
计算机组成原理——cache高速缓存存储器
转载自https://blog.csdn.net/chen1083376511/article/details/8187481
cache-高速缓存存储器
在主存与CPU之间插入一级或多级SRAM组成的高速缓存存储器。扩展cache有限,因为SRAM价格昂贵。
cache作用:为了解决CPU和主存之间速度不匹配而采用的一项重要技术。
cache特性:具有空间局部性以及时间局部性。
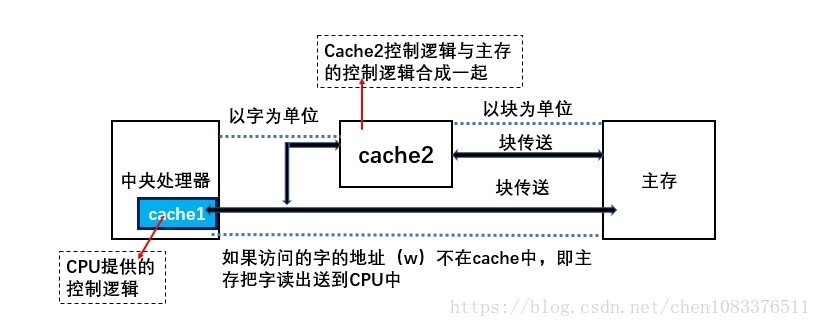
cache的组成:SRAM和控制逻辑。如果cache在CPU芯片外,它的控制逻辑一般和主存控制逻辑合成在一起,称主存/cache控制器。若cache在CPU内,则由CPU提供它的控制逻辑。
CPU与cache之间的数据交换是以字为单位,而cache与主存之间的数据交换是以块为单位。一个块由若干字组成,是定长的。
cache原理图
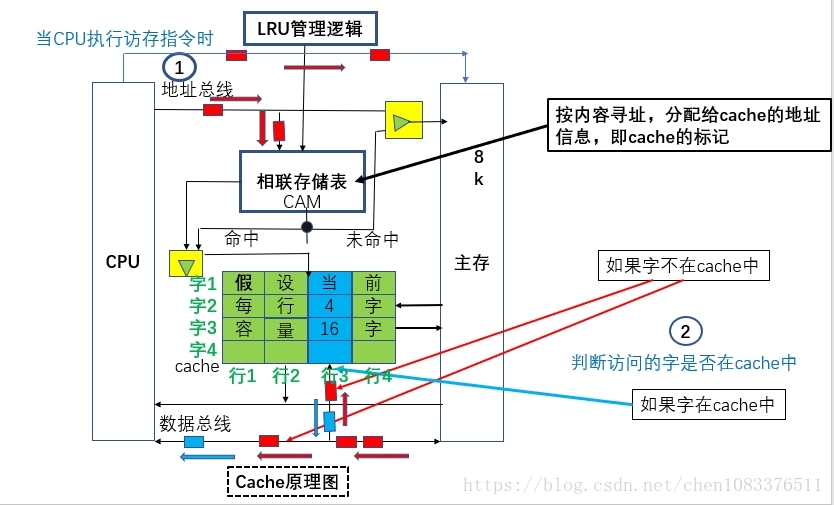
ache的命中率:为了使主存的平均读出时间尽可能接近cache的读出时间,cache命中率应接近于1.
地址映射
含义:为了把主存块放到cache中,必须应用某种方法把主存地址定位到cache中,称作地址映射。
地址映射方式:全相联映射方式、直接映射方式和组相联映射方式。
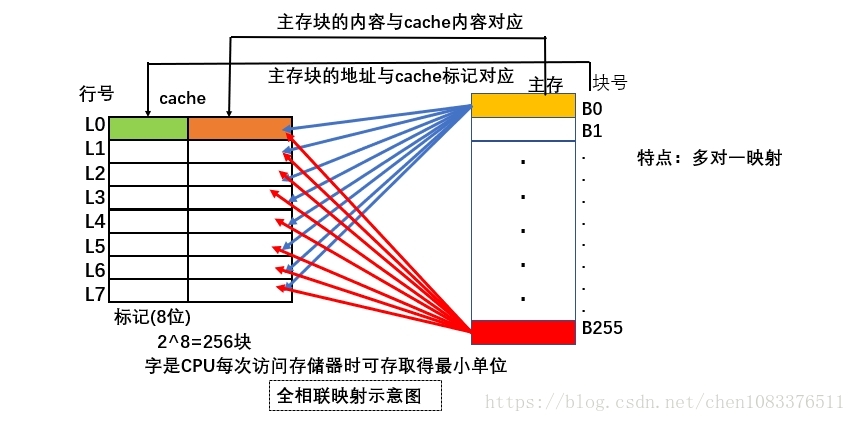
全相联映射方式

小结:
(1)在全相联cache中,全部标记用一个相联存储器来实现,全部数据用一个普通RAM来实现。
(2)优点”冲突率小,cache利用率高
(3)缺点:比较器难于设计与实现
(4)只适用小容量cache。
直接映射方式
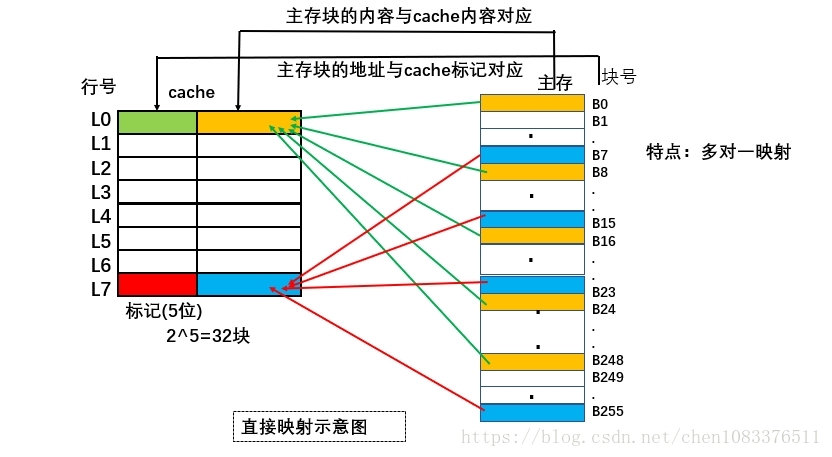

小结:
(1)优点:硬件简单,成本低。
(2)缺点:每个主存块只有一个固定得行位置可存放。
(3)发生冲突率大。(如果块号相距m整数倍得两个块存于同一cache行时)
(4)适合大容量cache.
组相联映射方式
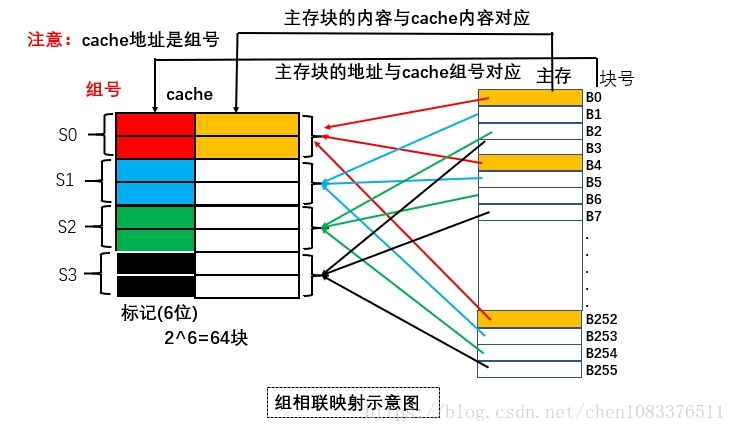

小结:
适度兼顾了“全相联映射方式”和“直接映射方式”的优点以及尽量避免两者的缺点。
替换策略
含义:当一个新的主存块需要拷贝到cache,而允许存放块的行位置都被其他主存占满时,就要产生替换。
适合的地址映射方式:全相联映射方式和组相联映射方式
(1)最不经常使用(LFU)算法
含义:将一段时间内被访问次数最少的那行数据换出。每行设置一个计数器,从0开始计数,每次访问某一行时被访问的计数器增1.当需要替换时,将计数值最小的行换出,同时将这些行的计数器全部清零。
特点:这种算法将计数周期限定在对这些定行两次替换之间的间隔时间内(即替换一次,计数器清零一次),不能严格反映近期访问情况。
(2)近期最少使用(LRU)算法
含义:将近期内长久未被访问过的换出。每行设置一个计数器,Cache每命中一次,命中行计数器清零,其他各行计数器增1.当需要替换时,将计数值最大的行换出。
特点:这种算法保护了刚拷贝到cache中的新数据行,有较高的命中率。
(3)随机替换
含义:从cache的行位置中随机地选取一行换出。
特点:在硬件上容易实现,且速度也比那几种策略快。但可能降低cache命中率和工作效率。
(4)先入先出(FIFO)算法
含义:总是将最先调入的cache的内容替换出来,不需要随时记录各字块的使用情况。
特点:容易实现,电路简单。但是可能会把一些经常使用的程序(如循环程序)也作为最早的cache块而替换出去。
cache的写回操作策略
含义:CPU对Cache的写入更改了Cache的内容。当被更改了内容的Cache块被替换出Cache时,选用写回操作替换策略使Cache内容和主存内容保持一致。
(1)写回法
当CPU写Cache命中时,只修改Cache的内容,而不立即写入主存;只有当此行被替换出时才写回主存。
优点:减少了访问主存的次数。
缺点:存在不一致性的隐患。
解决问题:每个Cache行必须配置一个修改位,以反映此行是否被CPU修改过。
(2)全写法
当CPU写Cache命中时,Cache与主存同时发生写修改。因而较好地维护了Cache与主存内容的一致性。当CPU写Cache未命中时,直接向主存进行写入。
优点:Cache中每行无需设置一个修改位以及相应的判断逻辑。
缺点:cache对CPU向主存的写操作无高速缓冲功能,降低了Cache的功效。
(3)写一次法
基于写回法并结合全写法的写策略,写命中与写未命中的处理方法与写回法基本相同,只是第一次写命中时要同时写入主存(全写法)。
优点:便于维护系统全部Cache的一致性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号