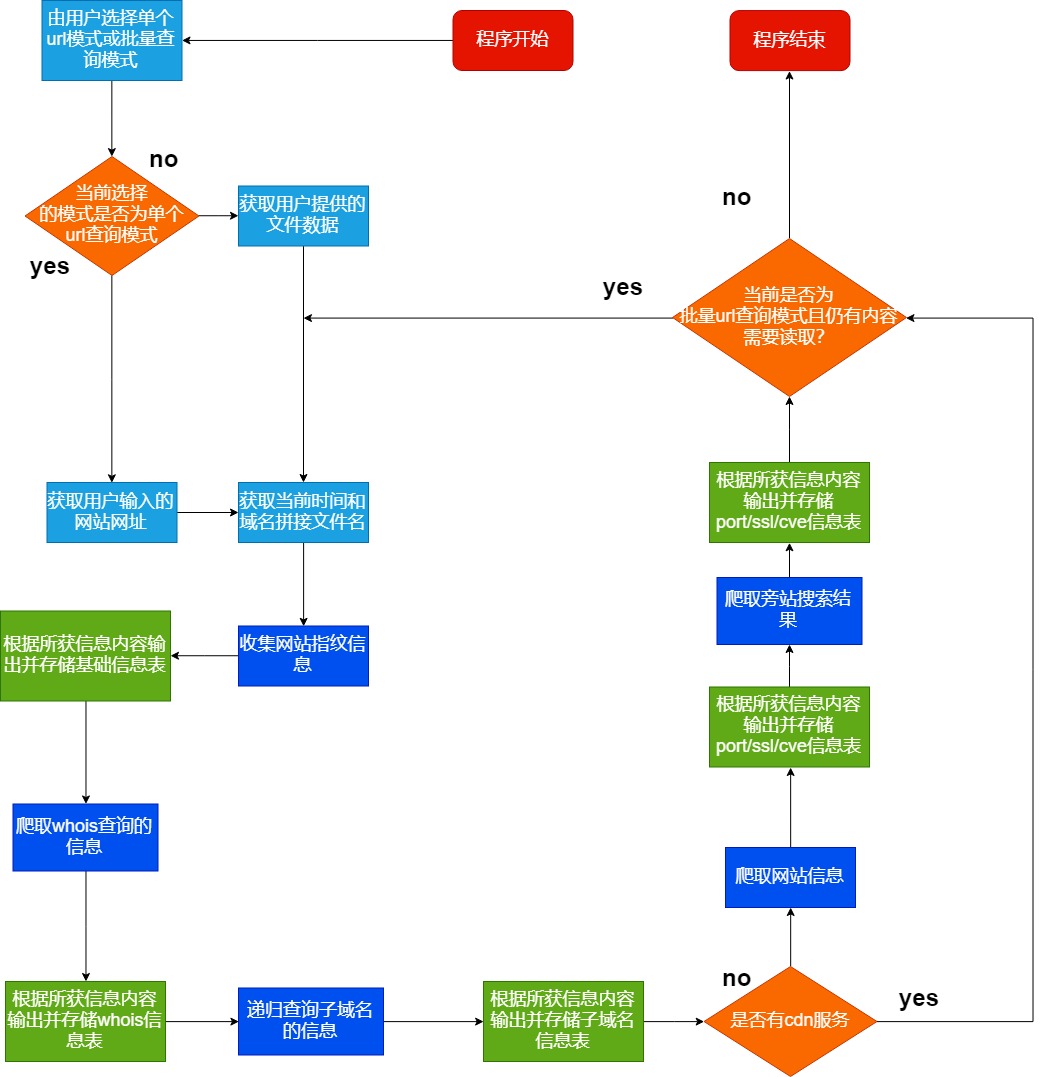
2.1 流程图
(从我原来的作业报告里扒下来的)
2.2 代码
没有贴出来的是图形化相关的代码,我觉得图形化有点鸡肋,命令行比较酷,文件夹的组织架构大概是这样的(这样不太好看,主要是现在不好意思传到 github 上,以后完善了再传吧,应该也没人用我的小垃圾工具,给其他学安全的小伙伴参考一下代码就得了)
2.2.1 Cio_main.py
# -*- coding: gb2312 -*- import argparse from lib.getinfo import * def main(): parser = argparse.ArgumentParser() parser.add_argument('-u', '--url', dest='url',help="input site's domain") parser.add_argument('-a', '--auto', dest='file', help="collect infomation with read txt file") args = parser.parse_args() if args.url == None and args.file == None: parser.print_help() os._exit(0) elif args.url != None and args.file == None: return args.url, 0 elif args.url == None and args.file != None: return args.file, 1 if __name__ == "__main__": domain, flag = main() if(flag == 0): print("正在查询 {domain} 相关信息,请稍等\n".format(domain=domain)) globalvar._init() currenttime = time.strftime("%H.%M.%S", time.localtime())#获取当前时间 globalvar.set_value('filename', domain + '_' + currenttime)#拼接文件名 filename = globalvar.get_value('filename') #tidefinger.pre_getinfo(domain) tb_chaoxi, ip, tb_banner=tidefinger.getinfo(domain) print(tb_chaoxi) print(tb_banner) if ip: tb_whois=aizhan.whois(domain) print(tb_whois) port_tb, ssl_tb, cve_tb=shodan.getinfo(ip) print(port_tb) print(ssl_tb) print(cve_tb) tb_aizhan=aizhan.pangzhan(domain) print(tb_aizhan) subdomain.getSubDomain(domain).start() else: tb_whois=aizhan.whois(domain) print(tb_whois) subdomain.getSubDomain(domain).start() if(flag == 1): #print("正在收集 {domain} 文件内各站的相关信息,请稍等\n".format(domain=domain)) f = open(domain, 'r') url = f.readline().replace('\n', '') while(url): print("正在查询 {url} 相关信息,请稍等\n".format(url=url)) globalvar._init() currenttime = time.strftime("%H.%M.%S", time.localtime())#获取当前时间 globalvar.set_value('filename', url + '_' + currenttime)#拼接文件名 filename = globalvar.get_value('filename') #tidefinger.pre_getinfo(domain) tb_chaoxi, ip, tb_banner=tidefinger.getinfo(url) print(tb_chaoxi) print(tb_banner) if ip: tb_whois=aizhan.whois(url) print(tb_whois) port_tb, ssl_tb, cve_tb=shodan.getinfo(ip) print(port_tb) print(ssl_tb) print(cve_tb) tb_aizhan=aizhan.pangzhan(url) print(tb_aizhan) subdomain.getSubDomain(url).start() url = f.readline().replace('\n', '') else: tb_whois=aizhan.whois(url) print(tb_whois) subdomain.getSubDomain(url).start() url = f.readline().replace('\n', '') print("\n---------------查询完毕!---------------\n")
2.2.2 lib/getinfo/aizhan.py
# -*- coding: gb2312 -*- import os import re import time import socket import chardet import requests import argparse import urllib.request import prettytable as pt from bs4 import BeautifulSoup from lib.common import * def pangzhan(domain):#旁站查询 aizhan_headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36', 'Content-Type': 'text/html; charset=UTF-8' } aizhan_url = "https://dns.aizhan.com/{domain}/".format(domain=domain) try: aizhan_response = requests.get(url=aizhan_url,headers=aizhan_headers,timeout=6) tb_aizhan = pt.PrettyTable(["旁站"]) soup = BeautifulSoup(aizhan_response.content,'html.parser')#指定解析器为html.parser az_page = [] az_page.append(aizhan_url) for div in soup.find_all('div',class_='pager'):#find_all返回所有匹配到的结果,class_参数匹配标签内class的属性 a = div.find_all('a')[3:-2]#div中第3个至倒数第3个<a></a>为翻页url,切片左闭右开,第一个是0最后一个是-1 for href in a: az_page.append(href['href']) for aizhan_url in az_page: soup = BeautifulSoup(aizhan_response.content,'html.parser') time.sleep(0.5) link_list=[] for select in soup.select('.dns-content a'):#定位所有class为dns-content内的a标签 link = select['href']#a标签中的href link_list.append(link) tb_aizhan.add_row([link]) # tb_aizhan.align = 'l'#输出表格左对齐 #print(tb_aizhan) filename = globalvar.get_value('filename') # print(filename) savetxt.text_save("./report/{filename}.txt".format(filename=filename),link_list,"旁站:") return tb_aizhan except Exception as e: print(e) print("爱站旁站异常") def whois(domain):#whois查询 aizhan_url = "https://whois.aizhan.com/{domain}/".format(domain=domain) try: request = urllib.request.Request(aizhan_url)#伪装浏览器 request.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36') response = urllib.request.urlopen(request) html = response.read() html = str(html,'utf-8') registrant_pattern = re.compile(r'Registrant: </b>(.*?)<br/>')#匹配注册人 registrant = registrant_pattern.findall(html) tmp = [str(j) for j in registrant]#列表转字符串 registrant_str = ''.join(tmp) if registrant_str == '': registrant_str = '暂无数据' email_pattern = re.compile(r'Registrant Contact Email: </b>(.*?)<br/>')#匹配邮箱 email = email_pattern.findall(html) tmp = [str(j) for j in email] email_str = ''.join(tmp) if email_str == '': email_str = '暂无数据' tb_whois = pt.PrettyTable(["域名持有人/机构名称","域名持有人/机构邮箱"]) tb_whois.add_row([registrant_str,email_str]) #print(tb_whois) filename = globalvar.get_value('filename') savetxt.text_save("./report/{filename}.txt".format(filename=filename),registrant,"域名持有人/机构名称:") savetxt.text_save("./report/{filename}.txt".format(filename=filename),email,"域名持有人/机构邮箱:") return tb_whois except Exception as e: print(e) print("爱站whois异常")
2.2.3 lib/getinfo/shodan.py
# -*- coding: gb2312 -*- import os import re import time import requests import argparse import urllib.request import prettytable as pt from lib.common import * def getinfo(ip): #shodan查端口服务 shodan_headers = { 'Host':'www.shodan.io', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36', 'Content-Type': 'application/x-www-form-urlencoded', } shodan_url = "https://www.shodan.io/host/{ip}".format(ip=ip) shodan_response = requests.get(url=shodan_url,headers=shodan_headers,timeout=15) port_pattern=re.compile(r'<div class="port">(\d*?)</div>') port_content=port_pattern.findall(shodan_response.text) ssl_pattern=re.compile(r'<div class="state">(.*?)</div>') ssl_content=ssl_pattern.findall(shodan_response.text) cve_pattern=re.compile(r'<th style="min-width:100px">(.*?)</th>') cve_content=cve_pattern.findall(shodan_response.text) if len(cve_content) == 0: cve_content = '暂无数据' cvedetail_pattern=re.compile(r'<th style="min-width:100px">([\s\S]*?)</td>') cvedetail_content=cvedetail_pattern.findall(shodan_response.text) tmp = [str(j) for j in cvedetail_content]#列表转字符串 cvedetail_str = ''.join(tmp) cvedetail_str=re.sub(r"<td>","",cvedetail_str)#替换为空 # print(cvedetail_str) cvetxt = re.split(r"</th>",cvedetail_str)#分组转列表 try: port_tb=pt.PrettyTable(["开放端口"]) if port_content: for i in range(len(port_content)): port_tb.add_row([port_content[i]]) else: port_tb.add_row("未发现开放端口") ssl_tb=pt.PrettyTable(["是否开启SSL"]) flag=False for ssl in ssl_content: if "https" in ssl: flag=True if flag: ssl_tb.add_row("是") else: ssl_tb.add_row("否") cve_tb=pt.PrettyTable(["基于软件和版本的可能漏洞"]) for i in range(len(cve_content)): cve_tb.add_row([cve_content[i]]) filename = globalvar.get_value('filename')#获取唯一标识文件名 savetxt.text_save("./report/{filename}.txt".format(filename=filename),port_content,"shodan收集的开放端口:") savetxt.text_save("./report/{filename}.txt".format(filename=filename),ssl_content,"shodan收集的开放服务:") savetxt.text_save("./report/{filename}.txt".format(filename=filename),cvetxt,"基于软件和版本的可能漏洞:\n") return port_tb, ssl_tb, cve_tb except Exception as e: print(e) print("shodan异常")
2.2.4 lib/getinfo/subdomain.py
# -*- coding: utf-8 -*- import requests import re import chardet import argparse from lib.common import * requests.packages.urllib3.disable_warnings()#为了避免ssl认证,将verify=False,但是日志会有warning,这行代码可以去除warning信息 class getSubDomain: def __init__(self, url): #第一次调用传入参数形如www.baidu.com,第二次至结束传入参数形如http://www.baidu.com if "http" not in url: self.url = "http://" + url else: self.url = url self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'} urlsplit = url.split(".") #教育和政府子域名取后三段,其余网站取后两段 if "edu.cn" in url or "org.cn" in url or "gov.cn" in url or "com.cn" in url: self.domain = urlsplit[-3] + "." + urlsplit[-2] + "." + urlsplit[-1] else: self.domain = urlsplit[-2] + "." + urlsplit[-1] self.SubDomainList = [self.url]#子域名列表 # print(self.SubDomainList) #域名匹配规则 self.domain_patten = re.compile('https?:\/\/[^"/]+?\.{url}'.format(url=self.domain)) # print(self.domain_patten) # 标题匹配规则 self.title_patten = re.compile('<title>(.*)?</title>') self.url_except = []#存放请求异常的url self.result = [] #从主站开始爬取 def start(self): print('\n子域名信息\n') global filename filename = globalvar.get_value('filename') with open('./report/{filename}.txt'.format(filename=filename), 'a') as f: f.writelines('\n'+'子域名信息:'+'\n') self.getSubDomain(self.url, 0) #对异常的url再重新跑一遍 #print('异常:{}'.format(self.url_except)) url_excepts = self.url_except[:]#创建一个新的列表,内容是url_except列表里的url for url_except in url_excepts: self.getSubDomain(url_except, 0) #打印所有结果 #for ret in self.result: # print(ret) #获取域名列表 def getSubDomain(self, url, layer): layer += 1 #有些https站请求会抛出异常,将异常url放入url_except列表 try: res = requests.get(url, headers=self.headers, timeout=5, verify=False) except Exception as e: self.url_except.append(url) # 将请求异常的url放入url_except列表里。 res = None try: self.code_title(url, res) subdomains = list(set(re.findall(self.domain_patten, res.text))) # 子域名列表,去重结果 #print(subdomains) # 遍历匹配到的所有子域名 for subdomain in subdomains: # print('第【{}】层 : {}'.format(layer, subdomain)) # 如果这个子域名之前没添加进列表里 if subdomain not in self.SubDomainList: self.SubDomainList.append(subdomain) self.getSubDomain(subdomain, layer) # else: # print('{}已经在列表里'.format(subdomain)) except Exception as e: pass #获取域名的标题和状态码 def code_title(self, url, res): result = {} code = res.status_code try: cont = res.content #获取网页的编码格式 charset = chardet.detect(cont)['encoding'] #对各种编码情况进行判断 html_doc = cont.decode(charset) except Exception as e: html_doc = res.text try: # self.title_patten = re.compile('<title>(.*)?</title>') title = re.search(self.title_patten, html_doc).group(1) result['url'],result['code'],result['title'] = url,code,title except Exception as e: result['url'], result['code'], result['title'] = url, code, 'None' finally: print(result) self.result.append(str(result)) self.save(str(result)) #保存文件 def save(self, result): with open('./report/{filename}.txt'.format(filename=filename), 'a') as f: f.writelines(result+'\n') ''' def main(): parser = argparse.ArgumentParser() parser.add_argument('-u','--url',dest='url',help="input site's domain") args = parser.parse_args() if args.url == None: parser.print_help() os._exit(0) return args.url if __name__ == "__main__": domain = main() print("正在查询 {domain} 相关信息,请稍等\n".format(domain=domain)) getSubDomain(domain).start() '''
2.2.5 lib/getinfo/tindfinger.py
# -*- coding: gb2312 -*- import os import re import time import requests import argparse import urllib.request import prettytable as pt from lib.common import * from selenium import webdriver def getbanner(banner):#banner比较特殊,需要特殊处理 # 构造表tb_banner flag = 1 list_banner = "" tb_banner = pt.PrettyTable(["banner信息"]) if (banner == ""): list_banner = "暂无数据" tb_banner.add_row([list_banner]) else: for i in banner: if (i == ","): continue if (flag == 1 and i == "\""): flag = 0 list_banner += i elif (flag == 0 and i == "\""): flag = 1 list_banner += i tb_banner.add_row([list_banner]) list_banner = "" else: list_banner += i return tb_banner def getinfo(domain):#潮汐指纹 cookie, cookie_l=getcookie.get() chaoxi_headers = { 'Host': 'finger.tidesec.net', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36', 'Cookie': cookie } chaoxi_url = 'http://finger.tidesec.net/' chaoxi_info = 'http://finger.tidesec.net/home/index/reget' try: option=webdriver.ChromeOptions() option.add_argument('headless') # 设置option,隐藏浏览器 browser = webdriver.Chrome(chrome_options=option) browser.delete_all_cookies()#先清所有cookie # cookies=browser.get_cookies() # print(cookies)这个cookies不是下面的列表,要删掉除了domain/name/path/value的其他参数 list_cookies=cookie_l browser.get(chaoxi_url) for i in list_cookies: browser.add_cookie(i) browser.get(chaoxi_url) browser.find_element_by_xpath('//*[@id="input1"]').send_keys(domain) browser.find_element_by_xpath('//*[@id="btn"]').click() #点击 time.sleep(60) source = browser.page_source #print(source)#打印网页 data = { 'target':domain } data = urllib.parse.urlencode(data).encode("utf-8")#POST提交 request = urllib.request.Request(url=chaoxi_info, data=data, headers=chaoxi_headers) response = urllib.request.urlopen(request, timeout=120) html = response.read().decode('utf-8') html = html.replace("\\\\",'\\')#\\换成\ html = eval("'{}'".format(html))#python抓取数据时会自动转义,反转义功能 cdn_pattern = re.compile(r'"cdn": "(.*?)"')#匹配CDN cdn = cdn_pattern.findall(html) tmp = [str(j) for j in cdn] cdn_str = ''.join(tmp) cms_pattern = re.compile(r'"cms_name": "(.*?)"')#匹配CMS cms = cms_pattern.findall(html) tmp = [str(j) for j in cms] cms_str = ''.join(tmp) if cms_str == '': cms_str = '暂无数据' ip_pattern = re.compile(r'"ip": "(.*?)"')#匹配IP信息 ip = ip_pattern.findall(html) tmp = [str(j) for j in ip] ip_str = ''.join(tmp) if ip_str == '': ip_str = '暂无数据' ipaddr_pattern = re.compile(r'"area": "(.*?)"')#匹配IP地址 ipaddr = ipaddr_pattern.findall(html) tmp = [str(j) for j in ipaddr] ipaddr_str = ''.join(tmp) if ipaddr_str == '': ipaddr_str = '暂无数据' isp_pattern = re.compile(r'"isp": "(.*?)"')#匹配ISP地址 isp = isp_pattern.findall(html) tmp = [str(j) for j in isp] isp_str = ''.join(tmp) if isp_str == '': isp_str = '暂无数据' os_pattern = re.compile(r'"os": "(.*?)"')#匹配操作系统 os = os_pattern.findall(html) tmp = [str(j) for j in os] os_str = ''.join(tmp) if os_str == '': os_str = '暂无数据' banner_pattern = re.compile(r'"banner": (.*)]') # 匹配Banner banner = banner_pattern.findall(html) # print (banner) banner[0]+="]" tmp = [str(j) for j in banner] banner_str = ''.join(tmp) if banner_str == '[]': banner_str = '暂无数据' #print(banner) filename = globalvar.get_value('filename')#获取唯一标识文件名 # print(filename) tb_banner = pt.PrettyTable(["banner信息"]) if cdn_str: tb_chaoxi = pt.PrettyTable(["CMS信息","CDN信息","操作系统"]) tb_chaoxi.add_row([cms_str,cdn_str,os_str]) #print(tb_chaoxi) savetxt.text_save("./report/{filename}.txt".format(filename=filename),cms,"cms信息:") savetxt.text_save("./report/{filename}.txt".format(filename=filename),cdn,"cdn信息:") savetxt.text_save("./report/{filename}.txt".format(filename=filename),os,"os信息:") savetxt.text_save("./report/{filename}.txt".format(filename=filename),banner,"banner信息:") temp = banner[0] banner = temp[1:] tb_banner=getbanner(banner) return tb_chaoxi, False, tb_banner else: tb_chaoxi = pt.PrettyTable(["CMS信息","IP信息","IP地址","ISP信息","CDN信息","操作系统"]) tb_chaoxi.add_row([cms_str,ip_str,ipaddr_str,isp_str,'暂无数据',os_str]) #print(tb_chaoxi) savetxt.text_save("./report/{filename}.txt".format(filename=filename),ip,"ip信息:") savetxt.text_save("./report/{filename}.txt".format(filename=filename),ipaddr,"ip地址:") savetxt.text_save("./report/{filename}.txt".format(filename=filename),isp,"isp信息:") savetxt.text_save("./report/{filename}.txt".format(filename=filename),cms,"cms信息:") savetxt.text_save("./report/{filename}.txt".format(filename=filename),cdn,"cdn信息:") savetxt.text_save("./report/{filename}.txt".format(filename=filename),os,"os信息:") savetxt.text_save("./report/{filename}.txt".format(filename=filename),banner,"banner信息:") temp = banner[0] banner = temp[1:] tb_banner=getbanner(banner) return tb_chaoxi, ip_str, tb_banner except Exception as e: print(e) print("潮汐异常")
2.2.6 lib/common/getcookie.py
def get(): f = open("Cookie.txt", "r") s = f.read() cookie = s.replace(" ", "") cookie_t = cookie.split(";") cookie_l = [] for c in cookie_t: temp = c.split("=") cookie_l.append({"domain":"finger.tidesec.net", "name":temp[0], "path":"/", "value":temp[1]}) #print(cookie_l) return s, cookie_l if __name__ == "__main__": get()
2.2.7 lib/common/globalvar.py
def _init(): global _global_dict _global_dict = {} def set_value(name, value): _global_dict[name] = value def get_value(name, defValue=None): try: return _global_dict[name] except KeyError: return defValue
2.2.8 lib/common/savetxt.py
# -*- coding: gb2312 -*- def text_save(filename, data, info):#filename为写入txt文件的路径,data为要写入数据列表,info注明写入txt的内容是什么. file = open(filename,'a')#a模式打开文件,在txt末尾添加新内容 file.write(info) if not data: #data为空 s='暂无数据'+'\n' file.write(s) if info == "旁站:": file.write('\n') for i in range(len(data)): if i == len(data)-1: s = str(data[i]) # if s == '': # s = '暂无数据' # s = s + '\n' # else: # s = s + '\n' else: s = str(data[i]) s = s + '\n' file.write(s) else: for i in range(len(data)): if i == len(data)-1: s = str(data[i]).replace('[','').replace(']','') if s == '': s = '暂无数据' s = s.replace("'",'').replace(',','') +'\n' else: s = s.replace("'",'').replace(',','') +'\n' else: s = str(data[i]).replace('[','').replace(']','')#去除[],这两行按数据不同,可以选择 s = s.replace("'",'').replace(',','') +',' #去除单引号,逗号,每行末尾追加换行符 file.write(s) file.close()
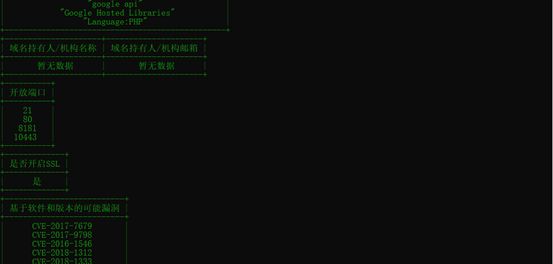
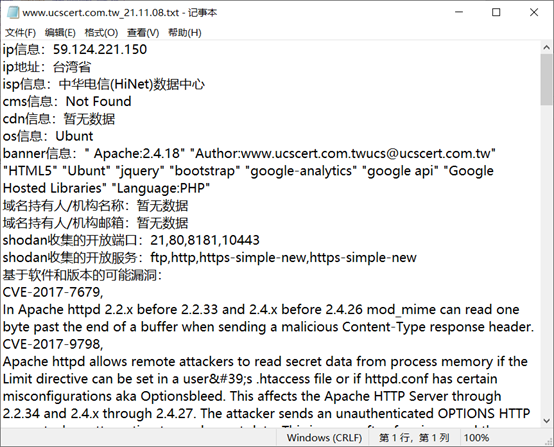
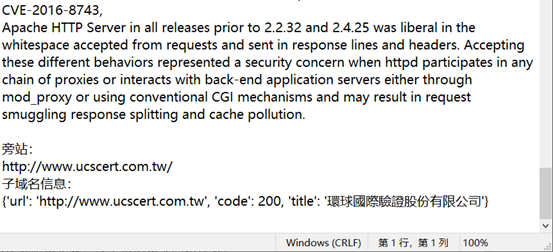
三、测试截图
这里只测试搜集一个网站的信息吧,图来自我曾经的作业报告(我抄我自己)
python3 Cio_main.py -u www.ucscert.com.tw




 浙公网安备 33010602011771号
浙公网安备 33010602011771号